KR102543451B1 - Image feature extraction and synthesis system using deep learning and its learning method - Google Patents
Image feature extraction and synthesis system using deep learning and its learning method Download PDFInfo
- Publication number
- KR102543451B1 KR102543451B1 KR1020220053447A KR20220053447A KR102543451B1 KR 102543451 B1 KR102543451 B1 KR 102543451B1 KR 1020220053447 A KR1020220053447 A KR 1020220053447A KR 20220053447 A KR20220053447 A KR 20220053447A KR 102543451 B1 KR102543451 B1 KR 102543451B1
- Authority
- KR
- South Korea
- Prior art keywords
- learning
- image
- encoder
- geometry
- vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—Two-dimensional [2D] image generation
- G06T11/60—Creating or editing images; Combining images with text
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—Two-dimensional [2D] image generation
- G06T11/20—Drawing from basic elements
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20212—Image combination
- G06T2207/20221—Image fusion; Image merging
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
본 발명은 딥 러닝을 이용한 이미지의 특징 추출 및 합성 시스템 및 이의 학습 방법에 대한 것으로, 본 발명의 이미지 특징 추출 및 합성 시스템은 제1 이미지(10)로부터 스타일 벡터(210)를 추출하는 스타일 인코더(200);, 제2 이미지(20)로부터 지오메트리 벡터(110)를 추출하는 지오메트리 인코더(100); 및 상기 지오메트리 벡터(110)와 상기 스타일 벡터(210)를 합성하여 합성 이미지(310)를 생성하는 합성 디코더(300);를 포함한다.The present invention relates to a system for extracting and synthesizing features of an image using deep learning and a method for learning the same. The system for extracting and synthesizing image features of the present invention includes a style encoder ( 200); the geometry encoder 100 extracting the geometry vector 110 from the second image 20; and a synthesizing decoder 300 generating a synthesized image 310 by synthesizing the geometry vector 110 and the style vector 210.

Description
본 발명은 딥 러닝을 이용하여 복수의 이미지의 특징들을 각각 추출하여 새로운 합성 이미지를 생성하는 시스템 및 그 시스템을 이루는 구성들을 학습하는 방법에 대한 것이다.The present invention relates to a system for generating a new composite image by extracting features of a plurality of images, respectively, using deep learning, and a method for learning components constituting the system.
또한, 본 발명은 인물 이미지의 지오메트리 정보와 스타일 정보를 독립적으로 추출 및 합성하는 것이 기술적 특징 중 하나일 수 있다.In addition, one of the technical features of the present invention may be to independently extract and synthesize geometry information and style information of a person image.
특허문헌 001은 얼굴 이미지 검색을 통한 가상 인물 생성 시스템 및 방법에 대한 것으로, 본 발명에 따른 얼굴 이미지 검색을 통한 가상 인물 생성 방법은, 컴퓨터 시스템에 의해 인공지능 기법을 기반으로 다양한 모습의 가상 캐릭터 얼굴 이미지를 생성하여 이미지 데이터베이스에 저장하는 단계와; 이미지 검색부에 의해 외부로부터 2D 이미지를 입력받아 가상 캐릭터 얼굴 이미지가 저장되어 있는 이미지 데이터베이스를 검색하는 단계와; 이미지 검색부에 의해 얼굴 랜드마크 기반 유사도 비교를 통해 이미지 데이터베이스로부터 유사한 이미지를 추출하는 단계; 및 가상 인물 생성부가 상기 이미지 검색부에 의해 추출된 이미지를 전송받아 그를 기반으로 새로운 가상 인물을 생성하는 단계를 포함하는 기술을 제시한다.Patent Document 001 relates to a system and method for generating a virtual person through face image search, and the method for generating a virtual person through face image search according to the present invention is a virtual character face of various appearances based on an artificial intelligence technique by a computer system. generating an image and storing it in an image database; receiving a 2D image from the outside by an image search unit and searching an image database in which a face image of a virtual character is stored; extracting similar images from an image database through face landmark-based similarity comparison by an image search unit; and receiving, by a virtual person creation unit, the image extracted by the image search unit and generating a new virtual person based thereon.
특허문헌 002는 이미지 보정방법 및 보정장치가 개시된다. 이미지 보정방법은, 필터 적용을 통한 이미지 보정, 필터 정보들의 저장, 필터 정보들을 이용한 심층 신경망 모델의 재훈련 및 심층 신경망 모델을 이용한 필터 정보 출력을 포함한다. 본 발명에 따르면, 5G 네트워크를 통한 인공지능(AI) 모델을 이용한 이미지 분석에 기반하여 이미지 보정이 가능한 기술을 제시한다.Patent Document 002 discloses an image correction method and correction device. The image correction method includes image correction through application of filters, storage of filter information, retraining of a deep neural network model using the filter information, and output of filter information using the deep neural network model. According to the present invention, a technology capable of image correction based on image analysis using an artificial intelligence (AI) model through a 5G network is presented.
특허문헌 003은 이미지 자동 생성 장치 및 생성 방법에 대한 것으로, 이미지 자동 생성 장치에 있어서, 적어도 하나의 프로세서를 포함하고, 상기 적어도 하나의 프로세서는, 제1 이미지를 기초로 상이한 도메인의 제2 이미지를 생성하고, 상기 생성한 제2 이미지에 서 미리 설정된 파라미터를 추출하고 상기 추출한 파라미터를 기초로 제3 이미지를 생성하는 기술을 제시한다.Patent Document 003 relates to an automatic image generation device and method, wherein the image automatic generation device includes at least one processor, and the at least one processor generates a second image of a different domain based on a first image. A technique of generating a second image, extracting preset parameters from the generated second image, and generating a third image based on the extracted parameter is proposed.
특허문헌 004는 이미지를 합성하는 인공 지능 장치 및 그 방법에 대한 것으로, 이미지 데이터를 저장하는 메모리, 이미지 데이터로부터 인물 객체 이미지 및 사물 객체 이미지를 획득하고, 인물 객체 이미지와 매칭되는 3차원 인물 모델을 생성하고, 이미지 데이터의 좌표 정보를 추출하고, 좌표정보에 매칭되는 거리뷰 데이터를 획득하고, 거리뷰 데이터로부터 사물 객체 이미지의 사물 객체가 촬영된 기준 객체 이미지를 추출하고, 인물 객체 이미지 및 사물 객체 이미지의 배치 정보를 획득하고, 배치 정보 및 기준 객체 이미지를 이용하여 3차원 인물 모델을 거리뷰 데이터의 거리뷰 이미지에 배치하는 프로세서를 포함하는 인공지능 장치를 제시한다.Patent Document 004 relates to an artificial intelligence device and method for synthesizing images, a memory for storing image data, obtaining a person object image and object object image from the image data, and a 3D person model matched with the person object image. generating, extracting coordinate information of image data, acquiring street view data matching the coordinate information, extracting reference object images in which the object object of the object object image is photographed from the street view data, and extracting a person object image and object object We present an artificial intelligence device including a processor that acquires image placement information and places a 3D person model on a street view image of street view data using the placement information and reference object image.
본 발명은 딥 러닝을 이용한 이미지의 특징 추출 및 합성 시스템 및 이의 학습 방법에 대한 것으로, 복수 이미지의 각 특성들을 추출하여 새로운 합성 이미지를 생성하는 시스템을 제공하고자 한다.The present invention relates to a system for extracting and synthesizing features of images using deep learning and a method for learning the same.
또한, 본 발명의 시스템의 각각의 구성을 순차대로 학습함으로써, 보다 효율적인 학습 방법을 제공하여 시스템의 완성도를 확보하고자 한다.In addition, it is intended to secure the completeness of the system by providing a more efficient learning method by sequentially learning each configuration of the system of the present invention.
또한, 본 발명의 각 구성인 복수의 인코더와 디코더들을 학습함에 있어, 학습 인물 이미지의 지오메트리 정보와 스타일 정보를 독립적으로 추출하는 방법을 수행하여 본 발명의 목적 및 효과를 확보하고자 한다.In addition, in learning a plurality of encoders and decoders, each component of the present invention, a method of independently extracting geometry information and style information of a learning person image is performed to secure the object and effect of the present invention.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지의 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템에 대한 발명이며, 제1 이미지로부터 스타일 벡터를 추출하는 스타일 인코더;, 제2 이미지로부터 지오메트리 벡터를 추출하는 지오메트리 인코더; 및 상기 지오메트리 벡터와 상기 스타일 벡터를 합성하여 합성 이미지를 생성하는 합성 디코더;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for an image synthesis system for generating a virtual image through feature extraction and synthesis of images using deep learning, a style encoder for extracting a style vector from a first image; 2 A geometry encoder that extracts a geometry vector from the image; and a synthesizing decoder generating a synthesized image by synthesizing the geometry vector and the style vector.
본 발명의 일 실시예에 따른 발명은 앞에서 제시한 발명을 학습하는 방법에 대한 발명이며, 상기 지오메트리 인코더는 (a) 스케치 인코더가 상기 제1 이미지로부터 추출한 제1 스케치로부터 제1 학습용 지오메트리 벡터를 생성하는 단계; 및 (b) 상기 제1 학습용 지오메트리 벡터와 상기 지오메트리 벡터의 오차인 제1 오차를 감소시키는 방향으로 상기 지오메트리 인코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention relates to a method for learning the above-mentioned invention, and the geometry encoder generates a first learning geometry vector from a first sketch extracted from the first image by the sketch encoder (a) doing; and (b) learning the geometry encoder in a direction to reduce a first error, which is an error between the first learning geometry vector and the geometry vector.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 (a) 단계는 (a-1) 스케치 디코더가 상기 제1 학습용 지오메트리 백터로부터 제1 학습용 변환 스케치를 생성하는 단계;, (a-2) 스케치 디코더가 상기 지오메트리 벡터로부터 제2 학습용 변환 스케치를 생성하는 단계;를 포함하고, 상기 (b) 단계는 (b-1) 상기 제1 학습용 변환 스케치와 상기 제2 학습용 변환 스케치의 오차인 제2 오차 감소시키는 방향으로 상기 지오메트리 인코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the above (a) Steps include: (a-1) generating, by a sketch decoder, a transformation sketch for first training from the first geometry vector for training; (a-2) generating, by a sketch decoder, a transformation sketch for second training from the geometry vector; And the step (b) includes (b-1) learning the geometry encoder in a direction that reduces a second error, which is an error between the first transformation sketch for learning and the second transformation sketch for learning; made up of
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 (a)단계 및 상기 (b)단계를 반복 수행하여 상기 지오메트리 인코더를 학습하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the above (a) and (b) are repeatedly performed to learn the geometry encoder.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 스케치 인코더 및 상기 스케치 디코더는 (c) 상기 스케치 인코더가 인물 이미지로부터 추출한 인물 스케치(12)로부터 제2 학습용 지오메트리 벡터를 생성하는 단계;, (d) 상기 스케치 디코더가 상기 제2 학습용 지오메트리 벡터로부터 제3 학습용 변환 스케치를 생성하는 단계; 및 (e) 상기 인물 스케치와 상기 제3 학습용 변환 스케치의 오차인 제3 오차(3)를 줄이는 방향으로 상기 스케치 인코더 및 상기 스케치 디코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the sketch encoder and The sketch decoder (c) generating a second learning geometry vector from the
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 스타일 인코더 및 상기 합성 디코더는 (f) 상기 스타일 인코더가 상기 합성 이미지로부터 제1 학습용 스타일 벡터를 생성하는 단계;, (g) 상기 지오메트리 인코더가 상기 제1 이미지로부터 제3 학습용 지오메트리 벡터를 생성하는 단계;, (h) 상기 합성 디코더가 상기 제1 학습용 스타일 벡터와 상기 제3 학습용 지오메트리 벡터를 합성하여 제1 학습용 합성 이미지를 생성하는 단계; 및 (i) 상기 제1 학습용 합성 이미지와 상기 제1 이미지의 오차인 제4 오차를 줄이는 방향으로 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the style encoder and The synthesis decoder includes: (f) the style encoder generating a style vector for first training from the synthesized image; (g) the geometry encoder generating a third geometry vector for training from the first image; ( h) synthesizing, by the synthesis decoder, the first learning style vector and the third learning geometry vector to generate a first learning synthesis image; and (i) learning the style encoder and the synthesis decoder in a direction to reduce an error between the first synthetic image for learning and a fourth error, which is an error between the first image.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 (f)단계 및 상기 (i)단계를 반복 수행하여 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the above (f) and (i) are repeatedly performed to learn the style encoder and the synthesis decoder.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 스타일 인코더 및 상기 합성 디코더는 (j) 상기 지오메트리 인코더가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터를 생성하는 단계;, (k) 상기 스타일 인코더가 상기 제2 이미지로부터 제2 학습용 스타일 벡터를 생성하는 단계;, (l) 상기 합성 디코더가 상기 제4 학습용 지오메트리 벡터와 상기 제2 학습용 스타일 벡터를 합성하여 제2 학습용 합성 이미지를 생성하는 단계; 및 (m) 상기 제2 학습용 합성 이미지와 상기 제2 이미지의 오차인 제5 오차를 줄이는 방향으로 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the style encoder and The synthesis decoder includes: (j) the geometry encoder generating a fourth learning geometry vector from the synthesized image; (k) the style encoder generating a second learning style vector from the second image; ( l) synthesizing, by the synthesis decoder, the fourth learning geometry vector and the second learning style vector to generate a second training synthesis image; and (m) learning the style encoder and the synthesis decoder in a direction of reducing a fifth error, which is an error between the second synthesized image for training and the second image.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 (j)단계 및 상기 (m)단계를 반복 수행하여 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the above (j) and (m) are repeatedly performed to learn the style encoder and the synthesis decoder.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 스타일 인코더 및 상기 합성 디코더는 (n) 상기 지오메트리 인코더가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터를 생성하는 단계;, (o) 상기 스타일 인코더가 상기 제2 이미지로부터 제2 학습용 스타일 벡터를 생성하는 단계;, (p) 상기 합성 디코더가 상기 제4 학습용 지오메트리 벡터와 상기 제2 학습용 스타일 벡터를 합성하여 제2 학습용 합성 이미지를 생성하는 단계; 및 (q) 상기 제2 학습용 합성 이미지와 상기 제2 이미지의 오차인 제5 오차를 줄이는 방향으로 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the style encoder and The synthesizing decoder includes: (n) the geometry encoder generating a fourth learning geometry vector from the synthesized image; (o) the style encoder generating a second learning style vector from the second image; ( p) synthesizing, by the synthesis decoder, the fourth learning geometry vector and the second learning style vector to generate a second training synthesis image; and (q) learning the style encoder and the synthesis decoder in a direction of reducing a fifth error, which is an error between the second synthesized image for learning and the second image.
본 발명의 일 실시예에 따른 발명은 딥 러닝을 이용한 이미지 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템의 학습 방법에 대한 발명이며, 앞에서 제시한 학습 방법에 있어서, 상기 스타일 인코더 및 상기 합성 디코더는 (r) 상기 제1 이미지 및 제2 이미지를 동일한 이미지인 제3 이미지로 설정하는 단계;, (s) 상기 스타일 인코더가 상기 제3 이미지로부터 제3 학습용 스타일 벡터를 생성하는 단계;, (t) 상기 지오메트리 인코더가 상기 제3 이미지로부터 제5 학습용 지오메트리 벡터를 생성하는 단계;, (u) 상기 합성 디코더가 상기 제3 학습용 스타일 벡터와 상기 제5 학습용 지오메트리 벡터를 합성하여 제3 학습용 합성 이미지를 생성하는 단계; 및 (v) 상기 제3 학습용 합성 이미지와 상기 제3 이미지의 오차인 제6 오차를 줄이는 방향으로 상기 스타일 인코더 및 상기 합성 디코더를 학습하는 단계;를 포함하는 구성으로 이루어진다.An invention according to an embodiment of the present invention is an invention for a learning method of an image synthesis system that generates a virtual image through image feature extraction and synthesis using deep learning, and in the learning method presented above, the style encoder and The synthesis decoder (r) setting the first image and the second image to a third image that is the same image; (s) generating a third learning style vector from the third image by the style encoder; , (t) the geometry encoder generating a fifth learning geometry vector from the third image;, (u) the synthesizing decoder synthesizing the third learning style vector and the fifth learning geometry vector for third learning generating a composite image; and (v) learning the style encoder and the synthesis decoder in a direction of reducing a sixth error between the third synthesized image for learning and the third image.
본 발명은 복수의 이미지 특징을 추출하여 하나의 합성 이미지를 생성할 수 있는 시스템과 이의 학습방법을 제공하여 이용자가 원하는 특징들을 내포하고 있는 가상의 이미지를 생성할 수 있다.The present invention provides a system capable of generating a single composite image by extracting features of a plurality of images and a learning method therefor, thereby generating a virtual image containing features desired by a user.
또한, 본 발명은 이미지 합성 시스템의 구성들을 순차적으로 학습하는 방법을 제시하여 효율적인 학습 방법을 제공할 수 있다.In addition, the present invention can provide an efficient learning method by suggesting a method of sequentially learning components of an image synthesis system.
또한, 합성 이미지를 생성하는 과정에서 이용자의 인위적인 보정을 통해 새로운 합성 이미지를 생성할 수 있다.In addition, in the process of generating a composite image, a new composite image may be created through user's artificial correction.
도 1은 본 발명의 일 실시예에 따른 복수 인물 이미지의 합성예들을 도시한 개념도이다.
도 2는 본 발명의 일 실시예에 따른 인물 이미지와 그로부터 추출한 인물 스케치의 예시도이다.
도 3은 본 발명의 일 실시예에 따른 이미지 합성 시스템의 구성도이다.
도 4는 본 발명의 일 실시예에 따른 지오메트리 인코더를 학습 개념도이다.
도 5는 본 발명의 일 실시예에 따른 스케치 인코더 및 스케치 디코더의 학습 개념도이다.
도 6은 본 발명의 다른 실시예에 따른 스타일 인코더 및 합성 디코더의 학습 개념도이다.
도 7은 본 발명의 일 실시예에 따른 이미지 합성 시스템 및 학습 방법에 이용될 수 있는 컴퓨터 장치의 구성 블록도이다.1 is a conceptual diagram illustrating synthesis examples of multiple person images according to an embodiment of the present invention.
2 is an exemplary view of a person image and a person sketch extracted therefrom according to an embodiment of the present invention.
3 is a configuration diagram of an image synthesis system according to an embodiment of the present invention.
4 is a conceptual diagram for learning a geometry encoder according to an embodiment of the present invention.
5 is a learning conceptual diagram of a sketch encoder and a sketch decoder according to an embodiment of the present invention.
6 is a learning conceptual diagram of a style encoder and a synthesis decoder according to another embodiment of the present invention.
7 is a configuration block diagram of a computer device that can be used in an image synthesis system and learning method according to an embodiment of the present invention.
본 발명의 이점 및 특징, 그리고 그것들을 달성하는 방법은 첨부되는 도면과 함께 상세하게 설명되는 실시예들을 참조하면 명확해질 것이다. 그러나 본 발명은 아래에서 제시되는 실시 예들로 한정되는 것이 아니라, 서로 다른 다양한 형태로 구현될 수 있고, 본 발명의 사상 및 기술 범위에 포함되는 모든 변환, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다. Advantages and features of the present invention, and methods of achieving them, will become clear with reference to the detailed description of the embodiments taken in conjunction with the accompanying drawings. However, it should be understood that the present invention is not limited to the embodiments presented below, but may be implemented in a variety of different forms, and includes all conversions, equivalents, and substitutes included in the spirit and scope of the present invention. .
아래에 제시되는 실시예들은 본 발명의 개시가 완전하도록 하며, 본 발 명이 속하는 기술분야에서 통상의 지식을 가진 자에게 발명의 범주를 완전하게 알려주기 위해 제공되는 것이다. 본 발명을 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 발명의 요지를 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다.The embodiments presented below are provided to make the disclosure of the present invention complete, and to fully inform those skilled in the art of the scope of the invention to which the present invention belongs. In describing the present invention, if it is determined that a detailed description of related known technologies may obscure the gist of the present invention, the detailed description will be omitted.
본 출원에서 사용한 용어는 단지 특정한 실시 예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다. Terms used in this application are only used to describe specific embodiments, and are not intended to limit the present invention. Singular expressions include plural expressions unless the context clearly dictates otherwise. In this application, the terms "include" or "have" are intended to designate that there is a feature, number, step, operation, component, part, or combination thereof described in the specification, but one or more other features It should be understood that the presence or addition of numbers, steps, operations, components, parts, or combinations thereof is not precluded.
본 발명의 실시 예에서 "통신", "통신망" 및 "네트워크"는 동일한 의미로 사용될 수 있다. 상기 세 용어 들은, 파일을 사용자 단말, 다른 사용자들의 단말 및 다운로드 서버 사이에서 송수신할 수 있는 유무선의 근거 리 및 광역 데이터 송수신망을 포함할 수 있다.In an embodiment of the present invention, "communication", "communication network" and "network" may be used in the same meaning. The above three terms may include wired and wireless local and wide area data transmission and reception networks capable of transmitting and receiving files between user terminals, terminals of other users, and download servers.
이하, 본 발명에 따른 실시 예들을 첨부된 도면을 참조하여 상세히 설명하기로 하며, 첨부 도면을 참조하여 설명함에 있어, 동일하거나 대응하는 구성 요소는 동일한 도면번호를 부여하고 이에 대한 중복되는 설명은 생략하기로 한다.Hereinafter, embodiments according to the present invention will be described in detail with reference to the accompanying drawings. In the description with reference to the accompanying drawings, the same or corresponding components are assigned the same reference numerals, and overlapping descriptions thereof are omitted. I'm going to do it.
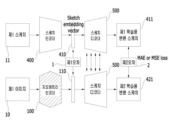
(실시예 1-1) 본 발명은 딥 러닝을 이용한 이미지의 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템에 대한 발명이며, 구체적으로 제1 이미지(10)로부터 스타일 벡터(210)를 추출하는 스타일 인코더(200);, 제2 이미지(20)로부터 지오메트리 벡터(110)를 추출하는 지오메트리 인코더(100);, 상기 지오메트리 벡터(110)와 상기 스타일 벡터(210)를 합성하여 합성 이미지(310)를 생성하는 합성 디코더(300);를 포함한다.(Embodiment 1-1) The present invention relates to an image synthesis system for generating a virtual image through feature extraction and synthesis of images using deep learning, and specifically, a
도3을 참조하면, 본 발명은 딥 러닝을 이용하여 복수의 이미지들의 특징을 추출하고 그 특징들을 합성하여 가상의 합성 이미지를 생성하는 이미지 합성 시스템에 대한 발명일 수 있다. 본 발명은 지오메트리 인코더(100), 스타일 인코더(200), 합성 디코더(300)를 포함할 수 있다.Referring to FIG. 3 , the present invention may relate to an image synthesis system that extracts features of a plurality of images using deep learning and synthesizes the features to generate a virtual composite image. The present invention may include a
지오메트리 인코더(100)는 인물의 이미지인 제2 이미지(20)로부터 컬러가 제외된 도 2와 같은 외관 스케치 정보가 포함되어 있는 지오메트리 벡터(110)를 추출하는 구성일 수 있다.The
스타일 인코더(200)는 제1 이미지(10)와는 다른 인물의 이미지인 제2 이미지(20)로부터 스타일, 컬러 등의 정보가 포함되어 있는 스타일 벡터(210)를 추출하는 구성일 수 있다.The
합성 디코더(300)는 지오메트리 벡터(110)와 스타일 벡터를 합성하여 제1 이미지(10)의 스타일, 컬러 정보와 제2 이미지(20)의 지오메트리 정보 또는 스케치 정보가 합성된 새로운 인물의 이미지를 생성하는 구성일 수 있다.The
본 발명은 위와 같이 서로 다른 두 이미지에서 각각 정보 일부를 추출하여 이들을 합성함으로써 새로운 이미지를 생성하는 시스템에 대한 것일 수 있다.As described above, the present invention may relate to a system for generating a new image by extracting a part of information from two different images and synthesizing them.
또한, 본 발명의 지오메트리 인코더(100), 스타일 인코더(200), 합성 디코더(300)는 후술하는 바와 같은 학습 방법에 의하여 학습되어 질 수 있다. 후술하는 학습방법에 의해서 본 발명을 이루는 각각의 구성들은 각각의 이미지로부터 원하는 정보들만을 추출하여 사용자의 의도에 맞게 새로운 이미지를 생성하는 구성조합으로 이루어지게 된다.In addition, the
또한, 본 발명은 후술하는 학습 방법에 의해 학습될 수 있는데, 학습의 핵심적인 특징 중 하나는 인물 이미지로부터 지오메트리 정보와 스타일 정보를 추출함에 있어, 서로의 영향을 배재하여 독립적으로 추출하는 것일 수 있다. 이를 통해 추출 및 합성의 예측 가능성을 확보할 수 있다.In addition, the present invention can be learned by a learning method described later. One of the key features of learning is to extract geometry information and style information from a person image independently by excluding each other's influence. . Through this, it is possible to secure the predictability of extraction and synthesis.
(실시예 2-1) 실시예 1-1의 이미지 합성 시스템의 학습 방법에 대한 것으로, 상기 지오메트리 인코더(100)는 (a) 스케치 인코더(400)가 상기 제1 이미지(10)로부터 추출한 제1 스케치(11)로부터 제1 학습용 지오메트리 벡터(410)를 생성하는 단계;, (b) 상기 제1 학습용 지오메트리 벡터(410)와 상기 지오메트리 벡터(110)의 오차인 제1 오차(1)를 감소시키는 방향으로 상기 지오메트리 인코더(100)를 학습하는 단계;, 를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Embodiment 2-1) In relation to the learning method of the image synthesis system of Embodiment 1-1, the
(실시예 2-2) 실시예 2-1에 있어서, 상기 (a)단계 및 상기 (b)단계를 반복 수행하여 상기 지오메트리 인코더(100)를 학습하는 이미지 합성 시스템의 학습 방법(Example 2-2) In Example 2-1, the learning method of the image synthesis system for learning the
본 발명은 지오메트리 인코더(100)를 학습하는 방법에 대한 발명이다. The present invention relates to a method for learning a geometry encoder (100).
스케치 인코더(400)는 스케치를 투입하면 지오메트리 정보로 추출 및 변환하는 구성이며, 스케치 디코더(500)는 지오메트리 정보를 투입하면 스케치로 추출 및 변환하는 구성일 수 있다. 지오메트리 벡터(110)는 지오메트리 정보가 담겨져있고, 컴퓨터로 읽을 수 있는 객체일 수 있다.The
이하 본 발명에 대해 구체적으로 설명한다.Hereinafter, the present invention will be described in detail.
본 발명에 의한 학습에 의하여 지오메트리 인코더(100)가 제1 이미지(10)로부터 추출한 지오메트리 벡터(110)와 스케치 인코더(400)가 제1 이미지(10)를 스케치한 제1 스케치(11)로부터 추출한 제1 학습용 지오메트리 벡터(410)의 오차가 줄어드는 방향으로 지오메트리 인코더(100)가 학습될 수 있다. The
인물 이미지인 제1 이미지(10)와 이로부터 추출한 스케치 이미지인 제1 스케치(11)는 도2에서 도시하는 바와 같이 색상 등의 스타일 정보를 제외한 인물의 스케치정보만을 포함하고 있는 것일 수 있다.As shown in FIG. 2 , the
포토샵 등의 일반적인 소프트웨어를 통해 이미지와 그 이미지에 대한 스케치 세트를 여러 세트를 준비한 후, 이미지는 지오메트리 인코더(100)에 투입하고, 스케치는 스케치 인코더(400)에 투입한 후, 각각에서 추출되는 지오메트리 벡터(110)와 제1 학습용 지오메트리 벡터(410)를 비교하여 그 오차를 감소시키는 방향으로 지오메트리 인코더(100)를 반복 학습하는 과정일 수 있다.After preparing several sets of images and sketch sets for the images through general software such as Photoshop, the images are input to the
본 발명의 학습과정에서는 지오메트리 인코더(100)만이 학습되며, 스케치 인코더(400)는 학습되어지지 않고 내부 알고리즘이 고정되어진 상태일 수 있다. 스케치 인코더(400)와 스케치 디코더(500)는 후술할 바와 같이 별도의 학습과정을 통해 이미 충분히 학습된 상태일 수 있다.In the learning process of the present invention, only the
본 발명에서 제1 이미지 및 제1 스케치를 이용하여 지오메트리 인코더(100)를 학습할 수 있는데, 제1 이미지 또는 제1 스케치는 특정한 이미지 또는 스케치를 의미하는 것이 아니며, 수 많은 이미지들과 그에 대응되는 스케치들을 학습 데이터로 하여 지오메트리 인코더(100)를 학습하는 것을 의미할 수 있다.In the present invention, the
(실시예 2-3) 실시예 2-1에 있어서, 상기 (a) 단계는 (a-1) 스케치 디코더(500)가 상기 제1 학습용 지오메트리 백터(410)로부터 제1 학습용 변환 스케치(411)를 생성하는 단계;, (a-2) 스케치 디코더(500)가 상기 지오메트리 벡터(110)로부터 제2 학습용 변환 스케치(421)를 생성하는 단계;, 를 포함하고, 상기 (b) 단계는 (b-1) 상기 제1 학습용 변환 스케치(411)와 상기 제2 학습용 변환 스케치(421)의 오차인 제2 오차(2)를 감소시키는 방향으로 상기 지오메트리 인코더(100)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 2-3) In Example 2-1, in the step (a), (a-1) the
(실시예 2-4) 실시예 2-3에 있어서, 상기 (a)단계 및 상기 (b)단계를 반복 수행하여 상기 지오메트리 인코더(100)를 학습하는 이미지 합성 시스템의 학습 방법(Example 2-4) In Example 2-3, the learning method of the image synthesis system for learning the
도 4를 참조하면, 본 발명은 지오메트리 인코더(100)를 학습하는 방법에 대한 것이다. 본 발명의 (a) 단계는 스케치 디코더(500)가 제1 학습용 지오메트리 벡터(410)로부터 제1 학습용 변환 스케치(411)를 생성하는 단계와 스케치 디코더(500)가 지오메트리 벡터(110)로부터 제2 학습용 변환 스케치(421)를 생성하는 단계를 더 포함할 수 있다.Referring to FIG. 4 , the present invention relates to a method for learning a
또한, (b) 단계는 제1 학습용 변환 스케치(411)와 제2 학습용 변환 스케치(421)를 비교하여 그 오차를 감소시키는 방향으로 지오메트리 인코더(100)를 학습하는 단계를 더 포함할 수 있다. In addition, step (b) may further include comparing the
이를 통해 지오메트리 인코더(100)를 학습시키는 입력값으로는 지오메트리 벡터(110)와 제1 학습용 지오메트리 벡터(410)와의 오차값인 제1 오차(1), 그리고 제1 학습용 변환 스케치(411)와 제2 학습용 변환 스케치(421)와의 오차값인 제2 오차(2) 등이 될 수 있다. As input values for learning the
또한, 지오메트리 인코더(100)를 학습시키는 입력값이 될 수 있는 것으로는 스케치 디코더(500)가 변환 스케치를 생성하는 중간 과정에서 생성되는 특징값(feature map)들의 오차일 수 있다. 보다 상세하게는 (a-1) 과정에서는 스케치 디코더(500)가 제1 학습용 지오메트리 벡터(410)로부터 제1 학습용 변환 스케치(411)를 생성하는데, 그 생성하는 과정에서 연속적으로 특징값들이 추출될 수 있다. 마찬가지로 (a-2) 과정에서도 스케치 디코더(500)가 지오메트리 벡터(110)로부터 제2 학습용 변환 스케치(421)를 생성하는 과정에서 특징값들이 추출될 수 있으며, 이러한 두 특징값들의 오차값들을 특징값 오차로 하여 지오메트리 인코더(100)를 학습시키는 입력값으로 이용할 수 있다.In addition, an input value for learning the
본 발명도 마찬가지로 지오메트리 인코더(100)를 학습하는 방법에 대한 것으로, 스케치 인코더(400)와 스케치 디코더(500)의 내부 알고리즘은 학습되거나 변화되지 않을 수 있다. 스케치 인코더(400)와 스케치 디코더(500)는 후술할 바와 같이 별도의 학습과정을 통해 충분히 학습된 상태일 수 있다.The present invention also relates to a method for learning the
(실시예 3-1) 실시예 2-4에 있어서, 상기 스케치 인코더(400) 및 상기 스케치 디코더(500)는 (c) 상기 스케치 인코더(400)가 인물 이미지로부터 추출한 인물 스케치(12)로부터 제2 학습용 지오메트리 벡터(420)를 생성하는 단계;, (d) 상기 스케치 디코더(500)가 상기 제2 학습용 지오메트리 벡터(420)로부터 제3 학습용 변환 스케치(431)를 생성하는 단계;, (e) 상기 인물 스케치와 상기 제3 학습용 변환 스케치(431)의 오차인 제3 오차(3)를 줄이는 방향으로 상기 스케치 인코더(400) 및 상기 스케치 디코더(500)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 3-1) In Example 2-4, the
(실시예 3-2) 실시예 3-1에 있어서, 상기 (c) 단계 및 상기 (e) 단계를 반복 수행하여 상기 스케치 인코더(400) 및 상기 스케치 디코더(500)를 학습하는 이미지 합성 시스템의 학습 방법.(Example 3-2) In Example 3-1, the image synthesis system for learning the
전술한 실시예들에서는 스케치 인코더(400)와 스케치 디코더(500)를 학습하지는 않았다. 보다 상세하게는 전술한 실시예들에서는 이미 스케치 인코더(400)와 스케치 디코더(500)가 충분히 학습되어 있었으며, 이러한 스케치 인코더(400)와 스케치 디코더(500)를 이용하여 지오메트리 인코더(100)를 학습하는 방법에 대한 발명이라고 할 수 있다.In the above-described embodiments, the
도 5를 참조하면, 본 발명은 스케치 인코더(400)와 스케치 디코더(500)를 학습하는 방법에 대한 것이다. 지오메트리 인코더(100)를 학습하기 위하여 스케치 인코더(400)와 스케치 디코더(500)는 이미 충분히 학습되어 있어야 하며, 본 발명은 지오메트리 인코더(100)의 학습보다 선결적으로 스케치 인코더(400) 및 디코더를 학습하는 발명에 대한 것이다.Referring to FIG. 5 , the present invention relates to a method for learning a
스케치 인코더(400)는 인물 이미지로부터 추출한 인물 스케치(12)로부터 제2 학습용 지오메트리 벡터(420)를 생성하는 단계를 수행할 수 있다.The
이후, 스케치 디코더(500)는 제2 학습용 지오메트리 벡터(420)로부터 제3 학습용 변환 스케치(431)를 생성하는 단계를 수행할 수 있다.Then, the
이후, 스케치 인코더(400)에 투입한 인물 스케치(12)와 스케치 디코더(500)가 생성한 제3 학습용 변환 스케치(431)를 비교하여 그 오차인 제3 오차(3)를 감소시키는 방향으로 스케치 인코더(400)와 스케치 디코더(500)를 학습할 수 있다.Thereafter, the
위와 같은 과정들을 복수의 인물 스케치(12)를 투입하면서 반복수행하여 스케치 인코더(400)와 스케치 디코더(500)를 학습시킬 수 있다.The above processes can be repeatedly performed while inputting a plurality of person sketches 12 to train the
위의 과정들을 통해 충분히 학습된 스케치 인코더(400)와 스케치 디코더(500)를 이용하게 된다면, 인물 스케치(12)를 스케치 인코더(400)에 투입하여 제2 학습용 지오메트리 벡터(420)를 생성하고, 제2 학습용 지오메트리 벡터(420)를 제공받아 스케치 디코더(500)가 제3 학습용 변환 스케치(431)를 생성하게되면, 스케치 인코더(400)에 투입한 인물 스케치(12)와 제3 학습용 변환 스케치(431)의 오차는 무시할 수 있을 정도로 작은 값을 갖게된다. If the
학습용 지오메트리 벡터나 학습용 변환 스케치는 그 자체가 목적이 아니라, 사용자가 원하는 모델을 학습하기 위한 수단에 불과한 객체일 수 있다.A geometry vector for learning or a transform sketch for learning may not be an object in itself, but an object that is merely a means for learning a model desired by a user.
상술한 일련의 과정을 통해 스케치 인코더(400)와 스케치 디코더(500)를 충분히 학습한 후, 이를 이용하여 지오메트리 인코더(100)를 학습할 수 있다.After sufficiently learning the
(실시예 4-1) 실시예 2-1에 있어서, 상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (f) 상기 스타일 인코더(200)가 상기 합성 이미지로부터 제1 학습용 스타일 벡터(220)를 생성하는 단계;, (g) 상기 지오메트리 인코더(100)가 상기 제1 이미지(10)로부터 제3 학습용 지오메트리 벡터(230)를 생성하는 단계;, (h) 상기 합성 디코더(300)가 상기 제1 학습용 스타일 벡터(220)와 상기 제3 학습용 지오메트리 벡터(230)를 합성하여 제1 학습용 합성 이미지(211)를 생성하는 단계;, (i) 상기 제1 학습용 합성 이미지(211)와 상기 제1 이미지(10)의 오차인 제4 오차(4)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 4-1) In Example 2-1, the
(실시예 4-2) 실시예 4-1에 있어서, 상기 (f)단계 및 상기 (i)단계를 반복 수행하여 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 이미지 합성 시스템의 학습 방법.(Example 4-2) In Example 4-1, the image synthesis system for learning the
본 발명은 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것이다. 스타일 인코더(200)는 합성 이미지로부터 제1 학습용 스타일 벡터(220)를 생성하는 단계를 수행할 수 있다.The present invention relates to a method for learning a style encoder (200) and a synthesis decoder (300). The
이후, 지오메트리 인코더(100)는 제1 이미지(10)로부터 제3 학습용 지오메트리 벡터(230)를 생성할 수 있다.Then, the
이후, 합성 디코더(300)는 제1 학습용 스타일 벡터(220)와 제3 학습용 지오메트리 벡터(230)를 합성하여 제1 학습용 합성 이미지(211)를 생성할 수 있다.Thereafter, the
이후, 제1 학습용 합성 이미지(211)와 제1 이미지(10)를 비교하여 그 오차를 줄이는 방향으로 스타일 인코더(200)와 합성 디코더(300)를 학습하는 단계를 수행한다.Thereafter, a step of learning the
전술한 학습 과정들에 대해 상세하게 설명하면, (f) 단계에서 투입되는 합성 이미지는 제1 이미지(10)의 스타일 벡터와 제2 이미지(20)의 지오메트리 벡터(110)를 합성한 이미지일 수 있다. (f) 단계에서는 스타일 인코더(200)가 이러한 합성 이미지를 투입받아 제1 학습용 스타일 벡터(220)를 생성하는 단계인데, 스타일 인코더(200)가 충분히 학습되었다면, 제1 학습용 스타일 벡터(220)는 제1 이미지(10)의 스타일 정보만을 함의하고 있는 벡터일 수 있다.If the above-described learning processes are described in detail, the synthesized image input in step (f) may be an image obtained by synthesizing the style vector of the
나아가 (g) 단계에서는 지오메트리 인코더(100)가 제1 이미지(10)를 투입받아 제3 학습용 지오메트리 벡터(230)를 생성하는 단계인데, 지오메트리 인코더(100)가 충분히 학습되어 있다면, 제3 학습용 지오메트리 벡터(230)는 제1 이미지(10)의 지오메트리 정보만을 함의하고 있는 벡터일 수 있다.Furthermore, in step (g), the
또한, (h) 단계에서는 합성 디코더(300)가 위에서 생성한 제1 학습용 스타일 벡터(220)와 제3 학습용 지오메트리 벡터(230)를 합성하여 제1 학습용 합성 이미지(211)를 생성할 수 있다. 마찬가지로 합성 디코더(300)가 충분히 학습되어 있다면, 제1 학습용 합성 이미지(211)는 제1 이미지(10)와 동일한 이미지일 수 있다. Also, in step (h), the
다만, 스타일 인코더(200)와 합성 디코더(300)가 충분히 학습되기 전이라면 제1 학습용 합성 이미지(211)는 제1 이미지(10)와 오차가 존재할 것이다.However, before the
따라서, 본 발명은 (i) 단계에서와 같이 이러한 오차를 줄이는 방향으로 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것일 수 있다.Accordingly, the present invention may relate to a method for learning the
또한, 본 발명은 전술한 (f) 단계 내지 (i) 단계를 반복 수행하여 스타일 인코더(200)와 합성 디코더(300)를 충분히 학습시키는 방법에 대한 것일 수 있다. (f) 단계 내지 (i)단계를 반복 수행하기 위하여 제1 이미지(10) 및 제2 이미지(20)를 충분히 확보하여야 할 수 있다. 이미지를 준비하는 과정은 온라인 및/또는 오프라인상으로 수행될 수 있으나, 이러한 과정은 본 발명의 핵심적인 특징이 아닐 수 있으므로 생략하기로 한다.In addition, the present invention may relate to a method for sufficiently learning the
(실시예 4-3) 실시예 4-2에 있어서, 상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (j) 상기 지오메트리 인코더(100)가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터(240)를 생성하는 단계;, (k) 상기 스타일 인코더(200)가 상기 제2 이미지(20)로부터 제2 학습용 스타일 벡터(250)를 생성하는 단계;, (l) 상기 합성 디코더(300)가 상기 제4 학습용 지오메트리 벡터(240)와 상기 제2 학습용 스타일 벡터(250)를 합성하여 제2 학습용 합성 이미지(221)를 생성하는 단계;, (m) 상기 제2 학습용 합성 이미지(221)와 상기 제2 이미지(20)의 오차인 제5 오차(5)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 4-3) In Example 4-2, the
(실시예 4-4) 실시예 4-3에 있어서, 상기 (j)단계 및 상기 (m)단계를 반복 수행하여 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 이미지 합성 시스템의 학습 방법.(Example 4-4) In Example 4-3, the image synthesis system for learning the
또한, 스타일 인코더(200)와 합성 디코더(300)를 학습하는 다른 네트워크도 수행될 수 있다. 전술한 (f) 단계 내지 (i) 단계에서는 제1 이미지(10)와 제1 학습용 합성 이미지(211)와의 오차값을 이용하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것이었다면, 본 발명은 제2 이미지(20)를 이용한 학습방법일 수 있다.Other networks that learn the
보다 구체적으로는, (j) 단계에서는 지오메트리 인코더(100)가 합성 이미지를 투입받아 제4 학습용 지오메트리 벡터(240)를 생성할 수 있다. 지오메트리 인코더(100)가 충분히 학습되어 있다면, 제4 학습용 지오메트리 벡터(240)는 제2 이미지(20)의 지오메트리 정보만을 함의하고 있는 벡터일 수 있다.More specifically, in step (j), the
이후, (k) 단계에서는 스타일 인코더(200)가 제2 이미지(20)를 투입받아 제2 학습용 스타일 벡터(250)를 생성할 수 있다. 스타일 인코더(200)가 충분히 학습되어 있다면, 제2 학습용 스타일 벡터(250)는 제2 이미지(20)의 스타일 정보만을 포함하고 있는 벡터일 수 있다. Then, in step (k), the
이후, (l) 단계에서는 합성 디코더(300)가 제4 학습용 지오메트리 벡터(240)와 제2 학습용 스타일 벡터(250)를 합성하여 제2 학습용 합성 이미지(221)를 생성할 수 있다. 합성 디코더(300)가 충분히 학습되어 있다면, 제2 학습용 합성 이미지(221)는 제2 이미지(20)와 동일한 이미지일 수 있다.Thereafter, in step (l), the synthesized
다만, 스타일 인코더(200)와 합성 디코더(300)가 충분히 학습되기 전이라면 제2 학습용 합성 이미지(221)는 제2 이미지(20)와 오차가 존재할 것이다. 그러한 오차값을 제5 오차(5)라고 한다.However, before the
따라서, 본 발명은 (m) 단계에서와 같이 이러한 오차를 줄이는 방향으로 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것일 수 있다.Accordingly, the present invention may relate to a method for learning the
또한, 본 발명은 전술한 (j) 단계 내지 (m) 단계를 반복 수행하여 스타일 인코더(200)와 합성 디코더(300)를 충분히 학습시키는 방법에 대한 것일 수 있다.In addition, the present invention may relate to a method for sufficiently learning the
(실시예 4-1) 및 (실시예 4-2)는 제1 이미지(10)와 대비한 오차(제4 오차(4))를 이용하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것이라면, (실시예 4-3) 및 (실시예 4-4)는 제4 오차(4)와 더불어 제2 이미지(20)와 대비한 오차(제5 오차(5))를 이용하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것일 수 있다.(Example 4-1) and (Example 4-2) learn the
(실시예 5-1) 실시예 2-1에 있어서, 상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (n) 상기 지오메트리 인코더(100)가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터(240)를 생성하는 단계;, (o) 상기 스타일 인코더(200)가 상기 제2 이미지(20)로부터 제2 학습용 스타일 벡터(250)를 생성하는 단계;, (p) 상기 합성 디코더(300)가 상기 제4 학습용 지오메트리 벡터(240)와 상기 제2 학습용 스타일 벡터(250)를 합성하여 제2 학습용 합성 이미지(221)를 생성하는 단계;, (q) 상기 제2 학습용 합성 이미지(221)와 상기 제2 이미지(20)의 오차인 제5 오차(5)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 5-1) In Example 2-1, the
(실시예 5-2) 실시예 5-1에 있어서, 상기 (n)단계 및 상기 (q)단계를 반복 수행하여 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 이미지 합성 시스템의 학습 방법.(Example 5-2) In Example 5-1, the image synthesis system for learning the
본 발명도 스타일 인코더(200) 및 합성 디코더(300)를 학습하는 방법에 대한 것이다. 이에 대한 설명은 (실시예 4-3) 및 (실시예 4-4)에서 기술한 것과 다름없으므로 그에 대한 설명으로 갈음할 수 있다. 다만, (실시예 4-3) 및 (실시예 4-4)는 제1 이미지(10)와 제1 학습용 합성 이미지(211)의 오차와 더불어서 제2 이미지(20)와 제2 학습용 합성 이미지(221)와의 오차를 모두 반영하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법이었다면, (실시예 5-1) 및 (실시예 5-2)는 제2 이미지(20)와 제2 학습용 합성 이미지(221)와의 오차만을 반영하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것일 수 있다. The present invention also relates to a method for learning the style encoder (200) and synthesis decoder (300). Since the explanation for this is the same as that described in (Example 4-3) and (Example 4-4), it can be replaced with a description thereof. However, in (Example 4-3) and (Example 4-4), the error between the
본 발명은 딥 러닝을 이용한 이미지의 특징 추출 및 합성을 통해 가상의 이미지를 생성하는 이미지 합성 시스템에 대한 발명이며, 구체적으로The present invention relates to an image synthesis system for generating a virtual image through feature extraction and synthesis of images using deep learning, and specifically
제1 이미지(10)로부터 지오메트리 벡터(110)를 추출하는 지오메트리 인코더(100);a geometry encoder (100) extracting a geometry vector (110) from the first image (10);
제2 이미지(20)로부터 스타일 벡터를 추출하는 스타일 인코더(200);a
상기 지오메트리 벡터(110)와 상기 스타일 벡터를 합성하여 합성 이미지를 생성하는 합성 디코더(300);를 포함한다.and a synthesizing
(실시예 6-1) 실시예 2-1에 있어서, 상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (r) 상기 제1 이미지(10) 및 제2 이미지(20)를 동일한 이미지인 제3 이미지(30)로 설정하는 단계;, (s) 상기 스타일 인코더(200)가 상기 제3 이미지(30)로부터 제3 학습용 스타일 벡터(260)를 생성하는 단계;, (t) 상기 지오메트리 인코더(100)가 상기 제3 이미지(30)로부터 제5 학습용 지오메트리 벡터(270)를 생성하는 단계;, (u) 상기 합성 디코더(300)가 상기 제3 학습용 스타일 벡터(260)와 상기 제5 학습용 지오메트리 벡터(270)를 합성하여 제3 학습용 합성 이미지(231)를 생성하는 단계;, (v) 상기 제3 학습용 합성 이미지(231)와 상기 제3 이미지(30)의 오차인 제6 오차(6)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.(Example 6-1) In Example 2-1, the
도 6을 참조하면, 본 발명은 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것이다. 구체적으로는, 전술한 실시예 4 및 실시예 5와는 다른 방법에 의하여 학습하는 방법에 대한 것일 수 있다. 실시예 4 및 실시예 5에서는 서로 다른 제1 이미지(10)와 제2 이미지(20)를 이용하여 합성 이미지를 생성한 후, 합성 이미지를 이용하여 다시 제1 학습용 합성 이미지(211) 및/또는 제2 학습용 합성 이미지(221)를 생성하고 그들의 오차값인 제4 오차 및/또는 제5 오차(5)를 이용하여 스타일 인코더(200)와 합성 디코더(300)를 학습하는 방법에 대한 것일 수 있다.Referring to FIG. 6 , the present invention relates to a method for learning a
그러나, 본 발명은 제1 이미지(10)와 제2 이미지(20)를 동일한 이미지인 제3 이미지(30)로 하고, 스타일 인코더(200)는 제3 이미지(30)로부터 제3 학습용 스타일 벡터(260)를 생성하고, 지오메트리 인코더(100)는 제3 이미지(30)로부터 제5 학습용 지오메트리 벡터(270)를 생성할 수 있다.However, in the present invention, the
이렇게 생성된 제3 학습용 스타일 벡터(260)와 제5 학습용 지오메트리 벡터(270)를 합성 디코더(300)가 합성하여 제3 학습용 합성 이미지(231)를 생성할 수 있다.The
제3 이미지(30)와 제3 학습용 합성 이미지(231)를 비교하여 그 오차값인 제6 오차(6)를 줄이는 방향으로 스타일 인코더(200)와 합성 디코더(300)를 학습할 수 있다.The
위와 같은 방법은 실시예 4 및 실시예 5에 대비하여 네트워크 구조가 비교적 간단하므로, 학습과정이 가볍고, 그 학습의 소요시간을 절약할 수 있는 장점을 확보할 수 있다.Since the above method has a relatively simple network structure compared to Example 4 and Example 5, the learning process is light and the advantage of saving the time required for the learning can be secured.
본 발명의 전체 명세서에서는 제1 오차(1) 내지 제6 오차(6)를 정의하였으며, 학습하고자 하는 구성, 예컨대, 지오메트리 인코더(100), 스타일 인코더(200), 합성 디코더(300) 등과 같은 구성을 학습시키는 원리는 오차들을 감소시키는 방향으로 피드백 작용을 수행하는 원리일 수 있다.In the entire specification of the present invention, the first error (1) to the sixth error (6) are defined, and a configuration to be learned, such as a
보다 구체적으로는 오차역전파(back propagation)방법을 이용하여 학습되어질 수 있으며, 이와 같은 방법은 당업자에게 알려져 있는 방법이므로, 구체적인 설명은 생략한다.More specifically, it can be learned using a back propagation method, and since such a method is known to those skilled in the art, a detailed description thereof will be omitted.
또한 최소제곱법(Least square method)을 이용할 수도 있으며, 이미지를 비교하여 그 오차값을 설정할 때, LAB 색차계산법을 이용할 수도 있다. 또한, 이미지 정보가 포함되어 있는 여러 벡터들의 인코딩, 디코딩, 합성 과정에서 생기는 특징맵(feature map)들을 연속적으로 비교하여 오차값을 계산하는 VGGNet(이하 "VGG")의 원리를 이용할 수도 있다. VGG오차 계산법은 이미지로 변환 또는 벡터로 변환되는 과정에서 레이어(layer)의 깊이를 늘리거나 줄이는 과정에서 생기는 특징맵들의 값들을 비교하는 것일 수 있다.In addition, the least square method may be used, and when comparing images and setting the error value, the LAB color difference calculation method may be used. In addition, the principle of VGGNet (hereinafter “VGG”), which calculates an error value by continuously comparing feature maps generated in the process of encoding, decoding, and synthesizing several vectors containing image information, may be used. The VGG error calculation method may compare values of feature maps generated in the process of increasing or decreasing the depth of a layer in the process of converting to an image or converting to a vector.
또한, 본 명세서에서 기재한 "학습용"은 그 자체가 목적이 아니라, 본 발명의 이미지 합성 시스템의 구성들을 학습시키기 위해 임시적으로 생성되는 객체일 수 있다.In addition, “learning” described in this specification is not a purpose in itself, but may be an object temporarily created to learn the configurations of the image synthesis system of the present invention.
궁극적으로 본 발명은 충분히 학습된 지오메트리 인코더(100), 스타일 인코더(200), 합성 디코더(300)를 이용하여 임의의 두 인물 이미지에 대하여 지오메트리 특징, 스타일 특징을 각각 추출하여 합성함으로써 각각의 특징들이 결합된 새로운 합성 이미지를 생성하는 시스템에 대한 것일 수 있다.Ultimately, the present invention extracts and synthesizes geometric features and style features from two arbitrary person images using the sufficiently learned
또한, 전술한 이미지 합성 시스템의 학습 방법에 대한 발명일 수 있으며, 본 발명에 의한 특징적인 학습 방법을 채용하여 이미지 합성 시스템을 학습할 수 있다.In addition, it may be an invention for a learning method of the above-described image synthesis system, and the image synthesis system may be learned by employing a characteristic learning method according to the present invention.
마지막으로, 도 7은 본 발명에 따른 딥 러닝을 이용한 이미지의 특징 추출 및 합성 시스템 및 이의 학습 방법을 수행하기 위해 채용될 수 있는 범용 컴퓨터 장치의 내부 블록도이다. 컴퓨터 장치(900)는 램(RAM: Random Access Memory)(920)과 롬(ROM: Read Only Memory)(930)을 포함하는 주기억장치와 연결되는 하나 이상의 프로세서(910)를 포함한다. 프로세서(910)는 중앙처리장치(CPU)로 불리기도 한다. 프로세서는 학습 방법을 수행시키는 구성으로 학습의 주체가 될 수 있다. 본 기술분야에서 널리 알려져 있는 바와 같이, 롬(930)은 데이터(data)와 명령(instruction)을 단방향성으로 CPU에 전송하는 역할을 하며, 램(920)은 통상적으로 데이터와 명령을 양방향성으로 전송하는데 사용된다. 램(920) 및 롬(930)은 컴퓨터 판독 가능 매체의 어떠한 적절한 형태를 포함할 수 있다. 대용량 기억장치(Mass Storage)(940)는 양방향성으로 프로세서(910)와 연결되어 추가적인 데이터 저장 능력을 제공하며, 상기된 컴퓨터 판독 가능 기록 매체 중 어떠한 것일 수 있다. 대용량 기억장치(940)는 프로그램, 데이터 등을 저장하는데 사용되며, 통상적으로 주기억장치보다 속도가 느린 하드 디스크와 같은 보조기억장치이다. CD 롬(960)과 같은 특정 대용량 기억장치가 사용될 수도 있다. 프로세서(910)는 비디오 모니터, 트랙볼, 마우스, 키보드, 마이크 로폰, 터치스크린형 디스플레이, 카드 판독기, 자기 또는 종이 테이프 판독기, 음성 또는 필기 인식기, 조이스틱, 또는 기타 공지된 컴퓨터 입출력장치와 같은 하나 이상의 입출력 인터페이스(950)와 연결된다. 마지막으로, 프로세서(910)는 네트워크 인터페이스(970)를 통하여 유선 또는 무선 통신 네트워크에 연결될 수 있다. 이러한 네트워크 연결을 통하여 상기된 방법의 절차를 수행할 수 있다. 상기된 장치 및 도구는 컴퓨터 하드웨어 및 소프트웨어 기술 분야의 당업자에게 잘 알려져 있다.Finally, FIG. 7 is an internal block diagram of a general-purpose computer device that can be employed to perform a system for extracting and synthesizing features of an image using deep learning and a learning method thereof according to the present invention. The
본 발명의 명세서(특히 특허청구범위에서)에서 "상기"의 용어 및 이와 유사한 지시 용어의 사용은 단수 및 복수 모두에 해당하는 것일 수 있다. 또한, 본 발명에서 범위(range)를 기재한 경우 상기 범위에 속하는 개별적인 값을 적용한 발명을 포함하는 것으로서(이에 반하는 기재가 없다면), 발명의 상세한 설명에 상기 범위를 구성하는 각 개별적인 값을 기재한 것과 같다. In the specification of the present invention (particularly in the claims), the use of the term "above" and similar indicating terms may correspond to both singular and plural. In addition, when a range is described in the present invention, it includes an invention in which individual values belonging to the range are applied (unless there is a description to the contrary), and each individual value constituting the range is described in the detailed description of the invention Same as
본 발명에 따른 방법을 구성하는 단계들에 대하여 명백하게 순서를 기재하거나 반하는 기재가 없다면, 상기 단계들은 적당한 순서로 행해질 수 있다. 반드시 상기 단계들의 기재 순서에 따라 본 발명이 한정되는 것은 아니다. 본 발명에서 모든 예들 또는 예시적인 용어(예들 들어, 등등)의 사용은 단순히 본 발명을 상세히 설명하기 위한 것으로서 특허청구범위에 의해 한정되지 않는 이상 상기 예들 또는 예시적인 용어로 인해 본 발명의 범위가 한정되는 것은 아니다. 또한, 당업자는 다양한 수정, 조합 및 변경이 부가된 특허청구범위 또는 그 균등물의 범주 내에서 설계 조건 및 팩터에 따라 구성될 수 있음을 알 수 있다. The steps constituting the method according to the present invention may be performed in any suitable order unless an order is explicitly stated or stated to the contrary. The present invention is not necessarily limited according to the order of description of the steps. The use of all examples or exemplary terms (eg, etc.) in the present invention is simply to explain the present invention in detail, and the scope of the present invention is limited due to the examples or exemplary terms unless limited by the claims. it is not going to be In addition, those skilled in the art can appreciate that various modifications, combinations and changes can be made according to design conditions and factors within the scope of the appended claims or equivalents thereof.
따라서, 본 발명의 사상은 상기 설명된 실시예에 국한되어 정해져서는 아니되며, 후술하는 특허청구범위뿐만 아니라 이 특허청구범위와 균등한 또는 이로부터 등가적으로 변경된 모든 범위는 본 발명의 사상의 범주에 속한다고 할 것이다Therefore, the spirit of the present invention should not be limited to the above-described embodiments and should not be determined, and all scopes equivalent to or equivalently changed from the claims as well as the claims to be described later are within the scope of the spirit of the present invention. would be said to belong to
10 : 제1 이미지 20 : 제2 이미지
30 : 제3 이미지 100 : 지오메트리 인코더
110 : 지오메트리 벡터 200 : 스타일 인코더
210 : 스타일 벡터 220 : 제1 학습용 스타일 벡터
230 : 제3 학습용 지오메트리 벡터 240 : 제4 학습용 지오메트리 벡터
250 : 제2 학습용 스타일 벡터 260 : 제3 학습용 스타일 벡터
270 : 제5 학습용 지오메트리 벡터 300 : 합성 디코더
400 : 스케치 인코더 410 : 제1 학습용 지오메트리 벡터
420 : 제2 학습용 지오메트리 벡터 411 : 제1 학습용 변환 스케치
421 : 제2 학습용 변환 스케치 431 : 제3 학습용 변환 스케치10: first image 20: second image
30: third image 100: geometry encoder
110: geometry vector 200: style encoder
210: style vector 220: style vector for first learning
230: geometry vector for third learning 240: geometry vector for fourth learning
250: style vector for second learning 260: style vector for third learning
270: geometry vector for fifth learning 300: synthesis decoder
400: sketch encoder 410: geometry vector for first learning
420: Geometry vector for second learning 411: Transformation sketch for first learning
421: conversion sketch for second learning 431: conversion sketch for third learning
Claims (11)
상기 지오메트리 인코더(100)는,
(a) 스케치 인코더(400)가 상기 제1 이미지(10)로부터 추출한 제1 스케치(11)로부터 제1 학습용 지오메트리 벡터(410)를 생성하는 단계; 및
(b) 상기 제1 학습용 지오메트리 벡터(410)와 상기 지오메트리 벡터(110)의 오차인 제1 오차(1)를 감소시키는 방향으로 상기 지오메트리 인코더(100)를 학습하는 단계;를 통해 학습되고,
상기 (a) 단계는,
(a-1) 스케치 디코더(500)가 상기 제1 학습용 지오메트리 백터로부터 제1 학습용 변환 스케치(411)를 생성하는 단계; 및
(a-2) 스케치 디코더(500)가 상기 지오메트리 벡터(110)로부터 제2 학습용 변환 스케치(421)를 생성하는 단계;를 포함하고,
상기 (b) 단계는,
(b-1) 상기 제1 학습용 변환 스케치(411)와 상기 제2 학습용 변환 스케치(421)의 오차인 제2 오차(2)를 감소시키는 방향으로 상기 지오메트리 인코더(100)를 학습하는 단계;를 포함하며,
상기 스타일 인코더(200) 및 상기 합성 디코더(300)는,
(f) 상기 스타일 인코더(200)가 상기 합성 이미지로부터 제1 학습용 스타일 벡터(220)를 생성하는 단계;
(g) 상기 지오메트리 인코더(100)가 상기 제1 이미지(10)로부터 제3 학습용 지오메트리 벡터(230)를 생성하는 단계;
(h) 상기 합성 디코더(300)가 상기 제1 학습용 스타일 벡터(220)와 상기 제3 학습용 지오메트리 벡터(230)를 합성하여 제1 학습용 합성 이미지(211)를 생성하는 단계; 및
(i) 상기 제1 학습용 합성 이미지(211)와 상기 제1 이미지(10)의 오차인 제4 오차(4)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 통해 학습되고,
상기 지오메트리 인코더(100)는 특징값 오차를 감소시키는 방향으로도 학습되며,
상기 특징값 오차는 상기 (a-1) 단계에서 상기 스케치 디코더(500)가 상기 제1 학습용 지오메트리 벡터(410)로부터 제1 학습용 변환 스케치(411)를 생성하는 과정에서 연속적으로 추출되는 특징값(feature map)과 상기 (a-2) 단계에서 상기 스케치 디코더(500)가 상기 지오메트리 벡터(110)로부터 제2 학습용 변환 스케치(421)를 생성하는 과정에서 연속적으로 추출되는 특징값(feature map)의 오차값으로 정의되는, 이미지 합성 시스템의 학습 방법.
A style encoder (200) extracting a style vector (210) from a first image (10), a geometry encoder (100) extracting a geometry vector (110) from a second image (20), and the geometry vector (110) and the above In the learning method of an image synthesis system including a synthesis decoder 300 generating a synthesis image 310 by synthesizing a style vector 210,
The geometry encoder 100,
(a) generating a first learning geometry vector 410 from the first sketch 11 extracted from the first image 10 by the sketch encoder 400; and
(b) learning the geometry encoder 100 in a direction that reduces a first error 1, which is an error between the first learning geometry vector 410 and the geometry vector 110; Learning through;
In step (a),
(a-1) generating, by the sketch decoder 500, a transform sketch 411 for first training from the geometry vector for first training; and
(a-2) generating, by the sketch decoder 500, a transformation sketch 421 for second learning from the geometry vector 110;
In step (b),
(b-1) learning the geometry encoder 100 in a direction that reduces a second error (2), which is an error between the first transformation sketch 411 for learning and the transformation sketch 421 for second learning; contains,
The style encoder 200 and the synthesis decoder 300,
(f) generating, by the style encoder 200, a first learning style vector 220 from the synthesized image;
(g) generating a third learning geometry vector 230 from the first image 10 by the geometry encoder 100;
(h) synthesizing, by the synthesis decoder 300, the first learning style vector 220 and the third learning geometry vector 230 to generate a first learning synthesis image 211; and
(i) learning the style encoder 200 and the synthesis decoder 300 in a direction of reducing a fourth error 4 that is an error between the first synthetic image 211 for learning and the first image 10 is learned through;
The geometry encoder 100 is also learned in the direction of reducing the feature value error,
The feature value error is a feature value ( feature map) and the feature value (feature map) continuously extracted in the process of generating the second learning conversion sketch 421 from the geometry vector 110 by the sketch decoder 500 in step (a-2) A learning method of an image synthesis system, defined as an error value.
상기 (a)단계 및 상기 (b)단계를 반복 수행하여 상기 지오메트리 인코더(100)를 학습하는 이미지 합성 시스템의 학습 방법.
The method of claim 2,
A learning method of an image synthesis system for learning the geometry encoder 100 by repeatedly performing steps (a) and (b).
상기 스케치 인코더(400) 및 상기 스케치 디코더(500)는 (c) 상기 스케치 인코더(400)가 인물 이미지로부터 추출한 인물 스케치(12)로부터 제2 학습용 지오메트리 벡터(420)를 생성하는 단계;
(d) 상기 스케치 디코더(500)가 상기 제2 학습용 지오메트리 벡터(420)로부터 제3 학습용 변환 스케치(431)를 생성하는 단계; 및
(e) 상기 인물 스케치와 상기 제3 학습용 변환 스케치(431)의 오차인 제3 오차(3)를 줄이는 방향으로 상기 스케치 인코더(400) 및 상기 스케치 디코더(500)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.
The method of claim 4,
The sketch encoder 400 and the sketch decoder 500 perform (c) generating a second learning geometry vector 420 from the person sketch 12 extracted from the person image by the sketch encoder 400;
(d) generating, by the sketch decoder 500, a third transform sketch 431 from the second geometry vector 420 for training; and
(e) learning the sketch encoder 400 and the sketch decoder 500 in a direction of reducing a third error 3, which is an error between the character sketch and the third conversion sketch 431 for learning; A learning method of an image synthesis system that is trained by the method.
상기 (f)단계 및 상기 (i)단계를 반복 수행하여 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 이미지 합성 시스템의 학습 방법.
The method of claim 2,
A learning method of an image synthesis system for learning the style encoder 200 and the synthesis decoder 300 by repeatedly performing steps (f) and (i).
상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (j) 상기 지오메트리 인코더(100)가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터(240)를 생성하는 단계;
(k) 상기 스타일 인코더(200)가 상기 제2 이미지(20)로부터 제2 학습용 스타일 벡터(250)를 생성하는 단계;
(l) 상기 합성 디코더(300)가 상기 제4 학습용 지오메트리 벡터(240)와 상기 제2 학습용 스타일 벡터(250)를 합성하여 제2 학습용 합성 이미지(221)를 생성하는 단계; 및
(m) 상기 제2 학습용 합성 이미지(221)와 상기 제2 이미지(20)의 오차인 제5 오차(5)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.
The method of claim 7,
The style encoder 200 and the synthesis decoder 300 may include (j) the geometry encoder 100 generating a fourth learning geometry vector 240 from the synthesis image;
(k) generating a second learning style vector 250 from the second image 20 by the style encoder 200;
(l) generating a second learning synthesis image 221 by synthesizing the fourth learning geometry vector 240 and the second learning style vector 250 by the synthesis decoder 300; and
(m) learning the style encoder 200 and the synthesis decoder 300 in a direction of reducing a fifth error 5 that is an error between the second synthesized image 221 for learning and the second image 20 A learning method of an image synthesis system that is learned by a method including;
상기 (j)단계 및 상기 (m)단계를 반복 수행하여 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 이미지 합성 시스템의 학습 방법.
The method of claim 8,
A learning method of an image synthesis system for learning the style encoder 200 and the synthesis decoder 300 by repeatedly performing steps (j) and (m).
상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (n) 상기 지오메트리 인코더(100)가 상기 합성 이미지로부터 제4 학습용 지오메트리 벡터(240)를 생성하는 단계;
(o) 상기 스타일 인코더(200)가 상기 제2 이미지(20)로부터 제2 학습용 스타일 벡터(250)를 생성하는 단계;
(p) 상기 합성 디코더(300)가 상기 제4 학습용 지오메트리 벡터(240)와 상기 제2 학습용 스타일 벡터(250)를 합성하여 제2 학습용 합성 이미지(221)를 생성하는 단계; 및
(q) 상기 제2 학습용 합성 이미지(221)와 상기 제2 이미지(20)의 오차인 제5 오차(5)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.
The method of claim 2,
The style encoder 200 and the synthesis decoder 300 include (n) the geometry encoder 100 generating a fourth learning geometry vector 240 from the synthesis image;
(o) generating a second learning style vector 250 from the second image 20 by the style encoder 200;
(p) generating a second learning synthesis image 221 by synthesizing the fourth learning geometry vector 240 and the second learning style vector 250 by the synthesis decoder 300; and
(q) learning the style encoder 200 and the synthesis decoder 300 in a direction of reducing a fifth error 5 that is an error between the second synthesized image 221 for learning and the second image 20 A learning method of an image synthesis system that is learned by a method including;
상기 스타일 인코더(200) 및 상기 합성 디코더(300)는 (r) 상기 제1 이미지(10) 및 제2 이미지(20)를 동일한 이미지인 제3 이미지(30)로 설정하는 단계;
(s) 상기 스타일 인코더(200)가 상기 제3 이미지(30)로부터 제3 학습용 스타일 벡터(260)를 생성하는 단계;
(t) 상기 지오메트리 인코더(100)가 상기 제3 이미지(30)로부터 제5 학습용 지오메트리 벡터(270)를 생성하는 단계;
(u) 상기 합성 디코더(300)가 상기 제3 학습용 스타일 벡터(260)와 상기 제5 학습용 지오메트리 벡터(270)를 합성하여 제3 학습용 합성 이미지(231)를 생성하는 단계; 및
(v) 상기 제3 학습용 합성 이미지(231)와 상기 제3 이미지(30)의 오차인 제6 오차(6)를 줄이는 방향으로 상기 스타일 인코더(200) 및 상기 합성 디코더(300)를 학습하는 단계;를 포함하는 방법으로 학습되는 이미지 합성 시스템의 학습 방법.
The method of claim 2,
The style encoder 200 and the synthesis decoder 300 step (r) setting the first image 10 and the second image 20 to a third image 30 that is the same image;
(s) generating a third learning style vector 260 from the third image 30 by the style encoder 200;
(t) generating a fifth learning geometry vector 270 from the third image 30 by the geometry encoder 100;
(u) synthesizing, by the synthesis decoder 300, the third learning style vector 260 and the fifth learning geometry vector 270 to generate a third learning synthesis image 231; and
(v) learning the style encoder 200 and the synthesis decoder 300 in a direction of reducing a sixth error 6 that is an error between the third synthesized image 231 for learning and the third image 30 A learning method of an image synthesis system that is learned by a method including;
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020220053447A KR102543451B1 (en) | 2022-04-29 | 2022-04-29 | Image feature extraction and synthesis system using deep learning and its learning method |
| KR1020230073814A KR102562386B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image synthesis system |
| KR1020230073819A KR102562387B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image feature extraction and synthesis system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020220053447A KR102543451B1 (en) | 2022-04-29 | 2022-04-29 | Image feature extraction and synthesis system using deep learning and its learning method |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020230073819A Division KR102562387B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image feature extraction and synthesis system |
| KR1020230073814A Division KR102562386B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image synthesis system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102543451B1 true KR102543451B1 (en) | 2023-06-13 |
Family
ID=86762470
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020220053447A Active KR102543451B1 (en) | 2022-04-29 | 2022-04-29 | Image feature extraction and synthesis system using deep learning and its learning method |
| KR1020230073814A Active KR102562386B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image synthesis system |
| KR1020230073819A Active KR102562387B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image feature extraction and synthesis system |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020230073814A Active KR102562386B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image synthesis system |
| KR1020230073819A Active KR102562387B1 (en) | 2022-04-29 | 2023-06-08 | Learning method for image feature extraction and synthesis system |
Country Status (1)
| Country | Link |
|---|---|
| KR (3) | KR102543451B1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117611953A (en) * | 2024-01-18 | 2024-02-27 | 深圳思谋信息科技有限公司 | Graphic code generation method, graphic code generation device, computer equipment and storage medium |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102229572B1 (en) * | 2019-11-28 | 2021-03-18 | 영남대학교 산학협력단 | Apparatus and method for image style transfer |
| KR20210054907A (en) | 2019-11-06 | 2021-05-14 | 엘지전자 주식회사 | Method and apparatus for editing image |
| KR20210062274A (en) | 2019-11-21 | 2021-05-31 | 주식회사 엔씨소프트 | Device and method for image automatic generation |
| KR20210078813A (en) | 2019-12-19 | 2021-06-29 | 엘지전자 주식회사 | An artificial intelligence apparatus for synthesizing image and method thereof |
| KR20210108529A (en) * | 2020-02-25 | 2021-09-03 | 주식회사 하이퍼커넥트 | Image Reenactment Apparatus, Method and Computer Readable Recording Medium Thereof |
| KR102332114B1 (en) * | 2020-11-24 | 2021-12-01 | 한국과학기술원 | Image processing method and apparatus thereof |
| KR20210147507A (en) * | 2020-05-29 | 2021-12-07 | 네이버 주식회사 | Image generation system and image generation method using the system |
| KR20220011100A (en) | 2020-07-20 | 2022-01-27 | 펄스나인 주식회사 | Digital human generation system and method through face image search |
| KR20220027565A (en) * | 2020-08-27 | 2022-03-08 | 연세대학교 산학협력단 | Multiple domain arbitrary style transfer with single model and method thereof |
-
2022
- 2022-04-29 KR KR1020220053447A patent/KR102543451B1/en active Active
-
2023
- 2023-06-08 KR KR1020230073814A patent/KR102562386B1/en active Active
- 2023-06-08 KR KR1020230073819A patent/KR102562387B1/en active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210054907A (en) | 2019-11-06 | 2021-05-14 | 엘지전자 주식회사 | Method and apparatus for editing image |
| KR20210062274A (en) | 2019-11-21 | 2021-05-31 | 주식회사 엔씨소프트 | Device and method for image automatic generation |
| KR102229572B1 (en) * | 2019-11-28 | 2021-03-18 | 영남대학교 산학협력단 | Apparatus and method for image style transfer |
| KR20210078813A (en) | 2019-12-19 | 2021-06-29 | 엘지전자 주식회사 | An artificial intelligence apparatus for synthesizing image and method thereof |
| KR20210108529A (en) * | 2020-02-25 | 2021-09-03 | 주식회사 하이퍼커넥트 | Image Reenactment Apparatus, Method and Computer Readable Recording Medium Thereof |
| KR20210147507A (en) * | 2020-05-29 | 2021-12-07 | 네이버 주식회사 | Image generation system and image generation method using the system |
| KR20220011100A (en) | 2020-07-20 | 2022-01-27 | 펄스나인 주식회사 | Digital human generation system and method through face image search |
| KR20220027565A (en) * | 2020-08-27 | 2022-03-08 | 연세대학교 산학협력단 | Multiple domain arbitrary style transfer with single model and method thereof |
| KR102332114B1 (en) * | 2020-11-24 | 2021-12-01 | 한국과학기술원 | Image processing method and apparatus thereof |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117611953A (en) * | 2024-01-18 | 2024-02-27 | 深圳思谋信息科技有限公司 | Graphic code generation method, graphic code generation device, computer equipment and storage medium |
| CN117611953B (en) * | 2024-01-18 | 2024-08-13 | 深圳思谋信息科技有限公司 | Graphic code generation method, graphic code generation device, computer equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102562386B1 (en) | 2023-08-01 |
| KR102562387B1 (en) | 2023-08-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115311389B (en) | A multimodal visual cueing technology representation learning method based on pre-trained models | |
| KR102403494B1 (en) | Method for learning Cross-domain Relations based on Generative Adversarial Network | |
| JP6962747B2 (en) | Data synthesizer and method | |
| CN114360502B (en) | Speech recognition model processing method, speech recognition method and device | |
| CN112767554A (en) | Point cloud completion method, device, equipment and storage medium | |
| KR20200065433A (en) | Style Trasnfer Model and Apparatus for Style Trasnfer of Composite Image based on Photo Montage | |
| KR20200092491A (en) | Apparatus and method for generating manipulated image based on natural language and system using the same | |
| CN116189265B (en) | Sketch face recognition method, device and equipment based on lightweight semantic transducer model | |
| WO2025242036A1 (en) | Document information extraction method and apparatus based on image-text modal fusion, and storage medium | |
| CN115797503B (en) | An Adaptive Image Editing Method Based on Latent Space Operations and Text Guidance | |
| CN105989067A (en) | Method for generating text abstract from image, user equipment and training server | |
| WO2025031067A1 (en) | Image processing method and apparatus, device, and computer readable storage medium | |
| JP7205646B2 (en) | Output method, output program, and output device | |
| WO2024160178A1 (en) | Image translation model training method, image translation method, device, and storage medium | |
| KR102562386B1 (en) | Learning method for image synthesis system | |
| CN113065417A (en) | Scene text recognition method based on generation countermeasure style migration | |
| CN120953442A (en) | A unified method and system for image generation and understanding based on joint diffusion modeling | |
| CN120494125A (en) | Training method for multi-modal model, image recognition method and related products | |
| Watanabe et al. | Generative adversarial network including referring image segmentation for text-guided image manipulation | |
| CN117274728B (en) | Model training method and related device | |
| Chae et al. | Semantic image synthesis with unconditional generator | |
| JP2025535488A (en) | Facial modeling model training method and device, modeling method and device, electronic device, and computer program | |
| CN118116384A (en) | A method, device and storage medium for speech recognition | |
| ÇIÇEK et al. | Urban map generation in artist’s style using generative adversarial networks (GAN) | |
| CN118378078B (en) | A deep dataset distillation and lightweight method using GAN prior enhancement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20220429 |
|
| PA0201 | Request for examination | ||
| PA0302 | Request for accelerated examination |
Patent event date: 20220429 Patent event code: PA03022R01D Comment text: Request for Accelerated Examination |
|
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20230110 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20230518 |
|
| A107 | Divisional application of patent | ||
| PA0107 | Divisional application |
Comment text: Divisional Application of Patent Patent event date: 20230608 Patent event code: PA01071R01D |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20230609 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20230609 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |