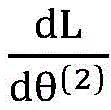Disclosure of Invention
An object of the embodiment of the present application is to provide a federated learning method, an apparatus, an electronic device, and a storage medium, which are used to solve the problem of low security in the current federated learning process.
The embodiment of the application provides a federated learning method, which comprises the following steps: receiving a secret state gradient random value sent by equipment on a non-tag side, wherein sample data is stored in the equipment on the non-tag side, and the secret state gradient random value is obtained by carrying out homomorphic encryption on a loss value corresponding to the sample data and adding a random number; homomorphic decryption is carried out on the secret state gradient random value to obtain a gradient random value; adding a noise value to the gradient random value to obtain a noise-added gradient random value; and sending the noise-added gradient random value to the equipment on the non-tag side so that the equipment on the non-tag side performs federal learning on the local model according to the noise-added gradient random value. In the implementation process, a noise-added gradient random value is obtained by adding a noise value to the obtained gradient random value; and sending the noise-added gradient random value to the equipment on the non-tag side, so that the equipment on the non-tag side is difficult to use the gradient value, the prediction tag and the sample data to break the sample tag stored on the equipment on the tag, and the security of federal learning is effectively improved.
Optionally, in this embodiment of the present application, adding a noise value to the gradient random value includes: a noise value is generated using a local differential privacy algorithm and added to the gradient random value. In the implementation process, the noise value is generated by using the local differential privacy algorithm, and the local differential privacy algorithm only considers the statistical characteristics of the local data set, so that the risk that the local data is leaked to other equipment is better avoided in the process of multi-party federal learning or multi-party safety calculation, and the safety of federal learning is effectively improved.
Optionally, in this embodiment of the application, before receiving the secret gradient random value sent by the non-tag side device, the method further includes: obtaining a dense state loss value, wherein the dense state loss value is calculated by a labeled side device, and the labeled side device is a device for storing a sample label corresponding to sample data; and sending the secret state loss value to the non-tag side equipment so that the non-tag side equipment calculates a secret state gradient value according to the secret state loss value, and adding the generated random number to the secret state gradient value to obtain and return a secret state gradient random value. In the implementation process, the secret state loss value is sent to the non-tag side equipment, so that the non-tag side equipment calculates the secret state gradient value according to the secret state loss value, the generated random number is added to the secret state gradient value, and the secret state gradient random value is obtained and returned, so that the problem that the gradient value is leaked to the non-tag side equipment in a plaintext state is solved, and the security of federal learning is effectively improved.
Optionally, in this embodiment of the present application, obtaining the secret state loss value includes: sending a public key of the central server to the equipment with the label so that the equipment with the label can use the public key to perform homomorphic encryption on the obtained loss value, and obtaining and returning a secret loss value; and receiving the secret state loss value sent by the equipment on the label side.
The embodiment of the application further provides a federated learning method, which is applied to equipment without a tag, and comprises the following steps: obtaining a secret state loss value, and calculating a secret state gradient value according to the secret state loss value and sample data stored on the non-tag side equipment, wherein the secret state loss value is obtained by homomorphic encryption; adding the generated random number to the secret gradient value to obtain a secret gradient random value; sending the secret state gradient random value to a central server so that the central server decrypts the gradient random value from the secret state gradient random value, adding a noise value into the gradient random value, and obtaining and returning the noise-added gradient random value; and receiving a noise-added gradient random value sent by the central server, and subtracting a random number from the noise-added gradient random value to obtain a noise-added gradient value, wherein the noise-added gradient value is used for carrying out federal learning on the local model. In the implementation process, a noise-added gradient random value is obtained by adding a noise value to the obtained gradient random value; and sending the noise-added gradient random value to the equipment on the non-tag side, so that the equipment on the non-tag side is difficult to use the gradient value, the prediction tag and the sample data to break the sample tag stored on the equipment on the tag, and the security of federal learning is effectively improved.
Optionally, in this embodiment of the present application, obtaining the secret state loss value includes: obtaining model parameters and sample data of a local model, and calculating an inner product result between the model parameters and the sample data; sending the inner product result to the equipment of the tagged party to enable the equipment of the tagged party to calculate a prediction label corresponding to the inner product result, calculating a loss value between the prediction label and a sample label corresponding to the inner product result, and then carrying out homomorphic encryption on the loss value by using a public key of the central server to obtain and return a secret state loss value; and receiving the secret state loss value sent by the equipment on the label side. In the implementation process, the inner product result between the model parameter and the sample data is calculated by acquiring the model parameter and the sample data of the local model; and the inner product result is sent to the equipment with the label, so that the problem that the sample data plaintext is directly leaked to the equipment with the label is avoided, and only the inner product result between the model parameter and the sample data is leaked to the equipment with the label, so that the security of federal learning is effectively improved.
The embodiment of the application further provides a bang learning device, which is applied to a central server and comprises: the system comprises a secret state gradient receiving module, a secret state gradient processing module and a random number generating module, wherein the secret state gradient receiving module is used for receiving a secret state gradient random value sent by equipment on a non-label side, sample data is stored in the equipment on the non-label side, and the secret state gradient random value is obtained by homomorphically encrypting a loss value corresponding to the sample data and adding the random number; the secret state gradient decryption module is used for homomorphic decryption of the secret state gradient random value to obtain a gradient random value; the gradient random noise adding module is used for adding a noise value in the gradient random value to obtain a noise-added gradient random value; and the noise gradient sending module is used for sending the noise gradient random value to the equipment on the non-tag side so as to enable the equipment on the non-tag side to carry out federal learning on the local model according to the noise gradient random value.
Optionally, in an embodiment of the present application, the gradient random noise adding module includes: and the differential privacy generation module is used for generating a noise value by using a local differential privacy algorithm and adding the noise value to the gradient random value.
Optionally, in an embodiment of the present application, the federal learning device further includes: the system comprises a dense state loss obtaining module, a dense state loss obtaining module and a data processing module, wherein the dense state loss obtaining module is used for obtaining a dense state loss value, the dense state loss value is calculated by a device on a labeled side, and the device on the labeled side is a device for storing a sample label corresponding to sample data; and the dense-state loss sending module is used for sending a dense-state loss value to the non-tag side equipment so that the non-tag side equipment calculates a dense-state gradient value according to the dense-state loss value, and adds the generated random number to the dense-state gradient value to obtain and return a dense-state gradient random value.
Optionally, in an embodiment of the present application, the secret state loss obtaining module includes: the public key homomorphic encryption module is used for sending the public key of the central server to the equipment with the label so that the equipment with the label uses the public key to homomorphically encrypt the obtained loss value, and the obtained loss value is returned; and the secret state loss receiving module is used for receiving the secret state loss value sent by the equipment with the label.
The embodiment of the application further provides a bang learning device, is applied to no label side equipment, includes: the secret state gradient calculation module is used for acquiring a secret state loss value and calculating a secret state gradient value according to the secret state loss value and sample data stored on the non-tag side equipment, wherein the secret state loss value is obtained by homomorphic encryption; the dense gradient random module is used for adding the generated random number to the dense gradient value to obtain a dense gradient random value; the secret state gradient sending module is used for sending the secret state gradient random value to the central server so that the central server decrypts the gradient random value from the secret state gradient random value, adds a noise value in the gradient random value, and obtains and returns the noise-added gradient random value; and the noise gradient receiving module is used for receiving the noise gradient random value sent by the central server, subtracting the random number from the noise gradient random value to obtain a noise gradient value, and the noise gradient value is used for carrying out federal learning on the local model.
Optionally, in an embodiment of the present application, the dense gradient calculating module includes: the inner product result calculation module is used for acquiring the model parameters and the sample data of the local model and calculating the inner product result between the model parameters and the sample data; the inner product result sending module is used for sending the inner product result to the equipment with the label, so that the equipment with the label calculates a prediction label corresponding to the inner product result, calculates a loss value between the prediction label and a sample label corresponding to the inner product result, and then uses a public key of the central server to homomorphically encrypt the loss value to obtain and return a secret loss value; and the first loss receiving module is used for receiving the secret state loss value sent by the equipment with the label.
An embodiment of the present application further provides an electronic device, including: a processor and a memory, the memory storing processor-executable machine-readable instructions, the machine-readable instructions when executed by the processor performing the method as described above.
Embodiments of the present application further provide a computer-readable storage medium, on which a computer program is stored, and the computer program is executed by a processor to perform the method as described above.
Detailed Description
The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only some of the embodiments of the present application, and not all of the embodiments. The components of the embodiments of the present application, as generally described and illustrated in the figures herein, could be arranged and designed in a wide variety of different configurations. Thus, the following detailed description of the embodiments of the present application, as presented in the figures, is not intended to limit the scope of the claimed embodiments of the application, but is merely representative of selected embodiments of the application. All other embodiments obtained by a person skilled in the art based on the embodiments of the present application without making any creative effort belong to the protection scope of the embodiments of the present application.
Before introducing the federal learning method provided in the embodiments of the present application, some concepts involved in the embodiments of the present application are introduced:
machine Learning (ML), a branch in the field of artificial intelligence to study human Learning behavior; by referring to the scientific or theoretical viewpoints of cognition science, biology, philosophy, statistics, information theory, control theory, computational complexity and the like, the method explores the human cognition rules and the learning process through the basic methods of induction, generalization, specialization, analogy and the like, and establishes various algorithms capable of being automatically improved through experience, so that the computer system has the capability of automatically learning specific knowledge and skills.
Homomorphic encryption (Homomorphic encryption) is a form of encryption that allows one to perform a particular form of algebraic operation on ciphertext to obtain a result that is still encrypted, and to decrypt it to obtain the same result as performing the same operation on plaintext. In other words, this technique allows one to perform operations such as retrieval, comparison, etc. in the encrypted data to yield the correct result without the need to decrypt the data throughout the process.
Differential Privacy (Differential Privacy) is a means of data sharing that can be implemented to share only some of the statistical features that describe a database, without disclosing specific to-individual information. The intuitive idea behind differential privacy is: if the influence caused by randomly modifying one record in the database is small enough, the obtained statistical characteristics can not be used for reversely deducing the content of a single record; this feature may be used to protect privacy. From another perspective, differential privacy can be considered as a constraint for algorithms that disclose statistical characteristics of statistical databases. The constraint requires that private information in the records of the database not be disclosed.
It should be noted that the federal learning method provided in this embodiment of the present application may be executed by an electronic device, where the electronic device includes but is not limited to: a tagged-party device, an untagged-party device, and/or a central server. The tagged side equipment refers to electronic equipment with a sample tag for training a model, and the tagged equipment may or may not have sample data corresponding to the sample tag. The non-label side device is an electronic device with sample data for training a model, but the non-label side device does not have a sample label corresponding to the sample data, so that the machine learning model needs to be trained by combining the sample data on the non-label side device and the sample label on the label side device. Optionally, the non-labeled device and the labeled device may select a central server, where the central server is used to coordinate a process of training the machine learning model together, and ensure that, in the process of training the machine learning, sample data on the non-labeled device is not leaked to the labeled device and the central server, and a sample label on the labeled device is not leaked to the non-labeled device and the central server, that is, neither the sample data nor the sample label can be leaked in the clear text to other devices except the device itself, and the central server does not know the sample data and the sample label in the clear text state.
The above-mentioned tagged side device, untagged side device and central server all refer to a device terminal or server having a function of executing a computer program, and the device terminal includes: a smart phone, a personal computer, a tablet computer, a personal digital assistant, or a mobile internet device, etc. A server refers to a device that provides computing services over a network, such as: x86 server and non-x 86 server, non-x 86 server includes: mainframe, minicomputer, and UNIX server. It is understood that the user corresponding to the above-mentioned tagged-side device and the user corresponding to the non-tagged-side device are both parties of federal learning, and therefore, the above-mentioned tagged-side device and the non-tagged-side device may also be both referred to as participant devices.
Application scenarios applicable to the federal learning method are described below, where the application scenarios include, but are not limited to: during federal learning, the gradient values obtained by the untagged device can be formulated as
Wherein,
representing the gradient value, y the sample label, h (θ)
(2) ) Denotes a prediction tag, x
(2) Representing sample data. Because the label-free equipment stores sample data, and an accurate prediction label, namely h (theta) can be obtained after the model is iterated for multiple times
(2) ) And x
(2) Are known. With the deepening of the training times, an accurate gradient value is finally obtained, and y is a discrete value of 0 or 1, so that the label-free device can easily use the gradient value, the prediction label and sample data to break the sample label stored on the labeled device, the specific breaking idea can simplify the above formula and consider the formula as a Subset Sum problem, and the Subset Sum problem has a quick solution under the condition of small-scale calculation or sparse search domain. Therefore, the sample label stored on the labeled device can be easily broken according to the gradient value, the prediction label and the sample data, and the federal learning safety is low. In such a scenario, the federate learning method can be used to add a noise value to the obtained gradient random value, so that the non-labeled side device is difficult to use the gradient value, the prediction label and the sample data to break the sample label stored on the labeled side device, thereby effectively improving the security of federate learning.
Please refer to fig. 1, which illustrates a flow chart of a federal learning method provided in an embodiment of the present application; in a federal learning scenario executed by three parties (including a labeled party device, an unlabeled party device, and a central server), the federal learning method can be applied to the central server, i.e., the federal learning method can be executed by the central server, and of course, can also be executed by a labeled party device in a federal learning method executed by two parties, which will be described in detail later. The main idea of the federal learning method is to obtain a noise-added gradient random value by adding a noise value to the obtained gradient random value; and sending the noise-added gradient random value to the equipment on the non-tag side, so that the equipment on the non-tag side is difficult to use the gradient value, the prediction tag and the sample data to break the sample tag stored on the equipment on the tag, and the security of federal learning is effectively improved. The federal learning method may specifically include:
step S110: the central server receives a secret state gradient random value sent by the equipment of the non-tag side, sample data is stored in the equipment of the non-tag side, and the secret state gradient random value is obtained by carrying out homomorphic encryption on a loss value corresponding to the sample data and adding a random number.
Please refer to fig. 2, which illustrates an interaction sequence diagram of a three-party execution federal learning method provided in the embodiment of the present application; the embodiment of step S110 described above is, for example: the central server may generate a pair of public key (pk) and private key (secret key) in advance using an asymmetric encryption algorithm, and then send the public key generated on the central server to the untagged device. After receiving a public key pk sent by a central server, a non-tag side device firstly obtains sample data and model parameters which are locally stored, wherein the sample data can be represented as x, and the model parameters can be represented as theta; and then calculating an inner product result between the sample data and the model parameters, and sending the inner product result to the equipment with the label, wherein the inner product result can be represented as u, and then u can be obtained by carrying out inner product calculation on x and theta. After receiving the inner product result sent by the non-tag device, the tagged device calculates a prediction tag corresponding to the inner product result, inputs the inner product result into the machine learning model, and obtains a prediction tag, where the prediction tag may be specifically represented as h (θ), and calculates a loss value between the prediction tag and a sample tag corresponding to the inner product result, where the loss value may be represented as y-h (θ), where y represents the sample tag, and then performs homomorphic encryption on the loss value using a public key of the central server, and obtains a secret state loss value represented as [ L []=[y-h(θ)]And transmitting the secret state loss value [ L ] to the non-label side equipment]. After the non-tag side equipment receives the secret state loss value sent by the tag side equipment, the secret state gradient is calculated according to the secret state loss value, and the secret state gradient can be expressed as

Then, the generated random number is added to the dense gradient value to obtain a dense gradient random value
Where R represents the generated random number, and finally, sends the secret gradient random value to the central server
The central server can receive the secret state gradient random value sent by the equipment without the label
After step S110, step S120 is performed: and the central server performs homomorphic decryption on the secret state gradient random value to obtain the gradient random value.
The embodiment of step S120 described above is, for example: central server for secret state gradient random value
The homomorphic decryption is carried out, and the obtained gradient random value can be expressed as
After step S120, step S130 is performed: and the central server adds a noise value in the gradient random value to obtain a noise-added gradient random value.
The embodiment of step S130 described above is, for example: the central server generates a noise value by using a Local Differential Privacy (LDP) algorithm, and adds the noise value to the gradient random value to obtain a noise-added gradient random value; the local differential privacy algorithm is also referred to as a localized differential privacy algorithm. The local differential privacy algorithm only considers the statistical characteristics of the local data set, so that the risk that local data are leaked to other equipment is better avoided in the multi-party federal learning or multi-party safety calculation process, and the safety of federal learning is effectively improved. The noise value can also be generated by adopting a Global Differential Privacy (GDP) algorithm, and the Global Differential Privacy algorithm considers the statistical characteristics of all data sets, so that the model training and convergence process can be accelerated more quickly in the multi-party federal learning or multi-party safety calculation process. Of course, in a specific practical process, the above-mentioned noise value may also use laplacian (Laplace) noise, or may use CH noise.
After step S130, step S140 is performed: and the central server sends the noise-added gradient random value to the equipment on the non-tag side, so that the equipment on the non-tag side performs federal learning on the local model according to the noise-added gradient random value.
The embodiment of step S140 described above is, for example: the central server sends the noise-added gradient random value to the non-tag side device through a Transmission Control Protocol (TCP) or a User Datagram Protocol (UDP). After receiving the noise-added gradient random value sent by the central server, the non-tag side equipment can subtract the random number from the noise-added gradient random value to obtain a noise-added gradient value, and then the noise-added gradient value is used for updating the weight value of the local model; local models herein include, but are not limited to: a logistic regression algorithm model in a machine learning algorithm. In the above process, only one round of data interaction process is described, and in specific practice, the above steps S110 to S140 need to be repeated until the loss function of the local model converges, for example: and when the loss value of the local model is smaller than a preset proportion or the number of iteration times (epoch) is larger than a preset threshold value, the trained local model can be obtained. The preset proportion can be set according to specific situations, for example, set to be 5% or 10%, etc.; the preset threshold may also be set according to specific situations, for example, set to 100 or 1000, etc.
In the implementation process, firstly, the secret state gradient random value sent by the non-tag side equipment is received, then homomorphic decryption is carried out on the secret state gradient random value to obtain a gradient random value, then a noise value is added into the gradient random value, and finally the noisy gradient random value is sent to the non-tag side equipment, so that the non-tag side equipment is difficult to crack the sample tag according to the received gradient random value, and the received gradient random value is a numerical value after noise is added. That is, by adding a noise value to the obtained gradient random value, a noise-added gradient random value is obtained; and sending the noise-added gradient random value to the equipment on the non-tag side, so that the equipment on the non-tag side is difficult to use the gradient value, the prediction tag and the sample data to break the sample tag stored on the equipment on the tag, and the security of federal learning is effectively improved.
Please refer to fig. 3, which illustrates an interaction sequence diagram of two parties executing the federal learning method according to an embodiment of the present application; the federal learning method may specifically include:
step S210: and the equipment on the label side receives the secret state gradient random value sent by the equipment on the non-label side, sample data is stored on the equipment on the non-label side, and the secret state gradient random value is obtained by homomorphically encrypting the loss value corresponding to the sample data and adding a random number.
The embodiment of step S210 described above is, for example: and the equipment on the non-tag side acquires the sample data and the model parameters, calculates the inner product result between the sample data and the model parameters, and then sends the inner product result to the equipment on the tag side. After receiving the inner product result sent by the equipment without the label, the equipment with the label first calculates the prediction label corresponding to the inner product result, calculates the loss value between the prediction label and the sample label corresponding to the inner product result, then performs homomorphic encryption on the loss value to obtain a secret state loss value, and finally sends the secret state loss value to the equipment without the label. After receiving the dense-state loss value sent by the equipment with the label, the equipment without the label calculates a dense-state gradient according to the received dense-state loss value, adds a random number generated at random to the dense-state gradient to obtain a dense-state gradient random value, and then sends the dense-state gradient random value to the equipment with the label. The device with the tag can receive the secret state gradient random value sent by the device without the tag.
After step S210, step S220 is performed: and the equipment on the part with the label performs homomorphic decryption on the secret state gradient random value to obtain the gradient random value.
After step S220, step S230 is performed: and the equipment on the label side adds a noise value in the gradient random value to obtain a noise-added gradient random value.
After step S230, step S240 is performed: and the equipment on the label side sends the noise-added gradient random value to the equipment on the non-label side, so that the equipment on the non-label side performs federal learning on the local model according to the noise-added gradient random value.
The implementation principle and implementation manner of the above steps S220 to S240 are similar to those of the steps S120 to S140, and therefore, the implementation principle and implementation manner will not be described herein, and if it is unclear, reference may be made to the description of the steps S120 to S140.
Please refer to fig. 4, which is a schematic flow chart of a federal learning method executed by a non-tag device according to an embodiment of the present application; in a specific practical process, the above non-tag side device may further calculate a dense state loss value according to a dense state prediction tag and a dense state sample tag corresponding to the sample data, instead of calculating the dense state loss value according to an inner product result, and the implementation may specifically include:
step S310: and the non-tag side equipment acquires a dense state loss value, and a dense state gradient value is calculated according to the dense state loss value and sample data stored on the non-tag side equipment, wherein the dense state loss value is calculated according to a dense state prediction tag and a dense state sample tag on the tag side equipment.
The embodiment of the step S310 is, for example: and the equipment of the non-tag party acquires the sample data, homomorphically encrypts the sample data by using the public key of the central server to obtain the sample data of the secret state, and then sends the sample data of the secret state to the equipment of the tag party. The method comprises the steps that the equipment on the label side calculates a dense state prediction label corresponding to dense state sample data, calculates a dense state loss value between the dense state prediction label and the dense state sample label calculated by the equipment on the label side, and then sends the dense state loss value to the equipment on the non-label side. And the non-tag side equipment receives the secret state loss value sent by the tag side equipment.
Step S320: and the non-tag side equipment adds the generated random number to the secret gradient value to obtain a secret gradient random value, and sends the secret gradient random value to the central server.
The embodiment of step S320 is, for example: after the non-tag side equipment receives the secret state loss value sent by the tag side equipment, the secret state gradient is calculated according to the secret state loss value, and the secret state gradient can be expressed as
Then, the generated random number is added to the dense gradient value to obtain a dense gradient random value
Where R represents the generated random number, and finally, sends the secret gradient random value to the central server
Step S330: the central server receives the secret state gradient random value sent by the non-label side equipment, homomorphic decryption is carried out on the secret state gradient random value to obtain a gradient random value, then, a noise value is added to the gradient random value to obtain a noise-added gradient random value, and the noise-added gradient random value is sent to the non-label side equipment.
Optionally, before receiving the secret gradient random value sent by the non-tag device, the central server may also send a secret loss value to the non-tag device, so that the non-tag device calculates the secret gradient random value according to the secret loss value, where the implementation may include:
step S331: the central server obtains a dense state loss value, wherein the dense state loss value is calculated by the equipment on the part with the label, and the equipment on the part with the label is equipment for storing a sample label corresponding to the sample data.
The embodiment of step S331 described above is, for example: the central server sends the public key of the central server to the equipment with the label through a Hyper Text Transfer Protocol (HTTP) or a Hyper Text Transfer Protocol Secure (HTTPS). After receiving the public key sent by the central server through the HTTP protocol or the HTTPS protocol, the tagged party equipment uses the public key to perform homomorphic encryption on the obtained loss value to obtain a secret state loss value.
Step S332: and the central server sends the secret state loss value to the non-tag side equipment so that the non-tag side equipment calculates a secret state gradient value according to the secret state loss value, and adds the generated random number to the secret state gradient value to obtain and return a secret state gradient random value.
The embodiment of the step S332 is, for example: and the central server sends the secret state loss value to the non-label side equipment through an HTTP (hyper text transport protocol) or an HTTPS (hyper text transport protocol). After receiving the secret state loss value sent by the central server, the non-tag side equipment calculates a secret state gradient value according to the secret state loss value, adds the generated random number to the secret state gradient value to obtain a secret state gradient random value, and finally sends the secret state gradient random value to the central server.
Step S340: and the equipment on the non-tag side receives the noise-added gradient random value sent by the central server, subtracts the random number from the noise-added gradient random value to obtain a noise-added gradient value, and trains a local model by using the noise-added gradient value.
The embodiment of step S340 is, for example: after receiving the noise-added gradient random value sent by the central server, the equipment on the non-tag side can subtract the random number from the noise-added gradient random value to obtain a noise-added gradient value, then train the local model by using the noise-added gradient value, and specifically update the weight value of the local model by using the noise-added gradient value; local models herein include, but are not limited to: a logistic regression algorithm model in a machine learning algorithm. In the above process, only a round of data interaction process is described, and in specific practice, the above steps need to be repeated until the loss function of the local model converges, specifically for example: and when the loss value of the local model is smaller than a preset proportion or the number of iteration times (epoch) is larger than a preset threshold value, the trained local model can be obtained. The preset proportion can be set according to specific situations, for example, set to be 5% or 10%, etc.; the preset threshold may also be set according to specific situations, for example, set to 100 or 1000, etc.
Please refer to fig. 5, which illustrates a schematic structural diagram of a federal learning device provided in an embodiment of the present application; the embodiment of the present application provides a bang learning device 400, is applied to central server, includes:
and a secret state gradient receiving module 410, configured to receive a secret state gradient random value sent by a non-tag side device, where sample data is stored in the non-tag side device, and the secret state gradient random value is obtained by performing homomorphic encryption on a loss value corresponding to the sample data and adding a random number.
And the secret gradient decryption module 420 is configured to perform homomorphic decryption on the secret gradient random value to obtain a gradient random value.
And a gradient random adding module 430, configured to add a noise value to the gradient random value to obtain a noise-added gradient random value.
And a noise gradient sending module 440, configured to send the noise gradient random value to the non-tag side device, so that the non-tag side device performs federal learning on the local model according to the noise gradient random value.
Optionally, in an embodiment of the present application, the gradient random noise adding module includes:
and the differential privacy generation module is used for generating a noise value by using a local differential privacy algorithm and adding the noise value into the gradient random value.
Optionally, in an embodiment of the present application, the federal learning device further includes:
and the dense state loss acquisition module is used for acquiring a dense state loss value, wherein the dense state loss value is calculated by the equipment on the part with the label, and the equipment on the part with the label is equipment for storing a sample label corresponding to the sample data.
And the secret state loss sending module is used for sending the secret state loss value to the non-tag side equipment so that the non-tag side equipment calculates a secret state gradient value according to the secret state loss value, and adds the generated random number to the secret state gradient value to obtain and return the secret state gradient random value.
Optionally, in an embodiment of the present application, the secret state loss obtaining module includes:
and the public key homomorphic encryption module is used for sending the public key of the central server to the equipment with the label so that the equipment with the label uses the public key to homomorphically encrypt the obtained loss value, and the obtained loss value is returned.
And the secret state loss receiving module is used for receiving the secret state loss value sent by the equipment with the label.
The embodiment of the application provides a bang learning device, is applied to no label side equipment, includes:
and the secret state gradient calculation module is used for acquiring a secret state loss value and calculating a secret state gradient value according to the secret state loss value and sample data stored on the non-tag side equipment, wherein the secret state loss value is obtained by homomorphic encryption.
And the dense gradient random module is used for adding the generated random number to the dense gradient value to obtain a dense gradient random value.
And the secret state gradient sending module is used for sending the secret state gradient random value to the central server so that the central server decrypts the gradient random value from the secret state gradient random value, adds a noise value in the gradient random value, and obtains and returns the noisy gradient random value.
And the noise gradient receiving module is used for receiving the noise gradient random value sent by the central server, subtracting the random number from the noise gradient random value to obtain a noise gradient value, and the noise gradient value is used for carrying out federal learning on the local model.
Optionally, in an embodiment of the present application, the dense gradient calculating module includes:
and the inner product result calculation module is used for acquiring the model parameters and the sample data of the local model and calculating the inner product result between the model parameters and the sample data.
And the inner product result sending module is used for sending the inner product result to the equipment with the label, so that the equipment with the label calculates a prediction label corresponding to the inner product result, calculates a loss value between the prediction label and a sample label corresponding to the inner product result, and then homomorphically encrypts the loss value by using a public key of the central server to obtain and return a secret state loss value.
And the first loss receiving module is used for receiving the secret state loss value sent by the equipment with the label.
It should be understood that the apparatus corresponds to the above-mentioned federal learning method embodiment, and can perform the steps related to the above-mentioned method embodiment, and the specific functions of the apparatus can be referred to the above description, and the detailed description is appropriately omitted here to avoid redundancy. The device includes at least one software function that can be stored in memory in the form of software or firmware (firmware) or solidified in the Operating System (OS) of the device.
Please refer to fig. 6 for a schematic structural diagram of an electronic device according to an embodiment of the present application. An electronic device 500 provided in an embodiment of the present application includes: a processor 510 and a memory 520, the memory 520 storing machine readable instructions executable by the processor 510, the machine readable instructions when executed by the processor 510 performing the method as above.
Embodiments also provide a computer-readable storage medium 530, where the computer-readable storage medium 530 stores thereon a computer program, and when the computer program is executed by the processor 510, the computer program performs the method described above.
The computer-readable storage medium 530 may be implemented by any type of volatile or nonvolatile storage device or combination thereof, such as a Static Random Access Memory (SRAM), an Electrically Erasable Programmable Read-Only Memory (EEPROM), an Erasable Programmable Read-Only Memory (EPROM), a Programmable Read-Only Memory (PROM), a Read-Only Memory (ROM), a magnetic Memory, a flash Memory, a magnetic disk, or an optical disk.
In the embodiments provided in the present application, it should be understood that the disclosed apparatus and method may be implemented in other ways. The apparatus embodiments described above are merely illustrative, and for example, the flowchart and block diagrams in the figures illustrate the architecture, functionality, and operation of possible implementations of apparatus, methods and computer program products according to various embodiments of the present application. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code, which comprises one or more executable instructions for implementing the specified logical function(s). It should also be noted that, in some alternative implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved.
In addition, functional modules of the embodiments in the present application may be integrated together to form an independent part, or each module may exist separately, or two or more modules may be integrated to form an independent part. Furthermore, in the description of the present specification, reference to the description of "one embodiment," "some embodiments," "an example," "a specific example," or "some examples" or the like means that a particular feature, structure, material, or characteristic described in connection with the embodiment or example is included in at least one embodiment or example of the embodiments of the present application. In this specification, the schematic representations of the terms used above are not necessarily intended to refer to the same embodiment or example. Furthermore, the particular features, structures, materials, or characteristics described may be combined in any suitable manner in any one or more embodiments or examples. Furthermore, various embodiments or examples and features of different embodiments or examples described in this specification can be combined and combined by one skilled in the art without contradiction.
In this document, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions.
The above description is only an alternative embodiment of the embodiments of the present application, but the scope of the embodiments of the present application is not limited thereto, and any person skilled in the art can easily conceive of changes or substitutions within the technical scope of the embodiments of the present application, and all the changes or substitutions should be covered by the scope of the embodiments of the present application.