CN115292051B - Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) - Google Patents
Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) Download PDFInfo
- Publication number
- CN115292051B CN115292051B CN202211169473.5A CN202211169473A CN115292051B CN 115292051 B CN115292051 B CN 115292051B CN 202211169473 A CN202211169473 A CN 202211169473A CN 115292051 B CN115292051 B CN 115292051B
- Authority
- CN
- China
- Prior art keywords
- migration
- pod
- receiving
- gpu
- index
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5011—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals
- G06F9/5016—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals the resource being the memory
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本申请提出了一种GPU资源POD的热迁移方法、装置及应用,包括以下步骤:GPU客户端发送迁移请求;迁移POD中的迁移组件在收到所述迁移请求后,将所述元数据缓存索引发送给接收POD的迁移接收组件;迁移POD中的迁移组件在收到所述迁移请求后,将高频内存块与低频内存块传输到迁移接收组件中;GPU服务端收到迁移请求后,对任务优先级进行调整;接收POD对接收文件进行哈希校验,并与所述GPU服务端确认GPU的稳定性。本方案通过解决GPU容器镜像传输问题、做到CPU状态快速拷贝、保持GPU任务调度这三者,达到算法容器云GPU资源POD的快速热迁移的目的。

This application proposes a method, device and application for hot migration of a GPU resource POD, including the following steps: the GPU client sends a migration request; the migration component in the migration POD caches the metadata after receiving the migration request The index is sent to the migration receiving component that receives the POD; after receiving the migration request, the migration component in the migration POD transmits the high-frequency memory block and the low-frequency memory block to the migration receiving component; after the GPU server receives the migration request, Adjust the priority of the task; the receiving POD performs a hash check on the received file, and confirms the stability of the GPU with the GPU server. This solution solves the problem of GPU container image transmission, achieves fast copying of CPU status, and maintains GPU task scheduling, so as to achieve the purpose of fast hot migration of GPU resource POD in the algorithm container cloud.
Description
技术领域technical field
本申请涉及算法容器云平台技术领域,特别是涉及一种GPU资源容器的热迁移方法、装置及应用。The present application relates to the technical field of algorithm container cloud platform, in particular to a method, device and application for hot migration of GPU resource containers.
背景技术Background technique
随着云计算技术的发展,凭借着标准化运行环境、快速部署运维、按需灵活分配等优点,Docker和Kubernetes技术已经成为众多企业应用交付的标准。同时随着GPU的通用化,深度学习领域对GPU的使用日益增长,结合两者的算法容器云应运而生,其能快速提供GPU资源,做到标准化算法应用的交付,在图形图像渲染以及并行计算、人工智能领域都发挥了重要的作用。With the development of cloud computing technology, with the advantages of standardized operating environment, rapid deployment and operation and maintenance, and flexible allocation on demand, Docker and Kubernetes technologies have become the standards for many enterprise application delivery. At the same time, with the generalization of GPUs, the use of GPUs in the field of deep learning is increasing. The algorithm container cloud that combines the two emerges as the times require. It can quickly provide GPU resources, achieve the delivery of standardized algorithm applications, and perform in graphics and image rendering and parallelism. Both computing and artificial intelligence have played an important role.
而深度学习领域的算法运算往往具有任务复杂,耗时长的特点,在涉及到POD(即容器组)因资源调整、工作优先级调整或者故障等原因需要调度调整时,运行状态的重置会导致算法运算的中断,导致算法的计算过程功亏一篑,同时因为容器的状态无法保持的原因,无法做到算法容器的灵活调度搭配,降低了容器云平台的利用率。Algorithmic operations in the field of deep learning often have the characteristics of complex tasks and long time-consuming. When PODs (container groups) need to be scheduled and adjusted due to resource adjustments, work priority adjustments, or failures, the reset of the running status will lead to The interruption of the algorithm operation leads to the failure of the calculation process of the algorithm. At the same time, because the state of the container cannot be maintained, the flexible scheduling and collocation of the algorithm container cannot be achieved, which reduces the utilization rate of the container cloud platform.
在算法容器云集群中,Pod是所有业务类型的基础,它是一个或多个容器的组合,对于具体的应用而言,Pod是它们的逻辑主机,Pod包含业务相关的多个算法容器,容器与云主机不同,容器是基于进程的,并不能像kvm云主机一样很容易地进行分离热迁移,在原生的Kubernetes容器云平台中,往往是通过yaml配置文件启动新的Pod并销毁旧的POD的形式完成迁移,对于新生成的Pod来说,往往是不具备原先的运行状态。In the algorithm container cloud cluster, Pod is the foundation of all business types. It is a combination of one or more containers. For specific applications, Pod is their logical host. Pod contains multiple algorithm containers related to business. Unlike cloud hosts, containers are process-based and cannot be separated and hot-migrated as easily as kvm cloud hosts. In the native Kubernetes container cloud platform, new pods are often started and old pods are destroyed through yaml configuration files The form of migration is completed, and for the newly generated Pod, it often does not have the original running state.
而在一些开源项目中,存在着通过CRIU(即Checkpoint/Restore In Userspace)来热迁移CPU的方式:对旧容器做检查点操作,然后停止容器,传输镜像文件至目的主机后恢复容器状态,现有技术相关的研究目光聚焦在如何做内存CPU的状态保持和恢复,存在着压缩内存页优化网络传输,减少重复拷贝的各类CPU优化方式,但是这些方案只适用于CPU资源容器。In some open source projects, there is a way to live migrate the CPU through CRIU (Checkpoint/Restore In Userspace): checkpoint the old container, stop the container, transfer the image file to the destination host, and restore the container state. Technology-related research focuses on how to maintain and restore the state of the memory CPU. There are various CPU optimization methods that compress memory pages to optimize network transmission and reduce duplicate copies, but these solutions are only applicable to CPU resource containers.
在CPU容器迁移方法中也存在着镜像的优化方案,一种为预先加载,在集群的每个服务器上都预先加载镜像,从而减少镜像传输的时间,另一种是依据容器镜像的overlay分层原理,通过分层判断镜像仓库与本地的区别,减少重复overlay的传输。In the CPU container migration method, there is also an image optimization scheme. One is preloading, which preloads the image on each server in the cluster, thereby reducing the time for image transmission. The other is based on the overlay layering of the container image. The principle is to judge the difference between the mirror warehouse and the local by layering, and reduce the transmission of repeated overlays.
CPU即中央处理器,为计算机系统的运算和控制核心,有25%的ALU(运算单元)、25%的Control(控制单元)、50%的Cache(缓存单元),GPU即图形处理器,具有90%的ALU(运算单元)、5%的Control(控制单元)、5%的Cache(缓存单元)。由于CPU资源容器与GPU资源容器是存在着极大的不同的,故导致目前市面上适用于CPU资源容器的热迁移方法无法直接适用于GPU资源容器,换言之,以上提及的这两种CPU方案都不适用于GPU容器,因为GPU容器镜像的大体积,预先加载是对于资源的极大浪费,而有些容器配置选项设置为imagePullPolicy: Always(即仍旧拉取镜像),预先加载并不能发生作用,而且也无法解决UpperDir(最上一层)的同步,而第二种overlay的分层,在大基数的情况下,减少个别重复层意义并不是特别大,也存在UpperDir的同步问题。The CPU is the central processing unit, which is the computing and control core of the computer system. There are 25% of the ALU (computing unit), 25% of the Control (control unit), and 50% of the Cache (caching unit). The GPU is the graphics processing unit. 90% of the ALU (computing unit), 5% of the Control (control unit), 5% of the Cache (cache unit). Due to the great difference between the CPU resource container and the GPU resource container, the hot migration method applicable to the CPU resource container currently on the market cannot be directly applied to the GPU resource container. In other words, the two CPU solutions mentioned above None of them are applicable to GPU containers, because of the large size of GPU container images, preloading is a great waste of resources, and some container configuration options are set to imagePullPolicy: Always (that is, the image is still pulled), preloading does not work, Moreover, the synchronization of UpperDir (the uppermost layer) cannot be solved, and the layering of the second overlay, in the case of a large base, is not particularly meaningful to reduce individual repeated layers, and there is also a synchronization problem of UpperDir.
具体而言,GPU容器的镜像大小要远远大于一般镜像,以深度学习中的tensorflow镜像为例,其在dockerhub上的官方镜像大小为3.2G,同比CPU常用镜像Centos只有234M,前者是后者的14倍,而且这只是POD中一个容器的原生镜像,考虑到算法容器组CPU、GPU资源的调用,状态记录等操作,其传输容量远胜于纯CPU容器,若按照一般的镜像传输方案,容器组的延迟中断将会是分钟级,甚至是小时级,在生产环境中是不可接受的。Specifically, the image size of a GPU container is much larger than that of a general image. Taking the tensorflow image in deep learning as an example, its official image size on dockerhub is 3.2G, compared with the CPU common image Centos is only 234M, the former is the latter 14 times that of a container, and this is only a native image of a container in the POD. Considering the operations of CPU and GPU resource calls and status records of the algorithm container group, its transmission capacity is far greater than that of pure CPU containers. If the general image transmission scheme is used, The delay interruption of the container group will be at the level of minutes or even hours, which is unacceptable in a production environment.
同时,GPU容器除了需要考虑到CPU状态,还需要考虑到GPU状态,而在算法云平台中,一个Pod往往含有多种算法,分别部署在各自容器内,组成一个算法集群的Pod,同时因为GPU资源的高昂费用,一块GPU往往共享给不同的算法组使用,其复杂度使得当前CPU资源的POD热迁移方案并不能平移到GPU资源POD使用。At the same time, the GPU container needs to consider not only the CPU state, but also the GPU state. In the algorithm cloud platform, a Pod often contains multiple algorithms, which are deployed in their respective containers to form Pods of an algorithm cluster. At the same time, because the GPU Due to the high cost of resources, a GPU is often shared by different algorithm groups, and its complexity prevents the current POD hot migration solution for CPU resources from being translated to GPU resource PODs.
综上所述,目前针对CPU的热迁移方案并不适用于GPU资源容器,目前CPU的热迁移方案用于GPU资源容器时具有GPU容器镜像文件的传输问题、CPU状态快速拷贝、保持GPU任务调度这三方面的问题。To sum up, the current CPU hot migration solution is not suitable for GPU resource containers. The current CPU hot migration solution used in GPU resource containers has problems with the transfer of GPU container image files, fast copy of CPU status, and maintenance of GPU task scheduling. these three issues.
发明内容Contents of the invention
本申请实施例提供了一种GPU资源POD的热迁移方法、装置及应用,解决了GPU容器镜像传输问题、做到CPU状态快速拷贝、保持GPU任务调度,实现算法容器云GPU资源POD的快速热迁移。The embodiment of the present application provides a method, device and application for thermal migration of GPU resource POD, which solves the problem of GPU container image transmission, achieves fast copying of CPU status, maintains GPU task scheduling, and realizes rapid thermal migration of algorithm container cloud GPU resource POD. migrate.
第一方面,本申请实施例提供了一种GPU资源POD的热迁移放方法,所述方法包括:In the first aspect, an embodiment of the present application provides a method for hot migration and release of a GPU resource POD. The method includes:
GPU客户端向需要进行热迁移的迁移POD和GPU服务端发送迁移请求,算法容器云平台的控制服务器通过所述迁移请求确认接收POD;The GPU client sends a migration request to the migrating POD and the GPU server that need to be hot-migrated, and the control server of the algorithm container cloud platform confirms receiving the POD through the migration request;
所述迁移POD中的迁移组件在收到所述迁移请求后,对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据索引缓存,将所述元数据缓存索引接收POD的迁移接收组件,所述接收POD的迁移接收组件根据所述元数据缓存索引在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的数据放入所述文件系统中;After receiving the migration request, the migration component in the migration POD checks the metadata tree index of the image file in the migration POD to obtain a metadata index cache, and receives the metadata cache index from the POD Migration receiving component, the migration receiving component receiving the POD establishes a file system in the receiving POD according to the metadata cache index, and puts the data corresponding to the metadata cache index into the file system;
收集迁移POD中的进程树信息,并在所述进程树信息的每一进程中添加寻址代码,所述寻址代码在对应的进程对内存进行调用时被拷贝到对应的内存的地址空间并实时记录每一内存的变化频次,根据所述变化频次将内存分为高频内存块和低频内存块,将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中。Collect the process tree information in the migration POD, and add addressing code in each process of the process tree information, the addressing code is copied to the address space of the corresponding memory when the corresponding process calls the memory and Record the change frequency of each memory in real time, divide the memory into a high-frequency memory block and a low-frequency memory block according to the change frequency, and transmit the high-frequency memory block and the low-frequency memory block as a memory state file to the migration receiver in the component.
第二方面,本申请实施例提供了一种GPU资源POD的热迁移装置,包括:In the second aspect, the embodiment of the present application provides a GPU resource POD hot migration device, including:
请求模块:GPU客户端向需要进行热迁移的迁移POD和GPU服务端发送迁移请求,算法容器云平台的控制服务器通过所述迁移请求确认接收POD;Request module: the GPU client sends a migration request to the migrating POD and the GPU server that need to be hot-migrated, and the control server of the algorithm container cloud platform confirms receiving the POD through the migration request;
文件迁移模块:所述迁移POD中的迁移组件在收到所述迁移请求后,对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据索引缓存,将所述元数据缓存索引接收POD的迁移接收组件,所述接收POD的迁移接收组件根据所述元数据缓存索引在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的数据放入所述文件系统中;File migration module: after receiving the migration request, the migration component in the migration POD checks the metadata tree index of the mirror file in the migration POD to obtain a metadata index cache, and caches the metadata The migration receiving component of the index receiving POD, the migration receiving component of receiving the POD establishes a file system in the receiving POD according to the metadata cache index, and puts the data corresponding to the metadata cache index into the file in the system;
内存迁移模块:收集迁移POD中的进程树信息,并在所述进程树信息的每一进程中添加寻址代码,所述寻址代码在对应的进程对内存进行调用时被拷贝到对应的内存的地址空间并实时记录每一内存的变化频次,根据所述变化频次将内存分为高频内存块和低频内存块,将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中。Memory migration module: collect the process tree information in the migration POD, and add addressing code in each process of the process tree information, and the addressing code is copied to the corresponding memory when the corresponding process calls the memory address space and record the change frequency of each memory in real time, divide the memory into high-frequency memory block and low-frequency memory block according to the change frequency, and transfer the high-frequency memory block and the low-frequency memory block as memory state files to In the migration receiving component.
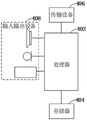
第三方面,本申请实施例提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行一种GPU资源POD的热迁移方法。In a third aspect, the embodiment of the present application provides an electronic device, including a memory and a processor, the memory stores a computer program, and the processor is configured to run the computer program to execute a GPU resource POD. Thermal migration method.
第四方面,本申请实施例提供了一种可读存储介质,所述可读存储介质中存储有计算机程序,所述计算机程序包括用于控制过程以执行过程的程序代码,所述过程包括一种GPU资源POD的热迁移方法。In a fourth aspect, an embodiment of the present application provides a readable storage medium, where a computer program is stored in the readable storage medium, and the computer program includes a program code for controlling a process to execute the process, and the process includes a A hot migration method for GPU resource PODs.
本发明的主要贡献和创新点如下:Main contribution and innovation of the present invention are as follows:
本申请实施例引入元数据和数据的概念,根据元数据将存储层切割为固定大小的块,生成扁平化的元数据树状图索引,接收容器并不需要像传统容器一样在所有镜像文件下载后再能启动,它可以根据元数据树状图索引通过网络调用迁移POD的镜像文件系统,并在调用后缓存。在后台对迁移POD的完整镜像文件进行下载,当完整镜像文件下载完成后替换掉元数据树状图索引,省略了大体积镜像网络传输的时间,以此解决了GPU容器镜像传输的问题。The embodiment of this application introduces the concepts of metadata and data, and cuts the storage layer into fixed-size blocks according to the metadata to generate a flattened metadata tree index. The receiving container does not need to be downloaded in all image files like traditional containers. After it can be started again, it can migrate the mirror file system of the POD through the network call according to the metadata tree index, and cache it after the call. Download the complete image file of the migrated POD in the background. When the complete image file is downloaded, the metadata tree index is replaced, which saves the time for network transmission of large-volume images, thereby solving the problem of GPU container image transmission.
本申请实施例通过细分内存块,为每块内存确认哈希值,在一定的频率将内存区分高频内存块和低频内存快,先传输低频内存块,再传输高频内存块,对低频内存块做内存的合并压缩,当高频内存块的频率降低后以低频内存块的形式进行传输,或在时间步长后进行传输,做到降低传输开销,增强内存的稳定,以此达到了GPU状态快速拷贝的效果;In the embodiment of the present application, the hash value is confirmed for each memory block by subdividing the memory blocks, and the memory is divided into high-frequency memory blocks and low-frequency memory blocks at a certain frequency. The low-frequency memory block is transmitted first, and then the high-frequency memory block is transmitted. The memory blocks are merged and compressed. When the frequency of the high-frequency memory block is reduced, it is transmitted in the form of a low-frequency memory block, or after a time step, so as to reduce the transmission overhead and enhance the stability of the memory. The effect of fast copy of GPU state;
本申请实施例将迁移POD对于GPU资源Pod的迁移请求通过GPU客户端发送给GPU服务端,由GPU服务端返回迁移结构,将负载的GPU状态改为仅需在GPU服务端上保持GPU状态,并重新链接到接收POD,降低了CPU与GPU的耦合,以此实现GPU的状态保持。In the embodiment of this application, the migration request of the migration POD for the GPU resource Pod is sent to the GPU server through the GPU client, and the GPU server returns the migration structure, and the GPU state of the load is changed to only need to maintain the GPU state on the GPU server. And re-link to the receiving POD, reducing the coupling between CPU and GPU, so as to realize the state maintenance of GPU.
本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。The details of one or more embodiments of the application are set forth in the accompanying drawings and the description below, so as to make other features, objects, and advantages of the application more comprehensible.
附图说明Description of drawings
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:The drawings described here are used to provide a further understanding of the application and constitute a part of the application. The schematic embodiments and descriptions of the application are used to explain the application and do not constitute an improper limitation to the application. In the attached picture:
图1是根据本申请实施例的一种GPU资源POD的热迁移方法的流程图;FIG. 1 is a flow chart of a method for hot migration of a GPU resource POD according to an embodiment of the present application;
图2是根据本申请实施例的一种GPU资源POD的热迁移装置的结构框图;FIG. 2 is a structural block diagram of a thermal migration device for a GPU resource POD according to an embodiment of the present application;
图3是根据本申请实施例的电子装置的硬件结构示意图。FIG. 3 is a schematic diagram of a hardware structure of an electronic device according to an embodiment of the present application.
具体实施方式detailed description
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本说明书一个或多个实施例相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本说明书一个或多个实施例的一些方面相一致的装置和方法的例子。Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. Implementations described in the following exemplary embodiments do not represent all implementations consistent with one or more embodiments of this specification. Rather, they are merely examples of apparatuses and methods consistent with aspects of one or more embodiments of the present specification as recited in the appended claims.
需要说明的是:在其他实施例中并不一定按照本说明书示出和描述的顺序来执行相应方法的步骤。在一些其他实施例中,其方法所包括的步骤可以比本说明书所描述的更多或更少。此外,本说明书中所描述的单个步骤,在其他实施例中可能被分解为多个步骤进行描述;而本说明书中所描述的多个步骤,在其他实施例中也可能被合并为单个步骤进行描述。It should be noted that in other embodiments, the steps of the corresponding methods are not necessarily performed in the order shown and described in this specification. In some other embodiments, the method may include more or less steps than those described in this specification. In addition, a single step described in this specification may be decomposed into multiple steps for description in other embodiments; multiple steps described in this specification may also be combined into a single step in other embodiments describe.
为了更好的理解本方案的技术点,在此对本方案中出现的名词加以解释:In order to better understand the technical points of this solution, here is an explanation of the nouns that appear in this solution:
边车容器(sidecar容器):sidecar容器是应于吊舱中的主容器一起运行的容器,这种边车容器在不更改它的情况下扩展并增强了当前容器的功能。如今,我们知道我们使用容器技术来包装所有依赖项,以便应用程序可以在任何地方运行。所述边车容器可以在不触摸或更改主容器的情况下向当前容器添加一些功能。Sidecar container (sidecar container): A sidecar container is a container that should run alongside the main container in a pod, this sidecar container extends and enhances the functionality of the current container without changing it. Today, we know that we use container technology to wrap all dependencies so that applications can run anywhere. Said sidecar container can add some functionality to the current container without touching or changing the main container.
镜像文件:POD中的主要资源内容存放在POD的镜像文件中,镜像文件需要通过POD进行运行。Image file: The main resource content in the POD is stored in the image file of the POD, and the image file needs to be run through the POD.
时间步长:时间步长指前后两个时间点之间的差,在本方案中,为设定的一个时间差,当设定时间差内高频内存块的内存频率没有降低到一定程度,则对高频内存块直接进行传输。Time step: Time step refers to the difference between two time points before and after. In this solution, it is a set time difference. When the memory frequency of the high-frequency memory block does not decrease to a certain extent within the set time difference, the High-frequency memory blocks are transferred directly.
实施例一Embodiment one
本申请实施例提供了一种GPU资源POD的热迁移方法,解决了GPU容器镜像传输问题、做到CPU状态快速拷贝、保持GPU任务调度,实现算法容器云GPU资源POD的快速热迁移,具体地,参考图1,所述方法包括:The embodiment of this application provides a method for hot migration of GPU resource POD, which solves the problem of GPU container image transmission, achieves fast copying of CPU status, maintains GPU task scheduling, and realizes fast hot migration of algorithm container cloud GPU resource POD, specifically , with reference to Figure 1, the method includes:
GPU客户端向需要进行热迁移的迁移POD和GPU服务端发送迁移请求,算法容器云平台的控制服务器通过所述迁移请求确认接收POD;The GPU client sends a migration request to the migrating POD and the GPU server that need to be hot-migrated, and the control server of the algorithm container cloud platform confirms receiving the POD through the migration request;
所述迁移POD中的迁移组件在收到所述迁移请求后,对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据索引缓存,将所述元数据缓存索引接收POD的迁移接收组件,所述接收POD的迁移接收组件根据所述元数据缓存索引在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的数据放入所述文件系统中;After receiving the migration request, the migration component in the migration POD checks the metadata tree index of the image file in the migration POD to obtain a metadata index cache, and receives the metadata cache index from the POD Migration receiving component, the migration receiving component receiving the POD establishes a file system in the receiving POD according to the metadata cache index, and puts the data corresponding to the metadata cache index into the file system;
收集迁移POD中的进程树信息,并在所述进程树信息的每一进程中添加寻址代码,所述寻址代码在对应的进程对内存进行调用时被拷贝到对应的内存的地址空间并实时记录每一内存的变化频次,根据所述变化频次将内存分为高频内存块和低频内存块,将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中。Collect the process tree information in the migration POD, and add addressing code in each process of the process tree information, the addressing code is copied to the address space of the corresponding memory when the corresponding process calls the memory and Record the change frequency of each memory in real time, divide the memory into a high-frequency memory block and a low-frequency memory block according to the change frequency, and transmit the high-frequency memory block and the low-frequency memory block as a memory state file to the migration receiver in the component.
在一些实施例中,在“算法容器云平台的控制服务器通过所述迁移请求确认接收POD”步骤中,所述控制服务器根据所述迁移请求的指向参数来确认接收POD,若所述迁移请求的指向参数为空,则根据资源和网络拓扑自动分配最适宜的服务器节点作为接收POD。In some embodiments, in the step of "the control server of the algorithm container cloud platform confirms receiving the POD through the migration request", the control server confirms receiving the POD according to the pointing parameter of the migration request, if the migration request If the pointing parameter is empty, the most suitable server node will be automatically allocated as the receiving POD according to the resources and network topology.
具体的,所述控制服务器对所述迁移请求中的参数进行分析,查看是否包含接收POD的指向参数,若所述迁移请求中含有接收POD的指向参数,则通过所述控制服务器所在的容器云平台来确认所述接收POD的资源余量,若资源余量满足迁移条件则确定所述接收POD,若所述资源余量不满足迁移条件,则迁移请求失败,返回失败结果。Specifically, the control server analyzes the parameters in the migration request to check whether it contains the pointing parameters of the receiving POD. The platform confirms the resource balance of the receiving POD. If the resource balance satisfies the migration condition, the receiving POD is determined. If the resource balance does not meet the migration condition, the migration request fails and a failure result is returned.
具体的,当所述迁移请求的指向参数为空时,则认为用户需要对迁移POD进行迁移,但不指定接收POD,则通过所述容器云平台的extend schedule(延长时间表)来根据POD的资源量、网络拓扑来寻找最合适的接收POD。Specifically, when the pointing parameter of the migration request is empty, it is considered that the user needs to migrate the migration POD, but does not specify to receive the POD. The amount of resources and network topology to find the most suitable receiving POD.
进一步的,所述容器云平台中POD的资源量和资源余量可以通过etcd(分布式注册服务中心)来确认。Further, the resource amount and resource balance of the POD in the container cloud platform can be confirmed through etcd (distributed registration service center).
在一些实施例中,由于接收POD的资源量与所述容器云平台中记录的接收POD资源余量并不是实时同步的,故当确认接收POD后,向所述接收POD的kubelet(控制组件)中发送确认请求,再一次确认所述接收POD中的资源余量是否满足迁移条件。In some embodiments, since the resource amount of the receiving POD is not synchronized with the resource balance of the receiving POD recorded in the container cloud platform in real time, after confirming the receiving of the POD, the kubelet (control component) of the receiving POD Send a confirmation request to confirm again whether the resource balance in the received POD meets the migration condition.
也就是说,在“所述算法容器云平台的控制服务器通过所述迁移请求确认接收POD”步骤之后包括步骤:向所述接收pod的控制组件发送确认请求,所述确认请求的内容为:确认所述接收pod的资源余量是否满足迁移条件。That is to say, after the step of "the control server of the algorithm container cloud platform confirms receiving the POD through the migration request", a step is included: sending a confirmation request to the control component of the receiving pod, the content of the confirmation request is: confirmation Whether the resource margin of the receiving pod satisfies the migration condition.
在一些实施例中,“所述迁移POD中的迁移组件在收到所述迁移请求”步骤中,所述迁移POD的迁移组件加入到所述算法容器云平台中获取所述迁移请求。In some embodiments, in the step of "the migration component in the migration POD receives the migration request", the migration component of the migration POD joins in the algorithm container cloud platform to obtain the migration request.
在一些实施例中,在“对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据缓存索引”步骤中,所述迁移POD中的边车容器对所述迁移POD中镜像文件的元数据树状图索引进行检索得到元数据索引缓存。In some embodiments, in the step of "checking the metadata tree index of the image file in the migration POD to obtain the metadata cache index", the sidecar container in the migration POD updates the image file in the migration POD The metadata tree index of the file is retrieved to obtain the metadata index cache.
具体的,所述边车容器检索所述元数据树状图中被使用的数据块,并基于所述数据块所在的数据库生成所述元数据索引。Specifically, the sidecar container retrieves the used data blocks in the metadata tree, and generates the metadata index based on the database where the data blocks are located.
所述元数据树状图索引是根据所述镜像文件中的数据生成的树状图索引,所述元数据索引缓存为所述元数据树状图索引中被使用了的数据切片所对应的树状图索引。The metadata dendrogram index is a dendrogram index generated according to the data in the image file, and the metadata index cache is the tree corresponding to the used data slice in the metadata dendrogram index Chart index.
具体的,将所述迁移POD中镜像文件中的数据分为固定大小的切片,这些数据切片保存在数据层中,根据所述数据层中的数据切片并生成对应的元数据树状图索引,对所述元数据树状图索引进行检索,检索所述元数据树状图索引中被使用了数据切片,并根据这些数据切片生成一个元数据缓存索引,并将所述元数据缓存索引对应的数据切片发送到所述接收POD的文件系统中。Specifically, the data in the mirror file in the migration POD is divided into fixed-size slices, and these data slices are stored in the data layer, and the corresponding metadata dendrogram index is generated according to the data slices in the data layer, Retrieving the metadata dendrogram index, retrieving data slices used in the metadata dendrogram index, and generating a metadata cache index based on these data slices, and storing the metadata cache index corresponding to The data slices are sent to the file system of the receiving POD.
具体的,所述元数据树状图索引是自校验的哈希树,使用自校验的哈希树作为所述元数据树状图索引可以通过哈希校验的方式避免镜像传输过程中,所述文件系统与所述镜像文件的内容不一致的问题;另外,通过索引的方式进行传输,做到了镜像文件的快速传输,不需要等待大体积镜像的分钟级甚至小时级整体传输,且索引的存在也避免了因网络闪断或中断的网络影响导致所述镜像文件与所述文件系统中的内容不一致的情况,从而完成GPU镜像文件的快速传输。Specifically, the metadata dendrogram index is a self-verifying hash tree, and using the self-verifying hash tree as the metadata dendrogram index can avoid , the content of the file system is inconsistent with the content of the image file; in addition, the transmission is carried out by indexing, so that the rapid transmission of the image file is achieved, and there is no need to wait for the minute-level or even hour-level overall transmission of the large-volume image, and the index The existence of the network also avoids the situation that the image file is inconsistent with the content in the file system due to the impact of network interruption or interruption, thereby completing the rapid transmission of the GPU image file.
在一些实施例中,在“所述接收POD的迁移接收组件根据所述元数据树状索引和所述元数据缓存索引创建在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的元数据放入所述文件系统中”步骤中,所述接收POD对所述文件系统进行使用时先通过所述元数据缓存索引使用其对应的数据切片,当需要用到除了所述元数据缓存索引所对应的数据切片之外的数据切片时,通过所述元数据树状图索引以网络调用的形式调用所述迁移POD的镜像文件中的数据切片进行使用。In some embodiments, in "the migration receiving component of the receiving POD creates a file system in the receiving POD according to the metadata tree index and the metadata cache index, and stores the metadata cache index Put the corresponding metadata into the file system" step, when the receiving POD uses the file system, it first uses the corresponding data slice through the metadata cache index, when it needs to use the For data slices other than the data slices corresponding to the metadata cache index, the data slices in the image file of the migrated POD are invoked for use through the metadata dendrogram index in the form of network calls.
在一些实施例中,在“将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中”步骤中,将所述低频内存块进行压缩、合并后作为内存状态文件传输到所述迁移接收组件中,当所述高频内存块的变化频次降低到所述低频内存块的变化频次时,将其看做低频内存块进行压缩、合并后作为内存状态文件传输到所述迁移接收组件中,或在设定的时间步长后将所述高频内存块直接传输到所述迁移接收组件中。In some embodiments, in the step of "transmitting the high-frequency memory block and the low-frequency memory block to the migration receiving component as a memory state file", the low-frequency memory block is compressed and combined as a memory The state file is transmitted to the migration receiving component, and when the change frequency of the high-frequency memory block is reduced to the change frequency of the low-frequency memory block, it is regarded as a low-frequency memory block, compressed, merged and transmitted as a memory state file to the migration receiving component, or directly transfer the high-frequency memory block to the migration receiving component after a set time step.
具体的,为了更高的展示所述高频内存块和所述低频内存块变化频次的变化,将所述高频内存块与所述低频内存块的频次变化使用哈希值进行表示。Specifically, in order to display the change frequency of the high-frequency memory block and the low-frequency memory block higher, the frequency change of the high-frequency memory block and the low-frequency memory block is represented by a hash value.
在设定的时间步长后将所述高频内存块直接传输到所述迁移接收组件中指的是:若在设定时间时长后高频内存块的变化频次依旧没有转变为低频内存块,为了保证内存信息传输的完整性,依旧是需要将高频内存块直接传输给所述迁移接收组件。Directly transmitting the high-frequency memory block to the migration receiving component after the set time step means: if the change frequency of the high-frequency memory block is still not changed to a low-frequency memory block after a set time period, in order To ensure the integrity of memory information transmission, it is still necessary to directly transmit high-frequency memory blocks to the migration receiving component.
进一步的,所述迁移接收组件对所述高频内存块和所述低频内存块进行合并,解析所述高频内存块和低频内存块中的资源,并根据所述高频内存块和所述低频内存块的资源在所述接收POD中递归地生成进程树,准备命名空间,在所述命名空间中将所述高频内存块和所述低频内存块的资源进行填充,并创建套接字。Further, the migration receiving component merges the high-frequency memory block and the low-frequency memory block, analyzes the resources in the high-frequency memory block and the low-frequency memory block, and The resources of the low-frequency memory block recursively generate a process tree in the receiving POD, prepare a namespace, fill the resources of the high-frequency memory block and the low-frequency memory block in the namespace, and create a socket .
具体的,所述套接字是一种网络编程接口,在本方案中,通过套接字将所述接收POD与网络建立连接,网络与所述接收POD通过套接字进行交互。Specifically, the socket is a network programming interface. In this solution, the receiving POD is connected to the network through the socket, and the network and the receiving POD interact through the socket.
进一步的,在接收POD中完成资源的填充后取消迁移阶段的内存映射,清除所述高频内存块与所述低频内存块中的寻址代码。Further, after the resources are filled in the received POD, the memory mapping in the migration stage is canceled, and the addressing codes in the high-frequency memory block and the low-frequency memory block are cleared.
具体的,通过对内存块变化频次的判断,将内存块区分高频、低频,并对所述低频内存块进行压缩、合并后传输,对所述高频内存块进行整理,等到所述高频次内存块的变化频次变低后传输或者在时间步长后对所述高频内存块进行传输,合理的降低了传输开销,增强了内存传输的稳定性,做到了内存状态的快速拷贝。Specifically, by judging the change frequency of the memory block, the memory block is divided into high-frequency and low-frequency, and the low-frequency memory block is compressed, combined and transmitted, and the high-frequency memory block is sorted, and the high-frequency memory block is waited until the high-frequency The frequency of change of the sub-memory block is reduced, or the high-frequency memory block is transmitted after the time step, which reasonably reduces the transmission overhead, enhances the stability of memory transmission, and achieves fast copying of the memory state.
在一些实施例中,当所述GPU服务端接收所述迁移请求后,对所述迁移POD的任务队列进行遍历,以迭代次数作为最小调度单元,对所述任务队列中的队伍进行输入输出分析和上下文切换,并对GPU内核进行前向调用,再后向的计算任务梯度的更新维度,确认任务队列中任务的优先级。In some embodiments, after the GPU server receives the migration request, it traverses the task queue of the migrated POD, uses the number of iterations as the minimum scheduling unit, and performs input and output analysis on the teams in the task queue And the context switch, and make a forward call to the GPU kernel, and then calculate the update dimension of the task gradient backward, and confirm the priority of the task in the task queue.
具体的,使用GPU服务端来接收迁移请求,是将CPU与GPU进行分离,降低了两者的耦合,将迁移POD的迁移请求通过客户端转发给服务端,由服务端返回GPU的计算结果,将复杂的GPU状态传递改为仅需在服务端保持GPU状态,重新链接迁移POD。Specifically, using the GPU server to receive the migration request is to separate the CPU from the GPU, reducing the coupling between the two, forwarding the migration request of the POD migration to the server through the client, and the server returns the calculation result of the GPU. Change the complex GPU state transfer to only need to maintain the GPU state on the server side, and relink the migration POD.
进一步的,将输入输出操作多、上下文切换频繁,耗时长的任务作为低优先级任务调整至队列前端来优先执行,以便迁移过程中发生阻塞,在迁移完成进行任务恢复时,将高优任务优先执行,提高正常运作时GPU的利用率。Further, tasks with many input and output operations, frequent context switching, and time-consuming tasks are adjusted to the front of the queue as low-priority tasks for priority execution, so that blocking occurs during the migration process, and high-priority tasks are given priority when the migration is completed and the task is restored. Implemented to improve GPU utilization during normal operation.
具体的,为了使得GPU的运行保持相对平稳的状态,便于与新容器节点的对接,可以人为制造任务,将所述人为制造任务插入队列以冻结GPU进程调度。Specifically, in order to keep the running of the GPU in a relatively stable state and to facilitate docking with new container nodes, tasks can be artificially created, and the artificially created tasks can be inserted into a queue to freeze GPU process scheduling.
在一些实施例中,当所述文件系统中的数据和所述内存状态文件迁移完成后,对其进行哈希校验,当哈希校验通过后,发送通过请求给所述算法容器云平台的控制服务器,所述控制服务器通过API并结合所述算法云平台的网络代理组件和DNS服务,并与GPU服务端进行对接进行网络状态更替,并通知所述算法容器云平台销毁迁移POD。In some embodiments, after the migration of the data in the file system and the memory state file is completed, a hash check is performed on it, and when the hash check is passed, a pass request is sent to the algorithm container cloud platform The control server, the control server connects with the GPU server through the API and combines the network proxy component and DNS service of the algorithm cloud platform to perform network status replacement, and notifies the algorithm container cloud platform to destroy the migration POD.
进一步的,在进行哈希校验之前,所述文件系统中的数据应与所述迁移POD总完整的镜像文件相同。Further, before the hash verification is performed, the data in the file system should be the same as the complete image file of the migrated POD.
如上所述,本方案提供的一种GPU资源POD的热迁移方法相较现有技术,可以达到:As mentioned above, compared with the existing technology, a GPU resource POD hot migration method provided by this solution can achieve:
1.解决GPU容器镜像传输问题:1. Solve the problem of GPU container image transmission:
引入元数据和数据的概念,元数据即是对于数据的描述,具体来说,元数据层中的数据是自校验的哈希树,而数据层被分为固定大小的切片。所有的数据被切分为数据切片并保存在数据层,同时生成相应的元数据树状图索引。当GPU容器组开始热迁移时,对镜像文件的元数据树状图索引作检索,检索被使用的数据切片,根据这些被使用的数据切片生成一份元数据索引缓存。Introduce the concepts of metadata and data. Metadata is the description of data. Specifically, the data in the metadata layer is a self-verifying hash tree, and the data layer is divided into fixed-size slices. All data is divided into data slices and stored in the data layer, and corresponding metadata dendrogram indexes are generated at the same time. When the GPU container group starts live migration, the metadata tree index of the image file is retrieved, the used data slices are retrieved, and a metadata index cache is generated based on these used data slices.
将所述元数据索引缓存发送至接收POD上,所述接收POD根据扁平化的元数据树状图索引和所述元数据索引缓存在所述接收POD上创建文件系统,将所述元数据索引缓存对应的数据同步到所述文件系统中,所述接收POD对于文件系统中数据的使用先通过所述元数据索引缓存使用对应的数据,若需要使用除元数据索引缓存对应数据之外的数据,则通过所述元数据树状图索引以网络调用的形式对所述迁移POD中的镜像文件进行调用,另外元数据索引缓存的存在,规避了网络中断而需要重传的问题,另一方面,哈希的校验功能也避免了迁移POD镜像文件中的数据与所述接收POD文件系统中的数据不一致的问题,这样一方面做到了镜像文件以索引的形式进行快速传输,不需要等待大体积镜像的分钟级甚至小时级整体传输,另外元数据树状图索引的存在,也避免了因网络闪断或中断的网络影响导致的镜像文件与文件系统中的数据不一致的问题。Send the metadata index cache to the receiving POD, and the receiving POD creates a file system on the receiving POD according to the flattened metadata tree index and the metadata index cache, and stores the metadata index The data corresponding to the cache is synchronized to the file system, and the receiving POD first uses the corresponding data through the metadata index cache to use the data in the file system. If necessary, use data other than the data corresponding to the metadata index cache , the image file in the migration POD is called in the form of a network call through the metadata tree index, and the existence of the metadata index cache avoids the problem of network interruption and the need for retransmission. On the other hand , the verification function of the hash also avoids the problem that the data in the migrating POD image file is inconsistent with the data in the receiving POD file system. The minute-level or even hour-level overall transmission of the volume image, and the existence of the metadata tree index also avoid the problem of inconsistency between the image file and the data in the file system caused by the impact of network interruption or interruption.
2.CPU状态快速拷贝:2. Fast copy of CPU state:
内存状态拷贝:根据所述迁移POD进程的递归收集容器进程及其子进程构成的进程树信息,向所述迁移POD的进程中注入寻址代码,当容器进程调用内存映射的时候,所述寻址代码会被拷贝到对应的内存地址空间,记录随后的内存变化频次,根据内存变化频次区分高频内存块和低频内存块,并作哈希表示,对所述低频内存块进行压缩、合并,传输至接收POD的迁移接收组件中,对于所述高频内存块,一则在其调用频率下降后,转为低频内存块进行传输,或者在时间步长后传输至所述接收POD的迁移接收组件中。Memory state copy: According to the recursive collection of the process tree information formed by the container process and its sub-processes of the migration POD process, inject addressing code into the process of the migration POD, when the container process calls memory mapping, the addressing code The address code will be copied to the corresponding memory address space, record the frequency of subsequent memory changes, distinguish high-frequency memory blocks and low-frequency memory blocks according to the frequency of memory changes, and make a hash representation, compress and merge the low-frequency memory blocks, Transfer to the migration receiving component of the receiving POD. For the high-frequency memory block, after its calling frequency decreases, it will be transferred to a low-frequency memory block for transmission, or it will be transferred to the migration receiving component of the receiving POD after a time step. in the component.
内存状态的恢复:合并传输的高频内存块与低频内存块,解析进程中的资源,递归地生成需要恢复的进程树,准备命名空间,填充内存数据,创建套接字,取消拷贝阶段的内存映射,并清除注入的寻址代码,将所述高频内存块与所述低频内存快合并处理降低了传输开销,增强了内存传输的稳定性。Restoration of memory state: Merge transmitted high-frequency memory blocks and low-frequency memory blocks, analyze resources in the process, recursively generate process trees that need to be restored, prepare namespaces, fill memory data, create sockets, and cancel memory in the copy stage Mapping and clearing the injected addressing code, combining the high-frequency memory block with the low-frequency memory block reduces transmission overhead and enhances the stability of memory transmission.
3.GPU的状态保持3. GPU state maintenance
通过使用客户端发送迁移请求,使用服务端接收迁移请求的方式分离CPU与GPU,降低两者的耦合,分离POD与GPU。具体来说,将所述迁移POD对于GPU的迁移请求通过客户端转发给服务端,由服务端返回GPU计算的迁移结果。这种方式将复杂的GPU状态传递改为仅需在服务端上保持GPU状态,并重新链接接收POD。By using the client to send the migration request and the server to receive the migration request, the CPU and GPU are separated, the coupling between the two is reduced, and the POD and GPU are separated. Specifically, the migration request of the migrated POD to the GPU is forwarded to the server through the client, and the server returns a migration result calculated by the GPU. This method changes the complex GPU state transfer to only need to maintain the GPU state on the server and relink the receiving POD.
特别的,对于服务端上GPU 的运行状态做了以下优化,使其更适应于热迁移。以迭代次数作为调度的最小单位,区分GPU高优先级任务和低优先级任务,低优先级任务往往具备较多的输入输出和上下文切换,在迁移过程中通过调整任务优先级,将低优任务调至队列前端。同时可选择的,人为制造任务,插入队列以冻结GPU进程调度。低优先级任务的优先执行,使得GPU的运行保持相对平稳的状态,便于与接收POD的对接,在迁移完成进行任务恢复时,将高优任务优先执行,提高正常运作时GPU的利用率。In particular, the following optimizations have been made to the running state of the GPU on the server to make it more suitable for live migration. The number of iterations is used as the smallest unit of scheduling to distinguish GPU high-priority tasks from low-priority tasks. Low-priority tasks often have more input and output and context switching. During the migration process, by adjusting the task priority, the low-priority tasks Move to the front of the queue. At the same time, optional, artificially created tasks are inserted into the queue to freeze the GPU process scheduling. The priority execution of low-priority tasks keeps the GPU running in a relatively stable state, which is convenient for docking with the receiving POD. When the migration is completed and the task is restored, the high-priority tasks are prioritized to improve the utilization of the GPU during normal operation.
通过解决GPU容器镜像传输问题、做到CPU状态快速拷贝、GPU的状态保持这三者,达到GPU资源POD的快速热迁移的目的。秒级的热迁移对使用者来说基本上无感知,运行状态的保持对于任务链长、计算时间久的算法具有重大意义,使得算法容器能够实现灵活调度搭配,增强了算法容器平台的稳健性和资源利用效率。By solving the problem of GPU container image transmission, achieving fast copy of CPU state, and maintaining the state of GPU, the purpose of fast hot migration of GPU resource POD is achieved. Second-level hot migration is basically imperceptible to users, and the maintenance of running status is of great significance for algorithms with long task chains and long computing times, which enables the algorithm container to achieve flexible scheduling and collocation, and enhances the robustness of the algorithm container platform and resource utilization efficiency.
实施例二Embodiment two
基于相同的构思,参考图2,本申请还提出了一种GPU资源POD的热迁移装置,包括:Based on the same idea, referring to Figure 2, this application also proposes a thermal migration device for GPU resource POD, including:
请求模块:GPU客户端向需要进行热迁移的迁移POD和GPU服务端发送迁移请求,算法容器云平台的控制服务器通过所述迁移请求确认接收POD;Request module: the GPU client sends a migration request to the migrating POD and the GPU server that need to be hot-migrated, and the control server of the algorithm container cloud platform confirms receiving the POD through the migration request;
文件迁移模块:所述迁移POD中的迁移组件在收到所述迁移请求后,对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据索引缓存,将所述元数据缓存索引接收POD的迁移接收组件,所述接收POD的迁移接收组件根据所述元数据缓存索引在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的数据放入所述文件系统中;File migration module: after receiving the migration request, the migration component in the migration POD checks the metadata tree index of the mirror file in the migration POD to obtain a metadata index cache, and caches the metadata The migration receiving component of the index receiving POD, the migration receiving component of receiving the POD establishes a file system in the receiving POD according to the metadata cache index, and puts the data corresponding to the metadata cache index into the file in the system;
内存迁移模块:收集迁移POD中的进程树信息,并在所述进程树信息的每一进程中添加寻址代码,所述寻址代码在对应的进程对内存进行调用时被拷贝到对应的内存的地址空间并实时记录每一内存的变化频次,根据所述变化频次将内存分为高频内存块和低频内存块,将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中。Memory migration module: collect the process tree information in the migration POD, and add addressing code in each process of the process tree information, and the addressing code is copied to the corresponding memory when the corresponding process calls the memory address space and record the change frequency of each memory in real time, divide the memory into high-frequency memory block and low-frequency memory block according to the change frequency, and transfer the high-frequency memory block and the low-frequency memory block as memory state files to In the migration receiving component.
实施例三Embodiment Three
本实施例还提供了一种电子装置,参考图3,包括存储器404和处理器402,该存储器404中存储有计算机程序,该处理器402被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。This embodiment also provides an electronic device, referring to FIG. 3 , including a
具体地,上述处理器402可以包括中央处理器(CPU),或者特定集成电路(ApplicationSpecificIntegratedCircuit,简称为ASIC),或者可以被配置成实施本申请实施例的一个或多个集成电路。Specifically, the
其中,存储器404可以包括用于数据或指令的大容量存储器404。举例来说而非限制,存储器404可包括硬盘驱动器(HardDiskDrive,简称为HDD)、软盘驱动器、固态驱动器(SolidStateDrive,简称为SSD)、闪存、光盘、磁光盘、磁带或通用串行总线(UniversalSerialBus,简称为USB)驱动器或者两个或更多个以上这些的组合。在合适的情况下,存储器404可包括可移除或不可移除(或固定)的介质。在合适的情况下,存储器404可在数据处理装置的内部或外部。在特定实施例中,存储器404是非易失性(Non-Volatile)存储器。在特定实施例中,存储器404包括只读存储器(Read-OnlyMemory,简称为ROM)和随机存取存储器(RandomAccessMemory,简称为RAM)。在合适的情况下,该ROM可以是掩模编程的ROM、可编程ROM(ProgrammableRead-OnlyMemory,简称为PROM)、可擦除PROM(ErasableProgrammableRead-OnlyMemory,简称为EPROM)、电可擦除PROM(ElectricallyErasableProgrammableRead-OnlyMemory,简称为EEPROM)、电可改写ROM(ElectricallyAlterableRead-OnlyMemory,简称为EAROM)或闪存(FLASH)或者两个或更多个以上这些的组合。在合适的情况下,该RAM可以是静态随机存取存储器(StaticRandom-AccessMemory,简称为SRAM)或动态随机存取存储器(DynamicRandomAccessMemory,简称为DRAM),其中,DRAM可以是快速页模式动态随机存取存储器404(FastPageModeDynamicRandomAccessMemory,简称为FPMDRAM)、扩展数据输出动态随机存取存储器(ExtendedDateOutDynamicRandomAccessMemory,简称为EDODRAM)、同步动态随机存取内存(SynchronousDynamicRandom-AccessMemory,简称SDRAM)等。Wherein, the
存储器404可以用来存储或者缓存需要处理和/或通信使用的各种数据文件,以及处理器402所执行的可能的计算机程序指令。The
处理器402通过读取并执行存储器404中存储的计算机程序指令,以实现上述实施例中的任意一种GPU资源POD的热迁移方法。The
可选地,上述电子装置还可以包括传输设备406以及输入输出设备408,其中,该传输设备406和上述处理器402连接,该输入输出设备408和上述处理器402连接。Optionally, the above-mentioned electronic device may further include a
传输设备406可以用来经由一个网络接收或者发送数据。上述的网络具体实例可包括电子装置的通信供应商提供的有线或无线网络。在一个实例中,传输设备包括一个网络适配器(Network Interface Controller,简称为NIC),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输设备406可以为射频(Radio Frequency,简称为RF)模块,其用于通过无线方式与互联网进行通讯。
输入输出设备408用于输入或输出信息。在本实施例中,输入的信息可以是迁移POD的迁移请求,高频内存块与低频内存块、元数据树状图索引等,输出的信息可以是迁移结果,哈希校验的结果等。Input and
可选地,在本实施例中,上述处理器402可以被设置为通过计算机程序执行以下步骤:Optionally, in this embodiment, the
S101、GPU客户端向需要进行热迁移的迁移POD和GPU服务端发送迁移请求,算法容器云平台的控制服务器通过所述迁移请求确认接收POD;S101. The GPU client sends a migration request to the migrating POD and the GPU server that need hot migration, and the control server of the algorithm container cloud platform confirms receiving the POD through the migration request;
S102、所述迁移POD中的迁移组件在收到所述迁移请求后,对所述迁移POD中镜像文件的元数据树状图索引进行检查得到元数据索引缓存,将所述元数据缓存索引接收POD的迁移接收组件,所述接收POD的迁移接收组件根据所述元数据缓存索引在所述接收POD中建立文件系统,并将所述元数据缓存索引所对应的数据放入所述文件系统中;S102. After receiving the migration request, the migration component in the migration POD checks the metadata tree index of the mirror file in the migration POD to obtain a metadata index cache, and receives the metadata cache index The migration receiving component of the POD, the migration receiving component of the receiving POD establishes a file system in the receiving POD according to the metadata cache index, and puts the data corresponding to the metadata cache index into the file system ;
S103、收集迁移POD中的进程树信息,并在所述进程树信息的每一进程中添加寻址代码,所述寻址代码在对应的进程对内存进行调用时被拷贝到对应的内存的地址空间并实时记录每一内存的变化频次,根据所述变化频次将内存分为高频内存块和低频内存块,将所述高频内存块与所述低频内存块作为内存状态文件传输到所述迁移接收组件中。S103. Collect process tree information in the migrated POD, and add an addressing code in each process of the process tree information, and the addressing code is copied to the address of the corresponding memory when the corresponding process calls the memory Space and record the change frequency of each memory in real time, divide the memory into high-frequency memory block and low-frequency memory block according to the change frequency, and transmit the high-frequency memory block and the low-frequency memory block as memory state files to the Migrate in the receiving component.
需要说明的是,本实施例中的具体示例可以参考上述实施例及可选实施方式中所描述的示例,本实施例在此不再赘述。It should be noted that, for specific examples in this embodiment, reference may be made to the examples described in the foregoing embodiments and optional implementation manners, and details will not be repeated in this embodiment.
通常,各种实施例可以以硬件或专用电路、软件、逻辑或其任何组合来实现。本发明的一些方面可以以硬件来实现,而其他方面可以以可以由控制器、微处理器或其他计算设备执行的固件或软件来实现,但是本发明不限于此。尽管本发明的各个方面可以被示出和描述为框图、流程图或使用一些其他图形表示,但是应当理解,作为非限制性示例,本文中描述的这些框、装置、系统、技术或方法可以以硬件、软件、固件、专用电路或逻辑、通用硬件或控制器或其他计算设备或其某种组合来实现。In general, the various embodiments may be implemented in hardware or special purpose circuits, software, logic or any combination thereof. Some aspects of the invention may be implemented in hardware, while other aspects may be implemented in firmware or software which may be executed by a controller, microprocessor or other computing device, although the invention is not limited thereto. Although various aspects of the present invention may be shown and described as block diagrams, flowcharts, or using some other graphical representation, it should be understood that, as non-limiting examples, these blocks, devices, systems, techniques or methods described herein may be presented in hardware, software, firmware, special purpose circuits or logic, general purpose hardware or controllers or other computing devices, or some combination thereof.
本发明的实施例可以由计算机软件来实现,该计算机软件由移动设备的数据处理器诸如在处理器实体中可执行,或者由硬件来实现,或者由软件和硬件的组合来实现。包括软件例程、小程序和/或宏的计算机软件或程序(也称为程序产品)可以存储在任何装置可读数据存储介质中,并且它们包括用于执行特定任务的程序指令。计算机程序产品可以包括当程序运行时被配置为执行实施例的一个或多个计算机可执行组件。一个或多个计算机可执行组件可以是至少一个软件代码或其一部分。另外,在这一点上,应当注意,如图3中的逻辑流程的任何框可以表示程序步骤、或者互连的逻辑电路、框和功能、或者程序步骤和逻辑电路、框和功能的组合。软件可以存储在诸如存储器芯片或在处理器内实现的存储块等物理介质、诸如硬盘或软盘等磁性介质、以及诸如例如DVD及其数据变体、CD等光学介质上。物理介质是非瞬态介质。Embodiments of the invention may be implemented by computer software executable by a data processor of a mobile device, such as in a processor entity, or by hardware, or by a combination of software and hardware. Computer software or programs (also referred to as program products) including software routines, applets and/or macros can be stored on any device-readable data storage medium and they include program instructions for performing certain tasks. A computer program product may include one or more computer-executable components configured to perform an embodiment when the program is run. One or more computer-executable components may be at least one software code or a portion thereof. Also in this regard, it should be noted that any blocks of the logic flow as in FIG. 3 may represent program steps, or interconnected logic circuits, blocks and functions, or a combination of program steps and logic circuits, blocks and functions. Software may be stored on physical media such as memory chips or memory blocks implemented within the processor, magnetic media such as hard or floppy disks, and optical media such as eg DVD and its data variants, CD. Physical media are non-transient media.
本领域的技术人员应该明白,以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。Those skilled in the art should understand that the various technical features of the above embodiments can be combined arbitrarily. For the sake of concise description, all possible combinations of the various technical features in the above embodiments are not described. There is no contradiction in the combination, and all should be considered as within the scope of the description.
以上实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请的保护范围应以所附权利要求为准。The above examples only express several implementation modes of the present application, and the description thereof is relatively specific and detailed, but should not be construed as limiting the scope of the present application. It should be noted that those skilled in the art can make several modifications and improvements without departing from the concept of the present application, and these all belong to the protection scope of the present application. Therefore, the protection scope of the present application should be determined by the appended claims.
Claims (9)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211169473.5A CN115292051B (en) | 2022-09-26 | 2022-09-26 | Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211169473.5A CN115292051B (en) | 2022-09-26 | 2022-09-26 | Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115292051A CN115292051A (en) | 2022-11-04 |
| CN115292051B true CN115292051B (en) | 2023-01-03 |
Family
ID=83833755
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211169473.5A Expired - Fee Related CN115292051B (en) | 2022-09-26 | 2022-09-26 | Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115292051B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116339954A (en) * | 2023-04-07 | 2023-06-27 | 北京趋动智能科技有限公司 | Process migration method, device, storage medium and electronic equipment |
| CN121636047A (en) * | 2024-09-09 | 2026-03-10 | 阿里云计算有限公司 | Secure container migration methods, equipment, storage media, and procedures. |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8285758B1 (en) * | 2007-06-30 | 2012-10-09 | Emc Corporation | Tiering storage between multiple classes of storage on the same container file system |
| WO2015027513A1 (en) * | 2013-09-02 | 2015-03-05 | 运软网络科技(上海)有限公司 | System for migrating point of delivery across domains |
| CN107704618A (en) * | 2017-10-27 | 2018-02-16 | 北京航空航天大学 | A kind of heat based on aufs file system migrates method and system |
| CN108279969A (en) * | 2018-02-26 | 2018-07-13 | 中科边缘智慧信息科技(苏州)有限公司 | Stateful service container thermomigration process based on memory compression transmission |
| CN110119377A (en) * | 2019-04-24 | 2019-08-13 | 华中科技大学 | Online migratory system towards Docker container is realized and optimization method |
| CN112631715A (en) * | 2020-12-04 | 2021-04-09 | 苏州浪潮智能科技有限公司 | Mirror migration optimization method, system and medium based on cache matching |
| CN113918096A (en) * | 2021-10-21 | 2022-01-11 | 城云科技(中国)有限公司 | Method and device for uploading algorithm mirror image packet and application |
| CN114172729A (en) * | 2021-12-08 | 2022-03-11 | 中国电信股份有限公司 | Trusted container migration method and device and storage medium |
| CN114528086A (en) * | 2022-02-26 | 2022-05-24 | 苏州浪潮智能科技有限公司 | Method, device, equipment and medium for thermal migration of pooled heterogeneous cloud computing application |
| CN114816656A (en) * | 2022-03-11 | 2022-07-29 | 新华三大数据技术有限公司 | Container group migration method, electronic device and storage medium |
| CN114860378A (en) * | 2022-04-29 | 2022-08-05 | 苏州浪潮智能科技有限公司 | File system migration method, device, system and medium thereof |
| CN114968477A (en) * | 2022-04-21 | 2022-08-30 | 京东科技信息技术有限公司 | Container heat transfer method and container heat transfer device |
| CN115039089A (en) * | 2019-11-29 | 2022-09-09 | 亚马逊技术有限公司 | Warm tier storage for search services |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8639665B2 (en) * | 2012-04-04 | 2014-01-28 | International Business Machines Corporation | Hybrid backup and restore of very large file system using metadata image backup and traditional backup |
| US10476809B1 (en) * | 2014-03-12 | 2019-11-12 | Amazon Technologies, Inc. | Moving virtual machines using migration profiles |
| CN105893542B (en) * | 2016-03-31 | 2019-04-12 | 华中科技大学 | A kind of cold data file redistribution method and system in cloud storage system |
| US10162559B2 (en) * | 2016-09-09 | 2018-12-25 | Veritas Technologies Llc | Systems and methods for performing live migrations of software containers |
| US10545913B1 (en) * | 2017-04-30 | 2020-01-28 | EMC IP Holding Company LLC | Data storage system with on-demand recovery of file import metadata during file system migration |
| CN109697016B (en) * | 2017-10-20 | 2022-02-15 | 伊姆西Ip控股有限责任公司 | Method and apparatus for improving storage performance of containers |
| US10824466B2 (en) * | 2018-09-26 | 2020-11-03 | International Business Machines Corporation | Container migration |
| US12346725B2 (en) * | 2020-07-02 | 2025-07-01 | International Business Machines Corporation | Artificial intelligence optimized cloud migration |
| US11314687B2 (en) * | 2020-09-24 | 2022-04-26 | Commvault Systems, Inc. | Container data mover for migrating data between distributed data storage systems integrated with application orchestrators |
-
2022
- 2022-09-26 CN CN202211169473.5A patent/CN115292051B/en not_active Expired - Fee Related
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8285758B1 (en) * | 2007-06-30 | 2012-10-09 | Emc Corporation | Tiering storage between multiple classes of storage on the same container file system |
| WO2015027513A1 (en) * | 2013-09-02 | 2015-03-05 | 运软网络科技(上海)有限公司 | System for migrating point of delivery across domains |
| CN107704618A (en) * | 2017-10-27 | 2018-02-16 | 北京航空航天大学 | A kind of heat based on aufs file system migrates method and system |
| CN108279969A (en) * | 2018-02-26 | 2018-07-13 | 中科边缘智慧信息科技(苏州)有限公司 | Stateful service container thermomigration process based on memory compression transmission |
| CN110119377A (en) * | 2019-04-24 | 2019-08-13 | 华中科技大学 | Online migratory system towards Docker container is realized and optimization method |
| CN115039089A (en) * | 2019-11-29 | 2022-09-09 | 亚马逊技术有限公司 | Warm tier storage for search services |
| CN112631715A (en) * | 2020-12-04 | 2021-04-09 | 苏州浪潮智能科技有限公司 | Mirror migration optimization method, system and medium based on cache matching |
| CN113918096A (en) * | 2021-10-21 | 2022-01-11 | 城云科技(中国)有限公司 | Method and device for uploading algorithm mirror image packet and application |
| CN114172729A (en) * | 2021-12-08 | 2022-03-11 | 中国电信股份有限公司 | Trusted container migration method and device and storage medium |
| CN114528086A (en) * | 2022-02-26 | 2022-05-24 | 苏州浪潮智能科技有限公司 | Method, device, equipment and medium for thermal migration of pooled heterogeneous cloud computing application |
| CN114816656A (en) * | 2022-03-11 | 2022-07-29 | 新华三大数据技术有限公司 | Container group migration method, electronic device and storage medium |
| CN114968477A (en) * | 2022-04-21 | 2022-08-30 | 京东科技信息技术有限公司 | Container heat transfer method and container heat transfer device |
| CN114860378A (en) * | 2022-04-29 | 2022-08-05 | 苏州浪潮智能科技有限公司 | File system migration method, device, system and medium thereof |
Non-Patent Citations (3)
| Title |
|---|
| Good Shepherds Care For Their Cattle: Seamless Pod Migration in Geo-Distributed Kubernetes;Paulo Souza Junior 等;《2022 IEEE 6th International Conference on Fog and Edge Computing (ICFEC)》;20220620;第26-34页 * |
| 一种面向节能的虚拟机在线迁移解决方案;赵丹等;《计算机技术与发展》;20171031(第02期);全文 * |
| 容器热迁移的快速内存同步技术;游强志 等;《计算机与现代化》;20220131;第17-34页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115292051A (en) | 2022-11-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11809726B2 (en) | Distributed storage method and device | |
| CN113302584B (en) | Storage management for cloud-based storage systems | |
| CN111868676B (en) | Servicing I/O operations in a cloud-based storage system | |
| CN112565325B (en) | Mirror image file management method, device and system, computer equipment and storage medium | |
| US10579364B2 (en) | Upgrading bundled applications in a distributed computing system | |
| US10896102B2 (en) | Implementing secure communication in a distributed computing system | |
| US9971823B2 (en) | Dynamic replica failure detection and healing | |
| AU2013266122B2 (en) | Backup image duplication | |
| CN102902600B (en) | Efficient application-aware disaster recovery | |
| US20190213085A1 (en) | Implementing Fault Domain And Latency Requirements In A Virtualized Distributed Storage System | |
| US11347684B2 (en) | Rolling back KUBERNETES applications including custom resources | |
| US10620871B1 (en) | Storage scheme for a distributed storage system | |
| CN110347651A (en) | Method of data synchronization, device, equipment and storage medium based on cloud storage | |
| US11537553B2 (en) | Managing snapshots stored locally in a storage system and in cloud storage utilizing policy-based snapshot lineages | |
| EP3739440A1 (en) | Distributed storage system, data processing method and storage node | |
| CN115292051B (en) | Hot migration method, device and application of GPU (graphics processing Unit) resource POD (POD) | |
| WO2019137321A1 (en) | Data processing method and apparatus, and computing device | |
| WO2024148824A1 (en) | Data processing method, system and apparatus, storage medium, and electronic device | |
| CN110413694A (en) | Metadata management method and relevant apparatus | |
| WO2023231572A1 (en) | Container creation method and apparatus, and storage medium | |
| CN114090179A (en) | Migration method and device of stateful service and server | |
| JP2021077374A (en) | Synchronous object placement for information lifecycle management | |
| CN114625474A (en) | Container migration method and device, electronic equipment and storage medium | |
| US11573923B2 (en) | Generating configuration data enabling remote access to portions of a snapshot lineage copied to cloud storage | |
| WO2019153880A1 (en) | Method for downloading mirror file in cluster, node, and query server |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20230103 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |