JP2025059651A - Learning database construction system, control device used in said system, and learning database construction method - Google Patents
Learning database construction system, control device used in said system, and learning database construction method Download PDFInfo
- Publication number
- JP2025059651A JP2025059651A JP2023169882A JP2023169882A JP2025059651A JP 2025059651 A JP2025059651 A JP 2025059651A JP 2023169882 A JP2023169882 A JP 2023169882A JP 2023169882 A JP2023169882 A JP 2023169882A JP 2025059651 A JP2025059651 A JP 2025059651A
- Authority
- JP
- Japan
- Prior art keywords
- target object
- dimensional
- information
- camera
- learning database
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B25—HAND TOOLS; PORTABLE POWER-DRIVEN TOOLS; MANIPULATORS
- B25J—MANIPULATORS; CHAMBERS PROVIDED WITH MANIPULATION DEVICES
- B25J13/00—Controls for manipulators
- B25J13/08—Controls for manipulators by means of sensing devices, e.g. viewing or touching devices
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/50—Depth or shape recovery
- G06T7/55—Depth or shape recovery from multiple images
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Mechanical Engineering (AREA)
- Robotics (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Image Analysis (AREA)
- Manipulator (AREA)
- Image Processing (AREA)
Abstract
Description
本発明は学習データベース構築システム、および、該システムに利用される制御装置、並びに、学習データベース構築方法に係る。 The present invention relates to a learning database construction system, a control device used in the system, and a learning database construction method.
従来、画像認識技術におけるAIの機械学習に利用される学習データ(教師データとも呼ばれる)のデータベースを構築するに当たっては、対象とする物体(以下、対象物体という)を高い精度で認識しておくことが望まれる。また、この学習データベースの構築には多くの時間と労力とが必要となっていた。 Conventionally, when constructing a database of learning data (also called teacher data) used in AI machine learning in image recognition technology, it is desirable to recognize the target object (hereinafter referred to as the target object) with high accuracy. In addition, constructing this learning database requires a lot of time and effort.
対象物体を撮影して学習データベースを構築する技術を開示するものとして、特許文献1および特許文献2が知られている。
特許文献1には、学習データセット(学習データベースに相当)の構築段階において、位置姿勢検出用マーカであるARマーカ(2次元パターンマーカ)に対象物体の物体情報を関連付けることが開示されている。また、この特許文献1には、データベースに、ARマーカと対象物体の物体名称等の物体情報とが関連付けられており、学習データセット作製装置のコンピュータがARマーカ認識手段として動作することにより、ARマーカを認識して、対象物体の物体情報を取得することが開示されている。
また、特許文献2には、ワークを把持するシミュレータ上のロボットハンドが把持動作を経て把持を成功させるときのロボットハンドの3次元座標データと、ワークをシミュレータ上の2次元撮像装置IDによって所定画角から撮像した2次元撮像画像データとを備える学習用データセットをシミュレータから取得して複数組記憶するデータセット記憶部と、ワークを2次元撮像装置IDによって所定画角と同じ画角から撮像した2次元撮像画像から、現実世界におけるロボットハンドの3次元座標を推論する学習モデルを構築することが開示されている。 Patent Document 2 also discloses a dataset storage unit that acquires from the simulator a learning dataset comprising three-dimensional coordinate data of the robot hand on the simulator when the robot hand grips a workpiece and successfully grips the workpiece through a gripping operation, and two-dimensional image data of the workpiece captured from a specified angle of view by a two-dimensional imaging device ID on the simulator, and stores multiple sets of the learning dataset, and constructs a learning model that infers the three-dimensional coordinates of the robot hand in the real world from two-dimensional images of the workpiece captured from the same angle of view as the specified angle of view by the two-dimensional imaging device ID.
しかしながら、特許文献1のものは、2次元カメラを使用するものであることから、背景の色と対象物体の色とが似ている場合には、対象物体の認識精度が大幅に低下してしまう虞がある。また、ARマーカを使用していることから、対象物体の姿勢が当該ARマーカを認識できない状態となっている場合には、対象物体の情報を取得することができないものとなるため、物体情報を取得可能な対象物体の姿勢が限定されることとなり、精度の高い学習データベースを構築することが難しかった。
However, because the technique in
また、特許文献2のものは、シミュレーションによる画像を利用するものであることから、現実の対象物体の特徴を十分に表現することはできておらず、対象物体の認識精度の向上には限界があることから、精度の高い学習データベースを構築することが困難であった。 In addition, because the technology in Patent Document 2 uses simulated images, it is unable to fully express the characteristics of real target objects, and there is a limit to how much the target object recognition accuracy can be improved, making it difficult to build a highly accurate learning database.
本発明は、かかる点に鑑みてなされたものであり、その目的とするところは、対象物体の認識精度(例えば対象物体の3次元姿勢の認識精度や対象物体における3次元上の特定位置の認識精度)の向上を図ることができる学習データベースを構築することが可能な学習データベース構築システム、および、該システムに利用される制御装置、並びに、学習データベース構築方法を提供することにある。 The present invention has been made in consideration of the above points, and its purpose is to provide a learning database construction system capable of constructing a learning database that can improve the recognition accuracy of a target object (for example, the recognition accuracy of the three-dimensional posture of a target object or the recognition accuracy of a specific three-dimensional position on the target object), as well as a control device and a learning database construction method used in the system.
前記の目的を達成するための本発明の解決手段は、対象物体を撮影可能な3次元カメラと、前記3次元カメラの位置および姿勢を変更可能な可動体と、前記3次元カメラによって撮影された前記対象物体の画像の情報を取得可能な制御装置とを備え、前記制御装置が、前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成部と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えていることを特徴とする。 The solution of the present invention for achieving the above object comprises a three-dimensional camera capable of photographing a target object, a movable body capable of changing the position and attitude of the three-dimensional camera, and a control device capable of acquiring information on an image of the target object photographed by the three-dimensional camera, the control device being characterized in comprising a three-dimensional information generation unit that generates three-dimensional information of the target object by controlling the movable body to perform three-dimensional photographing of the target object from multiple directions using the three-dimensional camera, an annotation information generation unit that automatically generates annotation information based on the three-dimensional information for an image of the target object photographed by the three-dimensional camera or a camera other than the three-dimensional camera, and a learning database construction unit that constructs a learning database using multiple data of the annotation information and the relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information as learning data.
この特定事項により、学習データベースは、アノテーション情報、および、アノテーション情報の自動生成時に使用したカメラに対する対象物体の相対的な3次元物理情報それぞれの複数データを学習データとして構築されているため、対象物体の認識精度(例えば対象物体の3次元姿勢の認識精度や対象物体における3次元上の特定位置の認識精度)の向上を図ることができる学習データベースを構築することが可能となる。例えば、対象物体に対して特定の処理を行うに際しては、当該対象物体の2次元画像を取得するのみで前記3次元物理情報を得ることができ、この3次元物理情報に基づいて対象物体の認識精度を高めることができて、当該対象物体に対する前記特定の処理を高い精度で実施することが可能となる。 Due to this specification, the learning database is constructed using multiple pieces of learning data, each of which is annotation information and three-dimensional physical information of the target object relative to the camera used when the annotation information was automatically generated, making it possible to construct a learning database that can improve the recognition accuracy of the target object (for example, the recognition accuracy of the three-dimensional posture of the target object and the recognition accuracy of a specific three-dimensional position on the target object). For example, when performing specific processing on the target object, the three-dimensional physical information can be obtained simply by acquiring a two-dimensional image of the target object, and the recognition accuracy of the target object can be improved based on this three-dimensional physical information, making it possible to perform the specific processing on the target object with high accuracy.
また、前記3次元物理情報は、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元姿勢情報である。 The three-dimensional physical information is the relative three-dimensional posture information of the target object with respect to the camera used when automatically generating the annotation information.
これによれば、対象物体の2次元画像を取得するのみで対象物体の相対的な3次元姿勢を認識することができる。例えばロボットによって対象物体を把持する場合に、把持位置の最適化を図ることが可能となる。 This makes it possible to recognize the relative three-dimensional posture of a target object simply by acquiring a two-dimensional image of the target object. For example, when a target object is grasped by a robot, it becomes possible to optimize the grasping position.
また、前記3次元物理情報は、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体における3次元上の特定位置の情報であってもよい。 The three-dimensional physical information may also be information about a specific three-dimensional position of the target object relative to the camera used when automatically generating the annotation information.
これによれば、対象物体の2次元画像を取得するのみで対象物体における3次元上の特定位置を認識することができる。例えばロボットによって対象物体の特定位置を加工する場合に、加工位置を高い精度で特定することが可能となる。 This makes it possible to recognize a specific three-dimensional position on a target object simply by acquiring a two-dimensional image of the target object. For example, when processing a specific position on a target object using a robot, it becomes possible to identify the processing position with high accuracy.
また、前記学習データベース構築システムに利用される制御装置も本発明の技術的思想の範疇である。つまり、可動体に支持されて該可動体の作動によって位置および姿勢を変更可能な3次元カメラによって撮影された対象物体の画像の情報を取得可能な制御装置であって、前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成部と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えたものである。 The control device used in the learning database construction system also falls within the scope of the technical idea of the present invention. In other words, the control device is capable of acquiring information on an image of a target object captured by a three-dimensional camera supported on a movable body and capable of changing the position and attitude by operating the movable body, and includes a three-dimensional information generation unit that generates three-dimensional information on the target object by controlling the movable body to perform three-dimensional photography of the target object from multiple directions using the three-dimensional camera, an annotation information generation unit that automatically generates annotation information based on the three-dimensional information for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera, and a learning database construction unit that constructs a learning database using multiple data on the annotation information and the relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information as learning data.
また、前記学習データベース構築システムにおいて実施される学習データベース構築方法も本発明の技術的思想の範疇である。つまり、3次元カメラを支持する可動体を制御して前記3次元カメラによって対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成工程と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成工程と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築工程とを含むものである。 The learning database construction method implemented in the learning database construction system also falls within the scope of the technical idea of the present invention. In other words, it includes a three-dimensional information generation step of generating three-dimensional information of a target object by controlling a movable body supporting a three-dimensional camera to perform three-dimensional photography of the target object from multiple directions using the three-dimensional camera, an annotation information generation step of automatically generating annotation information based on the three-dimensional information for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera, and a learning database construction step of constructing a learning database using multiple data of the annotation information and the relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information as learning data.
これらの特定事項にあっても、前述したように、対象物体の認識精度(例えば対象物体の3次元姿勢の認識精度や対象物体における3次元上の特定位置の認識精度)の向上を図ることができる学習データベースを構築することが可能となる。 Even with these specific features, as mentioned above, it is possible to construct a learning database that can improve the recognition accuracy of the target object (for example, the recognition accuracy of the target object's three-dimensional orientation or the recognition accuracy of a specific three-dimensional position on the target object).
本発明では、可動体を制御して3次元カメラによって対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する。また、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成する。そして、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築するようにしている。これにより、対象物体の認識精度(例えば対象物体の3次元姿勢の認識精度や対象物体における3次元上の特定位置の認識精度)の向上を図ることができる学習データベースを構築することが可能となる。 In the present invention, three-dimensional information of a target object is generated by controlling a movable body to perform three-dimensional photography in which the target object is photographed from multiple directions by a three-dimensional camera. Furthermore, annotation information is automatically generated based on the three-dimensional information for an image of the target object photographed by the three-dimensional camera or a camera other than the three-dimensional camera. A learning database is then constructed using multiple pieces of learning data, including the annotation information and the three-dimensional physical information of the target object relative to the camera used when automatically generating the annotation information. This makes it possible to construct a learning database that can improve the recognition accuracy of the target object (for example, the recognition accuracy of the three-dimensional posture of the target object or the recognition accuracy of a specific three-dimensional position on the target object).
以下、本発明の実施形態を図面に基づいて説明する。以下に述べる各実施形態は、ロボット(可動体)によって対象物体に所定の処理(例えば対象物体の把持や対象物体における特定位置の加工等)を行うに当たって利用される学習データベース(教師データベース)を構築するものとして本発明を適用した場合について説明する。尚、以下の説明では、同一の部品や構成要素には同一の符号を付している。それらの名称および機能も同じであるため、それらについての詳細な説明は繰り返さない。 Embodiments of the present invention will be described below with reference to the drawings. Each embodiment described below will be applied to the case where the present invention is constructed as a learning database (teacher database) that is used when a robot (movable body) performs a predetermined process on a target object (e.g., grasping the target object or processing a specific position on the target object). In the following description, identical parts and components are given the same reference numerals. As their names and functions are also the same, detailed descriptions of them will not be repeated.
<第1の実施形態>
本実施形態は、3Dカメラ(3次元カメラ)に対する対象物体の3次元姿勢を推定するに当たって利用される学習データベースを構築するものとして本発明を適用した場合について説明する。
First Embodiment
In this embodiment, a case will be described in which the present invention is applied to construct a learning database used for estimating the three-dimensional posture of a target object relative to a 3D camera (three-dimensional camera).
-学習データベース構築システムの全体構成および動作概要-
先ず、図1を参照して、本実施形態に係る学習データベース構築システム1の全体構成について説明する。学習データベース構築システム1は、主たる構成要素として、制御装置10、撮影ロボット20、および、載置装置30等を含んでいる。
-Overall configuration and operation of the learning database construction system-
First, the overall configuration of a learning
制御装置10は、サーバやコンピュータ等によって実現されるものであって、有線LANまたは無線LANを介して撮影ロボット20や載置装置30との間で各種データの送受信を行うことにより、撮影ロボット20に搭載された3Dカメラ24によって撮影された画像の情報を取得する等の各種の処理を実行する。この制御装置10において行われる処理の詳細については後述する。
The
撮影ロボット20は、アーム部27や該アーム部27の先端に取り付けられた作業部28等を備えた多関節ロボットで構成されており、制御装置10から送信される指令情報に基づいて、あるいは自身の判断処理(後述するCPU21での処理)に従って、アーム部27や作業部28等を様々な位置に移動させたり、様々な姿勢に傾けたりする等の各種の作業を実行する。
The
載置装置30は、深層学習やアノテーションの対象となる対象物体40が載置される載置台31を有するものである。この載置台31は、回転したり、傾けたりすることができるものである。 The mounting device 30 has a mounting table 31 on which a target object 40 that is the subject of deep learning or annotation is placed. This mounting table 31 can be rotated and tilted.
そして、制御装置10は、撮影ロボット20のアーム部27を稼働させることで3Dカメラ24の位置や姿勢を変化させ、これによって、載置台31に載置された対象物体40を様々な角度から撮影して、当該対象物体40のアノテーションを自動的に実行したり、当該対象物体40の撮影画像に自動的にバウンディングボックスを付与したり、または、当該撮影画像から当該対象物体40のセグメンテーションを実行したり、更には、3Dカメラ24に対する対象物体40の3次元姿勢を学習データとして取得したりすることができるものである(詳しくは後述する)。
The
このように、本実施形態にかかる学習データベース構築システム1にあっては、作業者の手間を削減した深層学習を可能にするものである。以下では、学習データベース構築システム1の各部の構成および動作について詳細に説明する。
In this way, the learning
-制御装置の構成-
本実施形態にかかる学習データベース構築システム1の構成要素である制御装置10の構成の一態様について図2を用いて説明する。制御装置10は、主たる構成要素として、CPU(Central Processing Unit)11、メモリ12、操作部13、および、通信インターフェイス14等を含んで構成されている。
-Control device configuration-
An embodiment of the configuration of the
CPU11は、メモリ12に記憶されているプログラムを実行することによって、制御装置10の各部を制御する。例えば、CPU11は、メモリ12に格納されているプログラムを実行し、各種のデータを参照することによって、後述する各種の処理を実行する。
The
そして、このCPU11は、前記プログラムによって実現される機能部として、3次元情報生成部11a、アノテーション情報生成部11b、および、学習データベース構築部11cを備えている。以下、これら各部の機能の概略について説明する。
The
3次元情報生成部11aは、撮影ロボット20(特に撮影ロボット20のアーム部27)を制御して3Dカメラ24によって対象物体40を複数の方向から撮影する3次元撮影を実施することによって対象物体40の3次元情報を生成する機能を有している。具体的に、3次元情報生成部11aは、対象物体40だけの3次元情報(3次元画像の情報)を取得する機能を有しており、撮影ロボット20のアーム部27を移動させたり回転させたりすることで、対象物体40の全ての周囲360度分の3次元撮影を行って、取得した360度分のRGB+depth mapから、対象物体40の3次元点群データを作成する機能を有している。
The three-dimensional
アノテーション情報生成部11bは、3Dカメラ24で対象物体40を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成する機能を有している。具体的に、アノテーション情報生成部11bは、対象物体40の3次元点群データと、3Dカメラ24によって対象物体40を撮影した際の撮影方向(アーム部27の姿勢に応じた3Dカメラ24の姿勢により決定される撮影方向)の情報とから、対象物体40に略外接するバウンディングボックス(またはセグメンテーションによる対象物体40の輪郭線)を自動生成する機能を有している。
The annotation
学習データベース構築部11cは、前記アノテーション情報、および、3Dカメラ24に対する対象物体40の相対的な3次元姿勢の情報(本発明でいう3次元物理情報)それぞれの複数データを学習データとした学習データベースを構築する。具体的に、学習データベース構築部11cは、対象物体40を複数方向から撮影することで、各方向それぞれに対応して対象物体40に付与されたバウンディングボックス(またはセグメンテーションによる対象物体40の輪郭線)の情報および対象物体40の3次元姿勢の情報を学習していき(学習データを取得していき)、これら学習データによって学習データベースを構築する機能を有している。
The learning
メモリ12は、各種のRAM、各種のROM等によって実現され、制御装置10に内包されているものであってもよいし、制御装置10の各種インターフェイスに着脱可能なものであってもよいし、制御装置10からアクセス可能な他の装置の記録媒体であってもよい。メモリ12は、CPU11によって実行されるプログラムや、CPU11によるプログラムの実行により生成されたデータ、入力されたデータ、その他の本実施形態で利用されるデータベース等を記憶する。
The
操作部13は、ユーザや管理者等の命令を受け付けて、当該命令をCPU11に入力する。
The
通信インターフェイス14は、CPU11からのデータを、有線LANや無線LANを介して撮影ロボット20に送信したり、逆に、撮影ロボット20からデータ(3Dカメラ24からの3次元画像の情報を含む)を受信してCPU11に受け渡したりする。
The
-撮影ロボットの構成-
次に、学習データベース構築システム1の構成要素である撮影ロボット20の構成の一態様について図3を用いて説明する。撮影ロボット20は、主たる構成要素として、CPU21、メモリ22、操作部23、3Dカメラ24、ライト25、通信インターフェイス26、アーム部27、および、作業部28等を含んで構成されている。
- Configuration of the filming robot -
Next, one embodiment of the configuration of the
CPU21は、メモリ22に記憶されているプログラムを実行することによって、撮影ロボット20の各部を制御する。例えば、撮影ロボット20の各関節部に備えられたモータの回転角度を調整することにより、アーム部27の姿勢を制御する。
The
メモリ22は、各種のRAMや、各種のROM等によって実現され、各種のプログラムや、CPU21によるプログラムの実行により生成されたデータ、制御装置10から与えられた操作命令、操作部23を介して入力されたデータ等を記憶する。
The
操作部23は、ボタンやスイッチ等から構成され、ユーザからの各種の命令を受け付けて、当該命令をCPU21に入力する。
The
3Dカメラ24は、RGB-Dカメラ等によって実現される。この3Dカメラ24は、例えば2つのカメラを利用することによって撮影した画像の各部までの距離を取得することができる。3Dカメラ24は、CPU21からの指示に基づいて、3次元撮影を行ったり、通常の2次元撮影を行ったりする。
The
ライト25は、CPU21からの指示に従って、3Dカメラ24の前方に光を照射するものである。
The light 25 emits light in front of the
通信インターフェイス26は、インターネットやキャリア網やルータ等を介して、制御装置10等の他の装置との間でデータを送受信する。例えば、通信インターフェイス26は、制御装置10から操作命令を受信して、CPU21に受け渡す。
The
アーム部27は、CPU21からの指示に従って、アーム部27に取り付けられた3Dカメラ24の位置や姿勢を制御したり、作業部28の位置や姿勢を制御したりする。3Dカメラ24はアーム部27に固定されている。また、アーム部27の姿勢は、撮影ロボット20の各関節の回転角度位置をモニタすることによって特定できる。このため、アーム部27の姿勢を認識することにより、3Dカメラ24の位置や姿勢を把握できるようになっている。例えば、3Dカメラ24のレンズの光軸に沿う方向(以下、X軸方向という:図8を参照)での座標位置(以下、X軸座標位置という)、当該X軸方向に直交し且つ水平方向に延在する方向(以下、Y軸方向という)での座標位置(以下、Y軸座標位置という)、前記X軸方向およびY軸方向それぞれに直交する方向に延在する方向(以下、Z軸方向という)での座標位置(以下、Z軸座標位置という)を、アーム部27の姿勢を認識することにより把握することが可能である。
The
作業部28は、アーム部27の先端に取り付けられた人の手に相当し、把持動作等を行うもので、CPU21からの指示に従って、対象物体40を把持したり、対象物体40の位置や向きを変更したりするための各種の動作を実行する。
The working
-制御装置の情報処理-
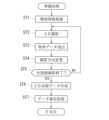
次に、図4を参照して、制御装置10の情報処理について詳述する。制御装置10のCPU11は、深層学習の準備処理として、メモリ12のプログラムに従って、図4に示す処理を実行する。この図4に示す処理は、前記3次元情報生成部11aによる処理である。
-Control device information processing-
Next, the information processing of the
先ず、予め、CPU11は、撮影環境(テーブル、ステージ、ロボット自身等)の3次元形状・位置情報等の3次元CADデータを受け付けて、メモリ12に登録(環境情報登録)しておく(ステップST1)。ここでいう撮影環境は、3Dカメラ24によって撮影される画像中における対象物体40以外の物体(将来的な画像処理において撮影画像から差し引くための物体)であって、例えば、載置装置30や、背景となる壁面や、3Dカメラ24の視野内に作業部28が入り込む状況にあっては当該作業部28等が挙げられる。
First, the
CPU11は、撮影ロボット20のアーム部27に取り付けた3Dカメラ24に対象物体40を撮影させて、RGB+depth mapを取得する(ステップST2)。尚、前述したように、3Dカメラ24は、撮影ロボット20のアーム部27に固定されているため、CPU11は、撮影ロボット20やアーム部27の姿勢情報から、3Dカメラ24の姿勢情報(前述したX軸座標位置、Y軸座標位置、Z軸座標位置等)を計算することができる。
The
CPU11は、ステップST2で撮影したRGB+depth mapから、ステップST1で登録した周囲の物体のデータ(撮影環境のデータ)を差し引くことによって、対象物体40だけの3次元情報(3次元画像の情報)を取得する(ステップST3の物体データ抽出)。
The
CPU11は、撮影ロボット20のアーム部27を移動させたり回転させたり、または、載置台31を回転させたり傾けたりして(ステップST4の撮影方向変更)、別の角度からの撮影を行う(ステップST2の3D撮影)。すなわち、対象物体40の全ての周囲360度分の3次元撮影が完了するまで(ステップST5でYES判定されるまで)、CPU11は、ステップST2からステップST5の処理を繰り返す。
The
CPU11は、対象物体40の360度分のRGB+depth mapから、対象物体40の3次元点群データを作成する(ステップST6の3D点群データ作成)。具体的には、図5に示すように、対象物体40の3次元撮影画像から、3次元の立体点群データが作成される。
The
尚、CPU11は、ステップST6で作成された点群に基づいて、点群が不足している箇所や、ノイズがある箇所に対して、その箇所がより詳細に撮影できるようにアーム部27を動かして3Dカメラ24で追加撮影を行い、3次元点群を再合成することが好ましい(ステップST7のデータ補完処理)。
Furthermore, it is preferable that the
このようにして3次元の立体点群データが作成されるため、この作成された立体点群データが本発明でいう3次元情報に相当し、立体点群データを作成する工程が本発明でいう3次元情報生成工程に相当する。 Three-dimensional point cloud data is created in this manner, and the created point cloud data corresponds to the three-dimensional information referred to in the present invention, and the process of creating the point cloud data corresponds to the three-dimensional information generation process referred to in the present invention.
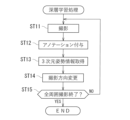
制御装置10のCPU11は、前述した図4で示した準備処理の後、引き続き、深層学習処理として、メモリ12のプログラムに従って、図6に示す処理を実行する。この図6に示す処理は、前記アノテーション情報生成部11bおよび学習データベース構築部11cによる処理である。
After the preparatory process shown in FIG. 4, the
CPU11は、撮影ロボット20のアーム部27に取り付けた3Dカメラ24に対象物体40を2次元撮影させる(ステップST11)。
The
CPU11は、撮影ロボット20やアーム部27の位置情報および姿勢情報と、対象物体40の位置情報および姿勢情報と、対象物体40の3次元点群データとに基づいて、対象物体40の見え方を計算したり、自動的にアノテーション情報を作成したりする(ステップST12)。
The
具体的に、本実施形態においては、例えば図7(a)~(c)に示すように、CPU11は、アノテーション情報として、対象物体40の3次元点群データと撮影方向とから、対象物体40に略外接するバウンディングボックスを自動生成する。図7(a)は対象物体40を正面から撮影した場合に付与されたバウンディングボックスであり、図7(b)は対象物体40を斜め前方から撮影した場合に付与されたバウンディングボックスである。これら図7(a),(b)は、水平線と垂直線とで囲まれるバウンディングボックスを付与した場合を表している。このバウンディングボックスは、水平線と垂直線との交点である4点の座標位置が規定されるものであり、本実施形態の場合、これら4点の座標位置が学習データとなる。
Specifically, in this embodiment, as shown in, for example, FIGS. 7(a) to (c), the
また、図7(c)は対象物体40を斜め後方から撮影した場合に付与された回転バウンディングボックスである。回転バウンディングボックスとは、対象物体40に対する最小外接矩形を設定するに当たり、バウンディングボックスを構成する直線として水平線および垂直線であることの制限を外すことで得られるものであり、水平線および垂直線で規定されるバウンディングボックスよりも小さな領域であって対象物体40に対する最小外接矩形を設定することができるものとなっている。この回転バウンディングボックスを付与した場合にあっては、当該回転バウンディングボックスを構成する各直線同士の交点である4点の座標位置が学習データとなる。 Figure 7(c) shows a rotated bounding box applied when the target object 40 is photographed from diagonally behind. A rotated bounding box is obtained by removing the restriction that the straight lines constituting the bounding box must be horizontal and vertical lines when setting a minimum circumscribing rectangle for the target object 40, and it is possible to set a minimum circumscribing rectangle for the target object 40 in an area smaller than a bounding box defined by horizontal and vertical lines. When this rotated bounding box is applied, the coordinate positions of the four points that are the intersections of the straight lines constituting the rotated bounding box become the learning data.
また、アノテーション情報として、バウンディングボックスに代えて、セグメンテーションを行い、対象物体40の輪郭線(対象物体40と背景とを分ける境界線)を自動生成したものとしてもよい。この場合、対象物体40と背景とを分ける境界線が学習データとなる。 In addition, instead of a bounding box, the annotation information may be an automatically generated contour line of the target object 40 (a boundary line separating the target object 40 from the background) obtained by performing segmentation. In this case, the boundary line separating the target object 40 from the background becomes the learning data.
以上のステップST11,ST12の処理がアノテーション情報生成部11bによって実施されるアノテーション情報生成工程に相当する。
The above steps ST11 and ST12 correspond to the annotation information generation process performed by the annotation
ステップST13では、ステップST12で取得した情報に加えて、当該撮影時点での撮影ロボット20のアーム部27の姿勢(3Dカメラ24の姿勢に対応)と、前述した準備処理において取得した(ステップST2で取得した)対象物体40の3次元姿勢情報とから、当該撮影時点での3Dカメラ24の姿勢において当該3Dカメラ24から見た(3Dカメラ24に対して相対的な)対象物体40の3次元姿勢を取得する。この3次元姿勢も本発明でいう学習データとなる。一般的に、図8に示すように、3Dカメラ24のレンズのX軸方向、Y軸方向、Z軸方向は、対象物体40の設置位置におけるX軸方向(水平方向)、Y軸方向(X軸方向に直交する水平方向)、Z軸方向(鉛直方向)の各軸それぞれにおけるズレ量から、3Dカメラ24に対する対象物体40の3次元姿勢を取得することができる。
In step ST13, in addition to the information acquired in step ST12, the three-dimensional posture of the target object 40 as seen from the 3D camera 24 (relative to the 3D camera 24) in the posture of the
その後、ステップST14において、CPU11は、撮影ロボット20のアーム部27を移動させたり回転させたりすることにより(ステップST14の撮影方向変更)、別の角度からの撮影を行う(ステップST11の撮影)。すなわち、対象物体40の全ての周囲360度分の2次元撮影が完了するまで(ステップST15でYES判定されるまで)、CPU11は、ステップST11からステップST15の処理を繰り返す。これにより、複数方向それぞれに対応して対象物体40に付与されたバウンディングボックス(またはセグメンテーションによる対象物体40の輪郭線)の情報および対象物体40の3次元姿勢の情報(3Dカメラ24に対して相対的な対象物体40の3次元姿勢を)が学習されていく(学習データとして取得されていく)こととなり、これら学習データによって学習データベースが構築されることになる。
Then, in step ST14, the
このような学習データベースが構築されることにより、3Dカメラ24によって一つの2次元画像を取得するのみで、対象物体40の3次元姿勢を推定(推論モデルを生成)することが可能となる。例えば、撮影ロボット20の作業部28によって対象物体40を把持するに当たっては、3Dカメラ24によって一つの2次元画像を取得するのみで、学習データベースを参照しながら(例えば、取得した2次元画像に合致する学習データの抽出により)対象物体40の3次元姿勢を推定して、最適な把持位置に向けて作業部28を移動させることが可能となる。
By constructing such a learning database, it becomes possible to estimate the three-dimensional posture of the target object 40 (generate an inference model) simply by acquiring one two-dimensional image with the
以上のステップST13~ST15の処理が学習データベース構築部11cによって実施される学習データベース構築工程に相当する。
The above steps ST13 to ST15 correspond to the learning database construction process carried out by the learning
-実施形態の効果-
以上説明したように本実施形態では、構築された学習データベースが、アノテーション情報、および、3Dカメラ24に対する対象物体40の相対的な3次元姿勢情報それぞれの複数データを学習データとして構築されている。このため、対象物体40の認識精度(対象物体40の3次元姿勢の認識精度)の向上を図ることができる学習データベースを構築することが可能となる。例えば、撮影ロボット20の作業部28によって対象物体40を把持するに際しては、当該対象物体40の2次元画像を取得するのみで対象物体40の相対的な3次元姿勢情報を得ることができ、この3次元姿勢情報に基づいて対象物体40の認識精度を高めることができて、当該対象物体40を把持するに当たって、最適な位置(例えば対象物体40の重心位置付近)を把持することが可能となる。
--Effects of the embodiment--
As described above, in this embodiment, the constructed learning database is constructed with a plurality of data of annotation information and relative three-dimensional posture information of the target object 40 with respect to the
以下、本発明における他の実施形態について説明する。 Other embodiments of the present invention are described below.
<第2の実施形態>
前述した実施形態に加えて、CPU11は、以前に自動的に作成したアノテーション情報に基づいた対象物体40の深層学習を利用した認識結果を用いることによって、それ以降、対象物体40を含む撮影画像からステップST11で計算された対象物体40のアノテーション情報と、深層学習で認識した情報との類似度を計算し、その類似度が大きい場合には、同様の角度に近い角度をより重点的にアノテーション処理を行うことが好ましい。
Second Embodiment
In addition to the above-described embodiment, it is preferable that the
<第3の実施形態>
前述した実施形態に加えて、撮影ロボット20や載置装置30や天井や壁面等にライトを準備してもよい。そして、ステップST14では、CPU11は、撮影ロボット20のアーム部27を移動させたり回転させたり、ライトをON/OFFしたり、ライトの光度を変更したり、ライトの光の色を変更したりして、別の角度からの撮影を行う。すなわち、対象物体40の周囲360度分の様々な光の状態の2次元撮影が完了するまで(ステップST15でYES判定されるまで)、CPU11は、ステップST11~ST15の処理を繰り返す。
Third Embodiment
In addition to the above-described embodiment, lights may be provided on the photographing
<第4の実施形態>
前述した実施形態に加えて、撮影ロボット20に搭載された作業部28により、対象物体40の向きや姿勢を変更させてもよい。この場合、対象物体40の3次元形状が変化するため、変更した対象物体40の向き・姿勢に関する情報とそのときの対象物体40の3次元形状を紐付けてメモリ12に対象物体40の姿勢毎に別々に保存する。
Fourth Embodiment
In addition to the above-described embodiment, the orientation and posture of the target object 40 may be changed by the working
CPU11は、深層学習処理(図6のフローチャートに示した処理)を実施する際に、メモリ12に保存された対象物体40の向きや姿勢を読み出し、対象物体40がそのとおりの姿勢になるように撮影ロボット20の作業部28により対象物体40の向き・姿勢を登録された状態にした後、深層学習処理を実施する。
When performing the deep learning process (the process shown in the flowchart of FIG. 6), the
<第5の実施形態>
前述した実施形態に加えて、ステップST11において、CPU11は、撮影ロボット20に2次元撮影を実行させたが、撮影ロボット20に3次元撮影を行わせてもよい。そして、各々の3次元撮影データに対して、3D点群データに基づいてアノテーション情報を付与するものであってもよい。
Fifth embodiment
In addition to the above-described embodiment, in step ST11, the
<第6の実施形態>
前述した実施形態においては、図4に示した準備処理で用いる3Dカメラ24を用いて、図6に示した深層学習処理のための撮影も行うものであった。これに限らず、図6に示す深層学習処理のための撮影には、図4の示す準備処理で用いる3Dカメラ24とは別のカメラを利用してもよい。
Sixth Embodiment
In the embodiment described above, the
<第7の実施形態>
前述した実施形態においては、撮影環境(テーブル、ステージ、ロボット自身等)の3次元形状・位置情報等の3次元CADデータを受け付けて、メモリ12に登録しておく形態を示したが、撮影環境の3次元情報も対象物体40と同様の方法で取得してもよい。
Seventh embodiment
In the above-described embodiment, three-dimensional CAD data such as three-dimensional shape and position information of the shooting environment (table, stage, robot itself, etc.) is accepted and registered in
図9を参照して、本実施形態においては、対象物体40を置く前に図4で示した対象物体取得方法と同様の方法で、撮影環境の3次元情報を取得し、環境情報が登録されていない場合(ステップST8でNO判定された場合)、得られた3次元情報を環境データとしてメモリ12に登録しておく(ステップST9)。
Referring to FIG. 9, in this embodiment, before placing the target object 40, three-dimensional information of the shooting environment is acquired in a manner similar to the target object acquisition method shown in FIG. 4, and if the environmental information has not been registered (if a NO judgment is made in step ST8), the acquired three-dimensional information is registered in
それ以降は第1の実施形態と同様の方法で、対象物体40の全ての周囲360度分の3次元撮影が完了するまで(ステップST5でYES判定されるまで)、CPU11は、ステップST2~ステップST5までの処理を繰り返す。
After that, in the same manner as in the first embodiment, the
<第8の実施形態>
前述した実施形態の学習データベース構築システム1の制御装置10や撮影ロボット20等の各装置の役割の一部または全部を他の装置が実行してもよい。例えば、制御装置10の役割の一部を、撮影ロボット20や、複数のパーソナルコンピューターや、クラウド上の複数のサーバで実行したりしてもよい。
Eighth embodiment
Some or all of the roles of the devices such as the
<第9の実施形態>
前述した第1の実施形態のものは、3Dカメラ24に対する対象物体40の3次元姿勢を推定するに当たって利用される学習データベースを構築するものとしていた。本実施形態は、それに代えて、対象物体40における特定位置の把持や特定位置に対する加工等の処理を行うに当たって利用される学習データベースを構築するものとして本発明を適用したものである。
Ninth embodiment
The first embodiment described above is intended to construct a learning database used to estimate the three-dimensional orientation of the target object 40 relative to the
図10は、本実施形態に係る対象物体40の特定位置の推論動作を説明するための図である。図10における対象物体40の位置P1は、作業部28によって把持すべき位置である。例えば対象物体40の重心位置付近の位置である。本実施形態にあっては、前述した学習データベース構築部11cによって取得される学習データを対象物体40上において作業部28によって把持すべき位置(位置P1)として学習させる。つまり、図6を用いて説明した深層学習処理のステップST13において、撮影時点での撮影ロボット20のアーム部27の姿勢(3Dカメラ24の姿勢に対応)と、前述した準備処理において取得した対象物体40の3次元姿勢情報とから、当該撮影時点での3Dカメラ24の姿勢において当該3Dカメラ24から見た(3Dカメラ24に対して相対的な)対象物体40の特定位置(例えば位置P1)を取得することになる。このようにして、対象物体40を複数方向から撮影することで、各方向それぞれに対応して対象物体40に付与されたバウンディングボックス(またはセグメンテーションによる対象物体40の輪郭線)の情報および対象物体40の特定位置の情報を学習していき(学習データを取得していき)、これら学習データによって学習データベースを構築することになる。これにより、一つの2次元画像を取得するのみで、対象物体40上において作業部28によって把持すべき位置を推定することができる。
Figure 10 is a diagram for explaining the inference operation of a specific position of the target object 40 according to this embodiment. The position P1 of the target object 40 in Figure 10 is the position to be grasped by the working
また、この場合、撮影ロボット20のTCP(Tool Center Point)についても学習させておくようにしてもよい。つまり、撮影ロボット20のアーム部27の稼働制御としては、このTCP(例えば図10における位置P2)に基づいて行うと共に、対象物体40の把持に際しては、把持すべき位置(位置P1)に基づいて作業部28の制御を行うようにするものである。
In this case, the TCP (Tool Center Point) of the
また、本実施形態の構成は、対象物体40を把持する場合に限らず、対象物体40における特定位置の加工等を行うものとして利用することもできる。例えば、図10における対象物体40の位置P3を加工(例えば溶接等の加工)する場合に、学習データベース構築部11cによって取得される学習データを対象物体40上における加工位置として学習させることにより、一つの2次元画像を取得するのみで、対象物体40上における加工位置を推定することができる。
The configuration of this embodiment is not limited to gripping the target object 40, and can also be used to process a specific position on the target object 40. For example, when processing (e.g., welding or other processing) position P3 of the target object 40 in FIG. 10, the learning data acquired by the learning
<他の実施形態>
尚、本発明は、前記各実施形態に限定されるものではなく、特許請求の範囲および該範囲と均等の範囲で包含される全ての変形や応用が可能である。
<Other embodiments>
The present invention is not limited to the above-described embodiments, and all modifications and applications within the scope of the claims and equivalents thereto are possible.
例えば、前記各実施形態では、撮影ロボット20によって対象物体40の把持や対象物体40における特定位置の加工を行うに当たって利用される学習データベースを構築するものとして本発明を適用した場合について説明した。本発明はこれに限らず、その他の用途に利用される学習データベースを構築するものとしてもよい。例えば、コンベア上を搬送される対象物体40が所定位置に達した時点での姿勢を認識し、所定姿勢にない対象物体40を作業者に報知したり、撮影ロボット20によって姿勢を修正したりするシステムに利用される学習データベースを構築するものとしてもよい。
For example, in each of the above embodiments, the present invention has been described as being applied to construct a learning database used when the photographing
また、前記各実施形態では、学習データベース構築システム1の構成要素として載置装置30を含んだものとしていたが、この載置装置30は、本発明において必須とする構成要素ではない。例えば、床面上に置いた対象物体40を撮影していくことによって学習データベースを構築するようにしてもよい。
In addition, in each of the above embodiments, the placement device 30 is included as a component of the learning
本発明は、対象物体の認識精度の向上を図るための学習データベース構築システムに適用可能である。 The present invention can be applied to a learning database construction system for improving the recognition accuracy of target objects.
1 学習データベース構築システム
10 制御装置
11a 3次元情報生成部
11b アノテーション情報生成部
11c 学習データベース構築部
20 撮影ロボット(可動体)
24 3Dカメラ(3次元カメラ)
40 対象物体
1 Learning
24 3D camera (three-dimensional camera)
40 Target object
前記の目的を達成するための本発明の解決手段は、対象物体を撮影可能な3次元カメラと、前記3次元カメラの位置および姿勢を変更可能な可動体と、前記3次元カメラによって撮影された前記対象物体の画像の情報を取得可能な制御装置とを備え、前記制御装置が、前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報と前記対象物体を撮影した際の撮影方向の情報とから、前記対象物体に外接するバウンディングボックスをアノテーション情報として自動生成するアノテーション情報生成部と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えており、前記対象物体に外接する前記バウンディングボックスは、当該バウンディングボックスを構成する直線として水平線および垂直線であることの制限を外すことで得られると共に、前記対象物体に対して水平線および垂直線で規定したバウンディングボックスに比べて領域が小さく且つ当該対象物体に対する最小外接矩形を設定する回転バウンディングボックスを含む、ことを特徴とする。 The solution of the present invention for achieving the above object includes a three-dimensional camera capable of photographing a target object, a movable body capable of changing the position and attitude of the three-dimensional camera, and a control device capable of acquiring information on an image of the target object photographed by the three-dimensional camera, the control device comprising a three-dimensional information generation unit that generates three-dimensional information of the target object by controlling the movable body to perform three-dimensional photographing in which the target object is photographed from a plurality of directions by the three-dimensional camera, and a three-dimensional information generation unit that generates a bounding box circumscribing the target object as annotation information from the three-dimensional information and information on the photographing direction when the target object was photographed for an image of the target object photographed by the three-dimensional camera or a camera other than the three-dimensional camera . and a learning database construction unit that constructs a learning database using multiple data of the annotation information and relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information as learning data , wherein the bounding box circumscribing the target object is obtained by removing the restriction that the straight lines that constitute the bounding box are horizontal and vertical lines, and includes a rotated bounding box that has a smaller area than a bounding box defined by horizontal and vertical lines for the target object and sets a minimum circumscribing rectangle for the target object .
また、前記学習データベース構築システムに利用される制御装置も本発明の技術的思想の範疇である。つまり、可動体に支持されて該可動体の作動によって位置および姿勢を変更可能な3次元カメラによって撮影された対象物体の画像の情報を取得可能な制御装置であって、前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報と前記対象物体を撮影した際の撮影方向の情報とから、前記対象物体に外接するバウンディングボックスをアノテーション情報として自動生成するアノテーション情報生成部と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えており、前記対象物体に外接する前記バウンディングボックスは、当該バウンディングボックスを構成する直線として水平線および垂直線であることの制限を外すことで得られると共に、前記対象物体に対して水平線および垂直線で規定したバウンディングボックスに比べて領域が小さく且つ当該対象物体に対する最小外接矩形を設定する回転バウンディングボックスを含むものである。 A control device used in the learning database construction system is also within the scope of the technical idea of the present invention. That is, a control device capable of acquiring information on an image of a target object captured by a three-dimensional camera supported on a movable body and capable of changing the position and orientation by operating the movable body, the control device comprising: a three-dimensional information generating unit that generates three-dimensional information of the target object by controlling the movable body to perform three-dimensional photography in which the target object is captured from a plurality of directions by the three-dimensional camera; and an annotation information generating unit that automatically generates, as annotation information, a bounding box circumscribing the target object from the three-dimensional information and information on the shooting direction when the target object was captured for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera. and a learning database construction unit that constructs a learning database using as learning data multiple data of the annotation information and relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information , wherein the bounding box circumscribing the target object is obtained by removing the restriction that the straight lines that constitute the bounding box are horizontal and vertical lines, and includes a rotated bounding box that has a smaller area than a bounding box defined by horizontal and vertical lines for the target object and sets a minimum circumscribing rectangle for the target object .
また、前記学習データベース構築システムにおいて実施される学習データベース構築方法も本発明の技術的思想の範疇である。つまり、3次元カメラを支持する可動体を制御して前記3次元カメラによって対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成工程と、前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報と前記対象物体を撮影した際の撮影方向の情報とから、前記対象物体に外接するバウンディングボックスをアノテーション情報として自動生成するアノテーション情報生成工程と、前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築工程とを含み、前記対象物体に外接する前記バウンディングボックスは、当該バウンディングボックスを構成する直線として水平線および垂直線であることの制限を外すことで得られると共に、前記対象物体に対して水平線および垂直線で規定したバウンディングボックスに比べて領域が小さく且つ当該対象物体に対する最小外接矩形を設定する回転バウンディングボックスを含んでいるものである。 Furthermore, the learning database construction method implemented in the learning database construction system is also within the scope of the technical idea of the present invention. In other words, the method includes a three-dimensional information generating step of generating three-dimensional information of the target object by controlling a movable body that supports a three-dimensional camera to perform three-dimensional photography in which the target object is photographed from a plurality of directions by the three-dimensional camera; an annotation information generating step of automatically generating a bounding box circumscribing the target object as annotation information from the three-dimensional information and information on the photographing direction when the target object was photographed for an image of the target object photographed by the three-dimensional camera or a camera other than the three-dimensional camera; and a learning database constructing step of constructing a learning database using as learning data a plurality of data of the annotation information and three-dimensional physical information of the target object relative to the camera used when automatically generating the annotation information, wherein the bounding box circumscribing the target object is obtained by removing the restriction that the straight lines constituting the bounding box are horizontal and vertical lines, and includes a rotated bounding box that has a smaller area than a bounding box defined by horizontal and vertical lines for the target object and sets a minimum circumscribing rectangle for the target object .
Claims (5)
前記3次元カメラの位置および姿勢を変更可能な可動体と、
前記3次元カメラによって撮影された前記対象物体の画像の情報を取得可能な制御装置とを備え、
前記制御装置は、
前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、
前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成部と、
前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えていることを特徴とする学習データベース構築システム。 A three-dimensional camera capable of photographing a target object;
a movable body capable of changing the position and attitude of the three-dimensional camera;
a control device capable of acquiring information on an image of the target object captured by the three-dimensional camera,
The control device includes:
a three-dimensional information generating unit that generates three-dimensional information of the target object by controlling the movable body to perform three-dimensional photography in which the target object is photographed from a plurality of directions by the three-dimensional camera;
an annotation information generating unit that automatically generates annotation information based on three-dimensional information for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera;
and a learning database construction unit that constructs a learning database using multiple pieces of data, each of which is the annotation information and the relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information, as learning data.
前記3次元物理情報は、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元姿勢情報であることを特徴とする学習データベース構築システム。 2. The learning database construction system according to claim 1,
A learning database construction system, characterized in that the three-dimensional physical information is relative three-dimensional posture information of the target object with respect to the camera used when automatically generating the annotation information.
前記3次元物理情報は、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体における3次元上の特定位置の情報であることを特徴とする学習データベース構築システム。 2. The learning database construction system according to claim 1,
A learning database construction system, characterized in that the three-dimensional physical information is information on a specific three-dimensional position of the target object relative to the camera used when automatically generating the annotation information.
前記可動体を制御して前記3次元カメラによって前記対象物体を複数の方向から撮影する3次元撮影を実施することによって前記対象物体の3次元情報を生成する3次元情報生成部と、
前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成部と、
前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築部とを備えていることを特徴とする制御装置。 A control device capable of acquiring information on an image of a target object captured by a three-dimensional camera supported on a movable body and capable of changing a position and attitude by operating the movable body, comprising:
a three-dimensional information generating unit that generates three-dimensional information of the target object by controlling the movable body to perform three-dimensional photography in which the target object is photographed from a plurality of directions by the three-dimensional camera;
an annotation information generating unit that automatically generates annotation information based on three-dimensional information for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera;
and a learning database construction unit that constructs a learning database using multiple pieces of data, each of which is the annotation information and the relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information, as learning data.
前記3次元カメラまたは当該3次元カメラとは別のカメラで前記対象物体を撮影した画像に対して前記3次元情報に基づいてアノテーション情報を自動生成するアノテーション情報生成工程と、
前記アノテーション情報、および、前記アノテーション情報の自動生成時に使用した前記カメラに対する前記対象物体の相対的な3次元物理情報それぞれの複数データを学習データとした学習データベースを構築する学習データベース構築工程とを含むことを特徴とする学習データベース構築方法。 a three-dimensional information generating step of generating three-dimensional information of a target object by controlling a movable body supporting a three-dimensional camera to perform three-dimensional photography in which the target object is photographed from a plurality of directions by the three-dimensional camera;
an annotation information generating step of automatically generating annotation information based on three-dimensional information for an image of the target object captured by the three-dimensional camera or a camera other than the three-dimensional camera;
and a learning database construction step of constructing a learning database using as learning data multiple data of the annotation information and relative three-dimensional physical information of the target object with respect to the camera used when automatically generating the annotation information.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023169882A JP2025059651A (en) | 2023-09-29 | 2023-09-29 | Learning database construction system, control device used in said system, and learning database construction method |
| PCT/JP2024/034723 WO2025070751A1 (en) | 2023-09-29 | 2024-09-27 | Training database construction system, control device used in said system, and training database construction method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023169882A JP2025059651A (en) | 2023-09-29 | 2023-09-29 | Learning database construction system, control device used in said system, and learning database construction method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2025059651A true JP2025059651A (en) | 2025-04-10 |
Family
ID=95203269
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023169882A Pending JP2025059651A (en) | 2023-09-29 | 2023-09-29 | Learning database construction system, control device used in said system, and learning database construction method |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP2025059651A (en) |
| WO (1) | WO2025070751A1 (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014130221A (en) * | 2012-12-28 | 2014-07-10 | Canon Inc | Image processing apparatus, control method thereof, image processing system, and program |
| JP2018055177A (en) * | 2016-09-26 | 2018-04-05 | Kddi株式会社 | Information processing unit and program |
| JP2020135679A (en) * | 2019-02-25 | 2020-08-31 | 富士通株式会社 | Data set creation method, dataset creation device, and dataset creation program |
| JP2021012684A (en) * | 2019-06-28 | 2021-02-04 | コニカ ミノルタ ビジネス ソリューションズ ユー.エス.エー., インコーポレイテッド | Detection of finger press from live video stream |
| JP2021131853A (en) * | 2020-02-19 | 2021-09-09 | パロ アルト リサーチ センター インコーポレイテッド | Change detection method and system using AR overlay |
-
2023
- 2023-09-29 JP JP2023169882A patent/JP2025059651A/en active Pending
-
2024
- 2024-09-27 WO PCT/JP2024/034723 patent/WO2025070751A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014130221A (en) * | 2012-12-28 | 2014-07-10 | Canon Inc | Image processing apparatus, control method thereof, image processing system, and program |
| JP2018055177A (en) * | 2016-09-26 | 2018-04-05 | Kddi株式会社 | Information processing unit and program |
| JP2020135679A (en) * | 2019-02-25 | 2020-08-31 | 富士通株式会社 | Data set creation method, dataset creation device, and dataset creation program |
| JP2021012684A (en) * | 2019-06-28 | 2021-02-04 | コニカ ミノルタ ビジネス ソリューションズ ユー.エス.エー., インコーポレイテッド | Detection of finger press from live video stream |
| JP2021131853A (en) * | 2020-02-19 | 2021-09-09 | パロ アルト リサーチ センター インコーポレイテッド | Change detection method and system using AR overlay |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2025070751A1 (en) | 2025-04-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6222898B2 (en) | Three-dimensional measuring device and robot device | |
| JP5949242B2 (en) | Robot system, robot, robot control apparatus, robot control method, and robot control program | |
| JP5471355B2 (en) | 3D visual sensor | |
| CN115213896A (en) | Object grasping method, system, device and storage medium based on robotic arm | |
| CN114912287A (en) | Robot autonomous grabbing simulation system and method based on target 6D pose estimation | |
| CN111085997A (en) | Capturing training method and system based on point cloud acquisition and processing | |
| CN115958589A (en) | Method and device for calibrating hand and eye of robot | |
| JP2012218119A (en) | Information processing apparatus, method for controlling the same, and program | |
| CN107300100B (en) | A Vision-Guided Approximation Method for Cascaded Manipulators Driven by Online CAD Models | |
| WO2022014312A1 (en) | Robot control device and robot control method, and program | |
| JP2013099808A (en) | Assembling apparatus, and method thereof, assembling operation program | |
| CN114193440B (en) | Robot automatic grabbing system and method based on 3D vision | |
| US20190287258A1 (en) | Control Apparatus, Robot System, And Method Of Detecting Object | |
| CN116766194A (en) | Binocular vision-based disc workpiece positioning and grabbing system and method | |
| CN116472551A (en) | Device for adjusting parameters, robot system, method and computer program | |
| TWI660255B (en) | Workpiece processing method and processing system | |
| JP2019158427A (en) | Controller, robot, robot system, and method for recognizing object | |
| CN117621079A (en) | Grasping method, device, electronic equipment and storage medium of robotic arm | |
| US20230150142A1 (en) | Device and method for training a machine learning model for generating descriptor images for images of objects | |
| JP2025059651A (en) | Learning database construction system, control device used in said system, and learning database construction method | |
| JP7833769B2 (en) | Network systems, computers, and deep learning methods | |
| CN113858214A (en) | Positioning method and control system for robot operation | |
| CN119515972A (en) | Generation and position calibration of motion mechanism trajectories and devices | |
| CN114187312A (en) | Target object grabbing method, device, system, storage medium and equipment | |
| JP2010186219A (en) | Template generation system, template matching system, and template generation method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240926 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20241210 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250210 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20250520 |