JP7141133B2 - Information processing device, information processing method and information processing program - Google Patents
Information processing device, information processing method and information processing program Download PDFInfo
- Publication number
- JP7141133B2 JP7141133B2 JP2020087379A JP2020087379A JP7141133B2 JP 7141133 B2 JP7141133 B2 JP 7141133B2 JP 2020087379 A JP2020087379 A JP 2020087379A JP 2020087379 A JP2020087379 A JP 2020087379A JP 7141133 B2 JP7141133 B2 JP 7141133B2
- Authority
- JP
- Japan
- Prior art keywords
- document
- unit
- similarity
- contract
- comparison
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images













Landscapes
- Document Processing Apparatus (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
特許法第30条第2項適用 1)ウェブサイトの掲載日 2019年5月20日 2)ウェブサイトのアドレス https://prtimes.jp/main/html/rd/p/000000005.000037680.html 3)公開者 株式会社PR TIMES 1)ウェブサイトの掲載日 2019年5月29日 2)ウェブサイトのアドレス https://www.cloudsign.jp/media/20190529-lawgue/ 3)公開者 弁護士ドットコム株式会社 1)ウェブサイトの掲載日 2019年12月18日 2)ウェブサイトのアドレス https://jp.techcrunch.com/2019/12/18/jlsi-fundraising/ 3)公開者 ベライゾンメディア・ジャパン株式会社 1)ウェブサイトの掲載日 2020年3月5日 2)ウェブサイトのアドレス https://lawgue.com/news/94 3)公開者 堀口圭、宮坂豪及び植木智之 1)ウェブサイトの掲載日 2019年5月20日 2)ウェブサイトのアドレス https://lawgue.com/ 3)公開者 堀口圭、宮坂豪及び植木智之Application of Article 30,
本発明は、情報処理装置、情報処理方法及び情報処理プログラムに関する。 The present invention relates to an information processing device, an information processing method, and an information processing program.
一般的に、取引に際して契約書を作成するが、契約書は取引に影響するため非常に重要である。このため、契約書作成を支援するためのシステムが従来から開発されている。例えば、特許文献1には、複数の法令に含まれる複数の法律条文について、条文毎の文書ベクトルを生成する処理と、各条文の文書ベクトル同士を比較し、所定の閾値以上の類似性を有する複数の条文を合体させた条文グループを生成する処理と、各条文グループについて、条文グループ毎の文書ベクトルを生成する処理と、入力された契約書データについて、条項毎の文書ベクトルを生成する処理と、この条項毎の文書ベクトルと、上記条文グループ毎の文書ベクトルとを比較し、類似する条文グループに含まれる各法律条文を、当該契約条項の関連条文と特定する処理と、契約条項毎に関連条文を列記した分析結果画面を生成する処理を実行する契約書分析システムが開示されている。 Contracts are generally drawn up for transactions, and contracts are very important because they affect transactions. For this reason, conventionally, systems have been developed to support the creation of contracts. For example, Patent Literature 1 discloses a process of generating a document vector for each of a plurality of legal provisions included in a plurality of laws and regulations, and comparing the document vectors of each of the provisions with each other to obtain a similarity equal to or greater than a predetermined threshold. A process of generating a clause group by combining a plurality of clauses, a process of generating a document vector for each clause group for each clause group, and a process of generating a document vector for each clause for the input contract data. , the document vector for each clause is compared with the document vector for each clause group, and each legal clause included in a similar clause group is identified as a related clause of the relevant contract clause; A contract analysis system is disclosed that executes a process of generating an analysis result screen listing clauses.
上記契約書分析システムでは、ユーザが契約書データを入力することにより、各契約条項に関連が深い法律条文が自動的に提示されるため、法律に疎いユーザであっても関連条文を事前にチェックすることが可能となるとしている。このように、上記契約書分析システムでは、作成中の契約に関連が深い法律条文が自動的に提示されるものの過去の契約書と比較しながら契約書を作成することができないなど利便性の点において向上の余地がある。 In the above contract analysis system, when the user enters contract data, the legal texts closely related to each contract clause are automatically presented, so even users who are unfamiliar with the law can check the related clauses in advance. It is possible to do so. In this way, the above contract analysis system automatically presents legal texts that are closely related to the contract being drafted, but it is not possible to create a contract while comparing it with past contracts. There is room for improvement in
本発明は、上記課題に鑑みてなされたものであり、利便性の高い情報処理装置、情報処理方法及び情報処理プログラムを提供することを目的とする。 The present invention has been made in view of the above problems, and an object of the present invention is to provide a highly convenient information processing apparatus, information processing method, and information processing program.
上記課題を解決するため、本発明の情報処理装置は、第1文書と、第1文書とは異なる第2文書との類似性を所定領域単位で算出する算出部と、算出部で算出された類似性に応じて、第1文書と、第2文書とを所定領域単位で比較する比較部と、比較部での比較結果に応じて、第1文書と第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する出力部とを備える。 In order to solve the above-described problems, an information processing apparatus of the present invention includes a calculation unit that calculates the similarity between a first document and a second document that is different from the first document for each predetermined area, and a comparison unit that compares the first document and the second document in units of a predetermined region according to the similarity; and an output unit for outputting comparison information to be displayed in a manner different from others.
本発明によれば、利便性の高い情報処理装置、情報処理方法及び情報処理プログラムを提供することができる。 According to the present invention, it is possible to provide a highly convenient information processing apparatus, information processing method, and information processing program.
以下、本発明の実施形態を図面に基づいて説明する。
なお、下記実施形態では、文書として契約書を例に実施形態を説明するが文書は契約書に限られない。例えば、規程文書、条例や条約、有価証券報告書、決算短信、特許明細書などであってもよい。
また、下記実施形態では、後述の変換部205が変換したベクトルを契約書の条項ごとに記憶する構成となっているが、比較のたびに変換部205が対象となる契約書の条項をベクトルに変換する構成としてもよい。
また、下記実施形態では、変換部205が変換したベクトルに基づいて類似性を算出しているが、シーケンスマッチングを用いた類似計算や、編集距離を用いた類似計算により類似性を算出するようにしてもよい。
BEST MODE FOR CARRYING OUT THE INVENTION An embodiment of the present invention will be described below with reference to the drawings.
In the following embodiment, the embodiment will be described using a contract as an example of a document, but the document is not limited to the contract. For example, it may be a regulatory document, an ordinance or a treaty, a securities report, a financial statement, or a patent specification.
In the embodiment described below, a vector converted by the
Further, in the following embodiment, the similarity is calculated based on the vector converted by the
[実施形態]
図1は、実施形態に係る情報処理システム1の概略構成の一例を示す図である。初めに、図1を参照して情報処理システム1の構成について説明する。情報処理システム1は、サーバ2(情報処理装置)と、このサーバ2とネットワーク4を介して接続されたユーザ端末3とを備える。なお、情報処理システム1が備えるサーバ2及びユーザ端末3の数はそれぞれ任意である。なお、サーバ2及びユーザ端末3間の通信は無線通信であるか有線通信であるか問わない。
[Embodiment]
FIG. 1 is a diagram showing an example of a schematic configuration of an information processing system 1 according to an embodiment. First, the configuration of the information processing system 1 will be described with reference to FIG. The information processing system 1 includes a server 2 (information processing device) and
(サーバ2)
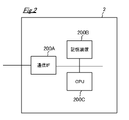
図2は、サーバ2(情報処理装置)のハード構成の一例を示す図である。図2に示すように、サーバ2は、通信IF200A、記憶装置200B、CPU200Cなどを備える。なお、サーバ2に入力装置(例えば、キーボード、タッチパネルなど)及び表示装置(例えば、液晶モニタや有機ELモニタなど)を備えるようにしてもよい。
(Server 2)
FIG. 2 is a diagram showing an example of the hardware configuration of the server 2 (information processing device). As shown in FIG. 2, the
通信IF200Aは、外部端末(実施形態では、ユーザ端末3)と通信するためのインターフェースである。
記憶装置200Bは、例えば、HDDや半導体記憶装置である。記憶装置200Bには、サーバ2で利用する情報処理プログラム及びデータベースなどが記憶されている。なお、実施形態では、情報処理プログラム及びデータベースは、サーバ2の記憶装置200Bに記憶されているが、USBメモリなどの外部記憶装置やネットワークを介して接続された外部サーバに記憶し、必要に応じて参照やダウンロード可能に構成されていてもよい。
The
図3は、記憶装置200Bに記憶されているデータベースの一例である。図3に示すように、記憶装置200Bには、ユーザデータベース1(以下、ユーザDB1)及び文書データベース2(以下、文書DB2)が記憶されている。なお、下記データベースDB1~DB2の情報をどのように関連付けて記憶装置200Bに記憶するかは任意であり、図3に示す例に限られない。また、必ずしもデータベースとして記憶装置200Bに記憶する必要はない。
FIG. 3 is an example of a database stored in the
図3は、データベースとして記憶装置200Bに記憶されている情報(データ)の一例を示す図である。
(ユーザDB1)
ユーザDB1には、ユーザの情報、例えば、パスワード、氏名、性別、年齢、生年月日、連絡先、アイコン用の自画像データなどの情報がユーザIDに関連付けて記憶されている。ユーザIDは、ユーザ毎に異なる識別情報であり、情報処理システム1にログインするためのIDともなる。パスワードは、情報処理システム1にログインするためのパスワードである。氏名、性別、年齢及び生年月日は、ユーザの氏名、性別、年齢及び生年月日である。連絡先は、ユーザのメールアドレス、電話番号、住所などである。なお、どのような情報をユーザIDに関連付けてユーザDB1に記憶するかは任意であり、上記情報に限られない。
FIG. 3 is a diagram showing an example of information (data) stored in the
(User database 1)
The user DB 1 stores user information such as password, name, gender, age, date of birth, contact information, self-portrait data for icons, etc. in association with the user ID. The user ID is identification information different for each user, and also serves as an ID for logging into the information processing system 1 . The password is a password for logging into the information processing system 1 . The name, gender, age and date of birth are the user's name, gender, age and date of birth. The contact information is the user's e-mail address, telephone number, address, and the like. In addition, what kind of information is stored in the user DB 1 in association with the user ID is arbitrary, and is not limited to the above information.
(文書DB2)
文書DB2には、契約書、各種テーブルなどの情報が記憶されている。以下、文書DB2に記憶されている情報について説明する。
契約書種類マスタテーブルM1には、契約書種類IDと、条項名との組のレコードが蓄積されている。ここで契約書種類IDは、契約書の種類を識別する契約書種類識別情報の一例である。
種類マスタテーブルM2には、条項種類IDと、条項名との組のレコードが蓄積されている。ここで条項種類IDは、条項の種類を識別する条項種類識別情報の一例である。
標準条項テーブルT1には、予め用意された標準的な契約書に含まれる条項に関する情報が格納される。
標準条項テーブルT1には、契約書種類IDと、条項種類IDと、ベクトルと、条項との組のレコードが蓄積されている。ベクトルは、条項すなわち条項単位の文章群が変換されたものである。
条項テーブルT2には、ユーザによって入力(アップロード)された契約書に含まれる条項が蓄積されている。また、条項テーブルT2には、契約書種類IDと、条項種類IDと、条項と、条項を変換したベクトルの組のレコードが蓄積されている。
また、文書DB2には、標準契約書に含まれる条項それぞれに対応するベクトルと当該条項に付された条項種類識別情報(ここでは契約書種類ID)との組に対して、契約書の種類が更に関連付けられて記憶されている。
(Document DB2)
The
The contract type master table M1 stores records of pairs of contract type IDs and clause names. Here, the contract type ID is an example of contract type identification information for identifying the type of contract.
The type master table M2 stores records of sets of clause type IDs and clause names. Here, the clause type ID is an example of clause type identification information that identifies the type of clause.
The standard clause table T1 stores information on clauses included in standard contracts prepared in advance.
The standard clause table T1 stores records of pairs of contract type IDs, clause type IDs, vectors, and clauses. A vector is obtained by transforming a clause, that is, a group of sentences for each clause.
Clauses included in contracts input (uploaded) by users are accumulated in the clause table T2. Also, the clause table T2 stores records of sets of contract type IDs, clause type IDs, clauses, and vectors obtained by converting the clauses.
Further, in the
CPU200Cは、サーバ2を制御し、図示しないROM(Read Only Memory)及びRAM(Random Access Memory)を備えている。
The
図4は、実施形態に係るサーバ2の機能構成の一例を示す図である。図4に示すように、サーバ2は、受信部201(第1~第2受付部)、送信部202(出力部)、記憶装置制御部203、分割部204、変換部205、算出部206、分類部207、カウント部208、比較部209などの機能を有する。なお、図4に示す機能は、サーバ2のROM(不図示)に記憶された情報処理プログラムをCPU200Cが実行することにより実現される。
FIG. 4 is a diagram showing an example of the functional configuration of the
受信部201は、ネットワーク4を介してユーザ端末3から送信される情報を受信する。受信部201は、例えば、分類部207により分類された第2契約書をグループごとに表示する第1指示を受信する。また、受信部201は、例えば、比較部209により比較された第2契約書のうち、所定領域以外の領域を表示する第2指示を受信する。
The receiving
記憶装置制御部203は、記憶装置200Bを制御する。具体的には、記憶装置制御部203は、記憶装置200Bへの情報の書き込みや読み出しを行う。
The storage
分割部204は、契約書を所定領域単位に分割する。実施形態では、分割部204は、契約書を条項ごとに分割する。具体的には、分割部204は、契約書から「条」という単語を抽出し、この「条」を境目とみなして条項毎に契約書を分割する。なお、所定領域単位をどのような単位とするかは任意である。例えば、項又は号を所定領域単位として対象の契約書を分割するようにしてもよい。この場合、分割部204は、対象の契約書から「項」又は「号」という単語を抽出し、この「項」又は「号」を境目とみなして項毎又は号毎に契約書を分割する。また、「条」という単語を抽出して分割するのではなく、条段落であることを連続する行の中のテキスト情報から判断して分割するようにしてもよい。なお、「項」や「号」の抽出についても同様に「項」や「号」という単語を抽出して分割するのではなく、項段落や号段落であることを連続する行の中のテキスト情報から判断して分割するようにしてもよい
The dividing
変換部205は、契約書の条項をベクトルに変換する。具体的には、変換部205は、分割部204による分割後の条項をベクトルに変換する。ベクトルは例えば、高次元の実数ベクトルである。変換部205により近い意味の条項は、近いベクトルに変換される。この変換によるベクトルを比較することで、契約書の類似性を条項ごとに算出することができる。
The
<変換部205による変換処理>
次に、各文章をベクトルに変換する処理の一例について説明する。
初めに、変換部205は、文章を形態素に分解する。例えば文章が「今日はいい天気です」の場合、「今日」、「は」、「いい」、「天気」、「です」に分解する。
次いで、変換部205は、連続するN個(Nは自然数)の形態素をn-gramとして定義する。例えば、Nが2の場合、変換部205は、以下のようにn-gramを定義する。
N=2:(今日,は),(は,いい),(いい天気),(天気です)
次いで、変換部205は行列を計算する。ここでは、仮に、三つの契約書S1、S2、S3があるものとする。変換部205は、契約書S1のすべてのn-gramは契約書S1に最も現れ、契約書S2、契約書S3に含まれる異なるn-gramは現れず、契約書S2、契約書S3に関しても同様となる行列U、Vを計算する。行列Uは、センテンス(文章)ごとの値の集合で、行列U、Vの最適化によって学習(最適化関数)を実行することにより、契約書のベクトル(分散表現)を導出する。行列Uは、行列Vと大きさの同じで90度傾けた行列で、センテンス(文章)毎の値の集合である。そして変換部205は、行列の片方であるVをもとに、含まれるすべてのn-gram分散表現を平均して文章のベクトル(分散表現ともいう)を得る。
以下、対象の文章(センテンス)Sをベクトルに変換する処理の具体的な手法の例について簡単に説明する。学習時には、行列Vで単語ごとの表現を求める。単語のセンテンス内での出現パターンを学習するためパラメーターUも使う。また行列U、Vを誤差関数を使って最適化する。分散表現導出時には、文章(センテンス)SのBag of WordsベクトルDを求める。ベクトルDと行列Vを掛け合わせ、出現頻度を加味したn-gramごとのベクトル表現の平均を取り、文章Sのベクトル表現を求める。
なお、変換部205によるベクトルへの変換には公知のライブラリや公知の方法を用いてもよい。
なお、変換部205は、条項に含まれる文章が三つである場合(第1文から第3文まで存在する場合)、変換部205は、第1文から第3文をそれぞれベクトルに変換し、それぞれのベクトルの平均を当該条項に対応するベクトルとする。
<Conversion processing by
Next, an example of processing for converting each sentence into a vector will be described.
First, the
Next, the
N=2: (today, ha), (ha, nice), (nice weather), (weather)
An example of a specific technique for converting a target sentence (sentence) S into a vector will be briefly described below. At the time of learning, a matrix V is used to obtain an expression for each word. We also use the parameter U to learn patterns of occurrence of words within sentences. Also, the matrices U and V are optimized using the error function. When deriving the distributed representation, the Bag of Words vector D of the sentence S is obtained. The vector representation of the sentence S is obtained by multiplying the vector D and the matrix V, and taking the average of the vector representation for each n-gram with appearance frequency added.
Note that a known library or a known method may be used for conversion into a vector by the
Note that when the clause includes three sentences (the first to third sentences exist), the converting
算出部206は、ユーザによる編集対象である契約書(以下、第1契約書ともいう)の条項と、文書DB2に格納された他の契約書(以下、第2契約書ともいう)の条項との類似性をベクトルに基づいて算出する。具体的には、算出部206は、第1契約書の条項のベクトルと、第2契約書の条項のベクトルとの類似性(例えばコサイン類似性)を算出する。なお、実施形態では、算出部206は、ベクトル間のコサイン類似性に基づいて契約書の条項間の類似性を算出するが、契約書の条項間の類似性を算出できれば、他の手法により類似性を算出するようにしてもよい。例えば、ユークリッド距離を用いた類似度計算により類似性を算出するようにしてもよい。
The
分類部207は、契約書の条項間の類似性に応じて第2契約書を所定のグループ(1以上のグループ)に分類する。具体的には、分類部207は、算出部206で算出された類似性が第1所定値以上第2所定値未満である第2契約書を第1グループに分類する。算出部206で算出された類似性が第2所定値以上第3所定値未満である第2契約書を第2グループに分類する。算出部206で算出された類似性が第3所定値以上第4所定値未満である第2契約書を第3グループに分類する。なお、実施形態では、3つのグループに分類しているが、いくつのグループに分類するかは任意である。また、第1~第4所定値をどのような値とするかについても任意である。
The
なお、分類部207は、契約書を分類する際に、ベクトル化された条文を混合ガウスモデルなど(一例)を用いて事前にクラスタリングしておき、そのクラスタリング結果に応じてグループ分けを判断してもよい。また、類似性の所定値とクラスタリングを組み合わせ、類似性の所定値の範囲であることかつ同一のクラスタリングに属することを条件にする形で、グループを判断してもよい。
When classifying contracts, the
カウント部208は、分類部207により分類された第2契約書の件数をグループごとにカウントする。
The
比較部209は、算出部206で算出された類似性に応じて、第1文書と、第2文書とを所定領域単位(実施形態では条項)で比較する。具体的には、比較部209は、第1契約書の条項と、第2契約書の条項とを比較し、両契約書の異なる箇所(文字)を検出する。
The
送信部202は、ネットワーク4を介してユーザ端末3へ情報を送信する。例えば、送信部202は、比較部209での比較結果に応じて、比較された契約書の同一箇所及び異なる箇所を異なる態様で表示させる比較情報を送信(出力)する。
また、送信部202は、受信部201が分類部207により分類された第2契約書をグループごとに表示する第1指示を受信した場合、指定されたグループに属する第2契約書を表示させる情報を送信(出力)する。
また、送信部202は、受信部201が比較部209により比較された第2契約書のうち、所定領域以外の領域を表示する第2指示を受信した場合、所定領域以外の領域を表示させる情報を送信(出力)する。
また、送信部202は、類似性が所定値以下である第2契約書の所定領域を送信(出力)する。
The
Further, when the receiving
Further, when the receiving
Also, the transmitting
(ユーザ端末3)
図5は、実施形態に係るユーザ端末3のハード構成及び機能構成の一例を示す図である。図5(a)は、ユーザ端末3のハード構成の一例を示す図、図5(b)は、ユーザ端末3の機能構成の一例を示す図である。ユーザ端末3は、PC(Personal Computer)や携帯端末(例えば、タブレット端末)などである。図5(a)に示すように、ユーザ端末3は、通信IF300A、記憶装置300B、入力装置300C、表示装置300D、CPU300Eなどを備える。
(User terminal 3)
FIG. 5 is a diagram showing an example of the hardware configuration and functional configuration of the
通信IF300Aは、他の装置(実施形態では、サーバ2)と通信するためのインターフェースである。
Communication IF 300A is an interface for communicating with another device (
記憶装置300Bは、例えば、HDD(Hard Disk Drive)や半導体記憶装置(SSD(Solid State Drive))である。記憶装置300Bには、ユーザ端末3の識別子(ID)及び情報処理プログラムなどが記憶されている。なお、識別子は、サーバ2がユーザ端末3に対して新たに付与してもよいし、IP(Internet Protocol)アドレス、MAC(Media Access Control)アドレスなどを利用してもよい。
The
入力装置300Cは、例えば、キーボード、タッチパネルなどであり、ユーザは、入力装置300Cを操作して、情報処理システム1の利用に必要な情報を入力することができる。 The input device 300C is, for example, a keyboard, a touch panel, or the like, and the user can input information necessary for using the information processing system 1 by operating the input device 300C.
表示装置300Dは、例えば、液晶モニタや有機ELモニタなどである。表示装置300Dは、情報処理システム1の利用に必要な画面を表示する。
The
CPU300Eは、ユーザ端末3を制御するものであり、図示しないROM及びRAMを備えている。
The
図5(b)に示すように、ユーザ端末3は、受信部301、送信部302、記憶装置制御部303、操作受付部304、表示装置制御部305などの機能を有する。なお、図5(b)に示す機能は、CPU300Eが、記憶装置300Bに記憶されている情報処理プログラムを実行することで実現される。
As shown in FIG. 5B, the
受信部301は、サーバ2から送信される情報を受信する。
The receiving
送信部302は、入力装置300Cを利用して入力された情報に識別子を付与してサーバ2へ送信する。ユーザ端末3から送信される情報に識別子を付与することでサーバ2は、受信した情報がどのユーザ端末3から送信されたものであるかを認識できる。
The
記憶装置制御部303は、記憶装置300Bを制御する。具体的には、記憶装置制御部303は、記憶装置300Bを制御して情報の書き込みや読み出しを行う。
The storage
操作受付部304は、入力装置300Cでの入力操作を受け付ける。
The
表示装置制御部305は、表示装置300Dを制御する。具体的には、表示装置制御部305は、表示装置300Dを制御して実施形態に係る情報処理システム1の利用に必要な画面を表示させる。
The display
(表示画面例)
図6~図8は、実施形態に係るユーザ端末3の表示装置300Dに表示される画面の一例を示す図である。以下、図6~図8を参照してユーザ端末3の表示装置300Dに表示される画面について説明する。なお、以下の説明では同一の構成には同一の符号を付して重複する説明を省略する。なお、以下の説明において、表示には、操作が完了するまで親ウィンドウへの操作を受け付けなくさせるタイプのウィンドウを表示するモーダル表示、タブの切り替えによる表示(タブ表示)、親ウィンドウとは別にサイズの小さなウィンドウ(サブウインドウ)を開く表示(サブウィンドウ表示)などが含まれるものとする。
(Example of display screen)
6 to 8 are diagrams showing examples of screens displayed on the
図6は、ユーザ端末3の表示装置300Dに表示される画面の一例である。図6に示す画面では、画面向かって左側にユーザにより指定された第1契約書D1が表示される。また、画面向かって左側の中央部には第1契約書D1の編集対象である条項J1が表示される。また、類似契約書表示ボタンB1を選択すると、画面向かって右側に、算出部206で算出された類似性に応じて分類部207により分類された第2契約書の条項が類似性に応じたグループG1~G3ごとに表示される(なお、図6に示す例では、各グループG1~G3のうち、最も類似性の高い第2契約書の条項が表示されている)。図6に示す例では、3つのグループG1~G3に分類された状態で表示されている。なお、表7に示す例では、類似性の高いグループから(画面上から画面下向かって)降順に表示される。
FIG. 6 is an example of a screen displayed on the
また、図6に示す画面には、カウント部208によりカウントされた各グループに分類された条項が含まれる第2契約書の件数N1~N3が表示される。図6に示す例では、グループG1には2件の第2契約書が、グループG2には3件の第2契約書が、グループG3には1件の第2契約書が各々分類されていることがわかる。また、図6に示すボタンB2を選択操作することで、後述の図7に示す画面が表示される。また、図6に示すボタンB3を左から右へスライド操作することで、後述の図8に示す画面(差分表示画面)が表示される。
The screen shown in FIG. 6 also displays the number of second contracts N1 to N3 containing the clauses classified into each group counted by the
なお、図6に示す画面では、画面向かって左側にユーザにより指定された編集対象である第1契約書D1が表示され、画面向かって右側に、算出部206で算出された類似性に応じて分類部207による分類された第2契約書が分類された状態で表示されているが、画面向かって右側にユーザにより指定された編集対象である第1契約書D1が表示され、画面向かって左側に、算出部206で算出された類似性に応じて分類部207による分類された第2契約書が分類された状態で表示されてもよい。
In the screen shown in FIG. 6, the first contract D1 to be edited designated by the user is displayed on the left side of the screen, and the similarity calculated by the
図7は、ユーザ端末3の表示装置300Dに表示される画面の一例である。なお、図7は、図6においてグループG1に分類された第2契約書を表示した例である。図7に示すように、画面向かって左側には第2契約書のファイル名F1、F2が表示される。また、図7の画面中央部には、画面右側で選択されたファイル名F1の第2契約書の内容が表示される。なお、図7に示す例では、ファイル名F1が選択されていることを示すため、ファイル名F1の背景が変化している(ハイライト表示されている)。また、図7に示す例では、ファイル名F1の第2契約書の内容のうち、図6において比較されている条項の領域の背景が変化している(ハイライト表示されている)。さらに、図7の中央上部には、選択されたファイル名F1の第2契約書のステータスS、作成日D1、作成日からの経過日数D2、作成者・編集者のアイコンUなどが表示される。
FIG. 7 is an example of a screen displayed on the
つまり、図6に示すボタンB2を選択操作することで、分類部207により分類された第2契約書をグループごとに表示する指示(第1指示)を受信部201が受け付けると、サーバ2の送信部202(出力部)は、指定されたグループに属する第2契約書を表示させる情報をユーザ端末3へ送信する。送信された情報は、ユーザ端末3の受信部301で受信され、ユーザ端末3の表示装置制御部305により表示装置300Dに図7に示す画面が表示される。
In other words, when the
図8は、ユーザ端末3の表示装置300Dに表示される画面の一例である。図8に示す画面では、画面向かって左側にユーザにより指定された第1契約書D1が表示される。また、画面向かって左側には第1契約書D1の編集対象である条項J1が表示される。また、画面向かって右側上段には、編集対象である第1契約書D1の条項J1が表示され、画面向かって右側下段には、比較対象である第2契約書のうち、条項J1に対応する条項J2が表示される。画面向かって右側では、第1契約書D1のうち編集対象である条項J1と、比較対象である第2契約書D2のうち、条項J1に対応する条項J2とが、互いに異なる箇所(以下、差分ともいう)が認識できる態様で表示される。
FIG. 8 is an example of a screen displayed on the
図8に示す例では、条項J1の条項J2とは異なる箇所が太字体で表示され、条項J2の条項J1とは異なる箇所が斜体で表示されているが、異なる箇所(文字)が認識できれば、他の態様、例えば、異なる箇所(文字)をハイライトで表示するようにしてもよい。なお、図8に示す例では、異なる箇所(文字)の位置をわかりやすくするために異なる箇所(文字)に下線を付しているが実際には下線は付されていない。 In the example shown in FIG. 8, the parts of Clause J1 that differ from Clause J2 are displayed in bold, and the parts of Clause J2 that differ from Clause J1 are displayed in italics. Other aspects, for example, different parts (characters) may be highlighted. In the example shown in FIG. 8, different parts (characters) are underlined in order to make the positions of different parts (characters) easier to understand, but they are not actually underlined.
このように、図8に示す画面では、画面向かって右側で比較対象である第2契約書の条項J2と異なる箇所(差分)を確認しながら、画面向かって左側で編集対象である第1契約書D1の条項J1を編集することができる。なお、図8においては、画面向かって左側で第1契約書D1の条項J1を編集すると、編集した内容が、画面向かって右側に表示される第1契約書D1の条項J1にリアルタイムに反映され、編集内容を反映した第1契約書D1の条項J1と比較対象である第2契約書の条項J2との差分を確認することができる。このため非常に利便性に優れる。 In this way, on the screen shown in FIG. 8, while checking the differences (differences) from clause J2 of the second contract to be compared on the right side of the screen, on the left side of the screen is the first contract to be edited. Clause J1 of document D1 can be edited. Note that in FIG. 8, when the clause J1 of the first contract D1 is edited on the left side of the screen, the edited contents are reflected in real time on the clause J1 of the first contract D1 displayed on the right side of the screen. , the difference between the clause J1 of the first contract document D1 reflecting the edited content and the clause J2 of the second contract document to be compared can be confirmed. Therefore, it is very convenient.
なお、図8に示す画面では、画面向かって左側にユーザにより指定された編集対象である第1契約書D1が表示され、画面向かって右側に、第1契約書D1及び第2契約書が、それぞれ差分が認識できる態様で表示される構成となっているが、画面向かって右側にユーザにより指定された編集対象である第1契約書D1が表示され、画面向かって左側に、第1契約書D1及び第2契約書が、それぞれ差分が認識できる態様で表示される構成としてもよい。また、図8に示す画面では、条項単位で画面の上下に差分が認識できる態様で表示される構成となっているが、行単位で画面の上下に差分が認識できる態様で表示される構成としてもよいし、画面の左右に差分が認識できる態様で表示される構成としてもよい。また、インラインで差分が認識できる態様で表示(見え消し表示で差分表示する方法)される構成としてもよい。 In the screen shown in FIG. 8, the first contract D1 to be edited designated by the user is displayed on the left side of the screen, and the first contract D1 and the second contract are displayed on the right side of the screen. The first contract D1 to be edited specified by the user is displayed on the right side of the screen, and the first contract D1 is displayed on the left side of the screen. D1 and the second contract may be configured to be displayed in such a manner that the difference between them can be recognized. In addition, although the screen shown in FIG. 8 is configured to display the difference between clauses at the top and bottom of the screen in units of clauses, it is configured to display the difference at the top and bottom of the screen in units of lines in a manner in which differences can be recognized. Alternatively, the configuration may be such that the difference is displayed on the left and right sides of the screen in such a manner that the difference can be recognized. In addition, a configuration may be adopted in which the difference is displayed in a manner in which the difference can be recognized inline (a method of displaying the difference in a hidden display).
(情報処理システム1で実行される処理)
図9~図12は、サーバ2で実行される処理の一例を示すフローチャートである。以下、図9~図12を参照して、サーバ2で実行される処理について説明するが、図1~図8を参照して説明した構成と同一の構成には同一の符号を付して重複する説明を省略する。
(Processing executed by information processing system 1)
9 to 12 are flowcharts showing an example of the processing executed by the
(ユーザ登録処理)
図9は、サーバ2で実行されるユーザ登録処理の一例を示すフローチャートである。以下、図9を参照して、サーバ2で実行されるユーザ登録処理について説明する。
(User registration process)
FIG. 9 is a flowchart showing an example of user registration processing executed by the
(ステップS101)
ユーザは、ユーザ端末3の入力装置300Cを操作して、ユーザの情報、例えば、パスワード、氏名、性別、年齢、生年月日、連絡先、アイコン用の自画像データなどの情報を入力する。入力されたユーザの情報は、操作受付部304で受け付けられる。受け付けられたユーザの情報は、送信部302からサーバ2へと送信される。サーバ2の受信部201は、ユーザ端末3から送信されたユーザの情報を受信する。
(Step S101)
The user operates the input device 300C of the
(ステップS102)
サーバ2の受信部201で受信されたユーザの情報は、記憶装置制御部203により、ユーザIDに関連付けて記憶装置200BのユーザDB1に記憶される。
(Step S102)
The user information received by the receiving
(契約書登録処理)
図10は、サーバ2で実行される契約書登録処理の一例を示すフローチャートである。以下、図10を参照して、サーバ2で実行される契約書登録処理について説明する。
(Contract registration process)
FIG. 10 is a flow chart showing an example of contract registration processing executed by the
(ステップS201)
ユーザは、ユーザ端末3の入力装置300Cを操作して、サーバ2に登録する契約書を指定する。この契約書の指定は、300Dに表示された所定領域に登録したい契約書をドラッグアンドドロップすることで行われるが、他の方法により指定される構成でもよい。指定された契約書は、送信部302からサーバ2へと送信される。サーバ2の受信部201は、ユーザ端末3から送信された契約書を受信する。
(Step S201)
The user operates the input device 300</b>C of the
(ステップS202)
サーバ2の分割部204は、受信部201で受信された契約書を所定領域単位に分割する。実施形態では、分割部204は、対象の契約書を条項ごとに分割する。
(Step S202)
The dividing
(ステップS203)
サーバ2の変換部205は、受信部201で受信された契約書を所定領域単位ごとにベクトルに変換する。具体的には、変換部205は、分割部204による分割後の条項をベクトルに変換する。
(Step S203)
The
(ステップS204)
サーバ2の記憶装置制御部203は、受信部201が受信した契約書及び変換部205により変換された条項毎のベクトルをユーザIDに関連付けて記憶装置200Bの文書DB2へ記憶する。
(Step S204)
The storage
(カウント処理)
図11は、サーバ2で実行されるカウント処理の一例を示すフローチャートである。以下、図11を参照して、サーバ2で実行されるカウント処理について説明する。
(count processing)
FIG. 11 is a flow chart showing an example of the counting process executed by the
(ステップS301)
ユーザは、ユーザ端末3の入力装置300Cを操作して、編集する契約書の条項を指定する。この指定は、送信部302からサーバ2へと送信される。サーバ2の受信部201は、ユーザ端末3から送信された指定を受信する。
(Step S301)
The user operates the input device 300C of the
(ステップS302)
サーバ2の算出部206は、文書DB2を参照し、指定された契約書に関連付けられたユーザIDと同じユーザIDが関連付けられた他の契約書を抽出する。
(Step S302)
The
(ステップS303)
サーバ2の算出部206は、指定された契約書の条項と、ステップS302で抽出された他の契約書の条項との類似性を算出する。より具体的には、変換部205により変換された条項のベクトルに基づいてコサイン類似度を算出する。
(Step S303)
The
(ステップS304)
サーバ2の分類部207は、契約書の条項間の類似性に応じて契約書を所定のグループに分類する。なお、分類部207による分類の詳細については既に説明したため省略する。
(Step S304)
The
(ステップS305)
サーバ2のカウント部208は、分類部207により分類された第2契約書の件数をグループごとにカウントする。
(Step S305)
The
(ステップS306)
サーバ2の送信部202は、カウント部208によりグループごとにカウントされた第2契約書の件数の情報を送信する。件数の情報は、ユーザ端末3の受信部301で受信される。表示装置制御部305は、受信した件数の情報に基づいて、グループごとにカウントされた第2契約書の件数を表示装置300Dに表示させる。
(Step S306)
The transmitting
なお、上記説明では、ステップS302においてサーバ2の算出部206は、文書DB2を参照し、指定された契約書に関連付けられたユーザIDと同一のユーザIDが関連付けられた他の契約書を抽出しているが、同一のグループ(例えば、企業、部署、タスクフォースなど)単位で契約書を抽出するようにしてもよい。この場合、同一のグループに属するユーザのユーザIDに同一のグループIDを関連付ける。そして、ステップS302においてサーバ2の算出部206は、文書DB2を参照し、指定された契約書に関連付けられたユーザIDに関連付けられたグループIDと同一のグループIDが関連付けられた他の契約書を抽出する。
In the above description, in step S302, the
(比較処理)
図12は、サーバ2で実行される比較処理の一例を示すフローチャートである。以下、図12を参照して、サーバ2で実行される比較処理について説明する。
(comparison processing)
FIG. 12 is a flow chart showing an example of comparison processing executed by the
(ステップS401)
ユーザは、ユーザ端末3の入力装置300Cを操作して、契約書の比較を指示する。この指示は、送信部302からサーバ2へと送信される。サーバ2の受信部201は、ユーザ端末3から送信された指示を受信する。
(Step S401)
The user operates the input device 300C of the
(ステップS402)
サーバ2の比較部209は、算出部206で算出された類似性に応じて、編集対象となる第1契約書と、第2契約書とを所定領域単位(実施形態では条項)で比較する。具体的には、比較部209は、対象となる第1契約書の条項と、算出部206で算出された類似性が所定値以上の第2契約書の条項とを比較し、両契約書の異なる箇所(文字)を検出する。
(Step S402)
The
(ステップS403)
送信部202は、比較部209での比較結果に応じて、比較された契約書の同一箇所及び異なる箇所を異なる態様で表示させる比較情報を送信(出力)する。比較情報は、ユーザ端末3の受信部301で受信される。表示装置制御部305は、受信した比較情報に基づいて、比較された契約書の同一箇所及び異なる箇所を異なる態様で表示装置300Dに表示させる。
(Step S403)
The transmitting
以上のように、実施形態に係るサーバ2(情報処理装置)は、編集対象である第1契約書(第1文書)と、第1契約書とは異なる他の契約書である第2契約書(第2文書)との類似性を所定領域単位(条項、項、号など)で算出する算出部206と、算出部206で算出された類似性に応じて、第1契約書と、第2契約書とを所定領域単位で比較する比較部209と、比較部209での比較結果に応じて、第1契約書と第2契約書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を送信(出力)する送信部202(出力部)とを備える。このように契約書(文書)単位ではなく、所定領域単位で契約書(文書)間の差分を比較することができるので、利便性が向上する。
As described above, the server 2 (information processing device) according to the embodiment can edit the first contract (first document) to be edited and the second contract, which is another contract different from the first contract.
また、実施形態に係るサーバ2は、類似性に応じて、第2契約書(第2文書)を所定のグループに分類する分類部207と、分類部207により分類された第2契約書の件数をグループごとにカウントするカウント部208とを備える。
このように類似性に応じて分類されたグループごとに編集対象である条項に類似する条項が存在する第2契約書の件数を知ることができるので利便性が向上する。
In addition, the
In this way, it is possible to know the number of second contracts in which clauses similar to the clause to be edited exist for each group classified according to similarity, thereby improving convenience.
また、実施形態に係るサーバ2は、分類部207により分類された第2契約書(第2文書)をグループごとに表示する第1指示を受け付ける受信部201(第1受付部)を備える。また、実施形態に係るサーバ2の送信部202(出力部)は、受信部201(第1受付部)が第1指示を受け付けた場合、指定されたグループに属する第2契約書を表示させる情報を送信(出力)する。このように、類似するグループごと第2契約書を表示できるので利便性が向上する。
The
また、実施形態に係るサーバ2は、比較部209により比較された第1契約書(第1文書)のうち、所定領域以外の領域を表示する第2指示を受け付ける受信部201(第2受付部)を備える。そして、サーバ2の送信部202(出力部)は、受信部201(第2受付部)が第2指示を受け付けた場合、所定領域以外の領域を表示させる情報を送信(出力)する。このように、比較している所定領域以外の領域についても表示して確認等をすることができるので利便性が向上する。
The
また、実施形態では、所定領域単位は、条項単位又は項単位である。一般に、契約書は、条項単位で記載されており、各条項は、項で構成されている。このため、所定領域単位を条項単位又は項単位とすることで、契約書の比較が容易となる。結果、利便性が向上する。 Also, in the embodiment, the predetermined area unit is a clause unit or a paragraph unit. In general, a contract is written on a clause-by-clause basis, and each clause consists of clauses. For this reason, by setting the predetermined area unit to the clause unit or the clause unit, it becomes easy to compare contracts. As a result, convenience is improved.
また、実施形態に係るサーバ2は、第1契約書(第1文書)及び第2契約書(第2文書)を所定領域単位でベクトルに変換する変換部205を備える。そして、サーバ2の算出部206は、所定領域単位で変換されたベクトルに基づいて、第1契約書(第1文書)と、第2契約書(第2文書)との類似性を所定領域単位で算出する。このように、文章の類似性を判定する際に利用されるベクトルに基づいて、類似性を算出するので類似性の精度が向上する。
The
[実施形態の変形例1]
以下、実施形態の変形例1について説明するが、図1~図12を参照して説明した構成と同じ構成には同一の符号を付して重複する説明を省略する。図13は、実施形態の変形例1に係るサーバ(情報処理装置)の機能構成の一例を示す図である。図13に示すように、実施形態の変形例1に係るサーバ2は、受信部201(第3受付部)、送信部202(出力部)、記憶装置制御部203、分割部204、変換部205、算出部206、分類部207、カウント部208、比較部209に加え、入替部210及び検索部211の機能を有する。
[Modification 1 of Embodiment]
Modification 1 of the embodiment will be described below, but the same components as those described with reference to FIGS. 13 is a diagram illustrating an example of a functional configuration of a server (information processing device) according to Modification 1 of the embodiment; FIG. As shown in FIG. 13, the
入替部210は、実施形態の変形例1に係るサーバ2(情報処理装置)は、対象となる第1契約書D1(第1契約書)との類似性に応じて第2契約書D2の表示順序を領域単位で入れ替える。具体的には、入替部210は、編集対象である第1契約書の各条項との類似性に応じて、比較対象である第2契約書を条項単位で入れ替える。換言すると、入替部210は、第2契約書の各条項のうち最も類似性が高いものが、第1契約書の対応する条項の右隣となるように入れ替える。
The
図14は、実施形態の変形例1に係るユーザ端末3の表示装置300Dに表示される画面の一例である。入替部210は、編集対象である第1契約書の各条項との類似性に応じて、比較対象である第2契約書を条項単位で入れ替えるため、図14に示すように、もともと契約書D2に記載されていた条項順ではなく、第1契約書D1の各条項J1~J3に類似する順序に入れ替えた状態でユーザ端末3の表示装置300Dに表示される。図14に示す例では、第1契約書D1の各条項J1~J3に類似する順序に入れ替えられているため、第2契約書D2は、条項J4、条項J5、条項J6の順でユーザ端末3の表示装置300Dに表示されている。つまり、第1契約書D1の条項J1の右隣には、第2契約書の各条項のうち条項J1に最も類似する条項J4が表示され、第1契約書D1の条項J2の右隣には、第2契約書の各条項のうち条項J2に最も類似する条項J5が表示され、第1契約書D1の条項J3の右隣には、第2契約書の各条項のうち条項J3に最も類似する条項J6が表示されている。
FIG. 14 is an example of a screen displayed on the
なお、図8に示した例と同様に、図14においても編集対象である第1契約書D1(第1文書)と、比較対象である第2契約書D2(第2文書)とが、異なる箇所(以下、差分ともいう)が認識できる態様で表示される。図14に示す例では、第1契約書D1の第2契約書D2とは異なる箇所が太字体で表示され、第2契約書D2の第1契約書D1とは異なる箇所が斜体で表示されているが、異なる箇所(文字)が認識できれば、他の態様、例えば、異なる箇所(文字)をハイライトで表示するようにしてもよい。なお、図14に示す例でも、異なる箇所(文字)の位置をわかりやすくするために異なる箇所(文字)に下線を付しているが実際には下線は付されていない。 As in the example shown in FIG. 8, also in FIG. 14, the first contract D1 (first document) to be edited and the second contract D2 (second document) to be compared are different. The part (hereinafter also referred to as difference) is displayed in a recognizable manner. In the example shown in FIG. 14, the portions of the first contract D1 that differ from the second contract D2 are displayed in bold, and the portions of the second contract D2 that differ from the first contract D1 are displayed in italics. However, if the different parts (characters) can be recognized, another aspect, for example, the different parts (characters) may be highlighted. In the example shown in FIG. 14 as well, the different parts (characters) are underlined in order to make the positions of the different parts (characters) easier to understand, but they are not actually underlined.
このように、入替部210を備えることで、ユーザは、第1契約書の条項J1と条項J1と類似する第2契約書の条項J4とを、第1契約書の条項J2と条項J2と類似する第2契約書の条項J5とを、第1契約書の条項J3と条項J3と類似する第2契約書の条項J6とを、それぞれ画面をスクロール等することなく同一画面において比較することができる。このように、本来であれば、画面をスクロールして対応する条項を探す必要がなく、同一画面において条項の記載を比較することができるため利便性が向上する。
In this way, with the
なお、図14を参照した説明では、編集対象である第1契約書D1に合わせて第2契約書D2の条項の順序を入れ替えているが、第2契約書D2に合わせて編集対象である第1契約書D1の条項の順序を入れ替えるようにしてもよい。 In the description with reference to FIG. 14, the order of the clauses of the second contract D2 is changed according to the first contract D1 to be edited. The order of the clauses in one contract D1 may be changed.
また、検索部211は、受信部201が受信したキーワード(検索ワード)に基づいて、契約書を検索する。送信部202は、検索部211により検索された検索ワードを他のワードと異なる態様(例えば、ハイライト表示)で表示させる検索情報を出力する。これにより、ユーザ端末3の表示装置300Dにおいて、検索された検索ワードの箇所が検索ワードを他のワードと異なる態様で表示される。結果、利便性が向上する。
Also, the
また、送信部202は、算出された類似性が所定値以下である第2契約書D2(この第2契約書は標準契約書であってよい)の所定領域を出力するように構成してもよい。このように構成することで、編集対象である第1契約書D1に欠落している条項がユーザ端末3の表示装置300Dに表示される。
Further, the
[実施形態の変形例2]
また、編集履歴を記憶することで文書のリビジョン管理を行い、文書の編集履歴のうちの特定のリビジョン間の同一箇所又は異なる箇所(差分)を他とは異なる態様で表示させるようにしてもよい。この場合、サーバ2の記憶装置制御部203は、ユーザによる契約書(文書)の編集履歴を文書ID及びリビジョンの情報に関連付けてとともにDB2へ記憶させる。そして、算出部206は、編集対象である第1契約書(第1文書)の特定リビジョンの編集履歴と、第2契約書(第2文書)の編集履歴との類似性を所定領域単位で算出する。次いで、比較部209は、算出部206で算出された類似性に応じて、第1契約書の編集履歴と、第2契約書の編集履歴とを所定領域単位(実施形態では条項)で比較する。送信部202は、比較部209での比較結果に応じて、比較された契約書の変種履歴の同一箇所及び異なる箇所を異なる態様で表示させる比較情報を送信(出力)する。比較情報は、ユーザ端末3の受信部301で受信される。表示装置制御部305は、受信した比較情報に基づいて、比較された契約書の編集履歴間の同一箇所及び異なる箇所を異なる態様で表示装置300Dに表示させる。このように契約書(文書)だけでなく、編集履歴についても、所定領域単位で契約書(文書)間の差分を比較することができるので、利便性が向上する。
[
Further, revision management of a document may be performed by storing the editing history, and the same portion or different portion (difference) between specific revisions in the editing history of the document may be displayed in a manner different from others. . In this case, the storage
[実施形態の変形例3]
なお、第2契約書のうち比較対象である条項以外の条項の展開表示を指示する操作ボタン(以下、展開ボタンともいう)を画面に配置してもよい。該展開ボタンを選択することで、サーバ2の受信部201が、比較部209により比較された第2契約書(第2文書)のうち、比較対象である条項(所定領域)以外の条項(領域)を表示する指示(第2指示)を受け付けると、サーバ2の送信部202は。比較対象である条項(所定領域)以外の条項(領域)を表示させる情報を送信(出力)する。送信された情報は、ユーザ端末3の受信部301で受信され、ユーザ端末3の表示装置制御部305により表示装置300Dに第2契約書(第2文書)のうち、比較対象である条項以外の条項が展開表示される。
[
It should be noted that an operation button (hereinafter, also referred to as an expansion button) for instructing expanded display of clauses other than the clauses to be compared in the second contract may be arranged on the screen. By selecting the expand button, the receiving
その他、上記実施形態及び変形例は、何れも本発明を実施するにあたっての具体化の一例を示したものに過ぎず、これによって本発明の技術的範囲が限定的に解釈されてはならないものである。すなわち、本発明はその要旨、またはその主要な特徴から逸脱することなく、様々な形で実施することができる。 In addition, the above embodiments and modifications are merely examples of specific implementations of the present invention, and the technical scope of the present invention should not be construed in a limited manner. be. Thus, the invention may be embodied in various forms without departing from its spirit or essential characteristics.
1 情報処理システム
2 サーバ(情報処理装置)
200A 通信IF
200B 記憶装置
200C CPU
201 受信部(第1~第3受付部)
202 送信部(出力部)
203 記憶装置制御部
204 分割部
205 変換部
206 算出部
207 分類部
208 カウント部
209 比較部
210 入替部
211 検索部
3 ユーザ端末
300A 通信IF
300B 記憶装置
300C 入力装置
300D 表示装置
300E CPU
301 受信部
302 送信部
303 記憶装置制御部
304 操作受付部
305 表示装置制御部
4 ネットワーク
DB1 ユーザデータベース
DB2 文書データベース
1
200A communication interface
201 receiving unit (first to third receiving units)
202 transmitter (output unit)
203 Storage
300B storage device
Claims (13)
前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する比較部と、
前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する出力部と、
前記類似性に応じて、前記第2文書を所定のグループに分類する分類部と、
前記分類部により分類された前記第2文書の件数を前記グループごとにカウントするカウント部と、を備え、
前記出力部は、
前記カウント部がカウントした前記グループごとの前記第2文書の件数を出力する、
ことを特徴とする情報処理装置。 a calculation unit that calculates the similarity between a first document and a second document different from the first document in units of predetermined regions;
a comparison unit that compares the first document and the second document in units of the predetermined area according to the similarity calculated by the calculation unit;
an output unit for outputting comparison information for displaying the same or different portions of the first document and the second document in a manner different from the others according to the comparison result of the comparison unit ;
a classification unit that classifies the second document into a predetermined group according to the similarity;
a counting unit that counts the number of the second documents classified by the classifying unit for each group;
The output unit
outputting the number of the second documents for each group counted by the counting unit;
An information processing device characterized by:
前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する比較部と、a comparison unit that compares the first document and the second document in units of the predetermined area according to the similarity calculated by the calculation unit;
前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する出力部と、を備え、an output unit that outputs comparison information for displaying the same or different portions of the first document and the second document in a manner different from the others, according to the comparison result of the comparison unit;
前記出力部は、The output unit
前記第1文書との前記類似性が所定値以下の前記第1文書に欠落する前記第2文書の所定領域を出力する、outputting a predetermined region of the second document lacking in the first document whose similarity with the first document is equal to or less than a predetermined value;
ことを特徴とする情報処理装置。An information processing device characterized by:
前記出力部は、
前記第1受付部が前記第1指示を受け付けた場合、指定されたグループに属する前記第2文書を表示させる情報を出力する
ことを特徴とする請求項1に記載の情報処理装置。 a first reception unit that receives a first instruction to display the second documents classified by the classification unit for each group;
The output unit
2. The information processing apparatus according to claim 1 , wherein when said first reception unit receives said first instruction, it outputs information for displaying said second document belonging to a designated group.
前記算出部は、
前記第1文書の編集履歴と、前記第2文書の編集履歴との類似性を所定領域単位で算出し、
前記比較部は、
前記算出部で算出された類似性に応じて、前記第1文書の履歴と、前記第2文書の履歴とを前記所定領域単位で比較する
ことを特徴とする請求項1乃至請求項4のいずれかに記載の情報処理装置。 a storage control unit that stores an edit history of at least one of the first document and the second document;
The calculation unit
calculating the similarity between the editing history of the first document and the editing history of the second document for each predetermined area;
The comparison unit
5. The history of the first document and the history of the second document are compared in units of the predetermined area according to the similarity calculated by the calculation unit. 1. The information processing device according to claim 1.
前記出力部は、
前記第2受付部が前記第2指示を受け付けた場合、前記所定領域以外の領域を表示させる情報を出力する
ことを特徴とする請求項1乃至請求項5のいずれかに記載の情報処理装置。 a second reception unit that receives a second instruction to display an area other than the predetermined area in the second document compared by the comparison unit;
The output unit
6. The information processing apparatus according to any one of claims 1 to 5, wherein when the second reception unit receives the second instruction, it outputs information for displaying an area other than the predetermined area.
条項単位又は項単位であることを特徴とする請求項1乃至請求項6のいずれかに記載の情報処理装置。 The predetermined area unit is
7. The information processing apparatus according to any one of claims 1 to 6 , wherein the information is provided on a clause-by-clause basis or on a claim-by-claim basis.
前記算出部は、
前記所定領域単位で変換されたベクトルに基づいて、前記第1文書と、前記第2文書との類似性を所定領域単位で算出することを特徴とする請求項1乃至請求項7のいずれかに記載の情報処理装置。 a conversion unit that converts the first document and the second document into vectors in units of the predetermined area;
The calculation unit
8. The method according to any one of claims 1 to 7 , wherein the similarity between said first document and said second document is calculated in units of predetermined areas based on the vectors converted in units of said predetermined areas. The information processing device described.
前記第3受付部が受け付けた前記検索ワードに基づいて、前記第1文書又は前記第2文書を検索する検索部と、
を備え、
前記出力部は、
前記検索部による検索された前記検索ワードを他のワードと異なる態様で表示させる検索情報を出力する
ことを特徴とする請求項1乃至請求項8のいずれかに記載の情報処理装置。 a third reception unit that receives a search word for searching the first document or the second document;
a search unit that searches for the first document or the second document based on the search word received by the third reception unit;
with
The output unit
The information processing apparatus according to any one of claims 1 to 8 , wherein search information for displaying the search word searched by the search unit in a manner different from other words is output.
比較部が、前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する工程と、
出力部が、前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する工程と、
分類部が、前記類似性に応じて、前記第2文書を所定のグループに分類する工程と、
カウント部が、前記分類部により分類された前記第2文書の件数を前記グループごとにカウントする工程と、
前記出力部が、前記カウント部がカウントした前記グループごとの前記第2文書の件数を出力する工程と、
を有することを特徴とする情報処理方法。 a step of calculating a similarity between a first document and a second document different from the first document by a calculation unit in units of predetermined regions;
a comparing unit comparing the first document and the second document in units of the predetermined area according to the similarity calculated by the calculating unit;
an output unit outputting comparison information for displaying the same or different portions of the first document and the second document in a manner different from the others, according to the comparison result of the comparison unit ;
a classifying unit classifying the second document into a predetermined group according to the similarity;
a counting unit counting the number of the second documents classified by the classifying unit for each group;
a step in which the output unit outputs the number of the second documents for each group counted by the counting unit;
An information processing method characterized by having
第1文書と、前記第1文書とは異なる第2文書との類似性を所定領域単位で算出する算出部、
前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する比較部、
前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する出力部、
前記類似性に応じて、前記第2文書を所定のグループに分類する分類部、
前記分類部により分類された前記第2文書の件数を前記グループごとにカウントするカウント部、として機能させ、
前記出力部は、
前記カウント部がカウントした前記グループごとの前記第2文書の件数を出力する、
ことを特徴とする情報処理プログラム。 the computer,
a calculation unit that calculates the similarity between a first document and a second document different from the first document in units of predetermined regions;
a comparison unit that compares the first document and the second document in units of the predetermined area according to the similarity calculated by the calculation unit;
an output unit for outputting comparison information for displaying the same or different portions of the first document and the second document in a manner different from the others according to the comparison result of the comparison unit ;
a classification unit that classifies the second document into a predetermined group according to the similarity;
functioning as a counting unit that counts the number of the second documents classified by the classifying unit for each group;
The output unit
outputting the number of the second documents for each group counted by the counting unit;
An information processing program characterized by:
比較部が、前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する工程と、a comparing unit comparing the first document and the second document in units of the predetermined area according to the similarity calculated by the calculating unit;
出力部が、前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する工程と、を有し、an output unit outputting comparison information for displaying the same or different portions of the first document and the second document in a manner different from the others, according to the comparison result of the comparison unit. ,
前記出力部は、The output unit
前記第1文書との前記類似性が所定値以下の前記第1文書に欠落する前記第2文書の所定領域を出力する、outputting a predetermined region of the second document lacking in the first document whose similarity with the first document is equal to or less than a predetermined value;
ことを特徴とする情報処理方法。An information processing method characterized by:
第1文書と、前記第1文書とは異なる第2文書との類似性を所定領域単位で算出する算出部、a calculation unit that calculates the similarity between a first document and a second document different from the first document in units of predetermined regions;
前記算出部で算出された類似性に応じて、前記第1文書と、前記第2文書とを前記所定領域単位で比較する比較部、a comparison unit that compares the first document and the second document in units of the predetermined area according to the similarity calculated by the calculation unit;
前記比較部での比較結果に応じて、前記第1文書と前記第2文書の同一箇所又は異なる箇所を他とは異なる態様で表示させる比較情報を出力する出力部、として機能させ、functioning as an output unit for outputting comparison information for displaying the same or different portions of the first document and the second document in a different manner according to the comparison result of the comparison unit;
前記出力部は、The output unit
前記第1文書との前記類似性が所定値以下の前記第1文書に欠落する前記第2文書の所定領域を出力する、outputting a predetermined region of the second document lacking in the first document whose similarity with the first document is equal to or less than a predetermined value;
ことを特徴とする情報処理プログラム。An information processing program characterized by:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020087379A JP7141133B2 (en) | 2020-05-19 | 2020-05-19 | Information processing device, information processing method and information processing program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020087379A JP7141133B2 (en) | 2020-05-19 | 2020-05-19 | Information processing device, information processing method and information processing program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2021182249A JP2021182249A (en) | 2021-11-25 |
| JP7141133B2 true JP7141133B2 (en) | 2022-09-22 |
Family
ID=78606591
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020087379A Active JP7141133B2 (en) | 2020-05-19 | 2020-05-19 | Information processing device, information processing method and information processing program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7141133B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7749618B2 (en) * | 2023-05-09 | 2025-10-06 | 弁護士ドットコム株式会社 | Program, information processing device, manufacturing method, and information processing method |
| JP7711135B2 (en) * | 2023-08-31 | 2025-07-22 | 弁護士ドットコム株式会社 | Program, method, information processing device, and system |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013175136A (en) | 2012-02-27 | 2013-09-05 | Ntt Comware Corp | Tracing support device, tracing support system, tracing support method, and tracing support program |
-
2020
- 2020-05-19 JP JP2020087379A patent/JP7141133B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013175136A (en) | 2012-02-27 | 2013-09-05 | Ntt Comware Corp | Tracing support device, tracing support system, tracing support method, and tracing support program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021182249A (en) | 2021-11-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9323826B2 (en) | Methods, apparatus and software for analyzing the content of micro-blog messages | |
| US11281852B2 (en) | Systems and methods for automatically creating tables using auto-generated templates | |
| US11645317B2 (en) | Recommending topic clusters for unstructured text documents | |
| JP5316158B2 (en) | Information processing apparatus, full-text search method, full-text search program, and recording medium | |
| Kestemont et al. | Cross-genre authorship verification using unmasking | |
| US20240119236A1 (en) | Creation of component templates based on semantically similar content | |
| US20150019216A1 (en) | Performing an operation relative to tabular data based upon voice input | |
| US20250005018A1 (en) | Information processing method, device, equipment and storage medium based on large language model | |
| US12032566B2 (en) | Clustering suggestions for partial query auto-completion | |
| US20050154690A1 (en) | Document knowledge management apparatus and method | |
| US20120016663A1 (en) | Identifying related names | |
| JP2012093927A (en) | File management device and file management method | |
| TW200805095A (en) | Data product search using related concepts | |
| JP5836893B2 (en) | File management apparatus, file management method, and program | |
| JP7141133B2 (en) | Information processing device, information processing method and information processing program | |
| JP5302614B2 (en) | Facility related information search database formation method and facility related information search system | |
| US20260037554A1 (en) | Document processing method, document processing system, information processing device, and graphic user interface | |
| US20250378259A1 (en) | Systems and methods for structure-based automated hyperlinking | |
| JP7685921B2 (en) | Information processing system, information processing method, and information processing program | |
| JP5269399B2 (en) | Structured document retrieval apparatus, method and program | |
| Zhen | Establishment of an Open Information Platform for the National Sports Center in China | |
| JP2024006420A (en) | Information processing device, information processing system, information processing method, and program | |
| JP2004220226A (en) | Document classification method and device for retrieved document | |
| JP7833487B2 (en) | Information processing device, information processing method, and information processing program | |
| Pratama et al. | The impact of using domain specific features on lexicon based sentiment analysis on Indonesian app review |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A80 | Written request to apply exceptions to lack of novelty of invention |
Free format text: JAPANESE INTERMEDIATE CODE: A80 Effective date: 20200602 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220208 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20220208 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220420 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220506 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220624 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220809 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220902 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7141133 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |