CN116149917A - Method and device for evaluating processor performance, computing device, and readable storage medium - Google Patents
Method and device for evaluating processor performance, computing device, and readable storage medium Download PDFInfo
- Publication number
- CN116149917A CN116149917A CN202310194425.XA CN202310194425A CN116149917A CN 116149917 A CN116149917 A CN 116149917A CN 202310194425 A CN202310194425 A CN 202310194425A CN 116149917 A CN116149917 A CN 116149917A
- Authority
- CN
- China
- Prior art keywords
- program
- program segments
- execution time
- segments
- program segment
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/22—Detection or location of defective computer hardware by testing during standby operation or during idle time, e.g. start-up testing
- G06F11/2205—Detection or location of defective computer hardware by testing during standby operation or during idle time, e.g. start-up testing using arrangements specific to the hardware being tested
- G06F11/2236—Detection or location of defective computer hardware by testing during standby operation or during idle time, e.g. start-up testing using arrangements specific to the hardware being tested to test CPU or processors
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/22—Detection or location of defective computer hardware by testing during standby operation or during idle time, e.g. start-up testing
- G06F11/2247—Verification or detection of system hardware configuration
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/22—Detection or location of defective computer hardware by testing during standby operation or during idle time, e.g. start-up testing
- G06F11/2273—Test methods
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Debugging And Monitoring (AREA)
Abstract
本申请提供了一种评估处理器性能的方法及装置、计算设备、可读存储介质,该方法包括:获取基准测试程序中多个程序段的执行时间;调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能。本申请实施例中,通过在采用模拟点工具对处理器的性能进行评估的过程中考虑多个程序段的执行时间,从而有助于降低采用模拟点工具进行处理器性能评估的误差。

The present application provides a method and device for evaluating the performance of a processor, a computing device, and a readable storage medium. The method includes: obtaining the execution time of multiple program segments in a benchmark test program; Execution time of the program segment, evaluating the performance of the processor. In the embodiment of the present application, the execution time of multiple program segments is considered in the process of evaluating the performance of the processor by using the simulation point tool, thereby helping to reduce errors in processor performance evaluation using the simulation point tool.
Description
技术领域technical field
本申请涉及计算机技术领域,更为具体的,涉及一种评估处理器性能的方法及装置、计算设备、可读存储介质。The present application relates to the field of computer technology, and more specifically, to a method and device for evaluating processor performance, computing equipment, and a readable storage medium.
背景技术Background technique
模拟点(simpoint)工具可以利用程序在执行过程中有随着时间变化的重复性行为这一特点,通过识别这些重复性行为,然后对于每一个重复性行为取一个样本来作为代表,以减少基准测试程序的执行时间,从而解决处理器性能评估过程中多次执行基准测试程序的耗时问题。The simulation point (simpoint) tool can take advantage of the fact that the program has repetitive behaviors that change over time during execution, by identifying these repetitive behaviors, and then taking a sample for each repetitive behavior as a representative to reduce the benchmark The execution time of the test program is used to solve the time-consuming problem of executing the benchmark test program multiple times in the processor performance evaluation process.
但是,在实际应用中发现,基于模拟点工具得到的基准测试程序的执行时间和实际执行完整的基准测试程序的时间具有很大的误差。However, in practical applications, it is found that there is a large error between the execution time of the benchmark test program obtained based on the simulation point tool and the actual execution time of the complete benchmark test program.
发明内容Contents of the invention
本申请提供一种评估处理器性能的方法及装置、计算设备、可读存储介质。下面对本申请实施例涉及的各个方面进行介绍。The present application provides a method and device for evaluating processor performance, a computing device, and a readable storage medium. Various aspects involved in the embodiments of the present application are introduced below.
第一方面,提供一种评估处理器性能的方法,该方法包括:获取基准测试程序中多个程序段的执行时间;调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能。In the first aspect, a method for evaluating the performance of a processor is provided, the method comprising: obtaining the execution time of multiple program segments in a benchmark test program; calling a simulation point tool, and evaluating the processor performance.
作为一种可能的实现方式,所述调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能,包括:调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类;根据所述多个程序段的聚类结果,评估所述处理器的性能。As a possible implementation manner, the calling the simulation point tool, and evaluating the performance of the processor according to the execution time of the multiple program segments includes: calling the simulation point tool, based on the multiple program segments clustering the multiple program segments; evaluating the performance of the processor according to the clustering results of the multiple program segments.
作为一种可能的实现方式,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组;调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。As a possible implementation manner, the calling the simulation point tool to cluster the multiple program segments based on the execution time of the multiple program segments includes: according to the execution time of the multiple program segments time, divide the plurality of program segments into one or more program segment groups; call the simulation point tool, respectively collect the program segments included in each program segment group of the one or more program segment groups kind.
作为一种可能的实现方式,所述根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组,包括:根据所述多个程序段的执行时间,对所述多个程序段进行排序;基于所述多个程序段的排序结果,将所述多个程序段分成一个或多个程序段组。As a possible implementation manner, the dividing the multiple program segments into one or more program segment groups according to the execution time of the multiple program segments includes: according to the execution time of the multiple program segments, Sorting the plurality of program segments; dividing the plurality of program segments into one or more program segment groups based on the sorting results of the plurality of program segments.
作为一种可能的实现方式,所述调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类,包括:调用所述模拟点工具,基于所述多个程序段的执行时间,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。As a possible implementation, the calling the simulation point tool to respectively cluster the program segments included in each program segment group of the one or more program segment groups includes: calling the simulation A point tool for clustering the program segments included in each of the one or more program segment groups based on the execution time of the plurality of program segment groups.
作为一种可能的实现方式,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:构建所述多个程序段中每个程序段的基本块向量,所述基本块向量中包括所述程序段的时间特征值,所述时间特征值用于指示所述程序段的执行时间;调用所述模拟点工具,基于所述基本块向量,对所述多个程序段进行聚类。As a possible implementation, the invoking the simulation point tool and clustering the multiple program segments based on the execution time of the multiple program segments includes: constructing each of the multiple program segments The basic block vector of a program segment, the basic block vector includes the time feature value of the program segment, and the time feature value is used to indicate the execution time of the program segment; call the simulation point tool, based on the The basic block vector is used to cluster the multiple program segments.
作为一种可能的实现方式,所述调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能,包括:调用所述模拟点工具,获取所述多个程序段的聚类结果,所述聚类结果包括一个或多个程序段样本代表;基于所述多个程序段的执行时间,确定所述一个或多个程序段样本代表的权重;根据所述一个或多个程序段样本代表的权重,评估所述处理器的性能。As a possible implementation, the calling the simulation point tool, and evaluating the performance of the processor according to the execution time of the multiple program segments includes: calling the simulation point tool to obtain the multiple program segments The clustering results, the clustering results include one or more program segment sample representatives; based on the execution time of the plurality of program segments, determine the weight of the one or more program segment sample representatives; according to the one or more A number of program segment samples represent weights for evaluating the performance of the processor.
作为一种可能的实现方式,所述获取基准测试程序中多个程序段的执行时间,包括:获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息;基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间。As a possible implementation, the acquiring the execution time of multiple program segments in the benchmark test program includes: acquiring the cache miss information of each program segment among the multiple program segments in the benchmark test program; based on the The cache miss information determines the execution time of a plurality of program segments in the benchmark test program.
作为一种可能的实现方式,所述多个程序段的每个程序段中包括所述缓存未命中信息对应的指令以及其他指令,所述基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间,包括:基于所述缓存未命中信息对应的指令的数量与第一执行时间的乘积,以及所述其他指令的数量与第二执行时间的乘积,确定所述多个程序段的执行时间,其中,所述第一执行时间大于所述第二执行时间。As a possible implementation, each program segment of the plurality of program segments includes instructions corresponding to the cache miss information and other instructions, and the benchmark test program is determined based on the cache miss information The execution time of multiple program segments in the program includes: determining the number of instructions based on the product of the number of instructions corresponding to the cache miss information and the first execution time, and the product of the number of other instructions and the second execution time The execution time of a program segment, wherein the first execution time is greater than the second execution time.
作为一种可能的实现方式,所述获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息,包括:基于三级缓存模型,统计所述基准测试程序中多个程序段中每个程序段的缓存未命中信息。As a possible implementation, the acquiring the cache miss information of each of the multiple program segments in the benchmark test program includes: based on the three-level cache model, counting the multiple programs in the benchmark test program Cache miss information for each program segment in the segment.
第二方面,提供一种评估处理器性能的装置,该装置包括:获取模块,用于获取基准测试程序中多个程序段的执行时间;评估模块,用于调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能。In a second aspect, there is provided a device for evaluating the performance of a processor, the device comprising: an acquisition module, configured to acquire the execution time of multiple program segments in a benchmark test program; an evaluation module, configured to call a simulation point tool, according to the multiple The execution time of a program segment is used to evaluate the performance of the processor.
作为一种可能的实现方式,所述评估模块用于:调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类;根据所述多个程序段的聚类结果,评估所述处理器的性能。As a possible implementation, the evaluation module is configured to: call the simulation point tool, and cluster the multiple program segments based on the execution time of the multiple program segments; The clustering results of the segments evaluate the performance of the processor.
作为一种可能的实现方式,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组;调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。As a possible implementation manner, the calling the simulation point tool to cluster the multiple program segments based on the execution time of the multiple program segments includes: according to the execution time of the multiple program segments time, divide the plurality of program segments into one or more program segment groups; call the simulation point tool, respectively collect the program segments included in each program segment group of the one or more program segment groups kind.
作为一种可能的实现方式,所述根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组,包括:根据所述多个程序段的执行时间,对所述多个程序段进行排序;基于所述多个程序段的排序结果,将所述多个程序段分成一个或多个程序段组。As a possible implementation manner, the dividing the multiple program segments into one or more program segment groups according to the execution time of the multiple program segments includes: according to the execution time of the multiple program segments, Sorting the plurality of program segments; dividing the plurality of program segments into one or more program segment groups based on the sorting results of the plurality of program segments.
作为一种可能的实现方式,所述调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类,包括:调用所述模拟点工具,基于所述多个程序段的执行时间,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。As a possible implementation, the calling the simulation point tool to respectively cluster the program segments included in each program segment group of the one or more program segment groups includes: calling the simulation A point tool for clustering the program segments included in each of the one or more program segment groups based on the execution time of the plurality of program segment groups.
作为一种可能的实现方式,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:构建所述多个程序段中每个程序段的基本块向量,所述基本块向量中包括所述程序段的时间特征值,所述时间特征值用于指示所述程序段的执行时间;调用所述模拟点工具,基于所述基本块向量,对所述多个程序段进行聚类。As a possible implementation, the invoking the simulation point tool and clustering the multiple program segments based on the execution time of the multiple program segments includes: constructing each of the multiple program segments The basic block vector of a program segment, the basic block vector includes the time feature value of the program segment, and the time feature value is used to indicate the execution time of the program segment; call the simulation point tool, based on the The basic block vector is used to cluster the multiple program segments.
作为一种可能的实现方式,所述评估模块用于:调用所述模拟点工具,获取所述多个程序段的聚类结果,所述聚类结果包括一个或多个程序段样本代表;基于所述多个程序段的执行时间,确定所述一个或多个程序段样本代表的权重;根据所述一个或多个程序段样本代表的权重,评估所述处理器的性能。As a possible implementation, the evaluation module is used to: call the simulation point tool to obtain the clustering results of the multiple program segments, the clustering results include one or more program segment sample representatives; based on The execution time of the plurality of program segments determines the weights represented by the one or more program segment samples; and evaluates the performance of the processor according to the weights represented by the one or more program segment samples.
作为一种可能的实现方式,所述获取基准测试程序中多个程序段的执行时间,包括:获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息;基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间。As a possible implementation, the acquiring the execution time of multiple program segments in the benchmark test program includes: acquiring the cache miss information of each program segment among the multiple program segments in the benchmark test program; based on the The cache miss information determines the execution time of a plurality of program segments in the benchmark test program.
作为一种可能的实现方式,所述多个程序段的每个程序段中包括所述缓存未命中信息对应的指令以及其他指令,所述基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间,包括:基于所述缓存未命中信息对应的指令的数量与第一执行时间的乘积,以及所述其他指令的数量与第二执行时间的乘积,确定所述多个程序段的执行时间,其中,所述第一执行时间大于所述第二执行时间。As a possible implementation, each program segment of the plurality of program segments includes instructions corresponding to the cache miss information and other instructions, and the benchmark test program is determined based on the cache miss information The execution time of multiple program segments in the program includes: determining the number of instructions based on the product of the number of instructions corresponding to the cache miss information and the first execution time, and the product of the number of other instructions and the second execution time The execution time of a program segment, wherein the first execution time is greater than the second execution time.
作为一种可能的实现方式,所述获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息,包括:基于三级缓存模型,统计所述基准测试程序中多个程序段中每个程序段的缓存未命中信息。As a possible implementation, the acquiring the cache miss information of each of the multiple program segments in the benchmark test program includes: based on the three-level cache model, counting the multiple programs in the benchmark test program Cache miss information for each program segment in the segment.
第三方面,提供一种计算设备,包括:存储器,用于存储代码;处理器,用于执行所述存储器中存储的代码,以执行如第一方面或第一方面中的任意一种可能的实现方式所述的方法。In a third aspect, a computing device is provided, including: a memory, used to store codes; a processor, used to execute the codes stored in the memory, to perform any one of the possible operations in the first aspect or the first aspect Implement the method described in the manner.
第四方面,提供一种计算机可读存储介质,其上存储有用于执行如第一方面或第一方面中的任意一种可能的实现方式所述的方法的代码。In a fourth aspect, a computer-readable storage medium is provided, on which codes for executing the method described in the first aspect or any possible implementation manner of the first aspect are stored.
第五方面,提供一种计算机程序代码,包括用于执行如第一方面或第一方面中的任意一种可能的实现方式所述的方法的指令。A fifth aspect provides computer program code, including instructions for executing the method described in the first aspect or any possible implementation manner of the first aspect.
本申请实施例通过在采用模拟点工具对处理器的性能进行评估的过程中考虑多个程序段的执行时间,从而有助于降低采用模拟点工具进行处理器性能评估的误差。The embodiment of the present application considers the execution time of multiple program segments in the process of evaluating the performance of the processor using the simulation point tool, thereby helping to reduce errors in processor performance evaluation using the simulation point tool.
附图说明Description of drawings
图1为本申请实施例提供的一种评估处理器性能的方法的流程示意图。FIG. 1 is a schematic flowchart of a method for evaluating processor performance provided by an embodiment of the present application.
图2为本申请实施例提供的另一种估计处理器性能的方法的流程示意图。FIG. 2 is a schematic flowchart of another method for estimating processor performance provided by an embodiment of the present application.
图3为本申请实施例提供的一种评估处理器性能的装置的结构示意图。FIG. 3 is a schematic structural diagram of an apparatus for evaluating processor performance provided by an embodiment of the present application.
图4为本申请实施例提供的一种计算设备的结构示意图。FIG. 4 is a schematic structural diagram of a computing device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。The following will clearly and completely describe the technical solutions in the embodiments of the application with reference to the drawings in the embodiments of the application. Apparently, the described embodiments are only some, not all, embodiments of the application.
在现代计算机体系结构的设计过程中,往往需要对不同的体系结构的性能进行评估,以提高处理器的性能。In the design process of modern computer architecture, it is often necessary to evaluate the performance of different architectures in order to improve the performance of the processor.
作为一种实现方式,可以通过模拟执行基准测试程序(benchmark)来预测处理器设计的性能和正确性。例如,基准测试程序可以采用标准性能评估公司(standardperformance evaluation corporation,SPEC)的CPU密集型基准测试套件中提供的基准测试程序,简称SPEC CPU程序。As an implementation, the performance and correctness of the processor design can be predicted by simulating the execution of a benchmark. For example, the benchmark test program may be the benchmark test program provided in the CPU-intensive benchmark test suite of the Standard Performance Evaluation Corporation (SPEC), referred to as the SPEC CPU program.
为了了解处理器在执行应用程序期间的周期性行为,通常需要使用模拟器详细的模拟每一个周期,但不幸的是,完整执行SPEC CPU程序需要数周甚至数月的时间,即使在最快的模拟器上也是如此。更糟的是,体系结构研究过程中经常需要在不同的架构配置和设计上模拟每一个基准测试程序,以找到性能、复杂性、面积和能耗之间的平衡。例如,为了找到缓存(cache)大小对于体系结构性能的影响,可能需要将同样的应用程序执行数百上千次,所花费的时间将是产品设计无法接受的。In order to understand the periodic behavior of the processor during the execution of the application, it is usually necessary to use a simulator to simulate each cycle in detail, but unfortunately, it takes weeks or even months to fully execute the SPEC CPU program, even in the fastest The same is true on the simulator. To make matters worse, the architectural research process often requires simulating each benchmark on different architectural configurations and designs to find a balance between performance, complexity, area, and power consumption. For example, in order to find out the impact of the cache size on the performance of the architecture, it may be necessary to execute the same application hundreds or thousands of times, and the time spent will be unacceptable for product design.
模拟点工具是体系结构研究的重要工具,它可以采用程序分析和机器学习的工具来解决上述体系结构模拟时间太长的问题。simpoint可以利用程序在执行过程中有随着时间变化的重复性行为这一特点,通过识别这些重复性行为,然后对于每一个重复性行为取一个样本来作为代表,从而减少程序的执行时间。也就是说,在执行基准测试程序的过程中,将基准测试程序中的重复性行为的多个程序替换为simpoint选取的样本代表,从而减少程序的执行时间。The simulation point tool is an important tool for architecture research. It can use program analysis and machine learning tools to solve the above-mentioned problem that the simulation time of the architecture is too long. Simpoint can take advantage of the feature that the program has repetitive behaviors that change over time during execution, by identifying these repetitive behaviors, and then taking a sample for each repetitive behavior as a representative, thereby reducing the execution time of the program. That is to say, in the process of executing the benchmark test program, multiple programs with repetitive behavior in the benchmark test program are replaced by the sample representatives selected by simpoint, thereby reducing the execution time of the program.
为了便于理解,下文对采用simpoint工具进行体系结构模拟的过程及相关概念进行简单介绍。In order to facilitate understanding, the process and related concepts of using the simpoint tool for architecture simulation are briefly introduced below.
在采用simpoint工具之前,通常预先将基准测试程序的指令流进行切段,如等分切段,得到多个程序段(interval)。Before adopting the simpoint tool, the instruction stream of the benchmark test program is usually segmented in advance, such as equally divided into segments, to obtain multiple program segments (intervals).
每个程序段中可能包括一个或多个基本块(basic block),基本块是指只有一个入口和一个出口的一段程序,基本块的一个典型特点是:只要基本块中第一条指令被执行了,那么基本块内所有指令,都会按照顺序仅执行一次。Each program segment may include one or more basic blocks. A basic block refers to a program with only one entry and one exit. A typical feature of a basic block is that as long as the first instruction in the basic block is executed Then all instructions in the basic block will be executed only once in order.
基本块向量可以指示程序段中基本块的信息,其中,基本块向量中包括的元素数量可以为程序段中基本块的数量,而每个元素的值可以为在运行该程序段的过程中,每个基本块的运行的次数与基本块中包含的指令条数的乘积。The basic block vector can indicate the information of the basic block in the program segment, wherein, the number of elements included in the basic block vector can be the number of basic blocks in the program segment, and the value of each element can be during the process of running the program segment, The product of the number of executions of each basic block and the number of instructions contained in the basic block.
如果两个程序段的基本块向量中每个基本块的值均相同,那么运行这两个程序段,和运行其中一个程序段两次在统计概念上来说是一样的。基于该原理,模拟点工具以基本块向量为特征对基准测试程序的指令流所包含的多个程序段进行聚类,如采用经典的K均值聚类算法(K-means),可以选出很小的模拟点(smulation points),也就是程序段的样本代表。另外,在一些情况下,可以将没有进行聚类的程序段对齐到相近的聚类中心中。If the value of each basic block in the basic block vector of two program segments is the same, then running the two program segments is statistically the same as running one of the program segments twice. Based on this principle, the simulation point tool uses the basic block vector as a feature to cluster multiple program segments contained in the instruction stream of the benchmark test program. If the classic K-means clustering algorithm (K-means) is used, many Small simulation points, which are sample representations of program segments. In addition, in some cases, program segments that have not been clustered can be aligned to close cluster centers.
在聚类之后,simpoint工具一般会输出两个文件:模拟点文件和权重(weights)文件。模拟点文件中保存了选择的interval(即程序段样本代表)的编号,weights中包含了程序段代表的权重。基于simpoint工具输出的权重文件,以及程序段样本代表的运行时间,可以计算基准测试程序的运行时间,从而评估处理器的性能。After clustering, the simpoint tool generally outputs two files: a simulation point file and a weights file. The number of the selected interval (that is, the sample representative of the program segment) is saved in the simulation point file, and the weights of the program segment representative are included in the weights. Based on the weight file output by the simpoint tool and the running time represented by the program segment samples, the running time of the benchmark program can be calculated to evaluate the performance of the processor.
但是,我们在实际应用的过程中发现,用simpoint选择的程序段样本代表在现场可编程门阵列(field programmable gate array,FPGA)上模拟的执行时间和实际执行完整的程序的时间具有很大的误差,尤其是当程序中具有大量的访存(load/store)指令的时候,例如Spec2006的gcc.403_2这个基准测试程序,误差率高达21.17%。这种误差在我们实际的设计当中是无法接受的,通过分析可以得出产生这种误差的原因可能包括以下两点。However, in the process of practical application, we found that the program segment sample selected by simpoint represents a large difference between the execution time simulated on the field programmable gate array (field programmable gate array, FPGA) and the actual execution time of the complete program. Errors, especially when there are a large number of load/store instructions in the program, such as the gcc.403_2 benchmark test program of Spec2006, the error rate is as high as 21.17%. This kind of error is unacceptable in our actual design. Through analysis, it can be concluded that the reasons for this kind of error may include the following two points.
一方面原因是,如前文所述,simpoint工具构建基本块向量是以每一个基本块内代码执行次数乘以代码的条数,即每一个基本块内指令流的指令数量作为特征。这种方法是把每一条指令的时间延迟(即执行时间)视为是相同的(即所有指令的时间延迟都是一拍),但这是不符合实际体系结构知识,也是不符合实际情况的。On the one hand, the reason is that, as mentioned above, the simpoint tool constructs the basic block vector by multiplying the number of code executions in each basic block by the number of codes, that is, the number of instructions in the instruction stream in each basic block as a feature. This method regards the time delay (i.e. execution time) of each instruction as the same (i.e. the time delay of all instructions is one beat), but this is not in line with the actual architecture knowledge and is not in line with the actual situation. .
另一方面原因是,simpoint聚类只考虑程序的逻辑重复性,虽然每一个程序段的指令数实际上是相同的(在实际使用中,通常将基准测试程序的指令流等分为多个程序段),却忽略了不同指令的执行时间并不相同,不同程序段实际的执行时间是千差万别的,尤其是访存指令load/store在cache不命中的情况下,时间延迟是其他指令的100到400倍,在使用模拟点结果去估算性能的时候,这种忽略是不可接受的。On the other hand, the reason is that simpoint clustering only considers the logical repetition of the program, although the number of instructions in each program segment is actually the same (in actual use, the instruction stream of the benchmark test program is usually divided into multiple programs section), but ignores that the execution time of different instructions is not the same, and the actual execution time of different program sections is very different, especially when the memory access instruction load/store misses the cache, the time delay is 100 to 100% of other instructions. 400 times, this omission is unacceptable when using simulation point results to estimate performance.
为了解决上述问题,本申请实施例提供了一种评估处理器性能的方法,通过在采用模拟点工具对处理器的性能进行评估的过程中考虑多个程序段的执行时间,从而有助于降低采用模拟点工具进行处理器性能评估的误差。In order to solve the above-mentioned problems, the embodiment of the present application provides a method for evaluating the performance of a processor, which helps to reduce the Error in processor performance evaluation using the analog point tool.
图1为本申请实施例提供的一种评估处理器性能的方法的流程示意图。FIG. 1 is a schematic flowchart of a method for evaluating processor performance provided by an embodiment of the present application.
参见图1,方法100包括步骤S110和步骤S120。Referring to Fig. 1, the
在步骤S110中,获取基准测试程序中多个程序段的执行时间。In step S110, the execution time of multiple program segments in the benchmark test program is acquired.
为了识别基准测试程序中的重复性行为,可以先将基准测试程序划分为多个单元,例如,将基准测试程序的程序流划分为多个程序段。作为一种实现方式,可以将基准测试程序的指令流按照固定的长度,如100M条指令的长度进行切段,得到多个程序段。In order to identify repetitive behaviors in the benchmarking program, the benchmarking program can be divided into multiple units first, for example, the program flow of the benchmarking program is divided into multiple program segments. As an implementation, the instruction stream of the benchmark test program can be segmented according to a fixed length, such as 100M instructions, to obtain multiple program segments.
在实际使用中,通过模拟器运行基准测试程序的二进制程序,然后利用引脚(pin)工具跟踪(trace)整个基准测试程序的指令流,进而可以根据固定的指令流大小将指令流切分成固定大小的片段,获得多个程序段。In actual use, run the binary program of the benchmark test program through the emulator, and then use the pin tool to trace (trace) the instruction flow of the entire benchmark test program, and then divide the instruction stream into fixed sized fragments, to obtain multiple program segments.
获取多个程序段的执行时间的方法包括多种。例如,可以通过运行多个程序段,并统计每个程序段的执行时间。There are many methods for obtaining the execution time of multiple program segments. For example, you can run multiple program segments and count the execution time of each program segment.
为了降低获取多个程序段执行时间的复杂度,还可以对多个程序段的执行时间进行估算。通过理论分析以及实验验证,可以发现,大部分指令的执行时间均为一个时钟周期(cycle),而在执行访存指令时,执行时间大都大于一个时钟周期,尤其是在三级缓存(L3cache)未命中的情况下,执行访存指令可能需要约100至400个时钟周期,这也是造成simpoint工具误差的主要原因。因此,作为一种实现方式,可以基于程序段的缓存未命中信息,估算每个程序段的执行时间。进一步地,由于一级缓存未命中和二级缓存未命中的情况带来的误差较小,为了降低估算的复杂度,可以基于程序段的三级缓存未命中信息,估算每个程序段的执行时间。In order to reduce the complexity of obtaining the execution time of multiple program segments, the execution time of multiple program segments can also be estimated. Through theoretical analysis and experimental verification, it can be found that the execution time of most instructions is one clock cycle (cycle), and when executing memory access instructions, the execution time is mostly longer than one clock cycle, especially in the three-level cache (L3cache) In the case of a miss, it may take about 100 to 400 clock cycles to execute the memory access instruction, which is also the main reason for the error of the simpoint tool. Therefore, as an implementation manner, the execution time of each program segment can be estimated based on the cache miss information of the program segment. Further, since the error caused by the first-level cache miss and the second-level cache miss is small, in order to reduce the complexity of estimation, the execution of each program segment can be estimated based on the third-level cache miss information of the program segment time.
在步骤S120中,调用模拟点工具,根据多个程序段的执行时间,评估处理器的性能。In step S120, the simulation point tool is invoked to evaluate the performance of the processor according to the execution time of multiple program segments.
结合前文所述的采用模拟点工具估计处理器性能的方法,可以从多个方面考虑程序段的执行时间,例如,可以基于多个程序段的执行时间对多个程序段进行聚类,根据多个程序段的聚类结果,评估处理器的性能;也可以在根据程序段代表的执行时间估算基准测试程序的执行时间的过程中,考虑多个程序段的执行时间,也就是说,基于所述多个程序段的执行时间以及聚类结果,评估处理器的性能。Combined with the method of estimating the performance of the processor using the simulation point tool described above, the execution time of the program segment can be considered from multiple aspects, for example, multiple program segments can be clustered based on the execution time of multiple program segments, according to multiple The clustering results of a program segment to evaluate the performance of the processor; it is also possible to consider the execution time of multiple program segments in the process of estimating the execution time of the benchmark program according to the execution time represented by the program segment, that is, based on the execution time of all program segments. Describe the execution time of multiple program segments and the clustering results to evaluate the performance of the processor.
本申请实施例通过在采用模拟点工具评估处理器的性能的过程中,考虑多个程序段的执行时间,能够降低多个程序段执行时间不同对处理器性能估计结果的影响,降低模拟点工具的估计误差。In the embodiment of the present application, by considering the execution time of multiple program segments in the process of evaluating the performance of the processor using the simulation point tool, the influence of different execution times of multiple program segments on the performance estimation result of the processor can be reduced, and the simulation point tool can be reduced. estimation error.
作为一种实现方式,根据多个程序段的执行时间,可以将多个程序段分成一个或多个程序段组,其中一个或多个程序段组的每个程序段组中所包括的程序段的执行时间相近;通过模拟点工具,分别对一个或多个程序段组的每个程序段组中所包括的程序段进行聚类;根据多个程序段的聚类结果,可以评估处理器的性能。As an implementation, according to the execution time of multiple program segments, multiple program segments can be divided into one or more program segment groups, wherein the program segments included in each program segment group of one or more program segment groups The execution time of the program segment is similar; through the simulation point tool, the program segments included in each program segment group of one or more program segment groups are clustered; according to the clustering results of multiple program segments, the performance of the processor can be evaluated performance.
在将多个程序段分成一个或多个程序段组的过程中,可以先根据多个程序段的执行时间,如按照缓存未命中的数值大小,对程序段进行排序,然后按照排序将多个程序段分成一个或多个程序段组。In the process of dividing multiple program segments into one or more program segment groups, the program segments can be sorted according to the execution time of multiple program segments, such as the numerical value of cache misses, and then the multiple program segments can be sorted according to the sorting. The blocks are divided into one or more block groups.
其中,每个程序段组中程序段的执行时间相近可以指每个程序段组中程序段的缓存未命中比率相近。如果从多个程序段中选出的程序段的代表的数量太多,则无法有效的减少基于基准测试程序估计处理器性能的时间。因此,为了控制程序段代表的数量,作为一个示例,一个或多个程序段组的每个程序段组中所包括的程序段的执行时间的差值小于或等于5%。The similar execution time of the program segments in each program segment group may mean that the cache miss ratios of the program segments in each program segment group are similar. If the number of representatives of the program segment selected from the plurality of program segments is too large, the time for estimating the performance of the processor based on the benchmark test program cannot be effectively reduced. Therefore, in order to control the number of program segment representations, as an example, the difference in execution time of the program segments included in each program segment group of the one or more program segment groups is less than or equal to 5%.
通过上述方式,可以将执行时间相近的程序段分在一个程序段组中,如此一来,在程序段组内采用simpoint工具进行基准测试程序的执行时间估计时,可以在一定程度上排除多个程序段的执行时间不同带来的误差,有助于降低采用simpoint工具估计处理器性能的误差。Through the above method, the program segments with similar execution time can be grouped into a program segment group. In this way, when the simpoint tool is used to estimate the execution time of the benchmark test program in the program segment group, multiple programs can be excluded to a certain extent. The error caused by the different execution time of the program segment is helpful to reduce the error of estimating the performance of the processor by using the simpoint tool.
为了进一步降低估计误差,可以基于程序段的执行时间,在程序段组内对程序段进行聚类。In order to further reduce estimation errors, program segments can be clustered within program segment groups based on their execution time.
在一些实施例中,调用模拟点工具,基于多个程序段的执行时间,对多个程序段进行聚类,可以在聚类过程中,增加每个程序段的时间特征值,其中,时间特征值用于指示该程序段的执行时间,如可以为前文提到的程序段执行时间的估算结果。如前文所述,可以基于程序段的基本块向量进行聚类,因此,可以构建多个程序段中每个程序段的基本块向量,该基本块向量中包括程序段的时间特征值。In some embodiments, the simulation point tool is called to cluster multiple program segments based on the execution time of multiple program segments, and the time feature value of each program segment can be increased during the clustering process, wherein the time feature The value is used to indicate the execution time of the program segment, such as the estimation result of the execution time of the program segment mentioned above. As mentioned above, clustering can be performed based on the basic block vectors of the program segments. Therefore, the basic block vectors of each of the multiple program segments can be constructed, and the basic block vectors include the time feature values of the program segments.
例如,可以在程序段的基本块向量中增加一个元素,该元素用于指示程序段的执行时间。通常程序段的基本块向量存储在*.bb文件中,因此,可以通过遍历*.bb文件,获取基本块向量的最大位数的值dim_max,然后将时间特性作为第dim_max维加入基本块向量。For example, an element may be added to the basic block vector of the program segment, and the element is used to indicate the execution time of the program segment. Usually the basic block vector of the program segment is stored in the *.bb file. Therefore, the value dim_max of the maximum number of digits of the basic block vector can be obtained by traversing the *.bb file, and then the time characteristic is added to the basic block vector as the dim_max dimension.
根据包括时间特征值的基本块向量,对多个程序段进行聚类,使得程序段的聚类结果与程序段的执行时间关联,能够降低处理器性能估计结果的误差。According to the basic block vector including the time feature value, clustering is performed on multiple program segments, so that the clustering results of the program segments are associated with the execution time of the program segments, and the error of the processor performance estimation result can be reduced.
如前文所述,调用模拟点工具,可以获取多个程序段的聚类结果,该聚类结果可以包括一个或多个程序段样本代表。作为一种实现方式,可以基于多个程序段的执行时间,确定一个或多个程序段样本代表的权重,从而根据该权重评估处理器的性能。As mentioned above, the clustering results of multiple program segments can be obtained by calling the simulation point tool, and the clustering results can include one or more program segment sample representatives. As an implementation manner, weights represented by one or more program segment samples may be determined based on the execution times of multiple program segments, so as to evaluate the performance of the processor according to the weights.
在实际使用中,调用模拟点工具获取的多个程序段的聚类结果,还可以包括一个或多个程序段样本代表的初始权重。由于模拟点工具给出的一个或多个程序段样本代表的初始权重,并不能代表程序段真实执行时间的权重,因此,可以根据多个程序段的执行时间,获取一个或多个程序段样本代表的更新权重,基于初始权重以及更新权重,可以评估处理器的性能。例如,可以对程序段样本代表的初始权重和更新权重进行加权求和,并将该结果作为最终的权重来估计处理器的性能。In actual use, the clustering results of multiple program segments obtained by calling the simulation point tool may also include initial weights represented by one or more program segment samples. Since the initial weight represented by one or more program segment samples given by the simulation point tool cannot represent the weight of the real execution time of the program segment, one or more program segment samples can be obtained according to the execution time of multiple program segments Represents the updated weights, based on the initial weights and the updated weights, the performance of the processor can be evaluated. For example, weighted summation may be performed on the initial weight represented by the program segment sample and the updated weight, and the result may be used as the final weight to estimate the performance of the processor.
作为一个示例,一个程序段样本代表的更新权重可以根据和该程序段样本代表所在的聚类簇中的程序段的执行时间之和与基准测试程序的所有程序段的执行时间之和的比值确定。As an example, the update weight of a program segment sample representative can be determined according to the ratio of the sum of the execution times of the program segments in the cluster where the program segment sample representative is located to the sum of the execution times of all program segments of the benchmark program .
通过基于执行时间确定程序段样本代表的权重,能够进一步提高估计处理器性能的准确性。The accuracy of estimating processor performance can be further improved by determining the weight of program segment sample representatives based on execution time.
前文提到,根据程序段的缓存未命中信息,可以计算出程序段的执行时间。在实际使用中,缓存未命中信息可以包括程序段中缓存未命中次数(miss_num)、访存总次数(visit_num)或未命中比率(miss_rate)等信息中的一种或多种信息。As mentioned above, according to the cache miss information of the program segment, the execution time of the program segment can be calculated. In actual use, the cache miss information may include one or more of information such as the number of cache misses (miss_num), the total number of memory accesses (visit_num), or the miss rate (miss_rate) in the program segment.
基于缓存未命中信息,可以确定程序段中缓存未命中的指令数量,从而计算出程序段的执行时间。例如,基于缓存未命中的指令数量与第一执行时间的乘积,以及程序段中其他指令的数量与第二执行时间的乘积,确定程序段的执行时间。其中,第一执行时间可以为执行一条缓存未命中的指令所需要的时间,第二执行时间可以为执行一条其他指令所需要的时间,如按照一个时钟周期估算。通常,执行缓存未命中的指令的时间大于执行其他指令的时间,也就是说第一执行时间大于第二执行时间。Based on the cache miss information, the number of cache miss instructions in the program segment can be determined, thereby calculating the execution time of the program segment. For example, the execution time of the program segment is determined based on the product of the number of cache miss instructions and the first execution time, and the product of the number of other instructions in the program segment and the second execution time. Wherein, the first execution time may be the time required to execute a cache miss instruction, and the second execution time may be the time required to execute another instruction, such as estimated according to one clock cycle. Usually, the execution time of the cache miss instruction is longer than the execution time of other instructions, that is to say, the first execution time is longer than the second execution time.
以缓存未命中信息为三级缓存未命中信息为例,不同的模拟架构下,如不同的FPGA下,三级缓存未命中的指令执行时间,即第一执行时间可能不同,可以基于实际的配置情况确定第一执行时间。Take the cache miss information as the third-level cache miss information as an example. Under different simulation architectures, such as different FPGAs, the instruction execution time of the third-level cache miss, that is, the first execution time may be different, which can be based on the actual configuration. Circumstances determine the first execution time.
作为一个示例,第一执行时间可以为400个时钟周期,第二执行时间可以为1个时钟周期。基于此,以程序段的指令数量为100M(100×1024×1024)为例,可以获得程序段的执行时间(interval_time)的计算公式:interval_time=miss_num×400+(100×1024×1024-miss_num)×1。As an example, the first execution time may be 400 clock cycles, and the second execution time may be 1 clock cycle. Based on this, taking the instruction quantity of the program segment as 100M (100×1024×1024) as an example, the calculation formula of the execution time (interval_time) of the program segment can be obtained: interval_time=miss_num×400+(100×1024×1024-miss_num) ×1.
为了获取程序段的缓存未命中信息,可以利用脚本模拟实际执行中的缓存行为。为了保持simpoint架构无关的特性,可以选用常见的cache模型来进行模拟。由于三级缓存模型在逻辑上包含一级缓存和二级缓存,而且三级缓存未命中的情况下,执行指令的时间延迟最大,因此我们可以采用三级缓存模型进行上述模拟。下面给出了一种通用的三级缓存的模型:In order to obtain the cache miss information of the program segment, the script can be used to simulate the cache behavior in actual execution. In order to maintain the irrelevant characteristics of the simpoint architecture, a common cache model can be selected for simulation. Since the L3 cache model logically includes L1 cache and L2 cache, and in the case of a L3 cache miss, the time delay for executing instructions is the largest, so we can use the L3 cache model for the above simulation. A general three-level cache model is given below:
(cache_size,line_size,[line_num,way_num],index_method,replacement_method)(cache_size, line_size, [line_num, way_num], index_method, replacement_method)
(2048,64,[2048,16],'TRA','PLRU')(2048,64,[2048,16],'TRA','PLRU')
其中,cache_size为缓存大小,line_size为缓存行的大小,line_num为缓存的行数,way_num为组相联的路数,index_method为索引方式,replacement_method为替换算法。Among them, cache_size is the cache size, line_size is the size of the cache line, line_num is the number of cache lines, way_num is the number of group association ways, index_method is the index method, and replacement_method is the replacement algorithm.
上述模型中,缓存的大小为2048,缓存行的大小为64,组相连路数为16,索引方式为TRA方式,替换算法为PLRU算法。In the above model, the size of the cache is 2048, the size of the cache line is 64, the number of group connection ways is 16, the indexing method is TRA, and the replacement algorithm is PLRU algorithm.
为了模拟程序段在执行过程中的缓存行为,还需要获取程序段的访存信息。例如,可以采用pin工具trace整个基准测试程序的指令流,记录跳转指令的PC信息,从而获得程序段的访存文件。访存文件中可以记录PC值、虚拟地址、内存中记录的值、内存长度、指令类型(如访问指令、存储指令)等信息。In order to simulate the cache behavior of the program segment during execution, it is also necessary to obtain the memory access information of the program segment. For example, the pin tool can be used to trace the instruction flow of the entire benchmark test program, record the PC information of the jump instruction, and obtain the memory access file of the program segment. Information such as PC value, virtual address, value recorded in memory, memory length, instruction type (such as access instruction, storage instruction) can be recorded in the access file.
利用程序段的访存文件中的信息,在缓存模型中模拟指令在缓存中的替换过程,从而统计出每一个程序段内部的未命中次数、访存总次数以及访存未命中的比率等。Using the information in the memory access file of the program segment, the replacement process of the instruction in the cache is simulated in the cache model, so as to count the number of misses, the total number of memory accesses, and the ratio of memory access misses in each program segment.
需要说明的是,前文提到的降低simpoint估计误差的方法可以单独使用,也可以将多种方法组合使用。It should be noted that the methods for reducing the simpoint estimation error mentioned above can be used alone or in combination.
图2为本申请实施例提供的另一种估计处理器性能的方法的流程示意图。下文结合图2,对处理器运行性能的估计方法进行详细地介绍。FIG. 2 is a schematic flowchart of another method for estimating processor performance provided by an embodiment of the present application. The method for estimating the operating performance of the processor will be described in detail below with reference to FIG. 2 .
方法200可以通过引入程序段的执行时间,在使用simpoint工具缩短SPEC CPU基准测试套件的二进制程序执行时间场景下,有助于提高simpoint的准确性。The
参见图2,方法200可以包括步骤S210至步骤S280。Referring to FIG. 2 , the
在步骤S210中,执行基准测试程序。In step S210, a benchmark test program is executed.
在使用simpoint工具优化处理器性能估计方法之前,通常先执行一次基准测试程序,如在模拟器上运行SPEC CPU的基准测试程序的二进制程序,以获取基准测试程序的相关信息。Before using the simpoint tool to optimize the processor performance estimation method, a benchmark test program is usually executed first, such as running the binary program of the SPEC CPU benchmark test program on the emulator to obtain relevant information of the benchmark test program.
为了便于simpoint工具的使用,在执行基准测试程序的过程中,可以采用pin工具trace整个基准测试程序的指令流,并根据固定的指令流大小,将指令流切分成固定大小的片段,也就是前文提到的多个程序段。In order to facilitate the use of the simpoint tool, in the process of executing the benchmark test program, the pin tool can be used to trace the instruction stream of the entire benchmark test program, and according to the fixed instruction stream size, the instruction stream is divided into fixed-size fragments, which is the previous article Multiple program segments mentioned.
在步骤S220中,获取访存文件。In step S220, the access file is obtained.
为了获取程序段的缓存未命中信息,首先需要获取每个程序段的访存信息,如访存文件mem_interval。作为一种实现方式,可以在采用pin工具trace基准测试程序的指令流的过程中,记录每一个实际跳转指令的PC信息,获得访存文件。访存文件中可以记录PC值、虚拟地址、内存中记录的值、内存长度、指令类型(如访问指令、存储指令)等信息。In order to obtain the cache miss information of the program segment, it is first necessary to obtain the memory access information of each program segment, such as the memory access file mem_interval. As an implementation, in the process of using the pin tool to trace the instruction flow of the benchmark test program, the PC information of each actual jump instruction can be recorded to obtain the access file. Information such as PC value, virtual address, value recorded in memory, memory length, instruction type (such as access instruction, storage instruction) can be recorded in the access file.
在步骤S230中,获取程序段文件。In step S230, a program segment file is obtained.
为了构建程序段的基本块向量,首先需要获取程序段的程序段文件。作为一种实现方式,可以在跟踪基准测试程序指令流的过程中,记录跳转指令类型、跳转指令的源地址、跳转指令的目的地址等信息,以形成程序段文件。In order to construct the basic block vector of the program segment, it is first necessary to obtain the program segment file of the program segment. As an implementation, in the process of tracing the instruction flow of the benchmark test program, information such as the type of the jump instruction, the source address of the jump instruction, and the destination address of the jump instruction can be recorded to form a program segment file.
在步骤S240中,获取程序段的时间特性数据。In step S240, the time characteristic data of the program segment is obtained.
前文提到,根据程序段的缓存未命中信息,可以获取程序段的时间特性数据。作为一种实现方式,基于程序段的访存信息,通过缓存模型模拟程序段在实际执行过程中的缓存行为,可以获取程序段的时间特性数据。其中,访存信息可以通过步骤S220中的程序段的访存文件获得。As mentioned above, according to the cache miss information of the program segment, the time characteristic data of the program segment can be obtained. As an implementation, based on the memory access information of the program segment, the time characteristic data of the program segment can be obtained by simulating the cache behavior of the program segment during actual execution through the cache model. Wherein, the access information can be obtained through the access file of the program segment in step S220.
为了保持simpoint架构无关的特性,可以选用常见的cache模型来进行模拟。由于三级缓存模型在逻辑上包含一级缓存和二级缓存,而且三级缓存未命中的情况下,执行指令的时间延迟最大,因此我们可以采用三级缓存模型进行上述模拟。In order to maintain the irrelevant characteristics of the simpoint architecture, a common cache model can be selected for simulation. Since the L3 cache model logically includes L1 cache and L2 cache, and in the case of a L3 cache miss, the time delay for executing instructions is the largest, so we can use the L3 cache model for the above simulation.
前文给出了一种通用的三级缓存的模型,为了简洁,此处不再赘述。A general three-level cache model was given above, and for the sake of brevity, details will not be repeated here.
利用程序段的访存文件中的信息,在缓存模型中模拟指令在缓存中的替换过程,从而可以统计出每一个程序段内部的未命中次数、访存总次数以及访存未命中的比率等缓存未命中信息。Use the information in the access file of the program segment to simulate the replacement process of instructions in the cache in the cache model, so that the number of misses, the total number of memory accesses, and the ratio of memory access misses in each program segment can be counted. Cache miss information.
对于缓存未命中的指令的执行时间,可以根据实际情况灵活确定,如可以根据采用的FPGA的配置确定。考虑配置最差的情况,三级缓存未命中时,指令的执行时间(即前文提到的第一执行时间)可以为400个时钟周期。The execution time of the cache miss instruction can be flexibly determined according to the actual situation, for example, it can be determined according to the configuration of the adopted FPGA. Considering the worst case of the configuration, when the L3 cache misses, the execution time of the instruction (that is, the first execution time mentioned above) may be 400 clock cycles.
以第一执行时间为400个时钟周期,程序段中除三级缓存未命中的指令以外的其他指令的执行时间为1个时钟周期为例,程序段的时间特性数据,如程序段的执行时间(interval_time)可以通过以下公式获得:interval_time=miss_num×400+(100×1024×1024-miss_num)×1。Taking the first execution time as 400 clock cycles, the execution time of other instructions in the program segment except for the L3 cache miss instruction is 1 clock cycle as an example, the time characteristic data of the program segment, such as the execution time of the program segment (interval_time) can be obtained by the following formula: interval_time=miss_num×400+(100×1024×1024−miss_num)×1.
在一些实施例中,程序段的执行时间可以用于确定程序段的权重文件。In some embodiments, the execution time of a program segment may be used to determine a weight file for a program segment.
在步骤S250中,生成*.bb文件。In step S250, a *.bb file is generated.
首先,获取初始基本块向量。通常可以利用bbv_build工具,遍历整个跳转指令流,补全基准测试程序的整个动态指令流,同时,可以使用控制流图(control flow graph,cfg)获取所有的基本块信息(如基本块的索引和大小)。根据这些信息可以获取程序段的初始基本块向量,可以将初始基本块向量生成为一个*.bb文件。First, get the initial basic block vector. Usually, the bbv_build tool can be used to traverse the entire jump instruction flow and complete the entire dynamic instruction flow of the benchmark test program. At the same time, the control flow graph (control flow graph, cfg) can be used to obtain all basic block information (such as the index of the basic block and size). According to these information, the initial basic block vector of the program segment can be obtained, and the initial basic block vector can be generated as a *.bb file.
其次,通过在初始基本块向量中增加时间特性数据,以获取包含时间特性的*.bb文件。例如,可以遍历程序段的初始基本块向量的*.bb文件,获取程序段的基本块向量的最大位数的值dim_max。然后,将程序段的时间特性数据作为每一个基本块向量的第dim_max维加入基本块向量的最后一维度,作为附加的一个特征值。Secondly, by adding the time characteristic data in the initial basic block vector, the *.bb file including the time characteristic is obtained. For example, the *.bb file of the initial basic block vector of the program segment may be traversed to obtain the value dim_max of the maximum number of bits of the basic block vector of the program segment. Then, add the time characteristic data of the program segment as the dim_maxth dimension of each basic block vector to the last dimension of the basic block vector as an additional feature value.
最后,根据程序段的分组信息,构建新的*.bb文件。Finally, build a new *.bb file according to the grouping information of the program segment.
为了进一步降低simpoint的估计误差,在对多个程序段聚类之前,可以将程序段分成一个或多个程序段组。例如,可以按照cache_miss数值大小对程序段进行排序,把排序后的程序段分成一个或多个大段(part),即前文提到的一个或多个程序段组。In order to further reduce the estimation error of simpoint, before clustering multiple program segments, the program segments can be divided into one or more program segment groups. For example, the program segments may be sorted according to the numerical value of cache_miss, and the sorted program segments are divided into one or more large parts (parts), that is, one or more program segment groups mentioned above.
如果从多个程序段中选出的程序段的代表(即选出的检查点镜像)的数量太多,则无法有效的减少基于基准测试程序估计处理器性能的时间。因此,根据实验结果,在对多个程序段进行分组的时候,可以控制每一个程序段组中cache_miss的差距在5%之内。If the number of program segment representatives selected from multiple program segments (that is, the selected checkpoint image) is too large, the time for estimating processor performance based on the benchmark test program cannot be effectively reduced. Therefore, according to the experimental results, when grouping multiple program segments, the difference of cache_miss in each program segment group can be controlled within 5%.
根据一个或多个程序段组的划分结果,可以重构新的*.bb文件。例如,将多个程序段的*.bb文件按照程序段的分组,写入程序段组的*.bb文件中,也就是说,最终的*.bb文件的数量和程序段组的数量相同。According to the division result of one or more program segment groups, a new *.bb file can be reconstructed. For example, the *.bb files of multiple program segments are written into the *.bb files of program segment groups according to the grouping of program segments, that is to say, the number of final *.bb files is the same as the number of program segment groups.
在步骤S260中,获取模拟点文件及权重文件。In step S260, the simulation point file and the weight file are obtained.
通过调用simpoint工具对每个程序段组的*.bb文件进行聚类采样,以实现在程序段组内对多个程序段的聚类,采样参数可以包括“-saveSimpoints”、“-saveSimpointWeights”、“-saveLabels”和“-maxK”。其中“-saveSimpoints”为得到聚类采样的聚类中心的程序段样本代表的编号,“-saveSimpointWeights”为获得程序段样本代表的权重,“-saveLabels”为获得每一个程序段所属于的聚类中心的编号,也就是获得哪些程序段被聚类在同一个簇,“-maxK”为设置聚类中心数量的最大值。By calling the simpoint tool, cluster and sample the *.bb files of each program segment group to realize the clustering of multiple program segments within the program segment group. The sampling parameters can include "-saveSimpoints", "-saveSimpointWeights", "-saveLabels" and "-maxK". Among them, "-saveSimpoints" is the number of the program segment sample representative of the cluster center of the cluster sampling, "-saveSimpointWeights" is the weight of the program segment sample representative, and "-saveLabels" is the cluster to which each program segment belongs The number of the center, that is, to obtain which program segments are clustered in the same cluster, "-maxK" is to set the maximum number of cluster centers.
如果采用K-means算法对多个程序段进行采样,K值(聚类中心数量在K值之内,即聚类中心数量小于或等于K值)默认为10,K值也可以根据自己的需求和实际情况进行调整。If the K-means algorithm is used to sample multiple program segments, the K value (the number of cluster centers is within the K value, that is, the number of cluster centers is less than or equal to the K value) defaults to 10, and the K value can also be based on your own needs. Adjust with the actual situation.
基于上述采样的结果,可以获得每一个程序段组的模拟点文件(*.simpoints文件)、权重文件(*.weights文件)和*.lables文件。也就是说,可以获得每个程序段组中的程序段样本代表及程序段样本代表在该程序段组内的权重。Based on the above sampling results, the simulation point file (*.simpoints file), weight file (*.weights file) and *.lables file of each block group can be obtained. That is to say, the program segment sample representatives in each program segment group and the weight of the program segment sample representatives in the program segment group can be obtained.
但是,由于上述采样是在每一个程序段组对应的*.bb文件内部进行的,也就是说,采样结果中的编号为程序段组内部的编号,因此,需要将上述采样结果中的编号映射为全局编号,得到新的*.simpoints文件。However, since the above sampling is carried out inside the *.bb file corresponding to each block group, that is to say, the number in the sampling result is the number inside the block group, therefore, it is necessary to map the number in the above sampling result to For the global number, get a new *.simpoints file.
考虑到程序段的时间特性,simpoint工具直接生成的权重并不能代表程序段真实的执行时间的权重,因此,可以基于步骤S240中获取的程序段的执行时间重新计算权重。以一个程序段组中有m个程序段为例,simpoint工具可以从该程序段组中选出n个聚类中心(对应n个聚类簇(cluster)),每一个聚类中心代表该程序段组内的一个聚类簇。其中,每个程序段的时间特性数据为ti(i=1,2,....,m),如果第i个聚类簇有xi个程序段,第i个聚类簇中每一个程序段的时间特征为tj(j=1,2,....,xi),则第i个聚类中心点的权重weightsi可以通过如下公式计算。Considering the time characteristic of the program segment, the weight directly generated by the simpoint tool cannot represent the real execution time weight of the program segment, therefore, the weight can be recalculated based on the execution time of the program segment obtained in step S240. Taking m program segments in a program segment group as an example, the simpoint tool can select n cluster centers (corresponding to n cluster clusters) from the program segment group, and each cluster center represents the program A cluster of clusters within a segment group. Among them, the time characteristic data of each program segment is ti (i=1,2,...,m), if the i-th cluster has xi program segments, each program in the i-th cluster The time feature of a segment is tj (j=1,2,...,xi), then the weights i of the i-th cluster center point can be calculated by the following formula.

为了进一步提高处理器性能估计结果的准确性,可以对程序段样本代表的初始权重(即simpoint工具直接给出的权重)和更新权重(即上述重新计算的权重)进行加权求和,并将该结果作为最终的权重来估计处理器的性能。In order to further improve the accuracy of the processor performance estimation results, the initial weight represented by the program segment sample (that is, the weight directly given by the simpoint tool) and the update weight (that is, the above-mentioned recalculated weight) can be weighted and summed, and the The result is used as the final weight to estimate the performance of the processor.
在步骤S270中,数据准备。In step S270, data preparation.
为了提升simpoint工具的性能,可以在程序段样本代表(即聚类中心对应的程序段)运行之前准备以下数据中的一种或多种:检查点(checkpoint)镜像文件、程序段的后1000条指令、5M的预热数据。其中,指令的数量可以根据实际情况进行灵活设置。In order to improve the performance of the simpoint tool, one or more of the following data can be prepared before the program segment sample representative (that is, the program segment corresponding to the cluster center) runs: checkpoint (checkpoint) image file, the last 1000 items of the program segment Instructions, 5M warm-up data. Wherein, the number of instructions can be flexibly set according to actual conditions.
检查点镜像文件为程序段在FPGA上执行的起始点的寄存器、CPU等硬件的具体内容,基于检查点镜像文件,可以在验证过程中快速运行程序段样本代表。The checkpoint image file is the specific content of the register, CPU and other hardware at the starting point of the program segment executed on the FPGA. Based on the checkpoint image file, the sample representative of the program segment can be quickly run during the verification process.
在步骤S280中,FPGA验证。In step S280, FPGA verification.
根据检查点镜像文件,在FPGA上执行程序段样本代表,并记录每一个程序段的执行时间。进一步地,根据记录结果和步骤S260中获得的最终权重,可以估算出完整的基准测试程序的执行时间。基于完整的基准测试程序的执行时间可以对处理器的运行性能进行评估。According to the checkpoint image file, the program segment sample representative is executed on the FPGA, and the execution time of each program segment is recorded. Further, according to the recording result and the final weight obtained in step S260, the execution time of the complete benchmark test program can be estimated. Processor performance can be evaluated based on the execution time of the complete benchmark program.
为了验证检查点镜像文件的正确性,可以获取每一个程序段的后1000条指令,FPGA也获取1000条指令,双方进行对比,以保证我们执行的正确性。In order to verify the correctness of the checkpoint image file, the last 1000 instructions of each program segment can be obtained, and the FPGA also obtains 1000 instructions. The two sides compare to ensure the correctness of our execution.
为了提升程序段执行时间估算结果的准确性,可以获取程序段的前5M指令进行预热,使得整体硬件处于一个正常执行的状态。通过实验证明,该方法能很好的提升评估的效果。In order to improve the accuracy of the program segment execution time estimation results, the first 5M instructions of the program segment can be obtained for warm-up, so that the overall hardware is in a normal execution state. Experiments show that this method can improve the evaluation effect very well.
为了验证本申请实施例提供的估计处理器运行性能的方法的准确性,可以分别在裸机情况下和加入操作系统的情况下,在FPGA上执行完整的基准测试程序,获取完整的基准测试程序的执行时间。通过实验验证,直接采用simpoint给出的权重,估算的基准测试程序的运行时间更加接近裸机执行的时间,而采用本申请实施例提供的基于程序段执行时间的权重的估算结果,更加接近在有操作系统的情况下执行的时间,也就是说,采用本申请实施例提供的方法,处理器性能的估计结果更加贴近实际使用情况。In order to verify the accuracy of the method for estimating the operating performance of the processor provided by the embodiment of the present application, a complete benchmark test program can be executed on the FPGA to obtain the complete benchmark test program in the case of bare metal and the case of adding an operating system. execution time. Through experimental verification, directly adopting the weight given by simpoint, the estimated runtime of the benchmark test program is closer to the execution time of the bare metal, and the estimation result of the weight based on the execution time of the program segment provided by the embodiment of the application is closer to that in the existing The execution time in the case of the operating system, that is, by using the method provided in the embodiment of the present application, the estimation result of the processor performance is closer to the actual usage situation.
根据实验结果,采用本申请实施例中的处理器的性能评估方法,能够将SPEC CPU2006下simpoint工具估算时间的误差从21%减小到3%以内,效果良好。According to the experimental results, using the processor performance evaluation method in the embodiment of this application, the error of the simpoint tool estimation time under SPEC CPU2006 can be reduced from 21% to less than 3%, and the effect is good.
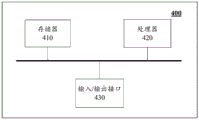
上文结合图1至图2详细描述了本申请的方法实施例,下面结合图3至图4详细描述本申请的装置实施例。应理解,装置实施例的描述与方法实施例的描述相互对应,因此,未详细描述的部分可以参见前面方法实施例。The method embodiment of the present application is described in detail above with reference to FIG. 1 to FIG. 2 , and the device embodiment of the present application is described in detail below in conjunction with FIG. 3 to FIG. 4 . It should be understood that the descriptions of the device embodiments correspond to the descriptions of the method embodiments, therefore, for parts that are not described in detail, reference may be made to the foregoing method embodiments.
图3为本申请实施例提供的一种评估处理器性能的装置的结构示意图,装置300包括获取模块310和评估模块320。FIG. 3 is a schematic structural diagram of an apparatus for evaluating processor performance provided by an embodiment of the present application. The apparatus 300 includes an acquisition module 310 and an evaluation module 320 .
获取模块310,用于获取基准测试程序中多个程序段的执行时间;An acquisition module 310, configured to acquire the execution time of multiple program segments in the benchmark test program;
评估模块320,用于调用模拟点工具,根据所述多个程序段的执行时间,评估所述处理器的性能。The evaluation module 320 is configured to call a simulation point tool to evaluate the performance of the processor according to the execution time of the multiple program segments.
可选地,所述评估模块用于:调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类;根据所述多个程序段的聚类结果,评估所述处理器的性能。Optionally, the evaluation module is configured to: call the simulation point tool, and cluster the multiple program segments based on the execution time of the multiple program segments; according to the clustering of the multiple program segments As a result, the performance of the processor is evaluated.
可选地,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组;调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。Optionally, the calling the simulation point tool, and clustering the multiple program segments based on the execution time of the multiple program segments includes: clustering the multiple program segments according to the execution time of the multiple program segments The multiple program segments are divided into one or more program segment groups; the simulation point tool is called to cluster the program segments included in each program segment group of the one or more program segment groups.
可选地,所述根据所述多个程序段的执行时间,将所述多个程序段分成一个或多个程序段组,包括:根据所述多个程序段的执行时间,对所述多个程序段进行排序;基于所述多个程序段的排序结果,将所述多个程序段分成一个或多个程序段组。Optionally, the dividing the plurality of program segments into one or more program segment groups according to the execution time of the plurality of program segments includes: The program segments are sorted; based on the sorting results of the multiple program segments, the multiple program segments are divided into one or more program segment groups.
可选地,所述调用所述模拟点工具,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类,包括:调用所述模拟点工具,基于所述多个程序段的执行时间,分别对所述一个或多个程序段组的每个程序段组中所包括的程序段进行聚类。Optionally, calling the simulation point tool to cluster the program segments included in each program segment group of the one or more program segment groups includes: calling the simulation point tool based on The execution time of the plurality of program segments clusters the program segments included in each program segment group of the one or more program segment groups respectively.
可选地,所述调用所述模拟点工具,基于所述多个程序段的执行时间,对所述多个程序段进行聚类,包括:构建所述多个程序段中每个程序段的基本块向量,所述基本块向量中包括所述程序段的时间特征值,所述时间特征值用于指示所述程序段的执行时间;调用所述模拟点工具,基于所述基本块向量,对所述多个程序段进行聚类。Optionally, the invoking the simulation point tool, and clustering the multiple program segments based on the execution time of the multiple program segments includes: constructing the A basic block vector, the basic block vector includes the time feature value of the program segment, the time feature value is used to indicate the execution time of the program segment; calling the simulation point tool, based on the basic block vector, clustering the plurality of program segments.
可选地,所述评估模块用于:调用所述模拟点工具,获取所述多个程序段的聚类结果,所述聚类结果包括一个或多个程序段样本代表;基于所述多个程序段的执行时间,确定所述一个或多个程序段样本代表的权重;根据所述一个或多个程序段样本代表的权重,评估所述处理器的性能。Optionally, the evaluation module is configured to: call the simulation point tool to obtain the clustering results of the multiple program segments, the clustering results include one or more program segment sample representatives; based on the multiple The execution time of the program segment determines the weight represented by the one or more program segment samples; and evaluates the performance of the processor according to the weight represented by the one or more program segment samples.
可选地,所述获取基准测试程序中多个程序段的执行时间,包括:获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息;基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间。Optionally, the acquiring the execution time of multiple program segments in the benchmark test program includes: acquiring cache miss information of each program segment among the multiple program segments in the benchmark test program; based on the cache miss information , to determine execution times of multiple program segments in the benchmark test program.
可选地,所述多个程序段的每个程序段中包括所述缓存未命中信息对应的指令以及其他指令,所述基于所述缓存未命中信息,确定所述基准测试程序中多个程序段的执行时间,包括:基于所述缓存未命中信息对应的指令的数量与第一执行时间的乘积,以及所述其他指令的数量与第二执行时间的乘积,确定所述多个程序段的执行时间,其中,所述第一执行时间大于所述第二执行时间。Optionally, each program segment of the plurality of program segments includes instructions corresponding to the cache miss information and other instructions, and based on the cache miss information, determine the number of programs in the benchmark test program The execution time of the segment includes: based on the product of the number of instructions corresponding to the cache miss information and the first execution time, and the product of the number of other instructions and the second execution time, determining the time of the plurality of program segments execution time, wherein the first execution time is greater than the second execution time.
可选地,所述获取所述基准测试程序中多个程序段中每个程序段的缓存未命中信息,包括:基于三级缓存模型,统计所述基准测试程序中多个程序段中每个程序段的缓存未命中信息。Optionally, the acquiring the cache miss information of each of the multiple program segments in the benchmark test program includes: based on the three-level cache model, counting each of the multiple program segments in the benchmark test program Cache miss information for the program segment.
图4为本申请实施例提供的一种计算设备的结构示意图。图4所示的计算设备400可以包括存储器410和处理器420。在一些实施例中,图4所示的计算设备400还可以包括输入/输出接口430。存储器410用于存储指令,该处理器420用于执行该存储器410存储的指令,以执行前文任一实施例描述的方法。FIG. 4 is a schematic structural diagram of a computing device provided by an embodiment of the present application. The
应理解,在本申请实施例中,该处理器420可以采用通用的中央处理器(centralprocessing unit,CPU),微处理器,应用专用集成电路(application specificintegrated circuit,ASIC),或者一个或多个集成电路,用于执行相关程序,以实现本申请实施例所提供的技术方案。It should be understood that, in the embodiment of the present application, the processor 420 may adopt a general-purpose central processing unit (central processing unit, CPU), a microprocessor, an application specific integrated circuit (application specific integrated circuit, ASIC), or one or more integrated The circuit is used to execute related programs, so as to realize the technical solutions provided by the embodiments of the present application.
该存储器410可以包括只读存储器和随机存取存储器,并向处理器420提供指令和数据。处理器420的一部分还可以包括非易失性随机存取存储器。例如,处理器420还可以存储设备类型的信息。The
在实现过程中,上述方法的各步骤可以通过处理器420中的硬件的集成逻辑电路或者软件形式的指令完成。结合本申请实施例所公开的方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器410,处理器420读取存储器410中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。In the implementation process, each step of the above method may be implemented by an integrated logic circuit of hardware in the processor 420 or instructions in the form of software. The methods disclosed in the embodiments of the present application may be directly implemented by a hardware processor, or implemented by a combination of hardware and software modules in the processor. The software module can be located in a mature storage medium in the field such as random access memory, flash memory, read-only memory, programmable read-only memory or electrically erasable programmable memory, register. The storage medium is located in the
应理解,本申请实施例中,该处理器可以为中央处理单元(central processingunit,CPU),该处理器还可以是其他通用处理器、数字信号处理器(digital signalprocessor,DSP)、专用集成电路(application specific integrated circuit,ASIC)、FPGA或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。It should be understood that in the embodiment of the present application, the processor may be a central processing unit (central processing unit, CPU), and the processor may also be other general processors, digital signal processors (digital signal processor, DSP), application specific integrated circuits ( application specific integrated circuit, ASIC), FPGA or other programmable logic devices, discrete gate or transistor logic devices, discrete hardware components, etc. A general-purpose processor may be a microprocessor, or the processor may be any conventional processor, or the like.
本申请实施例还提供一种计算机可读存储介质,用于存储程序,以使得计算机执行前文任一实施例描述的方法。An embodiment of the present application further provides a computer-readable storage medium for storing a program, so that a computer executes the method described in any of the foregoing embodiments.
应理解,在本申请实施例中,“与A相应的B”表示B与A相关联,根据A可以确定B。但还应理解,根据A确定B并不意味着仅仅根据A确定B,还可以根据A和/或其它信息确定B。It should be understood that in this embodiment of the present application, "B corresponding to A" means that B is associated with A, and B can be determined according to A. However, it should also be understood that determining B according to A does not mean determining B only according to A, and B may also be determined according to A and/or other information.
应理解,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。It should be understood that the term "and/or" in this article is only an association relationship describing associated objects, which means that there may be three relationships, for example, A and/or B may mean: A exists alone, and A and B exist at the same time , there are three cases of B alone. In addition, the character "/" in this article generally indicates that the contextual objects are an "or" relationship.
应理解,在本申请的各种实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。It should be understood that, in various embodiments of the present application, the sequence numbers of the above-mentioned processes do not mean the order of execution, and the execution order of the processes should be determined by their functions and internal logic, and should not be used in the embodiments of the present application. The implementation process constitutes any limitation.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed systems, devices and methods may be implemented in other ways. For example, the device embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components can be combined or May be integrated into another system, or some features may be ignored, or not implemented. In another point, the mutual coupling or direct coupling or communication connection shown or discussed may be through some interfaces, and the indirect coupling or communication connection of devices or units may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and the components shown as units may or may not be physical units, that is, they may be located in one place, or may be distributed to multiple network units. Part or all of the units can be selected according to actual needs to achieve the purpose of the solution of this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, each unit may exist separately physically, or two or more units may be integrated into one unit.
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber Line,DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够读取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,数字通用光盘(digital video disc,DVD))或者半导体介质(例如,固态硬盘(solid state disk,SSD))等。In the above embodiments, all or part of them may be implemented by software, hardware, firmware or any combination thereof. When implemented using software, it may be implemented in whole or in part in the form of a computer program product. The computer program product includes one or more computer instructions. When the computer program instructions are loaded and executed on the computer, the processes or functions according to the embodiments of the present application will be generated in whole or in part. The computer can be a general purpose computer, a special purpose computer, a computer network, or other programmable devices. The computer instructions may be stored in or transmitted from one computer-readable storage medium to another computer-readable storage medium, for example, the computer instructions may be transmitted from a website, computer, server or data center Transmission to another website site, computer, server or data center by wired (such as coaxial cable, optical fiber, digital subscriber line (DSL)) or wireless (such as infrared, wireless, microwave, etc.). The computer-readable storage medium may be any available medium that can be read by a computer, or a data storage device such as a server or a data center integrated with one or more available media. The available medium may be a magnetic medium (for example, a floppy disk, a hard disk, a magnetic tape), an optical medium (for example, a digital versatile disc (digital video disc, DVD)) or a semiconductor medium (for example, a solid state disk (solid state disk, SSD) )wait.
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。The above is only a specific implementation of the application, but the scope of protection of the application is not limited thereto. Anyone familiar with the technical field can easily think of changes or substitutions within the technical scope disclosed in the application. Should be covered within the protection scope of this application. Therefore, the protection scope of the present application should be determined by the protection scope of the claims.
Claims (22)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310194425.XA CN116149917A (en) | 2023-02-28 | 2023-02-28 | Method and device for evaluating processor performance, computing device, and readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310194425.XA CN116149917A (en) | 2023-02-28 | 2023-02-28 | Method and device for evaluating processor performance, computing device, and readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116149917A true CN116149917A (en) | 2023-05-23 |
Family
ID=86338952
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310194425.XA Pending CN116149917A (en) | 2023-02-28 | 2023-02-28 | Method and device for evaluating processor performance, computing device, and readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116149917A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116894209A (en) * | 2023-09-05 | 2023-10-17 | 北京开源芯片研究院 | Sampling point classification method, device, electronic equipment and readable storage medium |
| WO2025161419A1 (en) * | 2024-02-02 | 2025-08-07 | 华为技术有限公司 | Performance analysis method, application method, device, readable medium and program product |
| CN120631705A (en) * | 2025-08-12 | 2025-09-12 | 北京壁仞科技开发有限公司 | Method, computing device, medium, and program product for predicting the performance of a computing system on which an application program runs |
| CN120724936A (en) * | 2025-08-29 | 2025-09-30 | 蓝芯算力(深圳)科技有限公司 | Universal checkpoint generation method, system and related equipment for simulator |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090276190A1 (en) * | 2008-04-30 | 2009-11-05 | International Business Machines Corporation | Method and Apparatus For Evaluating Integrated Circuit Design Performance Using Basic Block Vectors, Cycles Per Instruction (CPI) Information and Microarchitecture Dependent Information |
| CN101799767A (en) * | 2010-03-05 | 2010-08-11 | 中国人民解放军国防科学技术大学 | Method for carrying out parallel simulation by repeatedly switching a plurality of operation modes of simulator |
| CN101916230A (en) * | 2010-08-11 | 2010-12-15 | 中国科学技术大学苏州研究院 | Performance Optimization Method of Last Level Cache Based on Partition Awareness and Thread Awareness |
| CN103049310A (en) * | 2012-12-29 | 2013-04-17 | 中国科学院深圳先进技术研究院 | Multi-core simulation parallel accelerating method based on sampling |
| US20150067819A1 (en) * | 2013-08-28 | 2015-03-05 | Hola Networks Ltd. | System and Method for Improving Internet Communication by Using Intermediate Nodes |
| CN109271288A (en) * | 2017-07-17 | 2019-01-25 | 展讯通信(上海)有限公司 | Processor silicon pre-performance evaluation method |
| CN111651341A (en) * | 2020-07-14 | 2020-09-11 | 中国人民解放军国防科技大学 | A Performance Evaluation Method for General-Purpose Processors |
-
2023
- 2023-02-28 CN CN202310194425.XA patent/CN116149917A/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090276190A1 (en) * | 2008-04-30 | 2009-11-05 | International Business Machines Corporation | Method and Apparatus For Evaluating Integrated Circuit Design Performance Using Basic Block Vectors, Cycles Per Instruction (CPI) Information and Microarchitecture Dependent Information |
| CN101799767A (en) * | 2010-03-05 | 2010-08-11 | 中国人民解放军国防科学技术大学 | Method for carrying out parallel simulation by repeatedly switching a plurality of operation modes of simulator |
| CN101916230A (en) * | 2010-08-11 | 2010-12-15 | 中国科学技术大学苏州研究院 | Performance Optimization Method of Last Level Cache Based on Partition Awareness and Thread Awareness |
| CN103049310A (en) * | 2012-12-29 | 2013-04-17 | 中国科学院深圳先进技术研究院 | Multi-core simulation parallel accelerating method based on sampling |
| US20150067819A1 (en) * | 2013-08-28 | 2015-03-05 | Hola Networks Ltd. | System and Method for Improving Internet Communication by Using Intermediate Nodes |
| CN109271288A (en) * | 2017-07-17 | 2019-01-25 | 展讯通信(上海)有限公司 | Processor silicon pre-performance evaluation method |
| CN111651341A (en) * | 2020-07-14 | 2020-09-11 | 中国人民解放军国防科技大学 | A Performance Evaluation Method for General-Purpose Processors |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116894209A (en) * | 2023-09-05 | 2023-10-17 | 北京开源芯片研究院 | Sampling point classification method, device, electronic equipment and readable storage medium |
| CN116894209B (en) * | 2023-09-05 | 2023-12-22 | 北京开源芯片研究院 | Sampling point classification method, device, electronic equipment and readable storage medium |
| WO2025161419A1 (en) * | 2024-02-02 | 2025-08-07 | 华为技术有限公司 | Performance analysis method, application method, device, readable medium and program product |
| CN120631705A (en) * | 2025-08-12 | 2025-09-12 | 北京壁仞科技开发有限公司 | Method, computing device, medium, and program product for predicting the performance of a computing system on which an application program runs |
| CN120724936A (en) * | 2025-08-29 | 2025-09-30 | 蓝芯算力(深圳)科技有限公司 | Universal checkpoint generation method, system and related equipment for simulator |
| CN120724936B (en) * | 2025-08-29 | 2025-11-11 | 蓝芯算力(深圳)科技有限公司 | Method, system and related equipment for generating check points of simulator in general way |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN116149917A (en) | Method and device for evaluating processor performance, computing device, and readable storage medium | |
| CN101650687B (en) | Large-scale parallel program property-predication realizing method | |
| US7797658B2 (en) | Multithreaded static timing analysis | |
| US11200149B2 (en) | Waveform based reconstruction for emulation | |
| CN108885579B (en) | Method and apparatus for data mining from nuclear traces | |
| US10540466B1 (en) | Systems and methods for streaming waveform data during emulation run | |
| Hierons et al. | Parallel algorithms for testing finite state machines: Generating UIO sequences | |
| US20060130029A1 (en) | Programming language model generating apparatus for hardware verification, programming language model generating method for hardware verification, computer system, hardware simulation method, control program and computer-readable storage medium | |
| JPH07334395A (en) | Evaluation method of data processing speed | |
| CN119271545A (en) | Code evaluation and conversion method, system and medium applied to heterogeneous multi-core chips | |
| US20130013283A1 (en) | Distributed multi-pass microarchitecture simulation | |
| US10102099B2 (en) | Performance information generating method, information processing apparatus and computer-readable storage medium storing performance information generation program | |
| CN120353684B (en) | A method and system for evaluating computer hardware performance based on simulation model | |
| CN114253821B (en) | A method, device and computer storage medium for analyzing GPU performance | |
| CN108008999A (en) | Index evaluating method and device | |
| WO2018032897A1 (en) | Method and device for evaluating packet forwarding performance and computer storage medium | |
| US11875095B2 (en) | Method for latency detection on a hardware simulation accelerator | |
| CN115543719B (en) | Component optimization method and device based on chip design, computer equipment and medium | |
| US10747601B2 (en) | Failure estimation in circuits | |
| CN117785641A (en) | RTL simulation performance evaluation method, device, terminal and medium | |
| CN118427094A (en) | Fuzzy test method, system, equipment and storage medium for embedded system | |
| CN118170597A (en) | Instruction verification method, device, electronic device and storage medium | |
| CN115408256B (en) | Benchmark test program generation method, benchmark test program generation device, computer equipment and storage medium | |
| CN115878440B (en) | Method, electronic device, medium and program for statically analyzing NPU instruction performance | |
| Sankaran et al. | Discriminating equivalent algorithms via relative performance |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |