CN116302532A - A computing power node marking method and device - Google Patents
A computing power node marking method and device Download PDFInfo
- Publication number
- CN116302532A CN116302532A CN202310257513.XA CN202310257513A CN116302532A CN 116302532 A CN116302532 A CN 116302532A CN 202310257513 A CN202310257513 A CN 202310257513A CN 116302532 A CN116302532 A CN 116302532A
- Authority
- CN
- China
- Prior art keywords
- mark
- computing power
- computing
- node
- power node
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/505—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering the load
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本申请公开了一种算力节点标记方法及装置,所述方法包括:获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;获得算力节点的第二标记;第二标记用于衡量所述第一标记的可信度;将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。

The present application discloses a computing power node marking method and device, the method comprising: obtaining the first mark of the computing power node to be marked; the first mark is used to mark the resource utilization level of the computing power node; obtaining the computing power node The second mark; the second mark is used to measure the credibility of the first mark; the first mark and the second mark are used as scheduling marks of computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
Description
技术领域technical field
本申请实施例涉及通信技术领域,特别涉及一种算力节点标记方法、装置、电子设备及可读存储介质。The embodiments of the present application relate to the field of communication technologies, and in particular to a computing power node marking method, device, electronic equipment, and readable storage medium.
背景技术Background technique
目前,边缘云、混合云、分布式云等逐渐成为云计算领域的热点,这就对算力节点的高效调度提出了更高的要求。其中,算计节点包括CPU(Central Processing Unit,中央处理器)、GPU(Graphics Processing Unit,图形处理器)、磁盘和内存等算力资源,当然并不局限于此。At present, edge cloud, hybrid cloud, and distributed cloud have gradually become hot spots in the field of cloud computing, which puts forward higher requirements for efficient scheduling of computing power nodes. Wherein, the calculation node includes CPU (Central Processing Unit, central processing unit), GPU (Graphics Processing Unit, graphics processing unit), disk and memory and other computing power resources, and of course it is not limited thereto.
良好的调度策略可以提高对算力节点的调度效率,使用户能够得到更优质的云服务。而目前对算力节点的标记方案为:给CPU、磁盘IO(Input/Output,输入/输出)等算力节点标记上CPU标签、IO标签等,同时根据分类给任务贴上CPU标签、IO标签或者普通标签,然后进入不同的标签队列。进而,在调度算力节点时,调度器根据标签将算力节点分配给相应的任务。A good scheduling strategy can improve the scheduling efficiency of computing power nodes, so that users can get better cloud services. The current labeling scheme for computing power nodes is: label CPU, disk IO (Input/Output, input/output) and other computing power nodes with CPU labels, IO labels, etc., and at the same time, attach CPU labels and IO labels to tasks according to classification Or ordinary tags, and then enter a different tag queue. Furthermore, when scheduling computing power nodes, the scheduler assigns computing power nodes to corresponding tasks according to labels.
发明人在实现本申请的过程中发现,目前的方案都是基于算力节点的类型或类别作为标签标记节点的,粒度较粗,缺乏量化。而基于此类粗粒度的标签进行调度,无法将任务准确地分配到符合负载条件的算力节点上。In the process of implementing this application, the inventor found that the current schemes are all based on the type or category of the computing power node as the label marking node, the granularity is relatively coarse, and the quantification is lacking. Scheduling based on such coarse-grained tags cannot accurately assign tasks to computing power nodes that meet the load conditions.
发明内容Contents of the invention
本申请实施例提供了一种算力节点标记方法、装置、电子设备及可读存储介质,以通过量化的标签来标记算力节点,使得具有粒度较细的标签,从而使得在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并降低计算优选算力节点的耗时,提升算力节点的利用率。技术方案如下:The embodiment of the present application provides a computing power node marking method, device, electronic equipment, and readable storage medium, so as to mark computing power nodes through quantized tags, so that there are finer-grained tags, so that when scheduling computing power nodes When , tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved. The technical solution is as follows:
根据本申请实施例的一个方面,提供了一种算力节点标记方法,该方法可以包括如下步骤:According to an aspect of an embodiment of the present application, a method for marking computing power nodes is provided, and the method may include the following steps:
获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;Obtain the first mark of the computing power node to be marked; the first mark is used to mark the resource utilization level of the computing power node;
获得算力节点的第二标记;第二标记用于衡量第一标记的可信度;Obtain the second mark of the computing power node; the second mark is used to measure the credibility of the first mark;
将第一标记及第二标记,作为算力节点的调度标记。The first mark and the second mark are used as the scheduling marks of the computing power nodes.
可选地,获得待标记的算力节点的第一标记的步骤,可以包括:Optionally, the step of obtaining the first mark of the computing power node to be marked may include:
基于资源利用率等级确定公式,获得待标记的算力节点的第一标记。Based on the resource utilization level determination formula, the first mark of the computing power node to be marked is obtained.
可选地,资源利用率等级确定公式可以包括:Optionally, the resource utilization rate determination formula may include:

其中,Label_1表示算力节点的第一标记;P1表示当M1<v1时,第一标记对应的资源利用率等级为P1;Pi+1表示当vi+1>M1≥vi时,第一标记对应的资源利用率等级为Pi+1;Pn+1表示当M1≥vn时,第一标记对应的资源利用率等级为Pn+1;Among them, Label_1 indicates the first label of the computing power node; P 1 indicates that when M 1 <v 1 , the resource utilization level corresponding to the first label is P 1 ; P i+1 indicates that when v i+1 >M 1 ≥ When v i , the resource utilization level corresponding to the first mark is P i+1 ; P n+1 means that when M 1 ≥ v n , the resource utilization level corresponding to the first mark is P n+1 ;
M1表示算力节点在第一采样时长内m个采样数据的均值;v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点;i、n、m均为正整数。M 1 represents the average value of the m sampling data of the computing power node within the first sampling period; v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., the i Classification threshold point, ..., the nth classification threshold point; i, n, m are all positive integers.
可选地,获得算力节点的第二标记的步骤可以包括:Optionally, the step of obtaining the second mark of the computing power node may include:
基于变异系数计算公式,获得算力节点的第二标记。Based on the calculation formula of the coefficient of variation, the second mark of the computing power node is obtained.
可选地,变异系数计算公式可以包括:Optionally, the formula for calculating the coefficient of variation may include:

其中,Label_2表示算力节点的第二标记;CV表示变异系数;M2表示算力节点在第二采样时长内p个采样数据的均值;其中,第二采样时长大于第一采样时长;第一采样时长内采样m个采样数据,p大于m;xk表示p个采样数据中第k个采样数据;p、k、m均为正整数。Among them, Label_2 represents the second label of the computing power node; CV represents the coefficient of variation; M 2 represents the mean value of the p sampling data of the computing power node in the second sampling time; where the second sampling time is longer than the first sampling time; the first m sampling data are sampled within the sampling duration, and p is greater than m; x k represents the kth sampling data among the p sampling data; p, k, and m are all positive integers.
可选地,将第一标记及第二标记,作为算力节点的调度标记的步骤,可以包括:Optionally, the step of using the first mark and the second mark as the scheduling mark of the computing power node may include:
按照第一采样时长作为一个更新周期,更新第一标记;Update the first mark according to the first sampling duration as an update period;
按照第二采样时长作为一个更新周期,更新第二标记;其中,第二采样时长大于第一采样时长;Update the second mark according to the second sampling duration as an update period; wherein, the second sampling duration is longer than the first sampling duration;
将更新后的第一标记及第二标记,作为算力节点的调度标记。The updated first mark and the second mark are used as the scheduling marks of the computing power nodes.
可选地,在将第一标记及第二标记,作为算力节点的调度标记之后,还可以包括:Optionally, after using the first mark and the second mark as the scheduling marks of computing power nodes, it may also include:
当接收到针对算力节点的调度指令时,获取具有调度标记的各个算力节点的第一标记;When receiving a scheduling instruction for a computing power node, obtaining a first mark of each computing power node with a scheduling mark;
选择所获取的各个第一标记中资源利用率等级最低的算力节点;Select the computing power node with the lowest level of resource utilization among the obtained first marks;
获取资源利用率等级最低的算力节点的第二标记,作为目标第二标记;Obtain the second mark of the computing power node with the lowest level of resource utilization as the target second mark;
当目标第二标记存在多个时,将目标第二标记中可信度最高的算力节点,选为用于资源调度的算力节点。When there are multiple target second marks, the computing power node with the highest reliability among the target second marks is selected as the computing power node for resource scheduling.
第二方面,本申请实施例还提供了一种算力节点标记装置,该装置可以包括:In the second aspect, the embodiment of the present application also provides a computing power node marking device, which may include:
第一获取模块,用于获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;The first acquisition module is used to obtain the first mark of the computing power node to be marked; the first mark is used to mark the resource utilization level of the computing power node;
第二获取模块,用于获得算力节点的第二标记;第二标记用于衡量第一标记的可信度;The second acquisition module is used to obtain the second mark of the computing power node; the second mark is used to measure the credibility of the first mark;
标记模块,用于将第一标记及第二标记,作为算力节点的调度标记。The marking module is configured to use the first marking and the second marking as scheduling markings of computing power nodes.
可选地,第一获取模块可以具体用于:Optionally, the first acquisition module may be specifically used for:
基于资源利用率等级确定公式,获得待标记的算力节点的第一标记。Based on the resource utilization level determination formula, the first mark of the computing power node to be marked is obtained.
可选地,资源利用率等级确定公式可以包括:Optionally, the resource utilization rate determination formula may include:

其中,Label_1表示算力节点的第一标记;P1表示当M1<v1时,第一标记对应的资源利用率等级为P1;Pi+1表示当vi+1>M1≥vi时,第一标记对应的资源利用率等级为Pi+1;Pn+1表示当M1≥vn时,第一标记对应的资源利用率等级为Pn+1;Among them, Label_1 indicates the first label of the computing power node; P 1 indicates that when M 1 <v 1 , the resource utilization level corresponding to the first label is P 1 ; P i+1 indicates that when v i+1 >M 1 ≥ When v i , the resource utilization level corresponding to the first mark is P i+1 ; P n+1 means that when M 1 ≥ v n , the resource utilization level corresponding to the first mark is P n+1 ;
M1表示算力节点在第一采样时长内m个采样数据的均值;v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点;i、n、m均为正整数。M 1 represents the average value of the m sampling data of the computing power node within the first sampling period; v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., the i Classification threshold point, ..., the nth classification threshold point; i, n, m are all positive integers.
可选地,第二获取模块可以具体用于:Optionally, the second acquisition module can be specifically used for:
基于变异系数计算公式,获得算力节点的第二标记。Based on the calculation formula of the coefficient of variation, the second mark of the computing power node is obtained.
可选地,变异系数计算公式可以包括:Optionally, the formula for calculating the coefficient of variation may include:

其中,Label_2表示算力节点的第二标记;CV表示变异系数;M2表示算力节点在第二采样时长内p个采样数据的均值;其中,第二采样时长大于第一采样时长;第一采样时长内采样m个采样数据,p大于m;xk表示p个采样数据中第k个采样数据;p、k、m均为正整数。Among them, Label_2 represents the second label of the computing power node; CV represents the coefficient of variation; M 2 represents the mean value of the p sampling data of the computing power node in the second sampling time; where the second sampling time is longer than the first sampling time; the first m sampling data are sampled within the sampling duration, and p is greater than m; x k represents the kth sampling data among the p sampling data; p, k, and m are all positive integers.
可选地,标记模块可以包括:Optionally, the marking module can include:
第一更新单元,用于按照第一采样时长作为一个更新周期,更新第一标记;The first update unit is configured to update the first mark according to the first sampling duration as an update cycle;
第二更新单元,用于按照第二采样时长作为一个更新周期,更新第二标记;其中,第二采样时长大于第一采样时长;The second updating unit is configured to update the second mark according to the second sampling duration as an updating period; wherein, the second sampling duration is longer than the first sampling duration;
标记单元,用于将更新后的第一标记及第二标记,作为算力节点的调度标记。The marking unit is configured to use the updated first marking and the second marking as scheduling markings of computing power nodes.
可选地,装置还可以包括:Optionally, the device may also include:
第三获取模块,用于在将第一标记及第二标记,作为算力节点的调度标记之后,当接收到针对算力节点的调度指令时,获取具有调度标记的各个算力节点的第一标记;The third acquisition module is used to obtain the first and second marks of each computing power node with the scheduling mark when receiving a scheduling instruction for the computing power node after using the first mark and the second mark as the scheduling mark of the computing power node. mark;
第一选择模块,用于选择所获取的各个第一标记中资源利用率等级最低的算力节点;The first selection module is configured to select the computing power node with the lowest level of resource utilization among the acquired first tags;
第四获取模块,用于获取资源利用率等级最低的算力节点的第二标记,作为目标第二标记;The fourth obtaining module is used to obtain the second mark of the computing power node with the lowest level of resource utilization as the target second mark;
第二选择模块,用于当目标第二标记存在多个时,将目标第二标记中可信度最高的算力节点,选为用于资源调度的算力节点。The second selection module is configured to select the computing power node with the highest reliability among the target second markings as the computing power node for resource scheduling when there are multiple target second markings.
第三方面,本申请实施例还提供了一种电子设备,电子设备包括处理器和存储器,存储器中存储有计算机程序,计算机程序由处理器加载并执行以实现如第一方面任一项的方法。In the third aspect, the embodiment of the present application also provides an electronic device, the electronic device includes a processor and a memory, and a computer program is stored in the memory, and the computer program is loaded and executed by the processor to implement the method according to any one of the first aspect .
第四方面,本申请实施例还提供了一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,计算机程序由处理器加载并执行以实现如第一方面任一项的方法。In a fourth aspect, the embodiment of the present application further provides a computer-readable storage medium, in which a computer program is stored, and the computer program is loaded and executed by a processor to implement the method according to any one of the first aspect.
本申请实施例提供的技术方案可以包括如下有益效果:The technical solutions provided by the embodiments of the present application may include the following beneficial effects:
本申请实施例提供的算力节点标记方案,可以先获得待标记的算力节点的第一标记,该第一标记用于标记算力节点的资源利用率等级。然后,可以获得算力节点的第二标记,该第二标记用于衡量第一标记的可信度。之后,将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。The computing power node marking scheme provided in the embodiment of the present application can first obtain the first mark of the computing power node to be marked, and the first mark is used to mark the resource utilization level of the computing power node. Then, the second mark of the computing power node can be obtained, and the second mark is used to measure the credibility of the first mark. Afterwards, the first mark and the second mark are used as the scheduling marks of the computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
附图说明Description of drawings
图1是本申请实施例提供的一种算力节点标记方法的流程图;Fig. 1 is a flow chart of a method for marking a computing power node provided by an embodiment of the present application;
图2是本申请实施例提供的另一种算力节点标记方法的流程图;Fig. 2 is a flow chart of another computing power node marking method provided by the embodiment of the present application;
图3是本申请实施例提供的一种算力节点标记装置的结构框图;Fig. 3 is a structural block diagram of a computing power node marking device provided by an embodiment of the present application;
图4是本申请实施例提供的一种电子设备的结构框图。Fig. 4 is a structural block diagram of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。In order to make the purpose, technical solution and advantages of the present application clearer, the implementation manners of the present application will be further described in detail below in conjunction with the accompanying drawings.
目前对算力节点进行标记的方案为:给CPU、磁盘IO等算力节点标记上CPU标签、IO标签等。同时,根据分类给任务贴上CPU标签、IO标签或者普通标签,然后进入不同的标签队列。进而,在调度算力节点时,调度器根据标签将算力节点分配给相应的任务。The current scheme for marking computing power nodes is: to mark CPU, disk IO and other computing power nodes with CPU tags, IO tags, etc. At the same time, assign CPU tags, IO tags, or common tags to tasks according to the classification, and then enter different tag queues. Furthermore, when scheduling computing power nodes, the scheduler assigns computing power nodes to corresponding tasks according to labels.
发明人在实现本申请的过程中发现,目前的方案都是基于算力节点的类型或类别作为标签标记节点的,粒度较粗,缺乏量化。而基于此类粗粒度的标签进行调度,无法将任务准确地分配到符合负载条件的算力节点上。In the process of implementing this application, the inventor found that the current schemes are all based on the type or category of the computing power node as the label marking node, the granularity is relatively coarse, and the quantification is lacking. Scheduling based on such coarse-grained tags cannot accurately assign tasks to computing power nodes that meet the load conditions.
为了解决上述技术问题,本申请实施例提供了一种算力节点标记方法、装置、电子设备及可读存储介质。In order to solve the above technical problems, embodiments of the present application provide a computing power node marking method, device, electronic equipment, and readable storage medium.
下面首先对本申请实施例提供的算力节点标记方法进行说明。本申请实施例提供的算力节点标记方法可以包括如下步骤:The method for marking computing power nodes provided by the embodiment of the present application will first be described below. The computing power node marking method provided in the embodiment of this application may include the following steps:
获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;Obtain the first mark of the computing power node to be marked; the first mark is used to mark the resource utilization level of the computing power node;
获得算力节点的第二标记;第二标记用于衡量第一标记的可信度;Obtain the second mark of the computing power node; the second mark is used to measure the credibility of the first mark;
将第一标记及第二标记,作为算力节点的调度标记。The first mark and the second mark are used as the scheduling marks of the computing power nodes.
应用本申请实施例提供的算力节点标记方案,可以先获得待标记的算力节点的第一标记,该第一标记用于标记算力节点的资源利用率等级。然后,可以获得算力节点的第二标记,该第二标记用于衡量第一标记的可信度。之后,将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。By applying the computing power node marking scheme provided in the embodiment of the present application, the first mark of the computing power node to be marked can be obtained first, and the first mark is used to mark the resource utilization level of the computing power node. Then, the second mark of the computing power node can be obtained, and the second mark is used to measure the credibility of the first mark. Afterwards, the first mark and the second mark are used as the scheduling marks of the computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
下面结合图1和图2对本申请实施例提供的算力节点标记方法进行详细说明。图1是本申请实施例提供的一种算力节点标记方法的流程图,参见图1,该算力节点标记方法可以包括如下步骤:The method for marking computing power nodes provided by the embodiment of the present application will be described in detail below with reference to FIG. 1 and FIG. 2 . Figure 1 is a flow chart of a method for marking a computing power node provided in an embodiment of the present application. Referring to Figure 1, the method for marking a computing power node may include the following steps:
S101:获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;S101: Obtain the first mark of the computing power node to be marked; the first mark is used to mark the resource utilization level of the computing power node;
可以理解的是,第一标记可以用于标记算力节点的资源利用率等级,其表现形式可以是数字、字母或阿拉伯数字,当然并不局限于此。It can be understood that the first mark may be used to mark the resource utilization level of the computing power node, and its expression form may be numbers, letters or Arabic numerals, but of course it is not limited thereto.
例如,资源利用率等级可以为0、1、2、3、……、9。其中,数字越大表明算力节点资源利用率等级越高。又例如,资源利用率等级可以为A、B、C、D、E、F、G、H、I、J。其中,字母位于字母表越靠后的位置,表明算力节点资源利用率等级越高。For example, resource utilization levels may be 0, 1, 2, 3, . . . , 9. Among them, the larger the number, the higher the resource utilization level of the computing power node. For another example, the resource utilization level may be A, B, C, D, E, F, G, H, I, J. Among them, the lower the letter is in the alphabet, the higher the resource utilization level of the computing power node.
算力节点资源利用率等级越高,则表明算力节点的闲置资源越少,反之闲置资源越多。这样,可以通过量化的第一标记来标记算力节点,使得算力节点具有粒度较细的标签。The higher the resource utilization level of the computing power node, the less idle resources the computing power node has, and vice versa, the more idle resources. In this way, computing power nodes can be marked with quantized first tags, so that computing power nodes have labels with a finer granularity.
可以理解的是,狭义概念上的量化是指通过数值来表示。广义概念上的量化是指可以进行比较/比对的表现形式,例如等级A、等级B和等级C,且等级A<B<C。本申请实施例中的量化既可以是狭义上的量化,也可以是广义上的量化,这都是合理的。It can be understood that quantification in a narrow sense refers to representation by numerical value. Quantification in a broad sense refers to the form of expression that can be compared/compared, such as grade A, grade B and grade C, and grade A<B<C. Quantification in the embodiments of the present application can be quantification in a narrow sense or in a broad sense, all of which are reasonable.
可选地,可以基于资源利用率等级确定公式,来获得待标记的算力节点的第一标记。该资源利用率等级确定公式可以为:Optionally, the first mark of the computing power node to be marked may be obtained based on a resource utilization level determination formula. The formula for determining the resource utilization level may be:
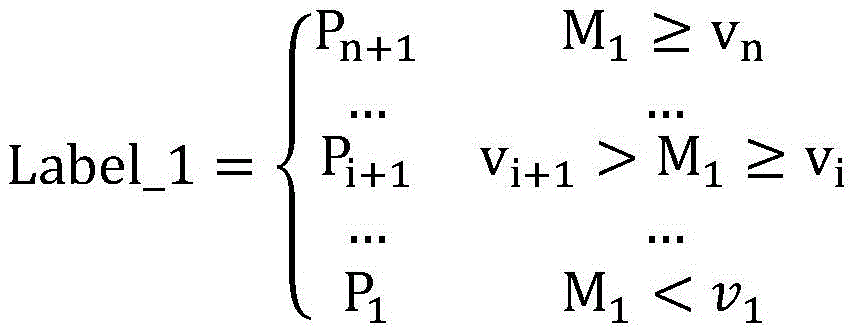
其中,Label_1表示算力节点的第一标记;P1表示当M1<v1时,第一标记对应的资源利用率等级为P1;Pi+1表示当vi+1>M1≥vi时,第一标记对应的资源利用率等级为Pi+1;Pn+1表示当M1≥vn时,第一标记对应的资源利用率等级为Pn+1。其中,P1表示第一资源利用率等级、……、Pi表示第i资源利用率等级、……、Pn+1表示第n+1资源利用率等级。Among them, Label_1 indicates the first label of the computing power node; P 1 indicates that when M 1 <v 1 , the resource utilization level corresponding to the first label is P 1 ; P i+1 indicates that when v i+1 >M 1 ≥ When v i , the resource utilization level corresponding to the first flag is P i+1 ; P n+1 means that when M 1 ≥ v n , the resource utilization level corresponding to the first flag is P n+1 . Wherein, P 1 represents the first resource utilization rate level, ..., P i represents the i-th resource utilization rate level, ..., P n+1 represents the n+1-th resource utilization rate level.
M1表示算力节点在第一采样时长内m个采样数据的均值;v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点;i、n、m均为正整数。其中,本领域技术人员可以根据经验和/或标签精细度要求预先设置上述分级阈值点,当然并不局限于此。M 1 represents the average value of the m sampling data of the computing power node within the first sampling period; v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., the i Classification threshold point, ..., the nth classification threshold point; i, n, m are all positive integers. Wherein, those skilled in the art may pre-set the above classification threshold points according to experience and/or label fineness requirements, and of course it is not limited thereto.
可以理解的是,资源利用率等级确定公式并不局限于上述内容。其中,本领域技术人员还可以根据算力节点的具体情况,给上述均值配置一个权重系数,当然并不局限于此。It can be understood that the formula for determining the resource utilization level is not limited to the above content. Among them, those skilled in the art can also configure a weight coefficient for the above mean value according to the specific conditions of the computing power node, and of course it is not limited thereto.
其中,通过资源利用率等级确定公式,可以基于预设的分级阈值点与算力节点在第一采样时长内m个采样数据的均值进行比较,并根据比对结果映射到相应的资源利用率等级。这样,可以获得关于算力节点的资源利用率等级信息,即获得算力节点的闲置资源信息。Among them, through the determination formula of the resource utilization rate, the preset grading threshold point can be compared with the mean value of the m sampling data of the computing power node in the first sampling period, and mapped to the corresponding resource utilization rate level according to the comparison result . In this way, information about resource utilization levels of computing power nodes can be obtained, that is, idle resource information of computing power nodes can be obtained.
S102:获得算力节点的第二标记;第二标记用于衡量第一标记的可信度;S102: Obtain the second mark of the computing power node; the second mark is used to measure the credibility of the first mark;
可以理解的是,第二标记可以用于标记算力节点的第一标记可信度。可信度越高,表明针对第一标记对应的资源利用率等级的确定结果可信度越高。其中,可以用阿拉伯数字、百分数数字,字母等来表示第一标记的可信度,当然并不局限于此。It can be understood that the second mark may be used to mark the credibility of the first mark of the computing power node. The higher the reliability, the higher the reliability of the determination result for the resource utilization level corresponding to the first mark. Wherein, Arabic numerals, percentage figures, letters, etc. may be used to represent the credibility of the first mark, and of course it is not limited thereto.
举例而言,可信度可以为0、1、2、3、……、9。其中,阿拉伯数字越大表明可信度越高,即针对第一标记对应的资源利用率等级的确定结果可信度越高。又例如,可信度可以为10%、20%等等。其中,百分数数字的数值越高,表明可信度越高。For example, the reliability may be 0, 1, 2, 3, . . . , 9. Wherein, the larger the Arabic numeral, the higher the reliability, that is, the higher the reliability of the determination result of the resource utilization level corresponding to the first mark. For another example, the confidence level may be 10%, 20% and so on. Among them, the higher the value of the percentage figure, the higher the reliability.
当然,第二标记还可以通过变异系数来衡量算力节点的第一标记的可信度。其中,变异系数越大表明偏离程度越大,风险也就越大,可信度越低;变异系数越小表明偏离程度越小,风险也就越小,可信度越高。可选地,可以基于变异系数计算公式,获得算力节点的第二标记。其中,该变异系数计算公式可以为:Of course, the second mark can also measure the credibility of the first mark of the computing power node through the coefficient of variation. Among them, the larger the coefficient of variation, the greater the degree of deviation, the greater the risk, and the lower the credibility; the smaller the coefficient of variation, the smaller the degree of deviation, the smaller the risk, and the higher the credibility. Optionally, the second mark of the computing power node can be obtained based on the calculation formula of the coefficient of variation. Wherein, the formula for calculating the coefficient of variation can be:

其中,Label_2表示算力节点的第二标记;CV表示变异系数;M2表示算力节点在第二采样时长内p个采样数据的均值;其中,第二采样时长大于第一采样时长;第一采样时长内采样m个采样数据,p大于m;xk表示p个采样数据中第k个采样数据;p、k、m均为正整数。Among them, Label_2 represents the second label of the computing power node; CV represents the coefficient of variation; M 2 represents the mean value of the p sampling data of the computing power node in the second sampling time; where the second sampling time is longer than the first sampling time; the first m sampling data are sampled within the sampling duration, and p is greater than m; x k represents the kth sampling data among the p sampling data; p, k, and m are all positive integers.
可以理解的是,变异系数计算公式并不局限于上述内容。其中,本领域技术人员还可以根据算力节点的具体情况,给上述变异系数CV配置一个校准系数,当然并不局限于此。It can be understood that the formula for calculating the coefficient of variation is not limited to the above content. Wherein, those skilled in the art can also configure a calibration coefficient for the above variation coefficient CV according to the specific conditions of the computing power node, and of course it is not limited thereto.
这样,通过变异系数计算公式计算出变异系数,并可以通过变异系数确定第一标记对应的资源利用率等级的可信程度。In this way, the coefficient of variation is calculated through the formula for calculating the coefficient of variation, and the degree of reliability of the resource utilization level corresponding to the first mark can be determined through the coefficient of variation.
S103:将第一标记及第二标记,作为算力节点的调度标记。S103: Use the first mark and the second mark as scheduling marks of computing power nodes.
可以理解的是,将第一标记及第二标记,作为算力节点的调度标记。这样,可以通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。It can be understood that the first mark and the second mark are used as scheduling marks of computing power nodes. In this way, the computing power nodes can be marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels.
从而,在调度算力节点时,可以基于第一标记,优先选择资源利用率等级低的算力节点进行调度,这样可以快速筛选出具备较多闲置资源能的算力节点,使之尽快且高效地工作。Therefore, when scheduling computing power nodes, based on the first mark, computing power nodes with low resource utilization levels can be preferentially selected for scheduling, so that computing power nodes with more idle resource capabilities can be quickly screened out, making them as fast and efficient as possible work.
当资源利用率等级最低的算力节点具有多个时,还可以基于第二标记选出可信度高的算力节点,使得可以从多个资源利用率等级最低的算力节点中,挑选出更具可靠性的算力节点。这样,可以将任务准确地分配到符合负载条件的算力节点上,而且可以降低计算优选算力节点的耗时,并提升算力节点的利用率。When there are multiple computing power nodes with the lowest level of resource utilization, a computing power node with high reliability can also be selected based on the second flag, so that it can be selected from multiple computing power nodes with the lowest level of resource utilization More reliable computing nodes. In this way, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
由于算力节点的资源状态一直是处于动态变化中的,因而为了可以获得更准确的调度标签,上述将第一标记及第二标记,作为算力节点的调度标记的步骤,具体可以包括:Since the resource status of computing power nodes is always changing dynamically, in order to obtain more accurate scheduling labels, the above-mentioned steps of using the first label and the second label as the scheduling labels of computing power nodes may specifically include:
按照第一采样时长作为一个更新周期,更新第一标记;Update the first mark according to the first sampling duration as an update period;
按照第二采样时长作为一个更新周期,更新第二标记;其中,第二采样时长大于第一采样时长;Update the second mark according to the second sampling duration as an update period; wherein, the second sampling duration is longer than the first sampling duration;
将更新后的第一标记及第二标记,作为算力节点的调度标记。The updated first mark and the second mark are used as the scheduling marks of the computing power nodes.
这样,可以通过第一采样时长和第二采样时长作为更新周期,动态更新第一标记和第二标记,使得可以获得更准确的调度标签。In this way, the first flag and the second flag can be dynamically updated by using the first sampling duration and the second sampling duration as an update period, so that more accurate scheduling labels can be obtained.
其中,第二采样时长大于第一采样时长,也就是,第一标记采用较短时间区间的采样,第二标记采用较长时间区间的采样。这样,较短时间区间内的数据可以更准确的表征当前节点的资源利用率等级,而较长时间区间的数据更准确评估第一标记的可信度。该种处理方式,可以使得所获得第一标记和第二标记更加准确。Wherein, the second sampling duration is longer than the first sampling duration, that is, the first mark adopts sampling in a shorter time interval, and the second mark adopts sampling in a longer time interval. In this way, the data in a shorter time interval can more accurately represent the resource utilization level of the current node, and the data in a longer time interval can more accurately evaluate the credibility of the first mark. This processing method can make the obtained first mark and second mark more accurate.
为了提高调度效率,在将第一标记及第二标记,作为算力节点的调度标记之后,还可以包括:In order to improve the scheduling efficiency, after using the first mark and the second mark as the scheduling mark of the computing power node, it can also include:
当接收到针对算力节点的调度指令时,获取具有调度标记的各个算力节点的第一标记;When receiving a scheduling instruction for a computing power node, obtaining a first mark of each computing power node with a scheduling mark;
选择所获取的各个第一标记中资源利用率等级最低的算力节点;Select the computing power node with the lowest level of resource utilization among the obtained first marks;
获取资源利用率等级最低的算力节点的第二标记,作为目标第二标记;Obtain the second mark of the computing power node with the lowest level of resource utilization as the target second mark;
当目标第二标记存在多个时,将目标第二标记中可信度最高的算力节点,选为用于资源调度的算力节点。When there are multiple target second marks, the computing power node with the highest reliability among the target second marks is selected as the computing power node for resource scheduling.
这样,通过对算力节点的运行状态进行定量标记,使标签能够更准确、更可靠地反应所属算力节点的资源状态。而且,在进行算力节点调度时,无需耗费大量时间和计算资源计算最优的算力节点。这样。可以将任务快速、准确地分配到符合负载条件的算力节点上,提高了算力节点的资源利用率。In this way, by quantitatively marking the operating status of the computing power node, the label can more accurately and reliably reflect the resource status of the computing power node to which it belongs. Moreover, when scheduling computing power nodes, there is no need to spend a lot of time and computing resources to calculate the optimal computing power nodes. so. Tasks can be quickly and accurately assigned to computing power nodes that meet the load conditions, improving the resource utilization of computing power nodes.
下面结合具体示例,对本申请实施例提供的算力节点标记方法进行详细说明。图2是本申请实施例提供的另一种算力节点标记方法的流程图,参见图2,该算力节点标记方法可以包括如下步骤:The method for marking computing power nodes provided by the embodiment of the present application will be described in detail below with reference to specific examples. Fig. 2 is a flow chart of another computing power node marking method provided in the embodiment of the present application. Referring to Fig. 2, the computing power node marking method may include the following steps:
S201:初始化待标记算力节点的参数配置,启动计时器。S201: Initialize the parameter configuration of the computing power node to be marked, and start the timer.
首先,可以初始化待标记的算力节点的第一标记Label_1=0和第二标记Label_2=0。First, the first label Label_1=0 and the second label Label_2=0 of the computing nodes to be labeled may be initialized.
然后,初始化预设监控指标X的分级阈值点序列V={v1…,vi,…,vn}。其中,v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点。Then, the grading threshold point sequence V={v 1 . . . , v i , . . . , v n } of the preset monitoring index X is initialized. Wherein, v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., i-th classification threshold point, ..., n-th classification threshold point.
之后,初始化分级状态集P={P1,…,Pi,…,Pn+1}。其中,P1表示第一资源利用率等级、……、Pi表示第i资源利用率等级、……、Pn+1表示第n+1资源利用率等级。i、n为正整数。Afterwards, the hierarchical state set P={P 1 , . . . , P i , . . . , P n+1 } is initialized. Wherein, P 1 represents the first resource utilization rate level, ..., P i represents the i-th resource utilization rate level, ..., P n+1 represents the n+1-th resource utilization rate level. i and n are positive integers.
另外,可以初始化计时器timer=0和重置计时器的时间间隔T,并初始化第一采样时长T1和第二采样时长T2,且T2>T1。In addition, the timer timer=0 may be initialized and the time interval T for resetting the timer may be initialized, and the first sampling duration T1 and the second sampling duration T2 may be initialized, and T2>T1.
S202:当达到重置计时器的时间间隔T时,重置计时器;并获取在当前时刻之前的第一采样时长T1内的第一采样数据序列和第二采样时长T2内的第二采样数据序列。S202: When the time interval T for resetting the timer is reached, reset the timer; and obtain the first sampling data sequence within the first sampling duration T1 before the current moment and the second sampling data within the second sampling duration T2 sequence.
具体地,可以启动计时器timer,当达到时间间隔T时,重置计时器;同时,获取监控指标X在当前时刻之前的第一采样时长T1时间区间内的第一采样数据序列X1={x1…,xk,…,xm}和在当前时刻之前的第二采样时长T2时间区间内的第二采样数据序列X2={x1…,xk,…,xm,…,xp}。p、k、m为正整数,p大于m。Specifically, the timer timer can be started, and when the time interval T is reached, the timer is reset; at the same time, the first sampling data sequence X1={x 1 ...,x k ,...,x m } and the second sampling data sequence X2={x 1 ...,x k ,...,x m ,...,x p in the second sampling duration T2 time interval before the current moment }. p, k, and m are positive integers, and p is greater than m.
x1…,xk,…,xm表示第一采样数据序列中的m个采样数据;x1…,xk,…,xm,…,xp表示在第二采样数据序列中的p个采样数据。x 1 ..., x k , ..., x m represent m sampling data in the first sampling data sequence; x 1 ..., x k , ..., x m , ..., x p represent p in the second sampling data sequence sample data.
S203:计算第一采样数据序列的均值,然后与分级阈值点序列中的各分级阈值点进行比较,获得分级状态集对应的分级状态,并作为第一标记。S203: Calculate the mean value of the first sampled data sequence, and then compare it with each classification threshold point in the classification threshold point sequence to obtain a classification state corresponding to the classification state set, and use it as a first mark.
其中,第一采样数据序列X1的均值可以用公式

P1表示当M1<v1时,第一标记对应的资源利用率等级为P1;Pi+1表示当vi+1>M1≥vi时,第一标记对应的资源利用率等级为Pi+1;Pn+1表示当M1≥vn时,第一标记对应的资源利用率等级为Pn+1;P 1 indicates that when M 1 <v 1 , the resource utilization level corresponding to the first mark is P 1 ; P i+1 indicates that when v i+1 >M 1 ≥ v i , the resource utilization rate corresponding to the first mark The level is P i+1 ; P n+1 means that when M 1 ≥ v n , the resource utilization level corresponding to the first mark is P n+1 ;
M1表示算力节点在第一采样时长内m个采样数据的均值;v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点;i、n、m均为正整数。M 1 represents the average value of the m sampling data of the computing power node within the first sampling period; v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., the i Classification threshold point, ..., the nth classification threshold point; i, n, m are all positive integers.
S204:计算第二采样数据序列对应的变异系数,作为第二标记。S204: Calculate the coefficient of variation corresponding to the second sampled data sequence as a second mark.
具体的,可以通过如下变异系数计算公式,计算第二标记:Specifically, the second marker can be calculated by the following coefficient of variation calculation formula:

其中,第二采样数据序列X2的均值
S205:更新算力节点对应第一标记和第二标记,作为算力节点更新后的调度标记;基于计时器的计时,重复执行上述步骤。S205: Update the computing power node corresponding to the first mark and the second mark as the updated scheduling mark of the computing power node; based on the timing of the timer, repeat the above steps.
为了清晰说明,利用待标记的算力节点为CPU作为示例,对本申请实施例提供的算力节点标记方法进行再次说明。For clarity, the computing power node marking method provided in the embodiment of the present application is described again by using the computing power node to be marked as a CPU as an example.
参见表1,表1展示了5个CPU算力节点在设定的第一采样时长和第二采样时长内针对CPU资源利用率的采样数据。See Table 1. Table 1 shows the sampling data of CPU resource utilization of 5 CPU computing power nodes within the set first sampling period and the second sampling period.

表1Table 1
从表1可见,在第一采样时长内采集了每个算力节点的5个采样数据,在第二采样时长内采集了每个算力节点10个采样数据。其中,第一采样时长与第二采样时长的计时开始时刻相同。另外,采样频率为采样设备所设置的采样频率。It can be seen from Table 1 that 5 sampling data of each computing power node are collected in the first sampling period, and 10 sampling data of each computing power node are collected in the second sampling period. Wherein, timing start times of the first sampling duration and the second sampling duration are the same. In addition, the sampling frequency is the sampling frequency set by the sampling device.
另外,技术人员可以设定设定分级阈值点序列为[10,20,30,40,50,60,70,80,90],分级状态集为[0,1,2,3,4,5,6,7,8,9]。从而,可以基于上述资源利用率等级确定公式及变异系数计算公式,计算得到第一标记和第二标记,计算结果参加表2。In addition, technicians can set the grading threshold point sequence as [10, 20, 30, 40, 50, 60, 70, 80, 90], and the grading state set as [0, 1, 2, 3, 4, 5 , 6, 7, 8, 9]. Therefore, the first mark and the second mark can be calculated based on the above resource utilization level determination formula and variation coefficient calculation formula, and the calculation results are listed in Table 2.


表2Table 2
可以理解的是,可以通过设置更细粒度的分级阈值,进一步细化第一标记;或者在高位采用细粒度的阈值、在低位采用粗粒度的阈值,例如[20,40,50,60,70,75,80,82.5,85,87.5,90]来进一步细化第一标记,进而提供更细粒度的第一标记。进而,在节点调度过程中,可以通过第一标记、第二标记快速筛选出候选节点。It can be understood that the first mark can be further refined by setting a finer-grained classification threshold; or adopt a fine-grained threshold at a high position and a coarse-grained threshold at a low position, for example [20, 40, 50, 60, 70 , 75, 80, 82.5, 85, 87.5, 90] to further refine the first label, thereby providing a finer-grained first label. Furthermore, during the node scheduling process, candidate nodes can be quickly screened out by the first mark and the second mark.
相应于上述方法实施例,本申请实施例还提供了一种算力节点标记装置,参见图3,该装置可以包括:Corresponding to the above method embodiment, the embodiment of the present application also provides a computing power node marking device, see Figure 3, the device may include:
第一获取模块301,用于获得待标记的算力节点的第一标记;第一标记用于标记算力节点的资源利用率等级;The first obtaining
第二获取模块302,用于获得算力节点的第二标记;第二标记用于衡量第一标记的可信度;The second acquiring
标记模块303,用于将第一标记及第二标记,作为算力节点的调度标记。The marking
可选地,第一获取模块301可以具体用于:Optionally, the first acquiring
基于资源利用率等级确定公式,获得待标记的算力节点的第一标记。Based on the resource utilization level determination formula, the first mark of the computing power node to be marked is obtained.
可选地,资源利用率等级确定公式可以包括:Optionally, the resource utilization rate determination formula may include:

其中,Label_1表示算力节点的第一标记;P1表示当M1<v1时,第一标记对应的资源利用率等级为P1;Pi+1表示当vi+1>M1≥vi时,第一标记对应的资源利用率等级为Pi+1;Pn+1表示当M1≥vn时,第一标记对应的资源利用率等级为Pn+1;Among them, Label_1 indicates the first label of the computing power node; P 1 indicates that when M 1 <v 1 , the resource utilization level corresponding to the first label is P 1 ; P i+1 indicates that when v i+1 >M 1 ≥ When v i , the resource utilization level corresponding to the first mark is P i+1 ; P n+1 means that when M 1 ≥ v n , the resource utilization level corresponding to the first mark is P n+1 ;
M1表示算力节点在第一采样时长内m个采样数据的均值;v1、……、vi、……、vn表示预设的第一个分级阈值点、……、第i个分级阈值点、……、第n个分级阈值点;i、n、m均为正整数。M 1 represents the average value of the m sampling data of the computing power node within the first sampling period; v 1 , ..., vi , ..., v n represent the preset first classification threshold point, ..., the i Classification threshold point, ..., the nth classification threshold point; i, n, m are all positive integers.
可选地,第二获取模块302可以具体用于:Optionally, the second obtaining
基于变异系数计算公式,获得算力节点的第二标记。Based on the calculation formula of the coefficient of variation, the second mark of the computing power node is obtained.
可选地,变异系数计算公式可以包括:Optionally, the formula for calculating the coefficient of variation may include:

其中,Label_2表示算力节点的第二标记;CV表示变异系数;M2表示算力节点在第二采样时长内p个采样数据的均值;其中,第二采样时长大于第一采样时长;第一采样时长内采样m个采样数据,p大于m;xk表示p个采样数据中第k个采样数据;p、k、m均为正整数。Among them, Label_2 represents the second label of the computing power node; CV represents the coefficient of variation; M 2 represents the mean value of the p sampling data of the computing power node in the second sampling time; where the second sampling time is longer than the first sampling time; the first m sampling data are sampled within the sampling duration, and p is greater than m; x k represents the kth sampling data among the p sampling data; p, k, and m are all positive integers.
可选地,标记模块303可以包括:Optionally, the marking
第一更新单元,用于按照第一采样时长作为一个更新周期,更新第一标记;The first update unit is configured to update the first mark according to the first sampling duration as an update period;
第二更新单元,用于按照第二采样时长作为一个更新周期,更新第二标记;其中,第二采样时长大于第一采样时长;The second updating unit is configured to update the second mark according to the second sampling duration as an updating period; wherein, the second sampling duration is longer than the first sampling duration;
标记单元,用于将更新后的第一标记及第二标记,作为算力节点的调度标记。The marking unit is configured to use the updated first marking and the second marking as scheduling markings of computing power nodes.
可选地,装置还可以包括:Optionally, the device may also include:
第三获取模块,用于在将第一标记及第二标记,作为算力节点的调度标记之后,当接收到针对算力节点的调度指令时,获取具有调度标记的各个算力节点的第一标记;The third acquisition module is used to obtain the first and second marks of each computing power node with the scheduling mark when receiving a scheduling instruction for the computing power node after using the first mark and the second mark as the scheduling mark of the computing power node. mark;
第一选择模块,用于选择所获取的各个第一标记中资源利用率等级最低的算力节点;The first selection module is configured to select the computing power node with the lowest level of resource utilization among the acquired first tags;
第四获取模块,用于获取资源利用率等级最低的算力节点的第二标记,作为目标第二标记;The fourth obtaining module is used to obtain the second mark of the computing power node with the lowest level of resource utilization as the target second mark;
第二选择模块,用于当目标第二标记存在多个时,将目标第二标记中可信度最高的算力节点,选为用于资源调度的算力节点。The second selection module is configured to select the computing power node with the highest reliability among the target second markings as the computing power node for resource scheduling when there are multiple target second markings.
应用本申请实施例提供的算力节点标记装置,可以先获得待标记的算力节点的第一标记,该第一标记用于标记算力节点的资源利用率等级。然后,可以获得算力节点的第二标记,该第二标记用于衡量第一标记的可信度。之后,将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。By using the computing power node marking device provided in the embodiment of the present application, the first mark of the computing power node to be marked can be obtained first, and the first mark is used to mark the resource utilization level of the computing power node. Then, the second mark of the computing power node can be obtained, and the second mark is used to measure the credibility of the first mark. Afterwards, the first mark and the second mark are used as the scheduling marks of the computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
需要说明的是,上述实施例提供的装置,在实现其功能时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。It should be noted that, when realizing the functions of the device provided by the above-mentioned embodiments, the division of the above-mentioned functional modules is used as an example for illustration. In practical applications, the above-mentioned function allocation can be completed by different functional modules according to the needs. The internal structure of the device is divided into different functional modules to complete all or part of the functions described above. In addition, the device and the method embodiment provided by the above embodiment belong to the same idea, and the specific implementation process thereof is detailed in the method embodiment, and will not be repeated here.
本申请实施例还提供了一种电子设备,参见图4,图4是本申请一个实施例提供的电子设备的结构框图。电子设备包括处理器401和存储器402,存储器402中存储有计算机程序,计算机程序由处理器401加载并执行以实现如上述任一项算力节点标记方法。An embodiment of the present application also provides an electronic device, see FIG. 4 , which is a structural block diagram of an electronic device provided by an embodiment of the present application. The electronic device includes a
处理器401可以包括一个或多个处理核心,比如4核心处理器、17核心处理器等。处理器401可以采用DSP(Digital Signal Processing,数字信号处理)、FPGA(FieldProgrammable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器401也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central ProcessingUnit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器401可以在集成有GPU,GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器401还可以包括AI(Artificial Intelligence,人工智能)处理器,该AI处理器用于处理有关机器学习的计算操作。The
存储器402可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是有形的和非暂态的。存储器402还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器402中的非暂态的计算机可读存储介质存储有计算机程序,该计算机程序由处理器401加载并执行以实现上述算力节点标记方法。
本领域技术人员可以理解,图4中示出的结构并不构成对电子设备的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。Those skilled in the art can understand that the structure shown in FIG. 4 does not constitute a limitation on the electronic device, and may include more or less components than shown in the figure, or combine certain components, or adopt different component arrangements.
应用本申请实施例提供的电子设备,可以先获得待标记的算力节点的第一标记,该第一标记用于标记算力节点的资源利用率等级。然后,可以获得算力节点的第二标记,该第二标记用于衡量第一标记的可信度。之后,将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。Using the electronic device provided by the embodiment of the present application, the first mark of the computing power node to be marked can be obtained first, and the first mark is used to mark the resource utilization level of the computing power node. Then, the second mark of the computing power node can be obtained, and the second mark is used to measure the credibility of the first mark. Afterwards, the first mark and the second mark are used as the scheduling marks of the computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
本申请实施例还提供了一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,计算机程序由处理器加载并执行以实现如上述算力节点标记方法实施例任一项所述的方法。The embodiment of the present application also provides a computer-readable storage medium, in which a computer program is stored, and the computer program is loaded and executed by a processor to implement any one of the above-mentioned computing power node labeling method embodiments. Methods.
应用本申请实施例提供的计算机可读存储介质,可以先获得待标记的算力节点的第一标记,该第一标记用于标记算力节点的资源利用率等级。然后,可以获得算力节点的第二标记,该第二标记用于衡量第一标记的可信度。之后,将第一标记及第二标记,作为算力节点的调度标记。这样,通过量化的第一标记和第二标记作为标签来标记算力节点,使得具有粒度较细的标签。这样,在调度算力节点时,可以将任务准确地分配到符合负载条件的算力节点上,并且可以降低计算优选算力节点的耗时,提升算力节点的利用率。Using the computer-readable storage medium provided by the embodiment of the present application, the first mark of the computing power node to be marked can be obtained first, and the first mark is used to mark the resource utilization level of the computing power node. Then, the second mark of the computing power node can be obtained, and the second mark is used to measure the credibility of the first mark. Afterwards, the first mark and the second mark are used as the scheduling marks of the computing power nodes. In this way, the computing power nodes are marked by using the quantized first mark and the second mark as labels, so as to have finer-grained labels. In this way, when scheduling computing power nodes, tasks can be accurately assigned to computing power nodes that meet the load conditions, and the time-consuming calculation of optimal computing power nodes can be reduced, and the utilization rate of computing power nodes can be improved.
可选地,该计算机可读存储介质可以包括:ROM(Read-Only Memory,只读存储器)、RAM(Random Access Memory,随机存取存储器)、SSD(Solid State Drives,固态硬盘)或光盘等。其中,随机存取存储器可以包括ReRAM(Resistance Random Access Memory,电阻式随机存取存储器)和DRAM(Dynamic Random Access Memory,动态随机存取存储器)。Optionally, the computer-readable storage medium may include: ROM (Read-Only Memory, read-only memory), RAM (Random Access Memory, random access memory), SSD (Solid State Drives, solid-state hard disk) or optical discs, etc. Wherein, the random access memory may include ReRAM (Resistance Random Access Memory, resistive random access memory) and DRAM (Dynamic Random Access Memory, dynamic random access memory).
其中,装置、电子设备和计算机可读存储介质实施例是方法实施例对应的内容,相关内容可以参见方法实施例,在此不做赘述。Wherein, the embodiments of the apparatus, electronic equipment, and computer-readable storage medium are the contents corresponding to the method embodiments, and related contents may refer to the method embodiments, and details are not repeated here.
应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。另外,本文中描述的步骤编号,仅示例性示出了步骤间的一种可能的执行先后顺序,在一些其它实施例中,上述步骤也可以不按照编号顺序来执行,如两个不同编号的步骤同时执行,或者两个不同编号的步骤按照与图示相反的顺序执行,本申请实施例对此不作限定。上述各个实施例也可以进行任意组合,在此不再对组合方案进行赘述。It should be understood that the "plurality" mentioned herein refers to two or more than two. "And/or" describes the association relationship of associated objects, indicating that there may be three types of relationships, for example, A and/or B may indicate: A exists alone, A and B exist simultaneously, and B exists independently. The character "/" generally indicates that the contextual objects are an "or" relationship. In addition, the numbering of the steps described herein only exemplarily shows a possible sequence of execution among the steps. In some other embodiments, the above-mentioned steps may not be executed according to the order of the numbers, such as two different numbers The steps are executed at the same time, or two steps with different numbers are executed in the reverse order as shown in the illustration, which is not limited in this embodiment of the present application. The foregoing embodiments may also be combined arbitrarily, and the combination solutions will not be repeated here.
以上所述仅为本申请的示例性实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。The above are only exemplary embodiments of the application, and are not intended to limit the application. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the application shall be included in the protection of the application. within range.
Claims (10)


Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310257513.XA CN116302532A (en) | 2023-03-09 | 2023-03-09 | A computing power node marking method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310257513.XA CN116302532A (en) | 2023-03-09 | 2023-03-09 | A computing power node marking method and device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116302532A true CN116302532A (en) | 2023-06-23 |
Family
ID=86820316
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310257513.XA Pending CN116302532A (en) | 2023-03-09 | 2023-03-09 | A computing power node marking method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116302532A (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150378764A1 (en) * | 2014-06-30 | 2015-12-31 | Bmc Software, Inc. | Capacity risk management for virtual machines |
| US20190179675A1 (en) * | 2017-12-11 | 2019-06-13 | Accenture Global Solutions Limited | Prescriptive Analytics Based Committed Compute Reservation Stack for Cloud Computing Resource Scheduling |
| CN112114647A (en) * | 2020-10-29 | 2020-12-22 | 苏州浪潮智能科技有限公司 | A power control method, system and device for a server |
| CN114035945A (en) * | 2021-10-29 | 2022-02-11 | 深圳市晨北科技有限公司 | Computing power resource allocation method, device, equipment and storage medium |
| CN115469996A (en) * | 2022-07-28 | 2022-12-13 | 天翼云科技有限公司 | Calculation force scheduling method and device, electronic equipment and storage medium |
| CN115658542A (en) * | 2022-11-11 | 2023-01-31 | 南京掌御信息科技有限公司 | Code cipher algorithm type identification and parameter misuse detection method and system |
-
2023
- 2023-03-09 CN CN202310257513.XA patent/CN116302532A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150378764A1 (en) * | 2014-06-30 | 2015-12-31 | Bmc Software, Inc. | Capacity risk management for virtual machines |
| US20190179675A1 (en) * | 2017-12-11 | 2019-06-13 | Accenture Global Solutions Limited | Prescriptive Analytics Based Committed Compute Reservation Stack for Cloud Computing Resource Scheduling |
| CN112114647A (en) * | 2020-10-29 | 2020-12-22 | 苏州浪潮智能科技有限公司 | A power control method, system and device for a server |
| CN114035945A (en) * | 2021-10-29 | 2022-02-11 | 深圳市晨北科技有限公司 | Computing power resource allocation method, device, equipment and storage medium |
| CN115469996A (en) * | 2022-07-28 | 2022-12-13 | 天翼云科技有限公司 | Calculation force scheduling method and device, electronic equipment and storage medium |
| CN115658542A (en) * | 2022-11-11 | 2023-01-31 | 南京掌御信息科技有限公司 | Code cipher algorithm type identification and parameter misuse detection method and system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112559007B (en) | Parameter updating method and device of multitask model and electronic equipment | |
| CN112148468B (en) | A resource scheduling method, device, electronic equipment and storage medium | |
| CN114241265A (en) | Multi-source domain multi-level transfer learning method based on sample weight | |
| CN111290699B (en) | Data migration method, device and system | |
| WO2024061327A1 (en) | Vector map generation method and apparatus, electronic device, and readable storage medium | |
| CN103677960B (en) | Game resetting method for virtual machines capable of controlling energy consumption | |
| CN115271821B (en) | Network distribution processing methods, devices, computer equipment and storage media | |
| WO2021169267A1 (en) | Text processing method and apparatus, device, and computer-readable storage medium | |
| CN115512188A (en) | Multi-target detection method, device, equipment and medium | |
| CN113591881A (en) | Intention recognition method and device based on model fusion, electronic equipment and medium | |
| CN116010300A (en) | A GPU caching method and device, electronic equipment, and storage medium | |
| CN113890712A (en) | Data transmission method and device, electronic equipment and readable storage medium | |
| CN115934362A (en) | Server-less perception computing cluster scheduling method and product for deep learning | |
| CN113268614B (en) | Label system updating method and device, electronic equipment and readable storage medium | |
| CN112561500B (en) | Salary data generation method, device, equipment and medium based on user data | |
| KR20220071895A (en) | Method for auto scaling, apparatus and system thereof | |
| CN116302532A (en) | A computing power node marking method and device | |
| CN115941708B (en) | Cloud big data storage management method, device, electronic equipment and storage medium | |
| CN114996198B (en) | Cross-processor data transmission method, device, equipment and medium | |
| CN113326888B (en) | Labeling capability information determination method, related devices and computer program products | |
| CN116700631B (en) | Task management device, method, graphics processor and electronic device | |
| CN119336504A (en) | A queue resource allocation method, device, equipment, medium and program product | |
| CN105389212A (en) | Job assigning method and apparatus | |
| CN114417998B (en) | Data feature mapping method, device, equipment and storage medium | |
| CN111309821B (en) | Task scheduling method, device and electronic equipment based on graph database |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |