CN114495971A - A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks - Google Patents
A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks Download PDFInfo
- Publication number
- CN114495971A CN114495971A CN202210182933.1A CN202210182933A CN114495971A CN 114495971 A CN114495971 A CN 114495971A CN 202210182933 A CN202210182933 A CN 202210182933A CN 114495971 A CN114495971 A CN 114495971A
- Authority
- CN
- China
- Prior art keywords
- neural network
- convolution
- fpga
- data
- ced
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000013528 artificial neural network Methods 0.000 title claims abstract description 78
- 238000000034 method Methods 0.000 title claims abstract description 19
- 238000009825 accumulation Methods 0.000 claims description 21
- 238000003860 storage Methods 0.000 claims description 13
- 238000012545 processing Methods 0.000 abstract description 15
- 239000010410 layer Substances 0.000 description 16
- 238000010586 diagram Methods 0.000 description 13
- 238000005516 engineering process Methods 0.000 description 6
- 230000007704 transition Effects 0.000 description 6
- 230000009467 reduction Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 3
- 239000002356 single layer Substances 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000001133 acceleration Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 241001442055 Vipera berus Species 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000013527 convolutional neural network Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000010295 mobile communication Methods 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Quality & Reliability (AREA)
- Complex Calculations (AREA)
Abstract
本发明公开了一种采用嵌入式硬件运行神经网络的语音增强方法,涉及语音信号处理领域,包括:通过语音传感器采集语音数据,并通过FPGA对语音数据进行傅里叶变换,得到语谱图数据;采用FPGA的逻辑单元构建R‑CED神经网络,得到R‑CED神经网络数字逻辑子系统;通过R‑CED神经网络数字逻辑子系统对语谱图数据进行降噪;通过FPGA对降噪后的语谱图数据进行时域还原,得到语音增强数据。本发明基于嵌入式硬件平台,通过FPGA构建实现神经网络,充分利用FPGA数字逻辑门阵列的并行性,相对于基于GPU、CPU等处理器的神经网络运行方式,大大提高了处理速度,保障了语音增强处理的实时性。

The invention discloses a speech enhancement method using embedded hardware to run a neural network, and relates to the field of speech signal processing. ;Construct the R‑CED neural network with the logic unit of FPGA, and obtain the R‑CED neural network digital logic subsystem; denoise the spectrogram data through the R‑CED neural network digital logic subsystem; use the FPGA to denoise the denoised The spectrogram data is restored in time domain to obtain speech enhancement data. The invention is based on an embedded hardware platform, constructs a neural network through FPGA, makes full use of the parallelism of the FPGA digital logic gate array, and greatly improves the processing speed compared with the neural network operation mode based on GPU, CPU and other processors, and guarantees voice Enhance real-time processing.
Description
技术领域technical field
本发明涉及语音信号处理领域,具体涉及一种采用嵌入式硬件运行神经网络的语音增强方法。The invention relates to the field of speech signal processing, in particular to a speech enhancement method using embedded hardware to run a neural network.
背景技术Background technique
语音增强技术指当纯净目标语音信号在复杂环境中被一种或多种噪声干扰甚至淹没后,通过一定的降噪算法抑制和降低噪声的影响,尽可能地将纯净目标语音提取出来的技术。其被广泛应用于移动通信、人机交互、军事通信等领域,用于消除和减弱各种噪声带来的负面影响。Speech enhancement technology refers to the technology that when the pure target speech signal is disturbed or even submerged by one or more kinds of noise in a complex environment, the influence of noise is suppressed and reduced by a certain noise reduction algorithm, and the pure target speech is extracted as much as possible. It is widely used in mobile communications, human-computer interaction, military communications and other fields to eliminate and reduce the negative effects of various noises.
随着物联网技术的发展,语音处理设备朝着智能化、终端化的方向快速发展,语音增强技术被大量应用于硬件平台。但是,物联网技术中的云计算模型,由于大量使用网络带宽,且不能实时反馈的原因,不适用与终端设备。为补充云计算的劣势,边缘计算模式应运而生。With the development of Internet of Things technology, voice processing equipment is developing rapidly in the direction of intelligence and terminalization, and voice enhancement technology is widely used in hardware platforms. However, the cloud computing model in the Internet of Things technology is not applicable to terminal devices due to the large use of network bandwidth and the inability to provide real-time feedback. In order to supplement the disadvantages of cloud computing, the edge computing model came into being.
边缘计算选择将运算任务分散到靠近数据源的轻量级设备中,在本地对部分数据直接进行采集和运算,实时反馈给用户。而随着半导体制造业工艺水平的提升,FPGA(FieldProgrammable Gate Array,FPGA)这类半定制集成电路芯片,以及片上系统SoC(system onchip,SoC)FPGA,为边缘计算提供了应用场景。虽然此类嵌入式设备具有本地采集、本地计算的优势,但其传输带宽、存储资源和计算资源的限制也阻碍了其大规模应用的发展。Edge computing chooses to distribute computing tasks to lightweight devices close to the data source, directly collect and operate some data locally, and feed back to users in real time. With the improvement of the semiconductor manufacturing technology level, semi-custom integrated circuit chips such as FPGA (Field Programmable Gate Array, FPGA), and system on chip (system on chip, SoC) FPGA provide application scenarios for edge computing. Although such embedded devices have the advantages of local acquisition and local computing, the limitations of their transmission bandwidth, storage resources and computing resources also hinder the development of their large-scale applications.
而现有语音增强算法,通常基于机器学习技术,例如生成对抗网络(GenerativeAdversarial Networks,GAN)、自编码器结构的GAN和长短记忆(Long Short-Term Memory,LSTM)等网络模型。这些算法大部分都采用了结构各异且层数较深的神经网络模型,用较高的计算代价换取了部分性能的提升,导致这些复杂的神经网络,难以在资源有限的硬件平台实现。Existing speech enhancement algorithms are usually based on machine learning techniques, such as Generative Adversarial Networks (GAN), GAN with autoencoder structure, and network models such as Long Short-Term Memory (LSTM). Most of these algorithms use neural network models with different structures and deep layers, which exchange higher computing costs for some performance improvements, making these complex neural networks difficult to implement on resource-limited hardware platforms.
发明内容SUMMARY OF THE INVENTION
针对现有技术中的上述不足,本发明提供的一种采用嵌入式硬件运行神经网络的语音增强方法解决了目前基于神经网络的语音增强系统难以在资源有限的嵌入式硬件平台上实现的问题。In view of the above deficiencies in the prior art, the present invention provides a voice enhancement method using embedded hardware to run a neural network, which solves the problem that the current neural network-based voice enhancement system is difficult to implement on an embedded hardware platform with limited resources.
为了达到上述发明目的,本发明采用的技术方案为:In order to achieve the above-mentioned purpose of the invention, the technical scheme adopted in the present invention is:
一种采用嵌入式硬件运行神经网络的语音增强方法,包括以下步骤:A speech enhancement method using embedded hardware to run a neural network, comprising the following steps:
S1、通过语音传感器采集语音数据,并通过FPGA对语音数据进行傅里叶变换,得到语谱图数据;S1. Collect voice data through a voice sensor, and perform Fourier transform on the voice data through an FPGA to obtain spectrogram data;
S2、采用FPGA的逻辑单元构建R-CED神经网络,得到R-CED神经网络数字逻辑子系统;S2. Construct the R-CED neural network by using the logic unit of the FPGA, and obtain the R-CED neural network digital logic subsystem;
S3、通过R-CED神经网络数字逻辑子系统对语谱图数据进行降噪;S3, denoise the spectrogram data through the R-CED neural network digital logic subsystem;
S4、通过FPGA对降噪后的语谱图数据进行时域还原,得到语音增强数据。S4, performing time domain restoration on the noise-reduced spectrogram data through the FPGA to obtain speech enhancement data.
进一步地,所述步骤S1中,通过Zynq7020型硬件平台FPGA的可编程逻辑PL端对语音数据进行傅里叶变换;Further, in the step S1, Fourier transform is performed on the voice data through the programmable logic PL end of the Zynq7020 type hardware platform FPGA;
所述步骤S2中,采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建R-CED神经网络;In described step S2, adopt the logic unit in the programmable logic PL end of Zynq7020 hardware platform FPGA to construct R-CED neural network;
所述步骤S4中,通过Zynq7020型硬件平台FPGA的处理器系统PS端对降噪后的语谱图数据进行时域还原。In the step S4, time domain restoration is performed on the noise-reduced spectrogram data through the PS end of the processor system of the Zynq7020 hardware platform FPGA.
进一步地,所述步骤S2包括以下分步骤:Further, the step S2 includes the following sub-steps:
S21、采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建神经网络卷积模块;S21. Construct a neural network convolution module by using the logic unit in the programmable logic PL end of the Zynq7020 hardware platform FPGA;
S22、通过神经网络卷积单元搭建R-CED神经网络数字逻辑子系统;S22. Build an R-CED neural network digital logic subsystem through a neural network convolution unit;
S23、采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建神经网络卷积参数存储模块;S23, using the logic unit in the programmable logic PL end of the Zynq7020 hardware platform FPGA to construct a neural network convolution parameter storage module;
S24、通过神经网络卷积参数存储模块储存R-CED神经网络数字逻辑子系统中各个卷积核模块的参数。S24, store the parameters of each convolution kernel module in the R-CED neural network digital logic subsystem through the neural network convolution parameter storage module.
进一步地,所述步骤S21构建的神经网络卷积模块包括:移位寄存器、至少一个乘法组单元、卷积控制单元和累加单元;Further, the neural network convolution module constructed in the step S21 includes: a shift register, at least one multiplication group unit, a convolution control unit and an accumulation unit;
所述移位寄存器用于通过移位操作,按FPGA机器时钟周期,将输入谱图数据和神经网络卷积参数存储模块内存储的卷积运算权重参数搬移至卷积运算模块;The shift register is used to move the input spectrogram data and the convolution operation weight parameters stored in the neural network convolution parameter storage module to the convolution operation module through a shift operation according to the FPGA machine clock cycle;
所述乘法组单元用于对输入谱图数据和卷积运算权重参数进行乘法运算,得到卷积运算结果;The multiplication group unit is used for multiplying the input spectrogram data and the weight parameter of the convolution operation to obtain the result of the convolution operation;
所述卷积控制单元用于通过预设的卷积控制有限状态机对移位寄存器、乘法组单元和累加单元进行时序控制,以实现卷积运算;The convolution control unit is used to perform timing control on the shift register, the multiplication group unit and the accumulation unit through the preset convolution control finite state machine, so as to realize the convolution operation;
所述累加单元用于对各个卷积控制单元的运算结果进行累加。The accumulating unit is used for accumulating the operation results of each convolution control unit.
进一步地,所述R-CED神经网络数字逻辑子系统还包括输入谱图数据填充模块,用于采用full填充方式,在神经网络卷积模块对输入谱图数据进行卷积运算地过程中,进行padding填0操作。Further, the R-CED neural network digital logic subsystem also includes an input spectrogram data filling module, which is used for using a full filling method to perform convolution operations on the input spectrogram data by the neural network convolution module. Padding fills 0 operation.
本发明的有益效果为:The beneficial effects of the present invention are:
1)本发明基于嵌入式硬件平台,通过FPGA构建实现神经网络,充分利用FPGA数字逻辑门阵列的并行性,相对于基于GPU、CPU等处理器的神经网络运行方式,大大提高了处理速度,保障了语音增强处理的实时性。1) The present invention is based on an embedded hardware platform, constructs a neural network through an FPGA, makes full use of the parallelism of the FPGA digital logic gate array, and greatly improves the processing speed compared to the neural network operation mode based on processors such as GPU and CPU, guaranteeing Real-time speech enhancement processing.
2)使用了内置可编程逻辑PL端和处理器系统PS端的Zynq7020型硬件平台FPGA,充分利用可编程逻辑PL易于构建并行数据处理的数字逻辑模块和处理器系统PS易于执行复杂串行程序指令的差异性特点,分工执行神经网络降噪和频域信号转时域的操作。2) Using the Zynq7020 hardware platform FPGA with built-in programmable logic PL side and processor system PS side, making full use of programmable logic PL to easily build digital logic modules for parallel data processing and processor system PS to easily execute complex serial program instructions Differential characteristics, the division of labor performs the operation of neural network noise reduction and frequency domain signal conversion to time domain.
3)针对的Zynq7020型硬件平台FPGA的特性,设计了R-CED神经网络的基础结构-神经网络卷积模块,将卷积的多循环式串行运算,转换为了数字逻辑电路特有的有限状态机控制的流水线式并行运算,有效提成了R-CED神经网络的处理速度。3) According to the characteristics of Zynq7020 hardware platform FPGA, the basic structure of R-CED neural network-neural network convolution module is designed, and the multi-loop serial operation of convolution is converted into a finite state machine unique to digital logic circuits. The controlled pipeline parallel operation effectively improves the processing speed of the R-CED neural network.
附图说明Description of drawings
图1为本发明实施例提供的一种采用嵌入式硬件运行神经网络的语音增强方法的流程图;1 is a flowchart of a speech enhancement method using embedded hardware to run a neural network provided by an embodiment of the present invention;
图2为本发明实施例Zynq7020型硬件平台FPGA结构示意图;2 is a schematic structural diagram of a Zynq7020 hardware platform FPGA according to an embodiment of the present invention;
图3为神经网络卷积模块的软件程序实现方式示意图;3 is a schematic diagram of a software program implementation of a neural network convolution module;
图4为本发明实施例提供的神经网络卷积模块的结构图;4 is a structural diagram of a neural network convolution module provided by an embodiment of the present invention;
图5为本发明实施例提供的移位寄存器的原理示意图;5 is a schematic diagram of the principle of a shift register provided by an embodiment of the present invention;
图6为本发明实施例提供的累加单元的行累加结构图;6 is a structural diagram of a row accumulation of an accumulation unit provided by an embodiment of the present invention;
图7为本发明实施例提供的累加单元的列累加结构图;7 is a structural diagram of a column accumulation of an accumulation unit provided by an embodiment of the present invention;
图8为本发明实施例的层状态转换图;FIG. 8 is a layer state transition diagram of an embodiment of the present invention;
图9为本发明实施例的操作状态转换图;9 is an operation state transition diagram of an embodiment of the present invention;
图10为本发明实施例的数据搬运状态转换图;FIG. 10 is a data transfer state transition diagram according to an embodiment of the present invention;
图11为本发明实施例的填充操作状态转换图;11 is a state transition diagram of a filling operation according to an embodiment of the present invention;
图12为本发明实施例提供的神经网络卷积参数存储模块的原理示意图。FIG. 12 is a schematic diagram of the principle of a neural network convolution parameter storage module provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。The specific embodiments of the present invention are described below to facilitate those skilled in the art to understand the present invention, but it should be clear that the present invention is not limited to the scope of the specific embodiments. For those of ordinary skill in the art, as long as various changes Such changes are obvious within the spirit and scope of the present invention as defined and determined by the appended claims, and all inventions and creations utilizing the inventive concept are within the scope of protection.
如图1所示,在本发明的一个实施例中,一种采用嵌入式硬件运行神经网络的语音增强方法,包括以下步骤:As shown in Figure 1, in one embodiment of the present invention, a speech enhancement method using embedded hardware to run a neural network includes the following steps:
S1、通过Zynq7020型硬件平台FPGA的可编程逻辑PL端对语音数据进行傅里叶变换,得到语谱图数据。S1. Fourier transform is performed on the speech data through the programmable logic PL end of the Zynq7020 hardware platform FPGA to obtain spectrogram data.
S2、采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建R-CED神经网络,得到R-CED神经网络数字逻辑子系统。S2. The R-CED neural network is constructed by using the logic unit in the programmable logic PL end of the Zynq7020 hardware platform FPGA, and the R-CED neural network digital logic subsystem is obtained.
本实施例Zynq7020型硬件平台FPGA的结构如图2所示,可编程逻辑PL端提供了可用硬件描述语言(例如Verilog HDL)控制连接关系的逻辑门阵列,处理器系统PS端提供了可运行软件程序的ARM处理器。图2中,虚线表示控制信号的流向,实线表示数据的流向。The structure of the Zynq7020 hardware platform FPGA in this embodiment is shown in Figure 2. The programmable logic PL side provides a logic gate array that can use a hardware description language (such as Verilog HDL) to control the connection relationship, and the processor system PS side provides runnable software program for the ARM processor. In FIG. 2 , the broken line indicates the flow of the control signal, and the solid line indicates the flow of the data.
R-CED神经网络数字逻辑子系统的核心是FPGA实现的卷积CNN。本实施例的步骤S2包括以下分步骤:The core of the R-CED neural network digital logic subsystem is the convolutional CNN implemented by FPGA. Step S2 of this embodiment includes the following sub-steps:
S21、采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建神经网络卷积模块。S21, using the logic unit in the programmable logic PL end of the Zynq7020 hardware platform FPGA to construct a neural network convolution module.
通常,神经网络卷积模块由软件程序实现,其程序如图3所示,卷积运算可视为乘法的累加,运算包括了输出特征图通道循环、输入特征图通道循环、输入特征图循环和卷积核循环。Usually, the neural network convolution module is implemented by a software program. The program is shown in Figure 3. The convolution operation can be regarded as the accumulation of multiplication. The operation includes output feature map channel loop, input feature map channel loop, input feature map loop and Convolution kernel loop.
本发明的核心思想是用硬件化的数字逻辑门电路实现卷积运算的并行化处理,达到其硬件加速的效果。The core idea of the present invention is to realize the parallel processing of the convolution operation by using the hardware-based digital logic gate circuit to achieve the effect of hardware acceleration.
根据并行化分析结果,卷积运算中,各层运算之间串行,单层运算并行,因此加速设计针对单层运算进行。According to the results of the parallelization analysis, in the convolution operation, the operations of each layer are serialized, and the single-layer operation is parallel, so the acceleration design is carried out for the single-layer operation.
表1 各个神经网络卷积模块参数Table 1 Parameters of each neural network convolution module

如图3中的伪代码所示,单层运算中包含四个嵌套的循环,针对其不同特点,采用不同的展开策略,以加速卷积运算:As shown in the pseudocode in Figure 3, the single-layer operation contains four nested loops. According to their different characteristics, different expansion strategies are adopted to speed up the convolution operation:
卷积核循环:全部展开,用寄存器存储单个卷积核运算所需的全部特征图数据和卷积核数据;各个神经网络卷积模块参数如表1所示。Convolution kernel cycle: All are expanded, and registers are used to store all feature map data and convolution kernel data required for a single convolution kernel operation; the parameters of each neural network convolution module are shown in Table 1.
输入特征图循环:不展开,由于系统中卷积运算的数据来源于FPGA片内的RAM,因此无法同时输入多个地址获得卷积核在滑动过程中对应的多个不同卷积窗口的特征图数据;Input feature map cycle: do not expand, because the data of the convolution operation in the system comes from the RAM on the FPGA chip, it is impossible to input multiple addresses at the same time to obtain the feature maps of multiple different convolution windows corresponding to the convolution kernel during the sliding process data;
输入特征图通道循环:部分展开,将特征图和权重按照通道划分为4个运算通道,在运算通道内,输入特征图的读取和运算是串行的,而在运算通道间是并行的;Input feature map channel loop: Partially expand, divide the feature map and weight into 4 operation channels according to the channel, in the operation channel, the reading and operation of the input feature map are serial, while between the operation channels are parallel;
输出特征图通道循环:部分展开,将权重按照输出特征图通道划分为4个部分,综合按照输入特征图通道循环展开的方式,每个部分都包含4个运算通道,共有16个运算通道。Output feature map channel loop: Partial expansion, the weight is divided into 4 parts according to the output feature map channel, comprehensively according to the input feature map channel loop expansion method, each part contains 4 computing channels, a total of 16 computing channels.
如图4所示,本实施例构建的神经网络卷积模块包括:移位寄存器、至少一个乘法组单元、卷积控制单元和累加单元。As shown in FIG. 4 , the neural network convolution module constructed in this embodiment includes: a shift register, at least one multiplication group unit, a convolution control unit, and an accumulation unit.
移位寄存器用于通过移位操作,按FPGA机器时钟周期,将输入谱图数据和神经网络卷积参数存储模块内存储的卷积运算权重参数搬移至卷积运算模块。其工作原理如图5所示。The shift register is used to move the input spectrogram data and the convolution operation weight parameters stored in the neural network convolution parameter storage module to the convolution operation module through the shift operation according to the FPGA machine clock cycle. Its working principle is shown in Figure 5.
若所有卷积层最大窗口为I×J,则移位寄存器个数为J-1,深度为I,权重输入为单个寄存器。移位寄存器无需存满I×J个数据,在I×(J-1)+1时即可开始向REG寄存器中搬运数据。图5以最大卷积窗口5×5,当前卷积窗口4×4,权重数据0-15为例。虚线框内为当前卷积窗口所占用位置,如箭头所示,将权重数据存入单个寄存器,每个时钟移位寄存器将有右侧地址数据向左搬运。左侧地址不仅输出数据,且存入上一个移位寄存器的指定地址中。If the maximum window of all convolutional layers is I × J, the number of shift registers is J-1, the depth is I, and the weight input is a single register. The shift register does not need to be full of I×J data, and the data can be transferred to the REG register when I×(J-1)+1. Figure 5 takes the
移位寄存器每个时钟输出数据到REG寄存器中,REG寄存器内部每个时钟按箭头方向对数据搬移,指导在有效位置获得卷积窗口的所有权重数据集。Each clock of the shift register outputs data to the REG register, and each clock inside the REG register moves the data in the direction of the arrow, instructing to obtain all the weight data sets of the convolution window at the effective position.
乘法组单元用于对输入谱图数据和卷积运算权重参数进行乘法运算,得到卷积运算结果。The multiplication group unit is used to multiply the input spectrogram data and the weight parameter of the convolution operation to obtain the result of the convolution operation.
本实施例的乘法组单元采用流水线设计,每个时钟都会输出卷积窗口里全部元素的乘积结果。The multiplication group unit in this embodiment adopts a pipeline design, and each clock outputs the product result of all elements in the convolution window.
累加单元用于对各个卷积控制单元的运算结果进行累加。针对硬件特点,将累加过程分为多级累加的加法器树结构,每级运算的中间结果用寄存器缓存,形成流水线结构。The accumulation unit is used to accumulate the operation results of each convolution control unit. According to the hardware characteristics, the accumulation process is divided into a multi-level accumulation adder tree structure, and the intermediate results of each level of operation are cached in registers to form a pipeline structure.
本实施例的累加单元包括Add_col(行累加)和Add_row(列累加)两部分,如图6和图7所示。Add_col模块将并行同步输入的4路数据对应累加后输出,采用流水线处理计算,无需额外参数配置。Add_row模块累加数据为串行输入,第一帧数据用RAM缓存。累加中,按地址将RAM中前一次累加的结果读出,并在相加后写入原地址。完成最后一帧累加后,加上bias偏移值。数据输入完成后,得到一帧输出特征图,送入后级模块。The accumulation unit of this embodiment includes two parts, Add_col (row accumulation) and Add_row (column accumulation), as shown in FIG. 6 and FIG. 7 . The Add_col module accumulates and outputs the corresponding 4-channel data input in parallel and synchronously, and adopts the pipeline processing calculation without additional parameter configuration. The accumulated data of the Add_row module is serial input, and the first frame data is buffered in RAM. During the accumulation, read out the result of the previous accumulation in the RAM according to the address, and write the original address after the addition. After completing the accumulation of the last frame, add the bias offset value. After the data input is completed, a frame of output feature map is obtained and sent to the subsequent module.
卷积控制单元用于通过预设的卷积控制有限状态机对移位寄存器、乘法组单元和累加单元进行时序控制,以实现卷积运算。The convolution control unit is used to perform sequential control on the shift register, the multiplication group unit and the accumulation unit through the preset convolution control finite state machine, so as to realize the convolution operation.
卷积控制单元包含两类输入:总控制器指令ctrl_cmd和输入标志信号flag_in。输出包括三类:参数配置信号config,输出标志信号flag_out和读数据信号Rd。The convolution control unit contains two types of inputs: the overall controller command ctrl_cmd and the input flag signal flag_in. The output includes three types: parameter configuration signal config, output flag signal flag_out and read data signal Rd.
卷积控制状态机包含三个嵌套的状态机,最外层为层状态,其次是操作状态,最内层为数据搬运状态。各个状态机及状态说明如表2所示。The convolution control state machine contains three nested state machines, the outermost layer is the layer state, followed by the operation state, and the innermost layer is the data handling state. The state machines and state descriptions are shown in Table 2.
层状态按卷积层划分,在进入第0层运算前完成信号初始化,添加准备状态IDLE。层状态机转换图如图8所示。The layer state is divided according to the convolution layer, the signal initialization is completed before entering the 0th layer operation, and the preparation state IDLE is added. The layer state machine transition diagram is shown in Figure 8.
IDLE状态内完成卷积运算相关信号初始化,LAYER0-LAYER15状态内完成第0层到第15层的卷积运算。The convolution operation related signal initialization is completed in the IDLE state, and the convolution operation from the 0th layer to the 15th layer is completed in the LAYER0-LAYER15 state.
表2卷积控制状态机的组成及说明Table 2 Composition and description of convolution control state machine

根据Conv_ctrl模块的输出标志信号,up_fm、up_w、get_fm,PS可以判断何时向卷积运算模块输入权重数据和特征图数据,以及何时从卷积模块输出缓存内读取数据。According to the output flag signals of the Conv_ctrl module, up_fm, up_w, get_fm, PS can determine when to input weight data and feature map data to the convolution operation module, and when to read data from the output buffer of the convolution module.
操作状态如图9所示。在CONFIG状态内,主要完成对相关模块的参数配置。The operating state is shown in Figure 9. In the CONFIG state, the parameter configuration of related modules is mainly completed.
CAL状态内,确定读取权重核特征图数据的实际,以及记录已完成运算的卷积核个数。In the CAL state, determine the actual reading of the weight kernel feature map data, and record the number of convolution kernels that have completed operations.
DM状态内,产生数据更新的标志信号,以及记录已经运算完成的卷积核个数。In the DM state, a flag signal for data update is generated, and the number of convolution kernels that have been calculated is recorded.
数据搬运状态如图10所示。The data transfer status is shown in Figure 10.
数据搬运状态为层状态DM中的子状态。根据不同的数据搬运需求分别为:等待状态WAIT、搬运特征图状态MOVE_M、搬运权重和特征图状态MOVE_MW、搬运下一次数据状态MOVE_NEXT。The data transfer state is a sub-state of the layer state DM. According to different data handling requirements, they are: waiting state WAIT, handling feature map state MOVE_M, handling weight and feature map state MOVE_MW, and handling next data state MOVE_NEXT.
S22、通过神经网络卷积单元搭建R-CED神经网络数字逻辑子系统。S22. Build an R-CED neural network digital logic subsystem through a neural network convolution unit.
R-CED神经网络数字逻辑子系统还包括输入谱图数据填充模块,用于采用full填充方式,在神经网络卷积模块对输入谱图数据进行卷积运算地过程中,进行padding填0操作。The R-CED neural network digital logic subsystem also includes an input spectrogram data padding module, which is used to use the full padding method to perform padding filling 0 operations during the convolution operation of the input spectrogram data by the neural network convolution module.
填充模块执行三个步骤:Populating the module performs three steps:
A1、在原始特征图写入OutputRAM前,先向其预留的空间内写入对应个数的0;A1. Before writing the original feature map to OutputRAM, write the corresponding number of 0s into the reserved space;
A2、原始特征图写入期间,在每行数据写入完成后,再写入对应个数的0;A2. During the writing of the original feature map, after each line of data is written, write the corresponding number of 0s;
A3、一张特征图写入完成后,继续写入对应个数的0。、A3. After a feature map is written, continue to write the corresponding number of 0s. ,
填充模块的控制采用了填充操作状态机,其转换图如图11所示。The control of the filling module adopts the filling operation state machine, and its transition diagram is shown in Figure 11.
填充操作状态机包含五个状态:IDLE、UP_ROW、MAP_ROW、PAD0、DOWN_ROW。各个状态的具体含义如表3所示。The fill operation state machine contains five states: IDLE, UP_ROW, MAP_ROW, PAD0, DOWN_ROW. The specific meaning of each state is shown in Table 3.
表3 填充操作状态机的组成及说明Table 3 Composition and description of filling operation state machine

S23、采用Zynq7020型硬件平台FPGA的可编程逻辑PL端内的逻辑单元构建神经网络卷积参数存储模块。S23, using the logic unit in the programmable logic PL end of the Zynq7020 hardware platform FPGA to construct a neural network convolution parameter storage module.
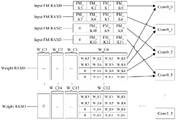
S24、通过神经网络卷积参数存储模块储存R-CED神经网络数字逻辑子系统中各个卷积核模块的参数。S24, store the parameters of each convolution kernel module in the R-CED neural network digital logic subsystem through the neural network convolution parameter storage module.
本实施例中,神经网络卷积参数存储模块的设计如图12所示。对于14通道的卷积层而言FM_Kk(k=0,1,2,3,…)和W_Cc(c=0,1,2,3,…)分别表示第k,c通道的特征图和权重数据,由于4个RAM共有16个通道,因此多余通道填0;In this embodiment, the design of the neural network convolution parameter storage module is shown in FIG. 12 . For a 14-channel convolutional layer, FM_K k (k=0,1,2,3,…) and W_C c (c=0,1,2,3,…) represent the feature maps of the kth and c channels, respectively and weight data, since there are 16 channels in 4 RAMs, the redundant channels are filled with 0;
图中Convx1_x2(x1,x2=0,1,2,3)表示该卷积模块的输入来自第x1个权重RAM的x2个通道和第x2个输入特征图RAM,因此一共有16个卷积运算模块同时工作;各卷积层输入特征图缓存及搬运方案如表4所示。In the figure Convx1_x2(x1,x2=0,1,2,3) indicates that the input of the convolution module comes from the x2 channels of the x1 weight RAM and the x2 input feature map RAM, so there are a total of 16 convolution operations The modules work at the same time; the input feature map cache and handling scheme of each convolutional layer are shown in Table 4.
表4 神经网络卷积参数存储模块存储的各卷积模块输入特征图缓存及搬运方案Table 4 The input feature map cache and handling scheme of each convolution module stored in the neural network convolution parameter storage module

S3、通过R-CED神经网络数字逻辑子系统对语谱图数据进行降噪。S3. Noise reduction is performed on the spectrogram data through the R-CED neural network digital logic subsystem.
S4、通过Zynq7020型硬件平台FPGA的处理器系统PS端对降噪后的语谱图数据进行时域还原,得到语音增强数据。S4, performing time domain restoration on the noise-reduced spectrogram data through the processor system PS end of the Zynq7020 hardware platform FPGA to obtain speech enhancement data.
综上,本发明具有如下的有益效果:To sum up, the present invention has the following beneficial effects:
1)本发明基于嵌入式硬件平台,通过FPGA构建实现神经网络,充分利用FPGA数字逻辑门阵列的并行性,相对于基于GPU、CPU等处理器的神经网络运行方式,大大提高了处理速度,保障了语音增强处理的实时性。1) The present invention is based on an embedded hardware platform, constructs a neural network through an FPGA, makes full use of the parallelism of the FPGA digital logic gate array, and greatly improves the processing speed compared to the neural network operation mode based on processors such as GPU and CPU, guaranteeing Real-time speech enhancement processing.
2)使用了内置可编程逻辑PL端和处理器系统PS端的Zynq7020型硬件平台FPGA,充分利用可编程逻辑PL易于构建并行数据处理的数字逻辑模块和处理器系统PS易于执行复杂串行程序指令的差异性特点,分工执行神经网络降噪和频域信号转时域的操作。2) Using the Zynq7020 hardware platform FPGA with built-in programmable logic PL side and processor system PS side, making full use of programmable logic PL to easily build digital logic modules for parallel data processing and processor system PS to easily execute complex serial program instructions Differential characteristics, the division of labor performs the operation of neural network noise reduction and frequency domain signal conversion to time domain.
3)针对的Zynq7020型硬件平台FPGA的特性,设计了R-CED神经网络的基础结构-神经网络卷积模块,将卷积的多循环式串行运算,转换为了数字逻辑电路特有的有限状态机控制的流水线式并行运算,有效提成了R-CED神经网络的处理速度。3) According to the characteristics of Zynq7020 hardware platform FPGA, the basic structure of R-CED neural network-neural network convolution module is designed, and the multi-loop serial operation of convolution is converted into a finite state machine unique to digital logic circuits. The controlled pipeline parallel operation effectively improves the processing speed of the R-CED neural network.
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。In the present invention, the principles and implementations of the present invention are described by using specific embodiments, and the descriptions of the above embodiments are only used to help understand the method and the core idea of the present invention; The idea of the invention will have changes in the specific implementation and application scope. To sum up, the content of this specification should not be construed as a limitation to the present invention.
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。Those of ordinary skill in the art will appreciate that the embodiments described herein are intended to assist readers in understanding the principles of the present invention, and it should be understood that the scope of protection of the present invention is not limited to such specific statements and embodiments. Those skilled in the art can make various other specific modifications and combinations without departing from the essence of the present invention according to the technical teaching disclosed in the present invention, and these modifications and combinations still fall within the protection scope of the present invention.
Claims (5)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210182933.1A CN114495971A (en) | 2022-02-25 | 2022-02-25 | A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210182933.1A CN114495971A (en) | 2022-02-25 | 2022-02-25 | A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114495971A true CN114495971A (en) | 2022-05-13 |
Family
ID=81484152
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210182933.1A Pending CN114495971A (en) | 2022-02-25 | 2022-02-25 | A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114495971A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115423081A (en) * | 2022-09-21 | 2022-12-02 | 重庆邮电大学 | Neural network accelerator based on CNN _ LSTM algorithm of FPGA |
| CN120895047A (en) * | 2025-09-04 | 2025-11-04 | 广东公信智能会议股份有限公司 | A method and system for voice data noise reduction in intelligent conferencing |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180068675A1 (en) * | 2016-09-07 | 2018-03-08 | Google Inc. | Enhanced multi-channel acoustic models |
| CN112101372A (en) * | 2019-06-17 | 2020-12-18 | 北京地平线机器人技术研发有限公司 | Method and device for determining image characteristics |
| CN112397090A (en) * | 2020-11-09 | 2021-02-23 | 电子科技大学 | Real-time sound classification method and system based on FPGA |
| CN112786021A (en) * | 2021-01-26 | 2021-05-11 | 东南大学 | Lightweight neural network voice keyword recognition method based on hierarchical quantization |
| CN113838473A (en) * | 2021-09-26 | 2021-12-24 | 科大讯飞股份有限公司 | Device's voice processing method, device and device |
| CN114001816A (en) * | 2021-12-30 | 2022-02-01 | 成都航空职业技术学院 | Acoustic imager audio acquisition system based on MPSOC |
-
2022
- 2022-02-25 CN CN202210182933.1A patent/CN114495971A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180068675A1 (en) * | 2016-09-07 | 2018-03-08 | Google Inc. | Enhanced multi-channel acoustic models |
| CN112101372A (en) * | 2019-06-17 | 2020-12-18 | 北京地平线机器人技术研发有限公司 | Method and device for determining image characteristics |
| CN112397090A (en) * | 2020-11-09 | 2021-02-23 | 电子科技大学 | Real-time sound classification method and system based on FPGA |
| CN112786021A (en) * | 2021-01-26 | 2021-05-11 | 东南大学 | Lightweight neural network voice keyword recognition method based on hierarchical quantization |
| CN113838473A (en) * | 2021-09-26 | 2021-12-24 | 科大讯飞股份有限公司 | Device's voice processing method, device and device |
| CN114001816A (en) * | 2021-12-30 | 2022-02-01 | 成都航空职业技术学院 | Acoustic imager audio acquisition system based on MPSOC |
Non-Patent Citations (1)
| Title |
|---|
| 魏磊: "基于CNN 的语音增强算法的研究与FPGA 实现", 中国优秀硕士学位论文全文数据库(信息科技辑), vol. 2022, no. 01, pages 2 - 4 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115423081A (en) * | 2022-09-21 | 2022-12-02 | 重庆邮电大学 | Neural network accelerator based on CNN _ LSTM algorithm of FPGA |
| CN120895047A (en) * | 2025-09-04 | 2025-11-04 | 广东公信智能会议股份有限公司 | A method and system for voice data noise reduction in intelligent conferencing |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111582465B (en) | Convolutional neural network acceleration processing system and method based on FPGA and terminal | |
| CN111242289B (en) | Convolutional neural network acceleration system and method with expandable scale | |
| CN107341547B (en) | An apparatus and method for performing convolutional neural network training | |
| KR102642849B1 (en) | Deep learning processing unit, method, device and storage medium | |
| CN108647773B (en) | A Hardware Interconnection System for Reconfigurable Convolutional Neural Networks | |
| CN108537331A (en) | A kind of restructural convolutional neural networks accelerating circuit based on asynchronous logic | |
| CN108241890A (en) | A kind of restructural neural network accelerated method and framework | |
| CN114897133A (en) | Universal configurable Transformer hardware accelerator and implementation method thereof | |
| CN110852428A (en) | Neural network acceleration method and accelerator based on FPGA | |
| WO2022007265A1 (en) | Dilated convolution acceleration calculation method and apparatus | |
| CN111275179B (en) | An architecture and method for accelerating neural network computing based on distributed weight storage | |
| CN118014022A (en) | FPGA general heterogeneous acceleration method and equipment for deep learning | |
| CN114003201B (en) | Matrix transformation method, device and convolutional neural network accelerator | |
| CN114495971A (en) | A Speech Enhancement Method Using Embedded Hardware to Run Neural Networks | |
| CN115577747A (en) | A Highly Parallel Heterogeneous Convolutional Neural Network Accelerator and Acceleration Method | |
| CN111831285A (en) | A code conversion method, system and application for in-memory computing platform | |
| CN111752879A (en) | An acceleration system, method and storage medium based on convolutional neural network | |
| CN109491934B (en) | Storage management system control method integrating computing function | |
| CN118093203A (en) | Data handling method, distributed training system, electronic device, and storage medium | |
| CN112862079B (en) | Design method of running water type convolution computing architecture and residual error network acceleration system | |
| CN115496190A (en) | An Efficient Reconfigurable Hardware Accelerator for Convolutional Neural Network Training | |
| JP7410961B2 (en) | arithmetic processing unit | |
| CN113313251A (en) | Deep separable convolution fusion method and system based on data stream architecture | |
| CN113177877B (en) | A Shure Elimination Accelerator optimized for SLAM backend | |
| CN119883593B (en) | A Method and System for Accelerating Large Model Inference Based on Dynamically Managed Model Parameters |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20220513 |
|
| RJ01 | Rejection of invention patent application after publication |