CN114708543A - Examination student positioning method in examination room monitoring video image - Google Patents
Examination student positioning method in examination room monitoring video image Download PDFInfo
- Publication number
- CN114708543A CN114708543A CN202210629393.7A CN202210629393A CN114708543A CN 114708543 A CN114708543 A CN 114708543A CN 202210629393 A CN202210629393 A CN 202210629393A CN 114708543 A CN114708543 A CN 114708543A
- Authority
- CN
- China
- Prior art keywords
- image data
- examination room
- video image
- monitoring video
- hair
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000012544 monitoring process Methods 0.000 title claims abstract description 49
- 238000000034 method Methods 0.000 title claims abstract description 33
- 210000004209 hair Anatomy 0.000 claims abstract description 71
- 238000001514 detection method Methods 0.000 claims abstract description 45
- 238000013135 deep learning Methods 0.000 claims abstract description 7
- 238000012216 screening Methods 0.000 claims abstract description 6
- 238000012545 processing Methods 0.000 claims abstract description 5
- 210000003128 head Anatomy 0.000 claims description 24
- 210000005069 ears Anatomy 0.000 claims description 13
- 210000001061 forehead Anatomy 0.000 claims description 12
- 238000003708 edge detection Methods 0.000 claims description 6
- 238000012360 testing method Methods 0.000 claims description 6
- 238000013136 deep learning model Methods 0.000 claims description 5
- 238000012549 training Methods 0.000 claims description 4
- 238000013507 mapping Methods 0.000 claims 1
- 230000006399 behavior Effects 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 230000007812 deficiency Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 238000010998 test method Methods 0.000 description 1
Images

Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
技术领域technical field
本发明属于图像处理领域,具体涉及一种考场监控视频图像中考生定位方法。The invention belongs to the field of image processing, and in particular relates to a method for locating a candidate in a monitoring video image of an examination room.
背景技术Background technique
在世界范围内,考试一直作为重要的检验、选拔手段广泛使用,这是由于其在一定程度上能确保公平、公正。然而为了顺利通过考试,存在各种各样作弊手段,为了保证考试的公平、公正原则,考试监控系统大量应用于各类考试中。然而,考场拥有了视频监控系统,却并不意味着能很好的解决作弊问题。In the world, the examination has been widely used as an important test and selection method, because it can ensure fairness and justice to a certain extent. However, in order to successfully pass the exam, there are various cheating methods. In order to ensure the fairness and impartiality of the exam, the exam monitoring system is widely used in various exams. However, the fact that the examination room has a video surveillance system does not mean that it can solve the problem of cheating very well.
这是由于视频监控虽然能较为完整的记录考场信息,但是是否存在考试作弊行为,仍然需要相关部门投入大量的人力去对这些视频数据进行后期的处理和审查,其中很大比例的视频中是没有作弊行为的,但每一段视频都需要经过相关人员的仔细审查,由此产生了大量的工作量,由此产生了对考场监控视频中考生的行为进行自动识别的需求,而如何对考场监控视频中考生进行定位,则成为了一个必须解决的关键问题。This is because although video surveillance can record the information of the examination room relatively completely, whether there is cheating in the examination still requires relevant departments to invest a lot of manpower to process and review these video data in the later stage. cheating behavior, but each video needs to be carefully reviewed by relevant personnel, resulting in a lot of workload, which has created the need to automatically identify the behavior of candidates in the examination room surveillance video, and how to check the examination room surveillance video. The positioning of middle school students has become a key problem that must be solved.
对于考场监控视频检测定位方法大致可以分为基于背景差分的方法、基于模板匹配的方法、基于图像特征的方法,这些方法存在检测范围有限,对于考场布局的依赖性较大等问题。The detection and positioning methods of surveillance video in the examination room can be roughly divided into methods based on background difference, methods based on template matching, and methods based on image features. These methods have problems such as limited detection range and greater dependence on the layout of the examination room.
发明内容SUMMARY OF THE INVENTION
本发明针对上述现有技术的不足,提出了一种考场监控视频图像中考生定位方法,包括以下步骤:Aiming at the deficiencies of the above-mentioned prior art, the present invention proposes a method for locating a candidate in a monitoring video image of an examination room, comprising the following steps:
步骤1:对包含了不同考试场景、不同考生的大量考场监控视频图像数据进行基于考生头顶部头发区域的框选标记,然后建立考场监控视频图像数据的考生头顶部头发区域数据集;Step 1: Make a frame selection mark based on the hair area on the top of the examinee's head for a large number of examination room surveillance video image data that includes different examination scenes and different candidates, and then establish a data set of the examinee's head hair area of the examination room surveillance video image data;
步骤2:建立针对考场监控视频图像数据中考生头顶部头发区域定位的目标检测深度学习模型,首先对考场监控视频图像数据中的可能为头发的像素点进行筛选,得到预处理图像数据,然后在预处理图像数据上进行基于SSD的深度学习目标检测;Step 2: Establish a target detection deep learning model for locating the hair area on the top of the examinee's head in the surveillance video image data of the examination room. First, screen the pixels that may be hair in the surveillance video image data of the examination room to obtain the preprocessed image data, and then in the Perform SSD-based deep learning target detection on preprocessed image data;
步骤3:将建立的考场监控视频图像数据的考生头顶部头发区域数据集按比例进行划分,分别生成训练数据集和测试数据集,对建立的针对考场监控视频图像数据中考生头顶部头发区域定位的目标检测深度学习模型进行训练和测试,得到最终目标检测模型
步骤4:将考场监控视频初始图像数据输入到最终目标检测模型
进一步的,步骤1:对包含了不同考试场景、不同考生的大量考场监控视频图像数据进行基于考生头顶部头发区域的框选标记,具体方法为:对考场监控视频图像数据中的考生的头顶部头发区域进行基于考生耳朵显露情况及基于近似图像的方框标记。Further, step 1: carry out a frame selection mark based on the hair area on the top of the examinee's head for a large number of examination room surveillance video image data including different examination scenes and different candidates, and the specific method is: the examination room surveillance video image data. The hair area is box marked based on the exposure of the candidate's ears and based on the approximate image.
进一步的,对考场监控视频图像数据中的考生的头顶部头发区域进行基于考生耳朵显露情况方框标记,耳朵显露情况分为:两个耳朵显露,一个耳朵显露,没有显露耳朵。Further, the hair area on the top of the candidate's head in the monitoring video image data of the examination room is marked with a box based on the candidate's ear exposure. The ear exposure is divided into: two ears are exposed, one ear is exposed, and no ears are exposed.
进一步的,对考场监控视频图像数据中的考生的头顶部头发区域进行基于近似图像的方框标记,具体为生成的边框的水平和垂直边都平行于图像数据边缘。Further, the approximate image-based frame marking is performed on the hair area on the top of the examinee's head in the monitoring video image data of the examination room, specifically, the horizontal and vertical sides of the generated frame are parallel to the edge of the image data.
进一步的,视频图像数据中考生两个耳朵显露,则框选区域为:以边缘检测所得头发与额头交界的最低点为框选区域底部,以框选区域底部到边缘检测所得头发最顶部距离的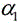


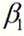
进一步的,视频图像数据中考生一个耳朵显露,则框选区域为:以头发与额头交界的最高点和最低点之间的中间值点为框选区域底部,以框选区域底部到头发最顶部距离的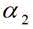


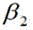
进一步的,视频图像数据中考生没有显露耳朵,以头发与额头交界的最高点为框选区域底部,以框选区域底部到头发最顶部的距离为框选高度,以额头在图像数据中显示的水平宽度为框选宽度,组成框选区域。Further, in the video image data, the candidates do not show their ears. The highest point at the junction of the hair and the forehead is the bottom of the frame selection area, the distance from the bottom of the frame selection area to the top of the hair is the frame selection height, and the forehead is displayed in the image data. The horizontal width is the width of the frame selection, forming the frame selection area.
进一步的,步骤2:对考场监控视频图像数据中的可能为头发的像素点进行筛选,得到预处理图像数据,具体方法为:首先对图像数据进行灰度化处理,得到灰度图像数据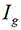
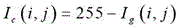




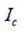





进一步的,步骤2:在预处理图像数据上进行基于SSD的深度学习目标检测,具体为:将二值检测结果图像数据
进一步的,步骤4:将考场监控视频初始图像数据输入到最终目标检测模型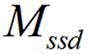


本发明解决了以下技术问题:The present invention solves the following technical problems:
1、提出一种根据考场监控视频图像数据中考生的耳朵可见情况,对考场监控视频图像数据进行基于考生头发区域的框选标记方法,提高了考生头发区域数据集的准确性和可靠性。1. This paper proposes a method of frame selection and marking based on the examinee's hair area for the examination room surveillance video image data according to the examinee's ear visibility in the examination room surveillance video image data, which improves the accuracy and reliability of the examinee's hair area data set.
2、通过对考场监控视频图像数据中的可能为头发的像素点进行基于高虚警率的目标检测的初步筛选,有效的提高了考生头发区域检测的准确性。2. Through the preliminary screening of the target detection based on the high false alarm rate for the pixels in the monitoring video image data of the examination room that may be hair, the accuracy of the examinee's hair area detection is effectively improved.
3、对考场监控视频图像数据的二值检测结果作为索引图像,以索引图像为基础进行锚框选择,在提高了考生头发区域检测的准确性的同时又降低了目标检测模型的复杂度。3. The binary detection result of the monitoring video image data of the examination room is used as the index image, and the anchor frame is selected based on the index image, which improves the accuracy of the examinee's hair area detection and reduces the complexity of the target detection model.
附图说明Description of drawings
图1为一种考场监控视频图像中考生定位方法流程图。Figure 1 is a flowchart of a method for locating candidates in a surveillance video image of an examination room.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,方法流程图如图1所示,包括以下步骤:The technical solutions in the embodiments of the present invention will be described clearly and completely below in conjunction with the accompanying drawings in the embodiments of the present invention. The flow chart of the method is shown in Figure 1 and includes the following steps:
一种考场监控视频图像中考生定位方法,包括:A method for locating candidates in a monitoring video image of an examination room, comprising:
步骤1:对包含了不同考试场景、不同考生的大量考场监控视频图像数据进行基于考生头顶部头发区域的框选标记,然后建立考场监控视频图像数据的考生头顶部头发区域数据集;Step 1: Make a frame selection mark based on the hair area on the top of the examinee's head for a large number of examination room surveillance video image data that includes different examination scenes and different candidates, and then establish a data set of the examinee's head hair area of the examination room surveillance video image data;
步骤2:建立针对考场监控视频图像数据中考生头顶部头发区域定位的目标检测深度学习模型,首先对考场监控视频图像数据中的可能为头发的像素点进行筛选,得到预处理图像数据,然后在预处理图像数据上进行基于SSD的深度学习目标检测;Step 2: Establish a target detection deep learning model for locating the hair area on the top of the examinee's head in the surveillance video image data of the examination room. First, screen the pixels that may be hair in the surveillance video image data of the examination room to obtain the preprocessed image data, and then in the Perform SSD-based deep learning target detection on preprocessed image data;
步骤3:将建立的考场监控视频图像数据的考生头顶部头发区域数据集按比例进行划分,分别生成训练数据集和测试数据集,对建立的针对考场监控视频图像数据中考生头顶部头发区域定位的目标检测深度学习模型进行训练和测试,得到最终目标检测模型
步骤4:将考场监控视频初始图像数据输入到最终目标检测模型
进一步的,步骤1:对包含了不同考试场景、不同考生的大量考场监控视频图像数据进行基于考生头顶部头发区域的框选标记,具体方法为:对考场监控视频图像数据中的考生的头顶部头发区域进行基于考生耳朵显露情况及基于近似图像的方框标记。Further, step 1: carry out a frame selection mark based on the hair area on the top of the examinee's head for a large number of examination room surveillance video image data including different examination scenes and different candidates, and the specific method is: the examination room surveillance video image data. The hair area is box marked based on the exposure of the candidate's ears and based on the approximate image.
进一步的,对考场监控视频图像数据中的考生的头顶部头发区域进行基于考生耳朵显露情况方框标记,耳朵显露情况分为:两个耳朵显露,一个耳朵显露,没有显露耳朵。Further, the hair area on the top of the candidate's head in the monitoring video image data of the examination room is marked with a box based on the candidate's ear exposure. The ear exposure is divided into: two ears are exposed, one ear is exposed, and no ears are exposed.
进一步的,对考场监控视频图像数据中的考生的头顶部头发区域进行基于近似图像的方框标记,具体为生成的边框的水平和垂直边都平行于图像数据边缘。Further, the approximate image-based frame marking is performed on the hair area on the top of the examinee's head in the monitoring video image data of the examination room, specifically, the horizontal and vertical sides of the generated frame are parallel to the edge of the image data.
进一步的,视频图像数据中考生两个耳朵显露,则框选区域为:以边缘检测所得头发与额头交界的最低点为框选区域底部,以框选区域底部到边缘检测所得头发最顶部距离的
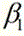
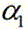

进一步的,视频图像数据中考生一个耳朵显露,则框选区域为:以头发与额头交界的最高点和最低点之间的中间值点为框选区域底部,以框选区域底部到头发最顶部距离的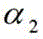



进一步的,视频图像数据中考生没有显露耳朵,以头发与额头交界的最高点为框选区域底部,以框选区域底部到头发最顶部的距离为框选高度,以额头在图像数据中显示的水平宽度为框选宽度,组成框选区域。Further, in the video image data, the candidates do not show their ears. The highest point at the junction of the hair and the forehead is the bottom of the frame selection area, the distance from the bottom of the frame selection area to the top of the hair is the frame selection height, and the forehead is displayed in the image data. The horizontal width is the width of the frame selection, forming the frame selection area.
进一步的,步骤2:对考场监控视频图像数据中的可能为头发的像素点进行筛选,得到预处理图像数据,具体方法为:首先对图像数据进行灰度化处理,得到灰度图像数据


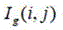



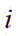


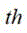

进一步的,步骤2:在预处理图像数据上进行基于SSD的深度学习目标检测,具体为:将二值检测结果图像数据
进一步的,步骤4:将考场监控视频初始图像数据输入到最终目标检测模型


显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的其他实施例,都属于本发明保护的范围。Obviously, the described embodiments are only some, but not all, embodiments of the present invention. Based on the embodiments of the present invention, other embodiments obtained by persons of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
Claims (10)


























Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210629393.7A CN114708543B (en) | 2022-06-06 | 2022-06-06 | A method for locating candidates in surveillance video images of examination room |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210629393.7A CN114708543B (en) | 2022-06-06 | 2022-06-06 | A method for locating candidates in surveillance video images of examination room |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114708543A true CN114708543A (en) | 2022-07-05 |
| CN114708543B CN114708543B (en) | 2022-08-30 |
Family
ID=82177605
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210629393.7A Active CN114708543B (en) | 2022-06-06 | 2022-06-06 | A method for locating candidates in surveillance video images of examination room |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114708543B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116310806A (en) * | 2023-02-28 | 2023-06-23 | 北京理工大学珠海学院 | An integrated management system and method for smart agriculture based on image recognition |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5430809A (en) * | 1992-07-10 | 1995-07-04 | Sony Corporation | Human face tracking system |
| CN105678213A (en) * | 2015-12-20 | 2016-06-15 | 华南理工大学 | Dual-mode masked man event automatic detection method based on video characteristic statistics |
| CN106991360A (en) * | 2016-01-20 | 2017-07-28 | 腾讯科技(深圳)有限公司 | Face identification method and face identification system |
| CN107451555A (en) * | 2017-07-27 | 2017-12-08 | 安徽慧视金瞳科技有限公司 | A kind of hair based on gradient direction divides to determination methods |
| CN108260918A (en) * | 2018-02-09 | 2018-07-10 | 武汉技兴科技有限公司 | A kind of human hair information collecting method, device and intelligent clipping device |
| CN109711377A (en) * | 2018-12-30 | 2019-05-03 | 陕西师范大学 | A method of positioning and counting candidates in a single-frame image of standardized examination room monitoring |
| CN112686965A (en) * | 2020-12-25 | 2021-04-20 | 百果园技术(新加坡)有限公司 | Skin color detection method, device, mobile terminal and storage medium |
-
2022
- 2022-06-06 CN CN202210629393.7A patent/CN114708543B/en active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5430809A (en) * | 1992-07-10 | 1995-07-04 | Sony Corporation | Human face tracking system |
| CN105678213A (en) * | 2015-12-20 | 2016-06-15 | 华南理工大学 | Dual-mode masked man event automatic detection method based on video characteristic statistics |
| CN106991360A (en) * | 2016-01-20 | 2017-07-28 | 腾讯科技(深圳)有限公司 | Face identification method and face identification system |
| CN107451555A (en) * | 2017-07-27 | 2017-12-08 | 安徽慧视金瞳科技有限公司 | A kind of hair based on gradient direction divides to determination methods |
| CN108260918A (en) * | 2018-02-09 | 2018-07-10 | 武汉技兴科技有限公司 | A kind of human hair information collecting method, device and intelligent clipping device |
| CN109711377A (en) * | 2018-12-30 | 2019-05-03 | 陕西师范大学 | A method of positioning and counting candidates in a single-frame image of standardized examination room monitoring |
| CN112686965A (en) * | 2020-12-25 | 2021-04-20 | 百果园技术(新加坡)有限公司 | Skin color detection method, device, mobile terminal and storage medium |
Non-Patent Citations (2)
| Title |
|---|
| XIAOFEI PENG等: "Teaching Assistant and Class Attendance Analysis Using Surveillance Camera", 《IFTC 2018: DIGITAL TV AND MULTIMEDIA COMMUNICATION》 * |
| 王红梅: "基于视频的人体检测与计数技术研究", 《中国优秀博硕士学位论文全文数据库(硕士)信息科技辑》 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116310806A (en) * | 2023-02-28 | 2023-06-23 | 北京理工大学珠海学院 | An integrated management system and method for smart agriculture based on image recognition |
| CN116310806B (en) * | 2023-02-28 | 2023-08-29 | 北京理工大学珠海学院 | Intelligent agriculture integrated management system and method based on image recognition |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114708543B (en) | 2022-08-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110705583B (en) | Cell detection model training method, device, computer equipment and storage medium | |
| CN111260645B (en) | Tampered image detection method and system based on block classification deep learning | |
| CN112712273B (en) | Handwriting Chinese character aesthetic degree judging method based on skeleton similarity | |
| CN109635875A (en) | A kind of end-to-end network interface detection method based on deep learning | |
| CN101615292B (en) | Accurate positioning method for human eye on the basis of gray gradation information | |
| CN110689000B (en) | Vehicle license plate recognition method based on license plate sample generated in complex environment | |
| CN105869085A (en) | Transcript inputting system and method for processing images | |
| CN111753873A (en) | An image detection method and device | |
| CN108257125B (en) | Depth image quality non-reference evaluation method based on natural scene statistics | |
| CN116433651B (en) | Small sample panel defect detection method, system, equipment and storage medium | |
| CN110400293A (en) | A no-reference image quality assessment method based on deep forest classification | |
| CN106340000A (en) | Bone age assessment method | |
| CN106960433B (en) | A full-reference sonar image quality evaluation method based on image entropy and edge | |
| CN113012167A (en) | Combined segmentation method for cell nucleus and cytoplasm | |
| CN116596877B (en) | A Bone Age Intelligent Assessment Method Based on Attention Mechanism | |
| CN102081742B (en) | Method for automatically evaluating writing ability | |
| CN115345858A (en) | Method, system and terminal device for evaluating quality of echocardiogram | |
| CN111126330A (en) | A method for locating the center of the pupil membrane and a method for detecting the fatigue degree of students listening to a lecture | |
| CN104751160B (en) | Galactophore image processing method based on sparse autocoding depth network | |
| CN108764029A (en) | Model intelligence inspection method | |
| CN114708543A (en) | Examination student positioning method in examination room monitoring video image | |
| CN120450982B (en) | Lung cancer image enhancement method based on generative adversarial network | |
| CN115311447A (en) | Pointer instrument indicating number identification method based on deep convolutional neural network | |
| KR20200005853A (en) | Method and System for People Count based on Deep Learning | |
| CN116708759A (en) | Method for detecting abnormal deflection of camera |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |