CN116128024A - Multi-perspective comparative self-supervised attribute network outlier detection method - Google Patents
Multi-perspective comparative self-supervised attribute network outlier detection method Download PDFInfo
- Publication number
- CN116128024A CN116128024A CN202211445037.6A CN202211445037A CN116128024A CN 116128024 A CN116128024 A CN 116128024A CN 202211445037 A CN202211445037 A CN 202211445037A CN 116128024 A CN116128024 A CN 116128024A
- Authority
- CN
- China
- Prior art keywords
- view
- target node
- attribute
- node
- subgraph
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/761—Proximity, similarity or dissimilarity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Testing And Monitoring For Control Systems (AREA)
Abstract
本发明公开了一种多视角对比自监督属性网络异常点检测方法,结合属性网络的节点结构和属性信息特征,提出了一种新的对比实例对,将多视角采样应用到对比学习异常检测中,从而使网络异常检测可以同时抓住结构上的异常和属性上的异常。主要包括:对属性网络进行异常注入;进行多视角采样得到多视角对比实例对;设计并训练多视角图神经网络对比学习模型;使用训练好的对比学习模型进行推理阶段,计算异常得分;通过异常得分,判断节点是否异常,进行异常节点的标记。通过在各种数据集上进行了广泛的实验,该方法除能够有效提升异常检测准确度外,也能够挖掘网络中存在的有实际意义的异常。

The invention discloses a multi-perspective comparative self-supervised attribute network anomaly detection method, combines the node structure and attribute information characteristics of the attribute network, proposes a new comparison instance pair, and applies multi-perspective sampling to comparative learning anomaly detection , so that the network anomaly detection can capture both structural anomalies and attribute anomalies. It mainly includes: injecting abnormalities into the attribute network; performing multi-view sampling to obtain multi-view comparative instance pairs; designing and training a multi-view graph neural network comparative learning model; Score, judge whether the node is abnormal, and mark the abnormal node. Through extensive experiments on various data sets, this method can not only effectively improve the accuracy of anomaly detection, but also mine meaningful anomalies in the network.
Description
技术领域Technical Field
本发明涉及网络安全领域,尤其涉及一种多视角对比自监督属性网络异常点检测方法。The present invention relates to the field of network security, and in particular to a multi-view comparison self-supervisory attribute network anomaly detection method.
背景技术Background Art
近年来,已有大量的研究关注属性网络异常检测任务,属性网络异常检测方法主要分为传统的非深度异常检测和深度异常检测两种。In recent years, a lot of research has focused on the attribute network anomaly detection task. Attribute network anomaly detection methods are mainly divided into two types: traditional non-deep anomaly detection and deep anomaly detection.
传统的非深度异常检测采用不同的分解策略从图结构和节点属性中提取有价值的信息,然后通过评分函数或残差分析发现异常节点,重点使用了矩阵分解(MF)技术。AMEN[1]考虑了每个节点的自我网络信息,并发现了属性网络上的异常邻域。此外,一些研究专注于发现节点特征子空间中的异常节点。ANOMALOUS[2]进一步将CUR分解纳入到残差分析中,以减轻噪声特征对异常检测的不利影响。然而,这些方法受到其浅层机制的限制,无法处理属性网络的关键问题,如网络稀疏性、数据非线性和不同信息源之间的复杂模式互动和计算挑战。随着用于异常检测的深度学习的飞速发展,研究人员提出了基于深度学习的方法来解决属性网络上的异常检测问题。Traditional non-deep anomaly detection uses different decomposition strategies to extract valuable information from graph structures and node attributes, and then discovers abnormal nodes through scoring functions or residual analysis, focusing on the use of matrix factorization (MF) technology. AMEN[1] considers the self-network information of each node and discovers abnormal neighborhoods on attribute networks. In addition, some studies focus on discovering abnormal nodes in node feature subspaces. ANOMALOUS[2] further incorporates CUR decomposition into residual analysis to alleviate the adverse effects of noise features on anomaly detection. However, these methods are limited by their shallow mechanisms and cannot handle key issues of attribute networks, such as network sparsity, data nonlinearity, and complex pattern interactions between different information sources and computational challenges. With the rapid development of deep learning for anomaly detection, researchers have proposed deep learning-based methods to solve the problem of anomaly detection on attribute networks.
最近,深度学习成为人工智能和机器学习中极为重要的部分,在提取数据中潜在复杂模式表现出优越的性能,在音频、图像和自然语言处理等领域得到了广泛应用。深度学习方法能够有效处理复杂的属性信息,并且可以从数据中学习隐含的规律。以下是常用的深度异常检测方法:Recently, deep learning has become an extremely important part of artificial intelligence and machine learning. It has shown excellent performance in extracting potential complex patterns in data and has been widely used in audio, image, and natural language processing. Deep learning methods can effectively process complex attribute information and learn implicit rules from data. The following are commonly used deep anomaly detection methods:
基于网络表示学习:将图形结构编码到嵌入式向量空间中,将邻居信息聚合到中心节点,通过训练损失函数找到异常节点和正常节点边缘之间的相对尺度。Based on network representation learning: encode the graph structure into the embedded vector space, aggregate the neighbor information to the central node, and find the relative scale between the abnormal nodes and the normal node edges through the training loss function.
基于图卷积神经网络:节点的表示通过GCN层生成,然后根据其神经网络的重建(此时重建损失作为异常分数)或者嵌入空间的分布(此时根据密度估计进行异常排名)来检测异常。DOMINANT[3]构造图自动编码器同时重构属性和结构信息,并通过重构误差对异常进行评估。Based on graph convolutional neural networks: The representation of the node is generated through the GCN layer, and then anomalies are detected based on the reconstruction of its neural network (in this case, the reconstruction loss is used as the anomaly score) or the distribution of the embedding space (in this case, anomaly ranking is performed based on density estimation). DOMINANT[3] constructs a graph autoencoder to simultaneously reconstruct attribute and structural information, and evaluates anomalies through reconstruction error.
基于图注意力网络:给定输入图,对于图上任意顶点都用注意力机制来学习节点嵌入。无监督技术AnomalyDAE[4]根据重建损失对每个节点进行评分,并将top-k节点标记为异常。Based on graph attention network: Given an input graph, an attention mechanism is used to learn node embedding for any vertex on the graph. The unsupervised technique AnomalyDAE[4] scores each node based on the reconstruction loss and marks the top-k nodes as abnormal.
基于对比学习:通过对比正实例对和负实例对来学习节点。设计一个对比学习模型来学习节点-子图实例对的向量表示,通过判别器对节点进行异常得分计算。Based on contrastive learning: learn nodes by comparing positive instance pairs and negative instance pairs. Design a contrastive learning model to learn the vector representation of node-subgraph instance pairs, and calculate the abnormality score of the node through the discriminator.
[参考文献][References]
[1]Perozzi B,Akoglu L.Scalable anomaly ranking of attributedneighborhoods[C].In Proceedings of the 2016SIAM International Conference onData Mining,2016:207–215.[1]Perozzi B,Akoglu L.Scalable anomaly ranking of attributedneighborhoods[C].In Proceedings of the 2016SIAM International Conference onData Mining,2016:207–215.
[2]Peng Z,Luo M,Li J,et al.ANOMALOUS:A Joint Modeling Approach forAnomaly Detection on Attributed Networks.[C].In IJCAI,2018:3513–3519.[2]Peng Z, Luo M, Li J, et al. ANOMALOUS: A Joint Modeling Approach for Anomaly Detection on Attributed Networks. [C]. In IJCAI, 2018: 3513–3519.
[3]Ding K,Li J,Bhanushali R,et al.Deep anomaly detection onattributed networks[C].In Proceedings of the 2019SIAM InternationalConference on Data Mining,2019:594–602.[3]Ding K, Li J, Bhanushali R, et al. Deep anomaly detection onattributed networks [C]. In Proceedings of the 2019SIAM International Conference on Data Mining, 2019:594–602.
[4]Fan H,Zhang F,Li Z.AnomalyDAE:Dual autoencoder for anomalydetection on attributed networks[C].In ICASSP 2020-2020IEEE InternationalConference on Acoustics,Speech and Signal Processing(ICASSP),2020:5685–5689.[4]Fan H, Zhang F, Li Z.AnomalyDAE: Dual autoencoder for anomalydetection on attributed networks[C].In ICASSP 2020-2020IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), 2020:5685–5689.
发明内容Summary of the invention
由于传统的属性网络异常检测算法无法处理大规模数据,忽略特征属性信息,深度学习算法虽处理特征信息更加强大,但这些工作大多是以学习数据表示为目的,而不直接针对检测异常。因此,本发明提出了一种多视角对比自监督属性网络异常点检测方法,以实现对大规模属性网络的异常检测。Since traditional attribute network anomaly detection algorithms cannot process large-scale data and ignore feature attribute information, although deep learning algorithms are more powerful in processing feature information, most of these works are aimed at learning data representation rather than directly detecting anomalies. Therefore, this paper proposes a multi-perspective comparison self-supervised attribute network anomaly detection method to achieve anomaly detection of large-scale attribute networks.
为了解决上述技术问题,本发明提出的一种多视角对比自监督属性网络异常点检测方法,包括以下步骤:In order to solve the above technical problems, the present invention proposes a multi-view contrast self-supervised attribute network outlier detection method, which includes the following steps:
步骤一、对属性网络进行异常注入,包括,结构异常注入和属性异常注入;Step 1: Perform anomaly injection on the attribute network, including structural anomaly injection and attribute anomaly injection;
步骤二、进行多视角采样得到多视角对比实例对,包括:Step 2: Perform multi-view sampling to obtain multi-view comparison instance pairs, including:
2-1)对异常注入之后的属性网络进行目标节点的选择,随机的遍历该属性网络中的每个节点作为目标节点;2-1) Select the target node for the attribute network after the anomaly injection, and randomly traverse each node in the attribute network as the target node;
2-2)通过一个采样器,分别基于结构重要性和属相相似度对同一个目标节点进行子采样得到与该目标节点对应的局部子图1和局部子图2,基于结构重要性记为视角1,基于属相相似度记为视角2;在得到局部子图1的过程中,通过引入的广度优先参数p和深度优先参数q用于控制游走,p>1,q<1,在得到局部子图2的过程中,通过计算该目标节点的属性相似度控制游走;2-2) Through a sampler, the same target node is subsampled based on structural importance and attribute similarity to obtain
2-3)对步骤2-2)得到两个局部子图进行匿名化,将目标节点的属性向量设为零向量;2-3) Anonymize the two local subgraphs obtained in step 2-2) and set the attribute vector of the target node to a zero vector;
2-4)将匿名化的目标节点与局部子图1合并成一组实例对,将匿名化的目标节点与局部子图2合并成另一组实例对;将上述两组实例对的正样例对和负样例对分别保存到相应的两个样本池中;2-4) Merge the anonymized target node and
步骤三、设计并训练多视角图神经网络对比学习模型,包括:Step 3: Design and train a multi-view graph neural network comparative learning model, including:
3-1)设计多视角图神经网络对比学习模型,该多视角图神经网络对比学习模型包括多视角图神经网络模块、读出模块和鉴别器模块;所述多视角图神经网络模块通过两个图卷积神经网络分别得到两个视角的子图表示和目标节点表示;所述读出模块将子图表示变为子图向量表示,使用平均池函数作为读出函数;所述鉴别器模块使用双线性评分函数对比实例对中的节点向量表示和子图向量表示;3-1) Design a multi-view graph neural network contrastive learning model, which includes a multi-view graph neural network module, a readout module and a discriminator module; the multi-view graph neural network module obtains subgraph representations and target node representations of two views respectively through two graph convolutional neural networks; the readout module converts the subgraph representation into a subgraph vector representation, and uses an average pooling function as a readout function; the discriminator module uses a bilinear scoring function to compare the node vector representation and the subgraph vector representation in the instance pair;
3-2)初始化所述的多视角图神经网络对比学习模型的参数(W(0),W(L),W(d)),W为判别器权值矩阵;利用二元分类目标函数对该对比学习模型进行训练,得到用于训练的节点的预测分数,并利用该预测分数和二元分类目标函数反向传播更新对比学习模型参数;3-2) Initializing the parameters of the multi-view graph neural network contrastive learning model (W (0) , W (L) , W (d) ), where W is the discriminator weight matrix; training the contrastive learning model using a binary classification objective function to obtain a prediction score of the node used for training, and back-propagating the prediction score and the binary classification objective function to update the contrastive learning model parameters;
步骤四、使用训练好的对比学习模型进行推理阶段,使用更新后的对比学习模型参数同时使用二元分类目标函数得到节点的预测分数,通过多轮计算取平均值得到最后异常得分;Step 4: Use the trained contrastive learning model to perform the inference phase, use the updated contrastive learning model parameters and the binary classification objective function to obtain the predicted score of the node, and take the average value through multiple rounds of calculation to obtain the final anomaly score;
步骤五、将异常得分为0.5±0.05的目标节点视为异常节点,将异常节点标记为1,将非异常节点标记为0。Step 5: The target nodes with anomaly scores of 0.5±0.05 are regarded as abnormal nodes, and the abnormal nodes are marked as 1, and the non-abnormal nodes are marked as 0.
进一步讲,本发明所述的多视角对比自监督属性网络异常点检测方法,其中:Furthermore, the multi-view contrast self-supervised attribute network outlier detection method described in the present invention comprises:
步骤2-4)中:所述两组实例对表示如下:In step 2-4): the two sets of instance pairs are represented as follows:


式(1)中,










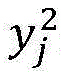



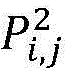
步骤3-1)中:式(2)示出了所述的子图表示:In step 3-1), formula (2) shows the subgraph representation:

式(2)中,



式(3)示出了所述的目标节点表示:Formula (3) shows the target node representation:

式(3)中,


所述的读出函数如式(4)所示:The readout function is shown in formula (4):

式(4)中,
步骤3-2)中,通过式(5)和式(6)计算用于训练的节点的预测分数:In step 3-2), the prediction score of the node used for training is calculated by equations (5) and (6):


式(5)和式(6)中,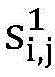







步骤三和步骤四中,所述的二元分类目标函数如下:In step 3 and step 4, the binary classification objective function is as follows:

式(7)中,CLM()是多视角图神经网络对比学习模型。In formula (7), CLM() is a multi-view graph neural network contrastive learning model.
步骤四中,所述的异常得分计算公式如下:In step 4, the abnormality score calculation formula is as follows:

式(8)中,f()是异常评分映射函数,



与现有技术相比,本发明的有益效果是:Compared with the prior art, the present invention has the following beneficial effects:
将本发明提出的多视角对比自监督属性网络异常点检测方法(本发明中简称为MV-CoLA)方法与四种属性网络异常检测方法(一种基于属性网络异常检测的联合建模方法-ANOMALOUS,属性网络深度深度异常检测方法-DOMINANT,图深度最大化互信息方法-DGI,对比自监督学习属性网络异常检测方法-CoLA)进行了比较。AUC值:ROC曲线是根据地面真实异常标签和异常检测结果,真阳性率(异常识别为异常)与假阳性率(正常节点识别为异常)的图。AUC值为ROC曲线下的面积,表示随机选择的异常节点排名高于正常节点的概率。AUC接近于1,表示该方法具有较高的性能。通过计算ROC曲线下面积,不同对比方法在6个数据集的AUC值如表3所示,在所有6个数据集上,本发明方法均取得了最好的异常检测性能。本发明方法与对比方法CoLA的最佳结果相比,平均AUC均得到了提高。主要原因是本发明方法中通过多视角实例对采样成功地捕获了每个节点与其局部子图之间的关系和属性特征,利用多视角的GNN的对比学习模型从上下文和结构信息中计算异常分数。The multi-view contrast self-supervised attribute network anomaly detection method (referred to as MV-CoLA in the present invention) proposed in the present invention is compared with four attribute network anomaly detection methods (a joint modeling method based on attribute network anomaly detection-ANOMALOUS, attribute network deep anomaly detection method-DOMINANT, graph depth maximization mutual information method-DGI, contrast self-supervised learning attribute network anomaly detection method-CoLA). AUC value: The ROC curve is a graph of the true positive rate (anomaly identified as anomaly) and the false positive rate (normal node identified as anomaly) based on the ground truth anomaly label and anomaly detection results. The AUC value is the area under the ROC curve, which indicates the probability that a randomly selected abnormal node is ranked higher than a normal node. AUC is close to 1, indicating that the method has a higher performance. By calculating the area under the ROC curve, the AUC values of different comparison methods on 6 data sets are shown in Table 3. On all 6 data sets, the method of the present invention has achieved the best anomaly detection performance. Compared with the best results of the comparison method CoLA, the average AUC of the method of the present invention has been improved. The main reason is that the method of the present invention successfully captures the relationship and attribute characteristics between each node and its local subgraph through multi-view instance pair sampling, and uses the multi-view GNN contrastive learning model to calculate the anomaly score from the context and structural information.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
图1是本发明多视角对比自监督属性网络异常点检测方法框图;FIG1 is a block diagram of a multi-view contrast self-supervised attribute network outlier detection method according to the present invention;
图2是图1中所示多视角采样示意图;FIG2 is a schematic diagram of multi-view sampling shown in FIG1 ;
图3是本发明多视角对比自监督属性网络异常点检测方法流程图;FIG3 is a flow chart of a multi-view contrast self-supervised attribute network outlier detection method according to the present invention;
图4是本发明实施例中6000个节点的局部论文合作网络异常检测结果;FIG4 is an anomaly detection result of a local paper collaboration network of 6000 nodes in an embodiment of the present invention;
图5-1和图5-2是本发明实施例中排名前1000的异常节点对应所属机构分布。FIG. 5-1 and FIG. 5-2 show the distribution of the organizations to which the top 1000 abnormal nodes belong in an embodiment of the present invention.
具体实施方式DETAILED DESCRIPTION
本发明提出一种多视角对比自监督属性网络异常点检测方法的设计构思是:结合属性网络的节点结构和属性信息特征,提出了一种新的对比实例对,将多视角采样应用到对比学习异常检测中,从而使网络异常检测可以同时抓住结构上的异常和属性上的异常,将本发明方法在各种数据集上进行了广泛的实验,证明该方法优于许多对比方法,除能够有效提升异常检测准确度外,还能够挖掘网络中存在的有实际意义的异常。The present invention proposes a multi-perspective comparative self-supervised attribute network anomaly detection method with the following design concept: combining the node structure and attribute information characteristics of the attribute network, a new comparative instance pair is proposed, and multi-perspective sampling is applied to comparative learning anomaly detection, so that network anomaly detection can simultaneously capture structural anomalies and attribute anomalies. The method of the present invention has been widely experimented on various data sets, which proves that the method is superior to many comparative methods. In addition to being able to effectively improve the accuracy of anomaly detection, it can also mine practical anomalies in the network.
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments, but the following embodiments are by no means intended to limit the present invention in any way.
如图1和图3所示本发明提出的一种多视角对比自监督属性网络异常点检测方法,主要包括以下步骤:As shown in FIG1 and FIG3 , the present invention proposes a multi-view contrast self-supervised attribute network outlier detection method, which mainly includes the following steps:
步骤一、对属性网络进行异常注入;Step 1: Inject anomalies into the attribute network;
步骤二、进行多视角采样得到多视角对比实例对;Step 2: Perform multi-view sampling to obtain multi-view comparison instance pairs;
步骤三、设计并训练多视角图神经网络对比学习模型;Step 3: Design and train a multi-view graph neural network comparative learning model;
步骤四、使用训练好的对比学习模型进行推理阶段,计算异常得分;Step 4: Use the trained contrastive learning model to perform the inference phase and calculate the anomaly score;
步骤五、通过异常得分,判断节点是否异常,进行异常节点的标记。Step 5: Use the anomaly score to determine whether the node is abnormal and mark the abnormal node.
各步骤详细描述如下:Each step is described in detail as follows:
步骤一:输入属性网络,进行异常注入,包括结构异常注入和属性异常注入。Step 1: Input the attribute network and perform exception injection, including structural exception injection and attribute exception injection.
将NNSF数据集处理成本方法需要的数据格式,由于NNSF数据集含有真实异常标签,不需要对数据集进行异常注入。The NNSF dataset is processed into the data format required by the cost method. Since the NNSF dataset contains real anomaly labels, there is no need to inject anomalies into the dataset.
本实施例在6个广泛使用的数据集上评估了MV-CoLA方法。这些数据集包括两个社交网络数据集和四个引文网络数据集。数据集详情见表1。由于在上述数据集中没有真实异常,需要将异常注入到属性网络中。结构异常注入,将团大小指定为中m后,从网络中随机选择中m个节点,使这些节点完全连接,然后将团中的中m个节点视为异常。迭代地重复这个过程,直到生成中n个团,结构异常的总数为中m×n。属性异常注入,首先随机选择另一个中m×n个节点作为属性扰动候选。对于每个选择的节点中i,从数据中随机选取另一个i个节点,通过最大化欧氏距离中||x_{i}-x_{j}||{2},选择k个节点中属性与节点i偏差最大的节点j。然后,将节点x_{i}的属性更改为x_{j}。输入MV-CoLA方法参数,训练周期T,批次大小:B,采样轮数R,游走概率p,q。This example evaluates the MV-CoLA method on six widely used datasets. These datasets include two social network datasets and four citation network datasets. See Table 1 for details of the datasets. Since there are no real anomalies in the above datasets, anomalies need to be injected into the attribute network. Structural anomaly injection, after specifying the cluster size as m, randomly select m nodes from the network, make these nodes fully connected, and then treat the m nodes in the cluster as anomalies. Repeat this process iteratively until n clusters are generated, and the total number of structural anomalies is m×n. Attribute anomaly injection, first randomly select another m×n node as an attribute perturbation candidate. For each selected node i, randomly select another i nodes from the data, and select the node j with the largest attribute deviation from node i among the k nodes by maximizing the Euclidean distance ||x_ {i} -x_ {j} || {2} . Then, change the attribute of node x_{i} to x_ {j} . Input MV-CoLA method parameters, training period T, batch size: B, number of sampling rounds R, walk probability p, q.
表1、6个实验数据集Table 1. 6 experimental datasets
社交网络:BlogCatalog和Flickr,在这些数据集中,节点表示网站的用户,边表示用户之间的关系。在社交网络中,用户通常会生成个性化的内容,如发布博客或分享带有标签描述的照片,这些文本内容被视为节点属性。Social networks: BlogCatalog and Flickr, in these datasets, nodes represent users of the website, and edges represent the relationship between users. In social networks, users usually generate personalized content, such as posting blogs or sharing photos with label descriptions, and these text contents are regarded as node attributes.
引文网络:Cora、citeseer、Pubmed、ACM是四个可用的公共数据集,它们由科学出版物组成。在这些网络中,节点表示已发表的论文,而边表示论文之间的引文关系。Citation networks: Cora, CiteSeer, Pubmed, ACM are four available public datasets consisting of scientific publications. In these networks, nodes represent published papers, while edges represent citation relationships between papers.
卷积层数设置为1。嵌入维数设定为64。每个数据集的批次大小B被设置为300。BlogCatalog、Flickr和ACM数据集的训练周期T为400,Cora、Citeseer和Pubmed数据集的训练周期T为100。Cora、Citeseer、Pubmed和Flickr的学习率为0.001,BlogCatalog和ACM的学习率分别设置为0.003和0.0005。The number of convolutional layers is set to 1. The embedding dimension is set to 64. The batch size B for each dataset is set to 300. The training epoch T is 400 for BlogCatalog, Flickr, and ACM datasets, and 100 for Cora, Citeseer, and Pubmed datasets. The learning rate is 0.001 for Cora, Citeseer, Pubmed, and Flickr, and 0.003 and 0.0005 for BlogCatalog and ACM, respectively.
步骤二、进行多视角采样得到多视角对比实例对。Step 2: Perform multi-view sampling to obtain multi-view comparison instance pairs.
首先进行目标节点的选择,随机的遍历图中的每个节点作为目标节点。然后进行多视角采样,通过一个采样器,从两个视角对相同的节点进行子采样,采样器由两种采样方法进行局部子图采样。第一个视角(基于结构重要性,即视角1)采样方法引入两个参数p(广度优先BFS)和q(深度优先DFS)控制游走策略。p和q值不同时,采样子图不同。如果p>1,游走倾向于节点邻居,反映出BFS特性如果q<1游走会倾向于往远处跑,反映出DFS特性。同时控制p,q得到基于结构重要性采样的局部子图1。第二个视角(基于属相相似度,即视角2)采样根据计算节点属性相似度进行游走。具体步骤如图2所示。其次匿名化,将初始节点的属性向量设为零向量,防止对比学习模型容易识别局部子图中目标节点的存在。最后组合成实例对,构建上述基于多视角互相融合的多视角对比实例对,将视角1的目标节点和局部子图2合并成一组实例对,另一组实例对则由局部子图1和视角2的目标节点构成,将两组实例对的正样例对(目标节点实例对)和负样例对(目标节点以外的实例对)分别保存到相应的样本池中。First, the target node is selected, and each node in the graph is randomly traversed as the target node. Then multi-perspective sampling is performed. Through a sampler, the same node is sub-sampled from two perspectives. The sampler uses two sampling methods to sample local subgraphs. The first perspective (based on structural importance, that is, perspective 1) sampling method introduces two parameters p (breadth-first BFS) and q (depth-first DFS) to control the wandering strategy. When the p and q values are different, the sampled subgraphs are different. If p>1, the wandering tends to the node neighbors, reflecting the BFS characteristics. If q<1, the wandering tends to run far away, reflecting the DFS characteristics. Control p and q at the same time to obtain
受视觉表示学习的多视角对比学习最新进展的启发,通过最大化一个视角的节点表示和另一个视角的图表示之间的互信息来学习节点和图表示,与对比全局或多视角相比,两个视角对比可以获得更好的节点表示。由此,本发明设计了一种新的多视角对比学习方法,通过一个采样器,从两个视角对相同的节点进行子采样,子采样由两个有效的游走机制组成,结合了带属性随机游走和带结构随机游走的优点。其中节点不仅具有网络连接A的特征,还具有节点属性X所描述的丰富辅助信息。联合采样A和X将使随机游走更有信息性。采样分为四个步骤:目标节点选择、多视角采样、匿名化和组合成实例对。Inspired by the latest progress in multi-view contrastive learning for visual representation learning, node and graph representations are learned by maximizing the mutual information between node representations from one view and graph representations from another view. Compared with comparing global or multi-views, two-view contrast can obtain better node representations. Therefore, the present invention designs a new multi-view contrastive learning method, which sub-samples the same nodes from two views through a sampler. The sub-sampling consists of two effective walk mechanisms, combining the advantages of attributed random walks and structured random walks. Among them, the nodes not only have the characteristics of network connections A, but also have rich auxiliary information described by the node attributes X. Joint sampling of A and X will make the random walk more informative. Sampling is divided into four steps: target node selection, multi-view sampling, anonymization, and combination into instance pairs.
2-1)目标节点选择。对异常注入(本实施例中无需)之后的属性网络进行目标节点的选择,随机的遍历该属性网络中的每个节点作为目标节点。2-1) Target node selection: After the abnormal injection (not necessary in this embodiment), the attribute network is selected as the target node, and each node in the attribute network is randomly traversed as the target node.
2-2)多图采样。通过一个采样器,分别从两个视角,即视角1是基于结构重要性和视角2是基于属相相似度,对同一个目标节点进行子采样,得到与该目标节点对应的基于结构重要性视角1的局部子图1和基于属相相似度视角2的局部子图2。2-2) Multi-graph sampling. Through a sampler, the same target node is sub-sampled from two perspectives, namely,
采样器由两个随机游走方法作为局部子图采样策略,在得到局部子图1的过程中,通过引入的广度优先参数p和深度优先参数q用于控制游走,p>1,q<1。在得到局部子图2的过程中,通过计算该目标节点的属性相似度控制游走,如图2所示。The sampler uses two random walk methods as local subgraph sampling strategies. In the process of obtaining
2-3)匿名化,匿名化的目的是防止对比学习方法容易识别局部子图中目标节点的存在。对步骤2-2)得到两个局部子图进行匿名化,将目标节点的属性向量设为零向量。2-3) Anonymization: The purpose of anonymization is to prevent the contrastive learning method from easily identifying the existence of the target node in the local subgraph. The two local subgraphs obtained in step 2-2) are anonymized, and the attribute vector of the target node is set to a zero vector.
2-4)组合成实例对。将匿名化的目标节点和子图合并成一组实例对,具体是:将匿名化的目标节点与局部子图1合并成一组实例对,将匿名化的目标节点与局部子图2合并成另一组实例对;将上述两组实例对的正样例对和负样例对分别保存到相应的两个样本池中。2-4) Combine into instance pairs. The anonymized target node and the subgraph are combined into a set of instance pairs. Specifically, the anonymized target node and the
所述两组实例对表示如下:The two sets of example pairs are represented as follows:


式(1)中,















步骤三、设计并训练多视角图神经网络对比学习模型,更新多视角图神经网络对比学习模型。Step 3: Design and train a multi-view graph neural network comparative learning model, and update the multi-view graph neural network comparative learning model.
采样的多视角对比实例对用于训练多视角图神经网络对比学习模型。多视角图神经网络对比学习模型由三个主要组件组成:多视角图神经网络模块、读出模块和鉴别器模块。其中多视角图神经网络模块通过两个图卷积神经网络模块分别得到两个视角的子图表示。读出模块将子图表示变为向量表示,使用平均池函数作为的读出函数。鉴别器模块使用双线性评分函数对比了一个实例对中的两个元素的嵌入,并输出最终的预测分数。最后通过整合多视角图神经网络模块、读出模块和鉴别器模块三个组件,将多视角图神经网络对比学习模型作为一个二元分类目标函数来预测对比实例对的标签。具体描述如下:The sampled multi-view contrast instance pairs are used to train the multi-view graph neural network contrastive learning model. The multi-view graph neural network contrastive learning model consists of three main components: a multi-view graph neural network module, a readout module, and a discriminator module. The multi-view graph neural network module obtains subgraph representations of two views respectively through two graph convolutional neural network modules. The readout module converts the subgraph representation into a vector representation and uses the average pooling function as the readout function. The discriminator module uses a bilinear scoring function to compare the embeddings of two elements in an instance pair and outputs the final prediction score. Finally, by integrating the three components of the multi-view graph neural network module, the readout module, and the discriminator module, the multi-view graph neural network contrastive learning model is used as a binary classification objective function to predict the labels of the contrast instance pairs. The specific description is as follows:
3-1)设计多视角图神经网络对比学习模型,该多视角图神经网络对比学习模型包括多视角图神经网络模块、读出模块和鉴别器模块。3-1) Design a multi-view graph neural network contrastive learning model, which includes a multi-view graph neural network module, a readout module and a discriminator module.
多视角图神经网络模块。目标是聚合局部子图中节点之间的信息,并将高维属性转移到低维嵌入空间中。本发明设计两个图卷积神经网络分别得到两个视角的子图表示。Multi-view graph neural network module. The goal is to aggregate the information between nodes in the local subgraph and transfer the high-dimensional attributes to the low-dimensional embedding space. The present invention designs two graph convolutional neural networks to obtain subgraph representations of two perspectives respectively.

其中,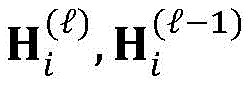


式(2)中,



目标节点表示:The target node represents:

式(3)中,


读出模块。目标是将子图表示变为向量表示。为了简化,使用平均池函数作为的读出函数,读出函数写如下:Readout module. The goal is to transform the subgraph representation into a vector representation. For simplicity, the average pooling function is used as the readout function, and the readout function is written as follows:

式(4)中,
鉴别模块。鉴别模块是的对比学习方法的核心组成部分。它对比了一个实例对中的两个元素的嵌入,使用双线性评分函数对比实例对中的节点向量表示和子图向量表示。Discriminative module. The discriminative module is the core component of the contrastive learning method. It compares the embeddings of two elements in an instance pair, using a bilinear scoring function to compare the node vector representation and the subgraph vector representation in the instance pair.
3-2)初始化所述的多视角图神经网络对比学习模型的参数(W(0),W(L),W(d)),W为判别器权值矩阵;利用二元分类目标函数对该对比学习模型进行训练,得到用于训练的节点的预测分数,并利用该预测分数和二元分类目标函数反向传播更新对比学习模型参数;3-2) Initializing the parameters of the multi-view graph neural network contrastive learning model (W (0) , W (L) , W (d) ), where W is the discriminator weight matrix; training the contrastive learning model using a binary classification objective function to obtain a prediction score of the node used for training, and back-propagating the prediction score and the binary classification objective function to update the contrastive learning model parameters;
通过式(5)和式(6)计算用于训练的节点的预测分数:The prediction score of the node used for training is calculated by equations (5) and (6):


式(5)和式(6)中,







本发明中,通过整合上述三个组件,提出的基于图神经网络的对比学习方法作为一个二元分类方法来预测对比实例对的标签,所述的二元分类目标函数如下:In the present invention, by integrating the above three components, the proposed contrastive learning method based on graph neural network is used as a binary classification method to predict the labels of contrast instance pairs. The binary classification objective function is as follows:

式(7)中,CLM()是多视角图神经网络对比学习模型。In formula (7), CLM() is a multi-view graph neural network contrastive learning model.
步骤四、使用训练好的对比学习模型进行推理阶段,使用更新后的对比学习模型参数同时通过一个分类器使用二元分类目标函数得到节点的预测分数,通过多轮计算取平均值得到最后异常得分。Step 4: Use the trained contrastive learning model to perform the inference phase. Use the updated contrastive learning model parameters and a classifier to use the binary classification objective function to obtain the node prediction score. Take the average value through multiple rounds of calculation to obtain the final anomaly score.
在对比学习方法经过良好的训练后,通过分类器得到一个视角的节点表示和另一个视角的子图表示之间的一致性。在理想条件下,对于一个正常节点,其正对s(+)的预测得分应接近1,而负对s(-)应接近0。对于一个异常节点,方法不能很好地区分其匹配模式,其正负对的预测得分较差(接近0.5)。After the contrastive learning method is well trained, the consistency between the node representation from one perspective and the subgraph representation from another perspective is obtained through the classifier. Under ideal conditions, for a normal node, the prediction score of its positive pair s (+) should be close to 1, while the negative pair s (-) should be close to 0. For an abnormal node, the method cannot distinguish its matching pattern well, and its prediction score of positive and negative pairs is poor (close to 0.5).

式(8)中,f()是异常评分映射函数,



步骤五、将异常得分为0.5±0.05的目标节点视为异常节点,将异常节点标记为1,将非异常节点标记为0。Step 5: The target nodes with anomaly scores of 0.5±0.05 are regarded as abnormal nodes, and the abnormal nodes are marked as 1, and the non-abnormal nodes are marked as 0.
本实施例中,计算256轮异常得分取平均值得到节点的异常得分,如果分数接近0.5,那么这个节点将视为异常。将MV-CoLA方法与四种属性网络异常检测方法(ANOMALOUS,DOMINANT,DGI,CoLA)进行了比较。AUC值:ROC曲线是根据地面真实异常标签和异常检测结果,真阳性率(异常识别为异常)与假阳性率(正常节点识别为异常)的图。AUC值为ROC曲线下的面积,表示随机选择的异常节点排名高于正常节点的概率。AUC接近于1,表示该方法具有较高的性能。通过计算ROC曲线下面积,不同对比方法在6个数据集的AUC值如表2所示,在所有6个数据集上,本方法都取得了最好的异常检测性能。In this embodiment, the anomaly score of the node is obtained by calculating the average of 256 rounds of anomaly scores. If the score is close to 0.5, then the node will be considered abnormal. The MV-CoLA method was compared with four attribute network anomaly detection methods (ANOMALOUS, DOMINANT, DGI, CoLA). AUC value: The ROC curve is a graph of the true positive rate (anomalies identified as anomalies) and the false positive rate (normal nodes identified as anomalies) based on the ground truth anomaly labels and anomaly detection results. The AUC value is the area under the ROC curve, which indicates the probability that a randomly selected abnormal node is ranked higher than a normal node. AUC is close to 1, indicating that the method has a higher performance. By calculating the area under the ROC curve, the AUC values of different comparison methods on 6 data sets are shown in Table 2. On all 6 data sets, this method has achieved the best anomaly detection performance.
表2Table 2
将本发明应用到真实场景中检测异常,对节点的异常分数进行排名,选取前节点进行分析,找到这些节点对应的原自科数据集对应的作者名称和所在机构,探究自科项目数据蕴含规律。The present invention is applied to real-world scenarios to detect anomalies, rank the anomaly scores of nodes, select the top nodes for analysis, find the author names and institutions corresponding to the original natural science data sets corresponding to these nodes, and explore the rules contained in the natural science project data.
将MV-CoLA应用在百万大规模网络NNSF数据集-国家自然科学基金(NationalNatural Science Foundation)数据集收录2000年至2021年共2052家研究机构789,669名学者的论文和对应的基金项目信息,共计763,311篇。研究领域按照国家学科分类,涵盖化学、生物、建筑、农业、计算机等各个领域。该数据集详情见表3。Apply MV-CoLA to the NNSF dataset of millions of large-scale networks. The National Natural Science Foundation dataset contains 763,311 papers and corresponding fund project information from 2052 research institutions and 789,669 scholars from 2000 to 2021. The research fields are classified according to national disciplines, covering chemistry, biology, architecture, agriculture, computer science and other fields. See Table 3 for details of the dataset.
表3Table 3
图4展示具有6000个节点的局部论文合作网络,图中灰色圆点是值筛选出的异常节点。网状结构为论文作者合作网络。从图中可以发现,论文作者合作网络具有小世界属性,任职于同一研究机构的研究人员之间形成较小的社团网络,人员在社团内部练习紧密,社团外部学术交流相对较少。图5-1和图5-2展示排名前1000的异常节点对应所属机构分布,统计分析发现,985高校研究人员占比最多,其中,北京大学,清华大学,中山大学和中科院研究机构参与自科项目的人员占比很高。其他非985普通高校占比20%。东南大学,大连理工大学等985高校参与自科项目的人员占比较低。Figure 4 shows a local paper collaboration network with 6,000 nodes. The gray dots in the figure are abnormal nodes that have been filtered out. The mesh structure is the paper author collaboration network. It can be seen from the figure that the paper author collaboration network has a small-world attribute. Researchers working in the same research institution form a smaller community network. The personnel practice closely within the community, and there is relatively little academic exchange outside the community. Figures 5-1 and 5-2 show the distribution of the corresponding institutions of the top 1,000 abnormal nodes. Statistical analysis shows that researchers from 985 universities account for the largest proportion. Among them, Peking University, Tsinghua University, Sun Yat-sen University and the Chinese Academy of Sciences Research Institute have a high proportion of personnel participating in natural science projects. Other non-985 ordinary universities account for 20%. 985 universities such as Southeast University and Dalian University of Technology have a low proportion of personnel participating in natural science projects.
尽管上面结合附图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。Although the present invention has been described above in conjunction with the accompanying drawings, the present invention is not limited to the above-mentioned specific embodiments, which are merely illustrative rather than restrictive. Under the guidance of the present invention, ordinary technicians in this field can make many modifications without departing from the purpose of the present invention, which are all within the protection of the present invention.
Claims (6)













































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211445037.6A CN116128024A (en) | 2022-11-18 | 2022-11-18 | Multi-perspective comparative self-supervised attribute network outlier detection method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211445037.6A CN116128024A (en) | 2022-11-18 | 2022-11-18 | Multi-perspective comparative self-supervised attribute network outlier detection method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116128024A true CN116128024A (en) | 2023-05-16 |
Family
ID=86298073
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211445037.6A Pending CN116128024A (en) | 2022-11-18 | 2022-11-18 | Multi-perspective comparative self-supervised attribute network outlier detection method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116128024A (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116913390A (en) * | 2023-07-12 | 2023-10-20 | 齐鲁工业大学(山东省科学院) | A gene regulatory network prediction method based on multi-view graph attention network |
| CN117009902A (en) * | 2023-08-02 | 2023-11-07 | 网络通信与安全紫金山实验室 | A data detection method, device, equipment and storage medium |
| CN117151160A (en) * | 2023-08-03 | 2023-12-01 | 新疆大学 | A graph anomaly detection method and model based on multi-frequency reconstruction |
| CN117201122A (en) * | 2023-09-11 | 2023-12-08 | 大连理工大学 | Unsupervised attribute network anomaly detection method and system based on view-level graph comparison learning |
| CN117828513A (en) * | 2024-03-04 | 2024-04-05 | 北京邮电大学 | A method and device for checking irrelevant citations in papers |
| CN118074958A (en) * | 2024-01-18 | 2024-05-24 | 中国人民解放军战略支援部队信息工程大学 | Network node full-granularity anomaly detection method and system based on attribute enhanced sampling |
| CN118573418A (en) * | 2024-05-16 | 2024-08-30 | 中国人民解放军战略支援部队信息工程大学 | Attribute network abnormal node detection method and system based on iterative filtering |
| CN119337377A (en) * | 2024-10-14 | 2025-01-21 | 浙江大学 | A phased anomaly detection approach for very large-scale industrial software supply chains |
-
2022
- 2022-11-18 CN CN202211445037.6A patent/CN116128024A/en active Pending
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116913390A (en) * | 2023-07-12 | 2023-10-20 | 齐鲁工业大学(山东省科学院) | A gene regulatory network prediction method based on multi-view graph attention network |
| CN117009902A (en) * | 2023-08-02 | 2023-11-07 | 网络通信与安全紫金山实验室 | A data detection method, device, equipment and storage medium |
| CN117151160A (en) * | 2023-08-03 | 2023-12-01 | 新疆大学 | A graph anomaly detection method and model based on multi-frequency reconstruction |
| CN117201122B (en) * | 2023-09-11 | 2024-06-14 | 大连理工大学 | Unsupervised attribute network anomaly detection method and system based on view level graph comparison learning |
| CN117201122A (en) * | 2023-09-11 | 2023-12-08 | 大连理工大学 | Unsupervised attribute network anomaly detection method and system based on view-level graph comparison learning |
| CN118074958B (en) * | 2024-01-18 | 2026-02-03 | 中国人民解放军网络空间部队信息工程大学 | Network node full-granularity anomaly detection method and system based on attribute enhanced sampling |
| CN118074958A (en) * | 2024-01-18 | 2024-05-24 | 中国人民解放军战略支援部队信息工程大学 | Network node full-granularity anomaly detection method and system based on attribute enhanced sampling |
| CN117828513B (en) * | 2024-03-04 | 2024-06-04 | 北京邮电大学 | Thesis subject irrelevant citation checking method and device |
| CN117828513A (en) * | 2024-03-04 | 2024-04-05 | 北京邮电大学 | A method and device for checking irrelevant citations in papers |
| CN118573418A (en) * | 2024-05-16 | 2024-08-30 | 中国人民解放军战略支援部队信息工程大学 | Attribute network abnormal node detection method and system based on iterative filtering |
| CN118573418B (en) * | 2024-05-16 | 2026-02-03 | 中国人民解放军网络空间部队信息工程大学 | Attribute network abnormal node detection method and system based on iterative filtering |
| CN119337377A (en) * | 2024-10-14 | 2025-01-21 | 浙江大学 | A phased anomaly detection approach for very large-scale industrial software supply chains |
| CN119337377B (en) * | 2024-10-14 | 2025-10-31 | 浙江大学 | A phased anomaly detection method for ultra-large-scale industrial software supply chains |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Liu et al. | Simple contrastive graph clustering | |
| Fu et al. | Learning semantic relationship among instances for image-text matching | |
| Zhu et al. | A survey on graph structure learning: Progress and opportunities | |
| CN112966127B (en) | Cross-modal retrieval method based on multilayer semantic alignment | |
| CN116128024A (en) | Multi-perspective comparative self-supervised attribute network outlier detection method | |
| Pan et al. | Low-rank tensor regularized graph fuzzy learning for multi-view data processing | |
| Li et al. | Network representation learning: a systematic literature review | |
| Yang et al. | Integrating fuzzy clustering and graph convolution network to accurately identify clusters from attributed graph | |
| Zhang et al. | Hierarchical graph pooling with structure learning | |
| Zhou et al. | M-evolve: structural-mapping-based data augmentation for graph classification | |
| Zhang et al. | Enhanced semantic similarity learning framework for image-text matching | |
| Wang et al. | Integrated heterogeneous graph attention network for incomplete multi-modal clustering | |
| Jin et al. | Deepwalk-aware graph convolutional networks | |
| Zhang et al. | Multiview graph restricted Boltzmann machines | |
| Xue et al. | Architecture knowledge distillation for evolutionary generative adversarial network | |
| Sun et al. | Applying hybrid graph neural networks to strengthen credit risk analysis | |
| Wang et al. | A hybrid CNN based on global reasoning for hyperspectral image classification | |
| Tong et al. | Representation learning using attention network and CNN for heterogeneous networks | |
| Wang et al. | Generative partial multi-view clustering | |
| Fei et al. | Deep multi-view contrastive clustering via graph structure awareness | |
| Zulfiqar et al. | Synthetic image generation using deep learning: A systematic literature review | |
| Yang et al. | Graph contrastive learning for clustering of multi-layer networks | |
| Lin et al. | Echoea: Echo information between entities and relations for entity alignment | |
| Li et al. | Efficient community detection in heterogeneous social networks | |
| Gao et al. | CommGNAS: unsupervised graph neural architecture search for community detection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |