CN114422934A - Media system and method for adaptation to hearing loss - Google Patents
Media system and method for adaptation to hearing loss Download PDFInfo
- Publication number
- CN114422934A CN114422934A CN202210104034.XA CN202210104034A CN114422934A CN 114422934 A CN114422934 A CN 114422934A CN 202210104034 A CN202210104034 A CN 202210104034A CN 114422934 A CN114422934 A CN 114422934A
- Authority
- CN
- China
- Prior art keywords
- audio
- level
- personal
- gain
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



























Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/04—Time compression or expansion
- G10L21/057—Time compression or expansion for improving intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Electric hearing aids
- H04R25/50—Customised settings for obtaining desired overall acoustical characteristics
- H04R25/505—Customised settings for obtaining desired overall acoustical characteristics using digital signal processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/12—Audiometering
- A61B5/121—Audiometering evaluating hearing capacity
- A61B5/123—Audiometering evaluating hearing capacity subjective methods
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/46—Volume control
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11B—INFORMATION STORAGE BASED ON RELATIVE MOVEMENT BETWEEN RECORD CARRIER AND TRANSDUCER
- G11B20/00—Signal processing not specific to the method of recording or reproducing; Circuits therefor
- G11B20/10—Digital recording or reproducing
- G11B20/10009—Improvement or modification of read or write signals
- G11B20/10018—Improvement or modification of read or write signals analog processing for digital recording or reproduction
- G11B20/10027—Improvement or modification of read or write signals analog processing for digital recording or reproduction adjusting the signal strength during recording or reproduction, e.g. variable gain amplifiers
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G5/00—Tone control or bandwidth control in amplifiers
- H03G5/005—Tone control or bandwidth control in amplifiers of digital signals
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G5/00—Tone control or bandwidth control in amplifiers
- H03G5/02—Manually-operated control
- H03G5/025—Equalizers; Volume or gain control in limited frequency bands
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G5/00—Tone control or bandwidth control in amplifiers
- H03G5/16—Automatic control
- H03G5/165—Equalizers; Volume or gain control in limited frequency bands
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/44—Receiver circuitry for the reception of television signals according to analogue transmission standards
- H04N5/60—Receiver circuitry for the reception of television signals according to analogue transmission standards for the sound signals
- H04N5/602—Receiver circuitry for the reception of television signals according to analogue transmission standards for the sound signals for digital sound signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Electric hearing aids
- H04R25/04—Electric hearing aids comprising pocket amplifiers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Electric hearing aids
- H04R25/70—Adaptation of deaf aid to hearing loss, e.g. initial electronic fitting
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/04—Circuit arrangements, e.g. for selective connection of amplifier inputs/outputs to loudspeakers, for loudspeaker detection, or for adaptation of settings to personal preferences or hearing impairments
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
- G10H2210/046—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal for differentiation between music and non-music signals, based on the identification of musical parameters, e.g. based on tempo detection
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2205/00—Details of stereophonic arrangements covered by H04R5/00 but not provided for in any of its subgroups
- H04R2205/041—Adaptation of stereophonic signal reproduction for the hearing impaired
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
- H04R2430/01—Aspects of volume control, not necessarily automatic, in sound systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2499/00—Aspects covered by H04R or H04S not otherwise provided for in their subgroups
- H04R2499/10—General applications
- H04R2499/11—Transducers incorporated or for use in hand-held devices, e.g. mobile phones, PDA's, camera's
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/033—Headphones for stereophonic communication
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Otolaryngology (AREA)
- General Health & Medical Sciences (AREA)
- Neurosurgery (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Quality & Reliability (AREA)
- Life Sciences & Earth Sciences (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Pathology (AREA)
- Biomedical Technology (AREA)
- Heart & Thoracic Surgery (AREA)
- Medical Informatics (AREA)
- Molecular Biology (AREA)
- Surgery (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
本发明涉及适应听力损失的媒体系统和方法,具体描述了一种媒体系统以及一种使用该媒体系统来适应用户的听力损失的方法。方法包括选择对应于用户的听力损失曲线的个人水平和频率相关的音频滤波器。个人水平和频率相关的音频滤波器可以是具有相应的平均增益水平和相应的增益轮廓的若干水平和频率相关的音频滤波器中的一个。可通过将个人水平和频率相关的音频滤波器应用于音频输入信号以基于音频输入信号的输入水平和输入频率增强音频输入信号来生成适应性音频输出信号。可由音频输出设备播放音频输出信号以递送用户清晰感知的语音或音乐,尽管存在用户的听力损失。也描述了其他方面并要求对其他方面进行保护。
The present invention relates to a media system and method for adapting to hearing loss, and specifically describes a media system and a method for adapting to a user's hearing loss using the media system. The method includes selecting an individual level and frequency dependent audio filter corresponding to the user's hearing loss profile. The personal level and frequency dependent audio filter may be one of several level and frequency dependent audio filters with corresponding average gain levels and corresponding gain profiles. The adaptive audio output signal may be generated by applying a personal level and frequency dependent audio filter to the audio input signal to enhance the audio input signal based on the input level and input frequency of the audio input signal. The audio output signal may be played by the audio output device to deliver speech or music clearly perceived by the user despite the user's hearing loss. Other aspects are also described and claimed for protection.
Description
本分案申请是基于申请号为202010482726.9,申请日为2020年6月1日,发明名称为“数据处理装置”的中国专利申请的分案申请。This divisional application is based on the divisional application of the Chinese patent application with the application number of 202010482726.9 and the filing date of June 1, 2020, and the invention name is "data processing device".
技术领域technical field
本发明公开了与具有音频能力的媒体系统相关的方面。更具体地,公开了与用于向用户播放音频内容的媒体系统相关的方面。The present invention discloses aspects related to audio-capable media systems. More particularly, aspects related to media systems for playing audio content to a user are disclosed.
背景技术Background technique
支持音频的设备(诸如膝上型计算机、平板电脑或其他移动设备)可将音频内容递送给用户。例如,用户可使用支持音频的设备来收听音频内容。音频内容可以是由扬声器播放给用户的预先存储的音频内容,诸如音乐文件、播客、虚拟助理消息等。另选地,再现的音频内容可以是实时音频内容,诸如来自电话呼叫、视频会议等的音频内容。Audio-enabled devices, such as laptops, tablets, or other mobile devices, can deliver audio content to users. For example, a user may use an audio-enabled device to listen to audio content. The audio content may be pre-stored audio content played by the speaker to the user, such as music files, podcasts, virtual assistant messages, and the like. Alternatively, the rendered audio content may be real-time audio content, such as audio content from phone calls, video conferences, and the like.
噪声暴露、衰老或其他因素可导致个体体验到听力损失。个体的听力损失曲线可能相差很大,并且甚至可能归因于未被诊断为患有听力受损的人。也就是说,每个个体都可能具有与正常值不同的一些频率相关的响度感知。此类差异在整个人群中可能相差很大,并且可能对应于人群的听力损失曲线的频谱。考虑到每个个体听到的声音不同,对于以相同方式再现给若干人的音频内容,每个个体可能会有不同的体验。例如,在特定频率下具有实质性听力损失的人可能会体验到在该频率下包含实质性分量的音频内容的回放被消音。相比之下,在特定频率下无听力损失的人可能会体验到相同音频内容的回放是清晰的。Noise exposure, aging, or other factors can cause an individual to experience hearing loss. Individual hearing loss profiles can vary widely, and can even be attributed to people who have not been diagnosed with hearing loss. That is, each individual may have some frequency-dependent loudness perception that differs from normal. Such differences may vary widely across the population and may correspond to the spectrum of the population's hearing loss curve. Given that each individual hears different sounds, each individual may have a different experience with audio content reproduced to several people in the same way. For example, a person with substantial hearing loss at a particular frequency may experience muted playback of audio content that contains substantial components at that frequency. In contrast, a person without hearing loss at a particular frequency may experience clear playback of the same audio content.
个体可调节支持音频的设备以修改音频内容的回放,以便增强用户的体验。例如,在特定频率下具有实质性听力损失的人可调节音频信号音量的总体水平以增加再现音频的响度。可进行此类调节,希望修改后的回放会补偿人的听力损失。An individual may adjust the audio-enabled device to modify the playback of audio content in order to enhance the user's experience. For example, a person with substantial hearing loss at certain frequencies may adjust the overall level of audio signal volume to increase the loudness of the reproduced audio. Such adjustments can be made in the hope that the modified playback will compensate for the person's hearing loss.
发明内容SUMMARY OF THE INVENTION
如上所述修改回放的音量调节可能无法以个性化方式补偿听力损失。例如,增大音频信号的总体水平可增大响度,但跨可听频率范围增大响度,而不管用户是否跨整个范围体验到听力损失。此类大规模水平调节的结果对于用户而言可能是令人不舒服的大声和令人不安的收听体验。Modifying the playback volume adjustment as described above may not compensate for hearing loss in a personalized way. For example, increasing the overall level of the audio signal may increase the loudness, but increase the loudness across the audible frequency range, regardless of whether the user experiences hearing loss across the entire range. The result of such massive leveling can be an uncomfortable loud and disturbing listening experience for the user.
本发明描述了一种媒体系统以及一种使用该媒体系统来适应用户的听力损失的方法。在一方面,该媒体系统通过以下操作来执行该方法:从若干音频滤波器(例如,若干水平和频率相关的音频滤波器)中选择音频滤波器(例如,水平和频率相关的音频滤波器);以及将该音频滤波器应用于音频输入信号以生成可回放给用户的音频输出信号。音频滤波器可以是个人音频滤波器,例如对应于用户的听力损失曲线的个人水平和频率相关的音频滤波器。The present invention describes a media system and a method of using the media system to accommodate a user's hearing loss. In one aspect, the media system performs the method by selecting an audio filter (eg, a level and frequency dependent audio filter) from a number of audio filters (eg, a number of level and frequency dependent audio filters) ; and applying the audio filter to the audio input signal to generate an audio output signal that can be played back to the user. The audio filter may be a personal audio filter, such as a personal level and frequency dependent audio filter corresponding to the user's hearing loss profile.
可由媒体系统从对应于相应的预设的听力损失曲线的水平和频率相关的音频滤波器中进行对个人水平和频率相关的音频滤波器的选择。由于水平和频率相关的音频滤波器具有对应于听力损失曲线的平均损失水平和损失轮廓的相应的平均增益水平和相应的增益轮廓,因此水平和频率相关的音频滤波器补偿预设的听力损失曲线。个人水平和频率相关的音频滤波器可基于音频输入信号的输入水平和输入频率来放大音频输入信号,并且因此,用户可正常体验来自再现的音频输出信号的声音(而不是像播放未校正的音频输入信号的情况那样消音)。Selection of the individual level and frequency dependent audio filters may be made by the media system from among level and frequency dependent audio filters corresponding to respective preset hearing loss curves. Since the level and frequency dependent audio filters have corresponding average gain levels and corresponding gain profiles corresponding to the average loss levels and loss profiles of the hearing loss profile, the level and frequency dependent audio filters compensate for the preset hearing loss profile . The personal level and frequency dependent audio filter can amplify the audio input signal based on the input level and input frequency of the audio input signal, and thus, the user can experience the sound from the reproduced audio output signal normally (rather than playing as uncorrected audio). muting as in the case of the input signal).
可通过简短而直接的注册过程来进行对个人水平和频率相关的音频滤波器的选择。在一方面,在注册过程的第一级期间使用一个或多个预先确定的增益水平或使用具有不同平均增益水平的第一组水平和频率相关音频滤波器来输出第一音频信号。可将第一音频信号回放给以不同的响度体验音频内容(例如,语音)的用户。用户可选择可听或优选的响度。更具体地,媒体系统响应于使用一个或多个预先确定的增益水平或第一组的一个或多个水平和频率相关的音频滤波器输出第一音频信号来接收对个人平均增益水平的选择。个人平均增益水平的选择可指示第一音频信号(例如,语音信号)是以用户可听的水平输出的。对个人平均增益水平的选择可指示第一音频信号是以优选响度输出的。媒体系统可部分地基于具有个人平均增益水平的个人水平和频率相关音频滤波器来选择个人水平和频率相关音频滤波器。例如,个人水平和频率相关音频滤波器的相应的平均增益水平可等于个人平均增益水平。Selection of individual level and frequency dependent audio filters can be made through a short and straightforward registration process. In one aspect, the first audio signal is output during a first stage of the registration process using one or more predetermined gain levels or using a first set of level and frequency dependent audio filters having different average gain levels. The first audio signal may be played back to a user experiencing audio content (eg, speech) at different loudnesses. The user can select audible or preferred loudness. More specifically, the media system receives the selection of the personal average gain level in response to outputting the first audio signal using one or more predetermined gain levels or a first set of one or more levels and a frequency-dependent audio filter. Selection of the personal average gain level may indicate that the first audio signal (eg, a speech signal) is output at a level audible to the user. Selection of the personal average gain level may indicate that the first audio signal is output at a preferred loudness. The media system may select the personal level and frequency dependent audio filter based in part on the personal level and frequency dependent audio filter having the personal average gain level. For example, the respective average gain levels of the personal level and frequency dependent audio filter may be equal to the personal average gain levels.
在一方面,在注册过程的第二级期间使用具有不同增益轮廓的第二组水平和频率相关的音频滤波器来输出第二音频信号。可基于在注册过程的第一级期间进行的用户选择来选择第二组水平和频率相关的音频滤波器以进行探索。例如,第二组中的每个水平和频率相关的音频滤波器都可具有对应于在第一级期间进行的可听度选择的个人平均增益水平。可将第二音频信号回放给以不同音色或音调设置体验音频内容(例如,音乐)并选择优选的音色或音调设置的用户。更具体地,媒体系统响应于输出第二音频信号来接收对个人增益轮廓的选择。媒体系统可部分地基于具有个人增益轮廓的个人水平和频率相关的音频滤波器来选择个人水平和频率相关的音频滤波器。例如,个人水平和频率相关音频滤波器的相应的增益轮廓可等于个人增益轮廓。In one aspect, the second audio signal is output using a second set of level and frequency dependent audio filters having different gain profiles during the second stage of the registration process. A second set of level and frequency dependent audio filters may be selected for exploration based on user selections made during the first stage of the registration process. For example, each level and frequency dependent audio filter in the second set may have an individual average gain level corresponding to the audibility selection made during the first stage. The second audio signal may be played back to a user experiencing the audio content (eg, music) in a different tone or tone setting and selecting a preferred tone or tone setting. More specifically, the media system receives the selection of the personal gain profile in response to outputting the second audio signal. The media system may select the personal level and frequency dependent audio filter based in part on the personal level and frequency dependent audio filter having the personal gain profile. For example, the respective gain profiles of the personal level and frequency dependent audio filters may be equal to the personal gain profiles.
在一方面,注册过程可使用对应于预设的听力损失曲线的水平和频率相关的音频滤波器来修改第一音频信号和第二音频信号以进行回放。例如,可使用对应于人群中最常见的听力损失曲线的音频滤波器。音频滤波器可另选地对应于来自人群的与用户的听力图密切相关的听力损失曲线。例如,媒体系统可接收用户的个人听力图,并且可基于该个人听力图,确定涵盖由听力图所表示的用户的听力损失曲线的若干预设的听力损失曲线。然后,媒体系统可确定对应于所确定的听力损失曲线的水平和频率相关的音频滤波器,并且可在注册过程的第一级或第二级中呈现音频期间使用那些音频滤波器。In one aspect, the registration process may modify the first audio signal and the second audio signal for playback using level and frequency dependent audio filters corresponding to preset hearing loss profiles. For example, audio filters corresponding to the most common hearing loss profiles in the population may be used. The audio filter may alternatively correspond to a hearing loss profile from a population that is closely related to the user's audiogram. For example, the media system may receive a user's personal audiogram, and may determine, based on the personal audiogram, a number of preset hearing loss profiles that encompass the user's hearing loss profile represented by the audiogram. The media system may then determine level and frequency dependent audio filters corresponding to the determined hearing loss profile, and may use those audio filters during presentation of audio in the first or second stage of the registration process.
媒体系统可直接基于用户的听力图来选择个人水平和频率相关的音频滤波器,而无需利用注册过程。例如,媒体系统可接收用户的个人听力图,并且可基于该个人听力图,选择与由听力图所表示的用户的听力损失曲线最密切匹配的预设的个人听力损失曲线。例如,个人听力图可指示用户具有平均听力损失水平和损失曲线,并且媒体系统可选择适合听力图的预设的听力损失曲线。然后,媒体系统可确定对应于个人听力损失曲线的水平和频率相关的音频滤波器。例如,媒体系统可确定具有对应于听力图的平均听力损失水平的平均增益水平和/或具有对应于损失轮廓的增益轮廓的水平和频率相关的音频滤波器。媒体系统可使用音频滤波器作为个人水平和频率相关的音频滤波器来增强音频输入信号并在回放音频内容时补偿用户的听力损失。The media system can select individual level and frequency dependent audio filters directly based on the user's audiogram without utilizing a registration process. For example, the media system may receive the user's personal audiogram, and based on the personal audiogram, may select a preset personal hearing loss profile that most closely matches the user's hearing loss profile represented by the audiogram. For example, a personal audiogram may indicate that the user has an average level of hearing loss and a loss profile, and the media system may select a preset hearing loss profile that fits the audiogram. The media system may then determine a level and frequency dependent audio filter corresponding to the individual's hearing loss profile. For example, the media system may determine an audio filter having an average gain level corresponding to an average hearing loss level of an audiogram and/or a level and frequency dependent audio filter having a gain profile corresponding to a loss profile. The media system may use the audio filter as a personal level and frequency dependent audio filter to enhance the audio input signal and compensate for the user's hearing loss when playing back the audio content.
上面的概述不包括本发明的所有方面的详尽列表。设想本发明包括可从上面概述的各个方面以及在下面的具体实施方式中公开并在随该专利申请提交的权利要求书中特别指出的各个方面的所有合适的组合而实践的所有系统和方法。此类组合具有未在上面的概述中具体叙述的特定优点。The above summary does not include an exhaustive list of all aspects of the invention. It is contemplated that the present invention includes all systems and methods that may be practiced in all suitable combinations of the various aspects outlined above as well as those disclosed in the Detailed Description below and particularly pointed out in the claims filed with this patent application. Such combinations have certain advantages not specifically recited in the summary above.
附图说明Description of drawings
图1是根据一方面的媒体系统的示图。1 is an illustration of a media system according to an aspect.
图2是根据一方面的具有感音神经性听力损失的个体的响度曲线的曲线图。2 is a graph of a loudness curve for an individual with sensorineural hearing loss, according to one aspect.
图3是根据一方面的将具有不同听力损失曲线的个体所感知的响度归一化所需的放大的曲线图。3 is a graph of amplification required to normalize the perceived loudness of individuals with different hearing loss profiles, according to one aspect.
图4是根据一方面的应用于音频输入信号以适应用户的听力损失的个人水平和频率相关的音频滤波器的示图。4 is an illustration of an individual level and frequency dependent audio filter applied to an audio input signal to accommodate a user's hearing loss, according to one aspect.
图5是根据一方面的用户的听力图的示图。5 is an illustration of an audiogram of a user according to an aspect.
图6至图8是根据一方面的听力损失曲线的示图。6-8 are diagrams of hearing loss curves according to an aspect.
图9是根据一方面的表示对应于听力损失曲线的水平和频率相关的音频滤波器的多频带压缩增益表的示图。9 is a diagram of a multi-band compression gain table representing a level and frequency dependent audio filter corresponding to a hearing loss curve, according to an aspect.
图10是根据一方面的增强音频输入信号以适应听力损失的方法的流程图。10 is a flowchart of a method of enhancing an audio input signal to accommodate hearing loss, according to an aspect.
图11是根据一方面的用于控制第一音频信号的输出的用户界面的示图。11 is an illustration of a user interface for controlling output of a first audio signal, according to an aspect.
图12是根据一方面的对用于在注册程序的第二级中进行探索的水平和频率相关的音频滤波器组的选择的示图。12 is an illustration of selection of level and frequency dependent audio filter banks for exploration in a second stage of a registration procedure, according to an aspect.
图13是根据一方面的用于控制第二音频信号的输出的用户界面的示图。13 is an illustration of a user interface for controlling output of a second audio signal, according to an aspect.
图14A至图14B是根据一方面的对具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。14A-14B are diagrams of selection of level and frequency dependent audio filters with different gain profiles, according to an aspect.
图15是根据一方面的选择具有个人平均增益水平和个人增益轮廓的个人水平和频率相关的音频滤波器的方法的流程图。15 is a flowchart of a method of selecting a personal level and frequency dependent audio filter having a personal average gain level and a personal gain profile, according to an aspect.
图16是根据一方面的用于控制第一音频信号的输出的用户界面的示图。16 is an illustration of a user interface for controlling output of a first audio signal, according to an aspect.
图17A至图17B是根据一方面的对具有不同平均增益水平的水平和频率相关的音频滤波器的选择的示图。17A-17B are diagrams of selection of level and frequency dependent audio filters with different average gain levels, according to an aspect.
图18是根据一方面的用于控制第二音频信号的输出的用户界面的示图。18 is an illustration of a user interface for controlling output of a second audio signal, according to an aspect.
图19A至图19B是根据一方面的对具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。19A-19B are diagrams of selection of level and frequency dependent audio filters with different gain profiles, according to one aspect.
图20是根据一方面的选择具有个人平均增益水平和个人增益轮廓的个人水平和频率相关的音频滤波器的方法的流程图。20 is a flowchart of a method of selecting a personal level and frequency dependent audio filter having a personal average gain level and a personal gain profile, according to an aspect.
图21A至图21B分别是根据一方面的基于个人听力图确定若干听力损失曲线的方法的流程图和示图。21A-21B are flowcharts and diagrams, respectively, of a method of determining a number of hearing loss curves based on a personal audiogram, according to an aspect.
图22A至图22B分别是根据一方面的基于个人听力图确定个人听力损失曲线的方法的流程图和示图。22A-22B are a flowchart and diagram, respectively, of a method of determining an individual's hearing loss profile based on an individual's audiogram, according to an aspect.
图23是根据一方面的媒体系统的框图。23 is a block diagram of a media system according to an aspect.
具体实施方式Detailed ways
本申请要求提交于2019年6月1日的美国临时专利申请62/855,951号的优先权权益,并且本申请将该临时专利申请以引用方式并入本文。This application claims the benefit of priority from US Provisional Patent Application No. 62/855,951, filed June 1, 2019, and this application incorporates this provisional patent application herein by reference.
各方面描述了一种媒体系统以及一种使用该媒体系统来适应用户的听力损失的方法。媒体系统可包括移动设备(诸如智能电话)和音频输出设备(诸如听筒)。然而,移动设备可以是用于向用户呈现音频的另一设备,诸如台式计算机、膝上型计算机、平板电脑、智能手表等,并且音频输出设备可包括其他类型的设备,诸如耳机、头戴式耳机、计算机扬声器等,仅举几个可能的应用。Aspects describe a media system and a method of using the media system to accommodate a user's hearing loss. The media system may include a mobile device (such as a smartphone) and an audio output device (such as a handset). However, the mobile device may be another device used to present audio to the user, such as a desktop computer, laptop computer, tablet computer, smart watch, etc., and the audio output device may include other types of devices such as headphones, headsets, etc. Headphones, computer speakers, etc., to name a few possible applications.
在各个方面中,参考附图进行描述。然而,可在不具有这些具体细节中的一个或多个具体细节或不与其他已知的方法和配置组合的情况下实践某些方面。在以下的描述中,阐述多个具体细节诸如具体配置、尺寸和过程,以便提供对方面的透彻理解。在其他实例中,没有特别详细地描述众所周知的过程和制造技术,以便不会不必要地模糊该描述。整个本说明书中对“一个方面”、“方面”等的引用意味着所描述的特定特征、结构、配置或特性包括在至少一个方面中。因此,整个本说明书中各个地方出现短语“一个方面”、“方面”等不一定是指相同方面。还有,特定特征、结构、配置或特性可以任何合适的方式组合在一个或多个方面中。In various aspects, the description is made with reference to the accompanying drawings. However, certain aspects may be practiced without one or more of these specific details or in combination with other known methods and configurations. In the following description, numerous specific details are set forth such as specific configurations, dimensions, and processes in order to provide a thorough understanding of the aspects. In other instances, well-known processes and fabrication techniques have not been described in particular detail so as not to unnecessarily obscure the description. Reference throughout this specification to "an aspect," "aspect," etc. means that a particular feature, structure, configuration or characteristic described is included in at least one aspect. Thus, appearances of the phrases "an aspect," "aspect," etc. in various places throughout this specification are not necessarily referring to the same aspect. Also, the particular features, structures, configurations or characteristics may be combined in any suitable manner in one or more aspects.
在整个描述中使用相对术语可指代相对位置或方向。例如,“在……前面”可指示远离参考点的第一方向。类似地,“在……后面”可指示在远离参考点且与第一方向相反的第二方向上的位置。然而,提供此类术语以建立相对参照系,并且此类术语不旨在将媒体系统的使用或取向限制为在下面各个方面中描述的具体构型。The use of relative terms throughout the description may refer to relative positions or orientations. For example, "in front of" may indicate a first direction away from the reference point. Similarly, "behind" may indicate a position in a second direction away from the reference point and opposite the first direction. However, such terms are provided to establish a relative frame of reference and are not intended to limit the use or orientation of the media system to the specific configurations described in the various aspects below.
在一方面,媒体系统用于适应用户的听力损失。媒体系统可补偿用户的轻度或中度的听力损失曲线。此外,补偿可以是个性化的,这意味着其基于个体的独特听力偏好以水平相关和频率相关的方式调节音频输入信号,而不是仅调节音频输入信号的平衡或总体水平。媒体系统可基于在简短而直接的注册过程期间作出的选择来个性化音频调谐。在注册过程期间,用户可体验到来自以不同方式滤波的若干音频信号的声音,并且用户可基于对体验的主观评估或比较来进行二元选择以选择个人音频设置。个人音频设置包括优选音频滤波器的平均增益水平和增益轮廓。当用户已选择个人音频设置时,媒体系统可通过应用具有个人音频设置的个人水平和频率相关的音频滤波器来生成音频输出信号,以基于音频输入信号的输入水平和输入频率来放大音频输入信号。音频输出信号的回放可向用户递送语音或音乐,尽管用户存在听力损失曲线,但语音或音乐对用户是清晰的。In one aspect, a media system is used to accommodate a user's hearing loss. The media system may compensate for the user's mild or moderate hearing loss profile. Furthermore, the compensation may be individualized, meaning that it adjusts the audio input signal in a level-dependent and frequency-dependent manner based on the individual's unique hearing preferences, rather than just the balance or overall level of the audio input signal. The media system can personalize audio tuning based on selections made during a short and straightforward registration process. During the registration process, the user may experience sounds from several audio signals filtered in different ways, and the user may make a binary selection to select a personal audio setting based on a subjective assessment or comparison of the experience. Personal audio settings include the average gain level and gain profile of the preferred audio filter. When the user has selected a personal audio setting, the media system may generate an audio output signal by applying a personal level and frequency dependent audio filter with the personal audio setting to amplify the audio input signal based on the input level and input frequency of the audio input signal . Playback of the audio output signal may deliver speech or music to the user that is clear to the user despite the user's hearing loss profile.
参考图1,根据一方面示出了媒体系统的示图。媒体系统100可用于向用户递送音频。媒体系统100可包括输出和/或传输音频输出信号的音频信号设备102以及将音频输出信号(或源于音频输出信号的信号)转换为声音的音频输出设备104。在一方面,音频信号设备102为智能电话。然而,音频信号设备102可包括其他类型的支持音频的设备,诸如膝上型计算机、平板电脑、智能手表、电视等。在一方面,音频输出设备104为听筒(有线或无线的)。然而,音频输出设备104可包括其他类型的设备,包含音频扬声器诸如耳机。音频输出设备104还可以是音频信号设备102的内部或外部扬声器,例如智能电话、膝上型计算机、平板电脑、智能手表、电视等的扬声器。在任何情况下,媒体系统100可包括硬件诸如一个或多个处理器、存储器等,其使得媒体系统100能够执行增强音频输入信号的方法以适应用户的听力损失。更具体地,媒体系统100可通过将用户的个性化音频滤波器应用于音频输入信号来提供个性化媒体增强,以使得能够回放适应用户的听力偏好和或听力能力的音频内容。Referring to FIG. 1, a diagram of a media system is shown according to one aspect. The
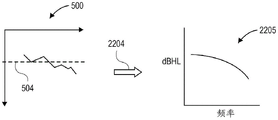
参考图2,示出了根据一方面的具有感音神经性听力损失的个体的响度曲线的曲线图。感音神经性听力损失是主要类型的听力损失,然而,也存在其他类型的听力损失,诸如传导性听力损失。具有感音神经性听力损失的个体具有比正常听众更高的可听度阈值,但同样会体验到令人不舒服的大声水平。具有传导性听力损失的个体的响度曲线会有所不同。更具体地,具有传导性听力损失的个体,与其具有正常听力的同伴相比,具有更高的可听度阈值和令人不舒服的大声水平。响度水平曲线200以举例的方式使用。Referring to FIG. 2, a graph of a loudness curve for an individual with sensorineural hearing loss is shown, according to one aspect. Sensorineural hearing loss is the main type of hearing loss, however, other types of hearing loss, such as conductive hearing loss, also exist. Individuals with sensorineural hearing loss have higher thresholds of audibility than normal listeners, but also experience uncomfortable loudness levels. Individuals with conductive hearing loss will have different loudness curves. More specifically, individuals with conductive hearing loss have higher audibility thresholds and uncomfortable loudness levels than their normal hearing counterparts. The
用户的听力偏好和/或听力能力是频率相关和水平相关的。具有听力受损的个体的耳朵中需要更高的声压水平来达到与具有较少听力损失的个体相同的感知响度。该曲线图示出了响度水平曲线200,该响度水平曲线描述了作为特定频率(例如,1kHz)下若干个体的声压水平(SPL)的函数的感知响度(PHON)。曲线202具有1:1的斜率并且原点为零,因为响度单位(例如,50PHON)被定义为正常听力的听众所感知的对应SPL(例如,50dB SPL)的1kHz音调的响度。相比之下,具有受损听力204的个体在声压水平达到阈值水平之前没有感知到响度。例如,当个体具有60dB听力损失时,个体将不会感知到响度,直到声压水平达到60dB。A user's hearing preference and/or hearing ability is frequency-dependent and level-dependent. Individuals with hearing impairment require higher sound pressure levels in the ears to achieve the same perceived loudness as individuals with less hearing loss. The graph shows a
参考图3,示出了根据一方面的将具有不同听力损失曲线的个体所感知的响度归一化所需的放大的曲线图。为了补偿个体的听力损失,可将增益应用于输入信号以升高具有听力损失的个体耳朵中的声压水平。该曲线图示出了增益曲线302,该增益曲线描述了作为具有图2的响度水平曲线的个体的声压水平的函数的与正常听力响度匹配所需的增益。显然,在特定频率下,具有正常听力的个体202不需要放大,因为显然,个体在所有声压水平下都已经具有正常听力响度。相比之下,具有受损听力204的个体在低声压水平下需要实质性的放大,以便感知到所应用的低于图2的阈值水平(例如,低于60dB)的声音。Referring to FIG. 3, a graph of amplification required to normalize the perceived loudness of individuals with different hearing loss profiles is shown, according to one aspect. To compensate for an individual's hearing loss, a gain may be applied to the input signal to raise the sound pressure level in the ear of an individual with hearing loss. The graph shows a
补偿个体的听力损失所需的放大的量随着声压水平增加而减小。更具体地,补偿听力损失所需的放大的量取决于频率和输入信号水平两者。也就是说,当音频输入信号的输入信号水平对于给定频率产生较高声压水平时,需要较少的放大来补偿该频率下的听力损失。类似地,个体的听力损失是频率相关的,因此响度水平曲线和增益曲线在另一频率(例如,2kHz)下可能有所不同。以举例的方式,如果具有受损听力的个体的增益曲线向上偏移(在2kHz下比在1kHz下听力损失更多),则需要更大的放大来正常感知该频率下的声音。因此,当音频输入信号的输入信号水平具有特定频率(2kHz)下的分量时,需要更大的放大来补偿该频率下的听力损失。基于音频输入信号的输入水平和输入频率调节音频输入信号以放大音频输入信号的方法在本文中可被称为多频带向上压缩。The amount of amplification required to compensate for an individual's hearing loss decreases as the sound pressure level increases. More specifically, the amount of amplification required to compensate for hearing loss depends on both frequency and input signal level. That is, when the input signal level of the audio input signal produces a higher sound pressure level for a given frequency, less amplification is required to compensate for hearing loss at that frequency. Similarly, an individual's hearing loss is frequency dependent, so the loudness level curve and gain curve may be different at another frequency (eg, 2 kHz). By way of example, if the gain curve of an individual with impaired hearing is shifted upwards (more hearing loss at 2 kHz than at 1 kHz), greater amplification is required to properly perceive sound at that frequency. Therefore, when the input signal level of the audio input signal has a component at a certain frequency (2 kHz), greater amplification is required to compensate for the hearing loss at that frequency. The method of adjusting the audio input signal to amplify the audio input signal based on the input level and the input frequency of the audio input signal may be referred to herein as multi-band up-compression.
多频带向上压缩可通过使未被感知到或被感知为太安静的声音进入可听范围来实现音频内容的期望增强,而无需调节已被感知为充分或通常大声的声音。换句话讲,多频带向上压缩可以水平相关和频率相关的方式增强音频输入信号,以使听力受损个体正常感知声音。听力受损个体的响度水平曲线的归一化可避免在某些水平或频率下的过放大或欠放大,这避免了与简单地在整个可听频率范围内调大音量和放大音频输入信号相关联的问题。Multiband up-compression can achieve the desired enhancement of audio content by bringing sounds that are not perceived or perceived as too quiet into the audible range without adjusting sounds that have been perceived as sufficiently or generally loud. In other words, multi-band up-compression can enhance the audio input signal in a level-dependent and frequency-dependent manner to allow hearing-impaired individuals to perceive sound normally. Normalization of loudness level curves for hearing-impaired individuals avoids over- or under-amplification at certain levels or frequencies, which is associated with simply turning up the volume and amplifying the audio input signal across the entire audible frequency range connection problem.
参考图4,示出了根据一方面的应用于音频输入信号以适应用户的听力损失的个人水平和频率相关的音频滤波器的示图。鉴于上述讨论,应当理解,媒体系统100可通过将个人水平和频率相关的音频滤波器402应用于音频输入信号404来适应个体的听力损失。个人水平和频率相关的音频滤波器402可将音频输入信号404转换成通常将由个体感知的音频输出信号406。以举例的方式,音频输入信号404可表示电话呼叫中的语音、音轨中的音乐、来自虚拟助理的语音或其他音频内容。如虚引线和点划引线所指示的,当在无多频带向上压缩的情况下再现时,某些频率的声音可被正常感知(由实引线指示),而其他频率的声音可被安静地感知(浊音或消音)或根本不感知(由不同密度的虚引线和点划引线指示)。相比之下,在将个人水平和频率相关的音频滤波器402应用于音频输入信号404之后,所生成的音频输出信号406可包含正常感知的特定频率的声音(由实引线指示)。因此,个人水平和频率相关的音频滤波器402可恢复语音、音乐和其他音频内容的细节,以增强由音频输出设备104回放给用户的声音。Referring to FIG. 4, a diagram of an individual level and frequency dependent audio filter applied to an audio input signal to accommodate a user's hearing loss is shown, according to an aspect. In view of the above discussion, it should be appreciated that the
参考图5,示出了根据一个方面的用户的听力图的示图。为了理解可如何选择或确定个人水平和频率相关的音频滤波器402以用于增强音频输入信号404,理解可如何识别用户的听力损失曲线并将其映射到特定于用户的多频带压缩滤波器可能是有帮助的。在一方面,用户的个人听力图500可包括表示作为频率的函数的可听阈值的一个或多个听力图曲线。例如,第一听力图曲线502a可表示用户的右耳的可听阈值,并且第二听力图曲线502b可表示用户的左耳的可听阈值。个人听力图500可使用已知的技术来确定。在一方面,可从听力图曲线502a、502B中的一者或两者确定平均听力损失504。例如,在例示的示例中,这两条曲线的平均听力损失504可为30dB。因此,个人听力图500指示跨人的主要可听范围(例如,在500Hz至8000kHz之间)的用户的平均听力损失和频率相关的听力损失两者。应注意,本文所提及的主要可听范围可小于人的可听范围(已知为20Hz至20kHz)。Referring to FIG. 5, a diagram of an audiogram of a user is shown according to one aspect. In order to understand how individual level and frequency dependent
图6至图8包括人群的听力损失曲线的示图。如下所述,每个听力损失曲线都可具有水平参数和轮廓参数的组合。听力损失曲线的水平参数可指示如通过纯音测听所确定的平均听力损失。轮廓参数可指示可听频率范围内的听力损失变化,例如,听力损失在某些频率下是否更明显。图6至图8所示的听力损失曲线可根据水平参数和轮廓参数来分组。在一方面,听力损失曲线是基于对真实听力图的分析而存在于人群中的听力损失的最常见曲线。更具体地,每个听力损失曲线都可代表具有独特水平和轮廓参数的听力图的三维空间中的常见听力图。6-8 include graphs of hearing loss curves for a population. As described below, each hearing loss curve can have a combination of level parameters and profile parameters. The level parameter of the hearing loss curve may indicate the average hearing loss as determined by pure tone audiometry. Profile parameters may indicate changes in hearing loss over an audible frequency range, eg, whether hearing loss is more pronounced at certain frequencies. The hearing loss curves shown in Figures 6-8 may be grouped according to level parameters and profile parameters. In one aspect, the hearing loss curve is the most common curve of hearing loss that exists in the population based on analysis of real audiograms. More specifically, each hearing loss curve may represent a common audiogram in the three-dimensional space of the audiogram with unique level and profile parameters.
图6示出了第一组602听力损失曲线。第一组602中的听力损失曲线可具有对应于具有轻度听力损失的听众的水平参数。例如,第一组602曲线的平均听力损失604可为20dB。更具体地,包含在第一组602内的听力损失曲线中的每一个都可具有相同的平均听力损失604。然而,听力损失曲线可在形状上不同。FIG. 6 shows a
在一方面,第一组602可包括具有不同轮廓参数的听力损失曲线。轮廓参数可包括平坦损失轮廓606、凹口损失轮廓608和倾斜损失轮廓610。不同的形状在相应频率下可具有明显的听力损失。例如,与凹口损失轮廓608或倾斜损失轮廓610相比,平坦损失轮廓606在低带频下(例如,在500Hz下)可具有更多听力损失。相比之下,与平坦损失轮廓606或倾斜损失轮廓610相比,凹口损失轮廓608在中间带频下(例如,在4kHz下)可具有更多的听力损失。与平坦损失轮廓606或凹口损失轮廓608相比,倾斜损失轮廓610在高带频下(例如,在8kHz下)可具有更多的听力损失。In one aspect, the
听力损失曲线形状可具有其他一般性区别。例如,与凹口损失轮廓608和倾斜损失轮廓610相比,平坦损失轮廓606可具有最小听力损失变化。也就是说,平坦损失轮廓606在每个频率下表现出更一致的听力损失。另外,对于相同曲线,凹口损失轮廓608在中间带频下可具有比在其他频率下更多的听力损失。Hearing loss curve shapes may have other general differences. For example,
图7示出了第二组702听力损失曲线的示图。听力损失曲线组中的每一组的平均听力损失都可从图6至图8顺序地增加。更具体地,第二组702中的听力损失曲线可具有对应于具有轻度至中度听力损失的听众的水平参数。例如,第二组702的平均听力损失704可为35dB。然而,第二组702的听力损失曲线可具有不同的轮廓参数,例如,平坦损失轮廓706、凹口损失轮廓708和倾斜损失轮廓710。由于跨人群的听力损失的规则性,每个水平组的形状都可通过形状相关。更具体地,损失轮廓706-710的形状可共享以上相对于损失轮廓606-610所述的一般性区别,但这些形状可能不是按相同比例缩放的。例如,与图7的其他损失轮廓相比,凹口损失轮廓708在中间带频下可具有最高损失,但凹口损失轮廓708的最大损失可处于高带频(与图6中的中间带频相比)。因此,图7的听力损失曲线可表示人群中具有轻度至中度听力损失的人的最常见的听力损失曲线。FIG. 7 shows a diagram of a
图8示出了第三组802听力损失曲线的示图。第三组802的平均听力损失804可高于第二组702的平均听力损失704。第三组802的平均听力损失可代表人具有中度听力损失。例如,平均听力损失804可为50dB。与其他组一样,第三组802的听力损失曲线可在形状上不同并且可包括平坦损失轮廓806、凹口损失轮廓808和倾斜损失轮廓810。损失轮廓806-810的形状可共享以上相对于损失轮廓606-610或706-710所述的一般性区别。因此,图8的听力损失曲线可表示人群中具有中度听力损失的人的最常见的听力损失曲线。FIG. 8 shows a diagram of a
图6至图8所示的听力损失曲线表示由媒体系统100所存储的对听力损失曲线的9个预设。更具体地,媒体系统100可存储从上述听力图的3D空间所获取的任何数量的听力损失曲线预设。每个预设都可具有可与个人听力图500进行比较的水平和轮廓参数组合。组602、702和802的9个预设中的一个可类似于个人听力图500。例如,通过视觉检查,显然,图5的个人听力图500具有最接近第二组702的听力损失曲线的平均听力损失水平(30dB,与35dB相比),并且表现出与平坦损失轮廓706密切相关的形状。因此,平坦损失轮廓706可被识别为具有个人听力图500的用户的个人听力损失轮廓。The hearing loss curves shown in FIGS. 6-8 represent nine presets for hearing loss curves stored by the
如上所述的听力图和听力损失曲线之间的比较以举例的方式引入,并且将在以下相对于图21至图22再次参考。在该级,示例阐明了每个个体都可具有与常见听力损失曲线(如从人群确定并作为预设存储在媒体系统100内)密切匹配的实际听力损失(如由听力图表示)的概念。为了补偿实际听力损失,媒体系统100可应用对应于并补偿密切匹配的听力损失曲线的个人水平和频率相关的音频滤波器402。The comparison between the audiogram and the hearing loss curve as described above is introduced by way of example and will be referenced again below with respect to FIGS. 21 to 22 . At this level, the example illustrates the concept that each individual may have an actual hearing loss (as represented by an audiogram) that closely matches a common hearing loss profile (as determined from a population and stored as a preset within the media system 100). To compensate for actual hearing loss,
参考图9,示出了根据一方面的表示对应于听力损失曲线的水平和频率相关的音频滤波器的多频带压缩增益表的示图。每个听力损失曲线都可映射到相应的水平和频率相关的音频滤波器。例如,与个人听力图500最密切匹配的组602-802的听力损失曲线中无论哪一个都可映射到作为个人水平和频率相关的音频滤波器402的水平和频率相关的音频滤波器。因此,媒体系统100可例如在存储器中存储若干预设听力损失曲线以及对应于听力损失曲线的若干水平和频率相关的音频滤波器。Referring to FIG. 9, a diagram of a multi-band compression gain table representing a level and frequency dependent audio filter corresponding to a hearing loss curve is shown, according to an aspect. Each hearing loss curve can be mapped to a corresponding level and frequency dependent audio filter. For example, whichever of the hearing loss curves of the group 602-802 that most closely matches the individual's
在一方面,个人水平和频率相关的音频滤波器402可以是多频带压缩增益表。多频带压缩增益表可以是特定于用户的处方,以补偿个体的听力损失,从而提供个性化媒体增强。在一方面,使用个人水平和频率相关的音频滤波器402来基于输入水平902和输入频率904放大音频输入信号404。可在从低声压水平跨越到高声压水平的范围内确定音频输入信号404的输入水平902。以举例的方式,音频输入信号404可具有在增益表左侧示出的声压水平,该声压水平可为例如20dB。可在可听频率范围内确定音频输入信号404的输入频率904。以举例的方式,音频输入信号404可具有在增益表的顶部的频率,该频率可为例如8kHz。基于音频输入信号404的输入水平902和输入频率904,媒体系统100可确定要将特定增益水平(例如,30dB)应用于音频输入信号404以生成音频输出信号406。应当理解,该示例与图2至图3的听力损失曲线和增益曲线一致。In one aspect, the personal level and frequency
图9的增益表示例示出,对于用户的每个听力损失曲线,可确定或选择对应的水平和频率相关的音频滤波器以补偿用户的听力损失。水平和频率相关的音频滤波器可定义每个输入频率下的增益水平,该增益水平与个体在这些频率下的听力损失反向对应。以举例的方式,具有与第二组702内的平坦损失轮廓706匹配的个人听力图500的用户可具有个人水平和频率相关的音频滤波器402,该音频滤波器在8kHz下比在500Hz下放大音频输入信号404更多。由增益表跨可听频率应用的增益可使由损失轮廓所表示的听力损失无效。The gain table of FIG. 9 illustrates that, for each hearing loss profile of the user, a corresponding level and frequency dependent audio filter may be determined or selected to compensate for the user's hearing loss. Level and frequency dependent audio filters define a gain level at each input frequency that corresponds inversely to an individual's hearing loss at those frequencies. By way of example, a user with a
参考图10,示出了根据一方面的增强音频输入信号以适应听力损失的方法的流程图。媒体系统100可执行该方法以提供音频内容的个性化增强。在操作1002处,媒体系统100的一个或多个处理器可从对应于相应的听力损失曲线的若干水平和频率相关的音频滤波器中选择个人水平和频率相关的音频滤波器402。该选择过程可以各种方式执行。例如,如以上所提及并且如以下相对于图22进一步讨论的,该选择可包括将用户的个人听力图与预设的听力损失曲线进行匹配。然而,可以设想,媒体系统100的一些用户可能不具有可用于匹配的现有听力图。此外,即使当此类听力图可用时,不同用户的响度感知也可能存在超阈值差异。例如,具有类似听力图的两个用户仍然可在给定频率下以不同的方式主观上体验声压水平,例如,第一用户可能对声压水平感到舒服,而第二用户可能会觉得声压水平不舒服。因此,可能有益的是向用户个性化音频滤波器选择而不仅仅依赖于听力图数据。更具体地,用户可能具有听力图数据未完全捕获到的偏好,并且因此,可能有益的是允许用户从不一定与个人听力图精确匹配的不同水平和频率相关的音频滤波器中进行选择。Referring to FIG. 10, a flow diagram of a method of enhancing an audio input signal to accommodate hearing loss is shown according to an aspect. The
在一方面,可使用方便且噪声鲁棒性的注册程序来驱动对适应用户的听力偏好的个人水平和频率相关的音频滤波器的选择。注册程序可回放通过一个或多个预先确定的增益水平和/或一个或多个水平和频率相关的音频滤波器更改的一个或多个音频信号,该一个或多个水平和频率相关的音频滤波器对应于预先确定的人口统计人员的最常见的听力损失曲线。用户可在注册程序期间进行选择,例如,选择水平和频率相关的音频滤波器中的一个或多个,并且通过用户选择,媒体系统100可确定和/或选择适当的个人水平和频率相关的音频滤波器以应用于用户的音频输入信号。以下描述注册程序的若干实施方案。注册程序可结合若干级,并且实施方案的一个或多个级可不同。例如,图11至图15描述了包括其中用户的选择指示回放的音频信号是否是可听的第一级的注册程序,并且图16至图20描述了包括其中用户的选择指示来自具有不同平均增益水平的一组音频滤波器的优选音频滤波器的第一级的注册程序。In one aspect, a convenient and noise-robust registration procedure may be used to drive the selection of individual level and frequency dependent audio filters adapted to the user's hearing preferences. The registration procedure may play back one or more audio signals modified by one or more predetermined gain levels and/or one or more level and frequency dependent audio filters, the one or more level and frequency dependent audio filters The device corresponds to the most common hearing loss profiles of pre-determined demographics. The user may make selections during the registration procedure, eg, select one or more of the level and frequency dependent audio filters, and through the user selection, the
参考图11,示出了根据一方面的用于控制第一音频信号的输出的用户界面的示图。在注册过程期间,媒体系统100可使用一个或多个预先确定的增益水平来输出第一音频信号。预先确定的增益水平可以是标量增益水平(宽带或频率独立的增益),其被应用以允许以不同的响度回放音频信号以供用户收听。例如,媒体系统可生成第一音频信号以供扬声器回放给用户。第一音频信号可表示语音(例如,语音文件),其包含所录制的以来自世界各地的语言说出的问候语。语音在增益水平之间具有良好的对比度(与音乐相比),并且因此可在注册过程的第一级期间促进对适当的平均增益水平的选择。Referring to FIG. 11, a diagram of a user interface for controlling output of a first audio signal is shown according to an aspect. During the registration process, the
在第一级期间,可以第一预先确定的增益水平为用户再现音频输入信号404。例如,可以低水平(例如,40dB或更小)输出语音信号。第一预先确定的增益水平可对应于不同的平均听力损失水平(例如,水平604、704或804)中的一个。例如,具有平均听力损失水平604并且可能不具有听力损失水平704和804的人口统计人员预期可听到40dB或更小的水平。During the first stage, the
在以第一放大水平回放第一音频信号期间,用户可选择在媒体系统100的音频信号设备102上显示的图形用户界面的可听度选择元素1102或不可听度选择元素1104。更具体地,在收听第一设置之后,用户可进行指示输出音频信号是否具有对用户可听的响度的选择。用户可选择可听度选择元素1102以指示输出水平是可听的。相比之下,用户可选择不可听度选择元素1104以指示输出水平是不可听的。During playback of the first audio signal at the first amplification level, the user may select the
在对可听度选择元素1102或不可听度选择元素1104进行选择之后,用户可选择选择元素1106以向系统提供选择。当系统接收到对可听度选择元素1102的选择时,系统可基于指示输出音频信号是否对用户可听的选择来确定用户的个人平均增益水平。例如,当系统在第一级的第一阶段期间接收到对可听度选择元素1102的选择时,系统可确定用户的个人平均增益水平对应于轻度听力损失曲线组的平均听力损失水平604。该听力损失曲线组可用作用于在注册程序的第二级中进一步探索水平和频率相关的音频滤波器的基础。相比之下,在第一阶段期间对不可听度选择元素1104的选择可使注册程序进行到注册程序的第一级的第二阶段。After selection of
在第一级的第二阶段中,可以第二放大水平播放第一音频信号。例如,语音信号可输出更高的水平(例如,55dB)。在收听到第二设置之后,用户可选择可听度选择元素1102或不可听度选择元素1104以指示语音信号是否是可听的。In the second stage of the first stage, the first audio signal may be played at a second amplification level. For example, the speech signal may output a higher level (eg, 55dB). After listening to the second setting, the user may select the
在对可听度选择元素1102或不可听度选择元素1104进行选择之后,用户可选择选择元素1106以向系统提供选择。该系统可基于指示输出音频信号是否对用户可听的选择来确定个人平均增益水平。例如,当系统在第一级的第二阶段期间接收到对可听度选择元素1102的选择时,系统可确定用户的个人平均增益水平对应于轻度至中度听力损失曲线组的平均听力损失水平704。该听力损失曲线组可用作用于在注册程序的第二级中进一步探索水平和频率相关的音频滤波器的基础。相比之下,当系统在第二阶段期间接收到对不可听度选择元素1104的选择时,系统可确定用户的个人平均增益水平对应于中度听力损失曲线组的平均听力损失水平804。该听力损失曲线组可用作用于在注册程序的第二级中进一步探索水平和频率相关的音频滤波器的基础。After selection of
可在第一级期间使用一个或多个预先确定的增益水平以增益增大的顺序生成和/或输出第一音频信号。例如,如上所述,随着用户进行通过注册程序的第一级,可在第一阶段期间以40dB输出第一音频信号,然后在第二阶段期间以55dB输出第一音频信号。可继续使用增大的预定增益水平回放语音信号,直到确定个人平均增益水平。可通过选择可听度选择元素1102或选择不可听度选择元素1104来确定个人平均增益水平。例如,如果用户在以55dB输出语音信号时选择可听度选择元素1102,则确定对应于轻度至中度听力损失曲线的个人平均增益水平。相比之下,如果用户在以55dB输出语音信号之后选择不可听度选择元素1104,则确定对应于中度听力损失曲线的个人平均增益水平。The first audio signal may be generated and/or output in order of increasing gain during the first stage using one or more predetermined gain levels. For example, as described above, as the user progresses through the first stage of the registration procedure, the first audio signal may be output at 40 dB during the first stage and then at 55 dB during the second stage. The speech signal may continue to be played back with increasing predetermined gain levels until an individual average gain level is determined. The individual average gain level may be determined by selecting the
可将第一音频信号设置在校准水平,并且因此可不允许注册过程的第一级期间的音量调节。更具体地,媒体系统100的一个或多个处理器可在第一音频信号的输出期间禁用媒体系统100的音量调节。通过在注册过程的第一级期间锁定媒体系统100的音量控件,补偿听力损失的增益水平可被设置为对应于正测试的常见听力损失曲线的预先确定的增益水平。因此,可使用在评估期间固定的预定水平的语音刺激来探索这些水平。The first audio signal may be set at a calibration level, and therefore volume adjustment during the first stage of the registration process may not be allowed. More specifically, one or more processors of the
参考图12,示出了根据一方面的对用于在注册程序的第二级中进行探索的水平和频率相关的音频滤波器组的选择的示图。注册程序的第一级期间的选择驱动可用于在注册程序的第二级期间进行探索的水平和频率相关的音频滤波器组。Referring to FIG. 12, an illustration of the selection of a level and frequency dependent audio filter bank for exploration in the second stage of the registration procedure is shown in accordance with an aspect. Selection during the first stage of the registration procedure drives the level and frequency dependent audio filter banks that can be used for exploration during the second stage of the registration procedure.
当在注册程序的第一级的第一阶段期间以第一水平(例如,40dB)呈现语音信号时,用户进行选择以指示输出音频信号是否是可听的。对可听度选择元素1102的选择指示第一水平是可听的,并且可被称为第一阶段可听度选择1200。该系统可基于第一阶段可听度选择1200来确定零增益音频滤波器和/或第一组水平和频率相关的音频滤波器(1F、1N和1S)具有等于用户的个人平均增益水平的相应平均增益水平。更具体地,该系统可响应于第一阶段可听度选择1200确定用户的个人平均增益水平是零增益音频滤波器或第一组水平和频率相关音频滤波器(1F、1N和1S)的平均增益水平中的一个。例如,零增益音频滤波器可具有为零的平均增益水平,并且第一组滤波器可具有对应于第一组602听力损失曲线的平均增益水平。可在注册程序的第二级期间探索音频滤波器中的一个或多个,以进一步缩小确定范围,如下所述。When the speech signal is presented at a first level (eg, 40 dB) during the first stage of the first stage of the registration procedure, the user makes a selection to indicate whether the output audio signal is audible. Selection of
当在注册程序的第一级的第二阶段期间以第二水平(例如,55dB)呈现语音信号时,用户进行选择以指示输出音频信号是否是可听的。对可听度选择元素1102的选择指示第二水平是可听的,并且可被称为第二阶段可听度选择1204。该系统可基于第二阶段可听度选择1204来确定第二组水平和频率相关的音频滤波器(2F、2N和2S)具有等于用户的个人平均增益水平的平均增益水平。更具体地,可将用户的个人平均增益水平确定为第二组的平均增益水平。例如,第二组滤波器可具有对应于第二组702听力损失曲线的平均增益水平。可在注册程序的第二级期间探索第二组的音频滤波器中的一个或多个,如下所述。When the speech signal is presented at a second level (eg, 55dB) during the second stage of the first stage of the registration procedure, the user makes a selection to indicate whether the output audio signal is audible. Selection of
在以第二水平呈现语音信号期间对不可听度选择1104的选择指示第二水平是不可听的,并且可被称为第二阶段不可听度选择1206。该系统可基于第二阶段不可听度选择1206来确定第三组水平和频率相关的音频滤波器(3F、3N和3S)具有等于用户的个人平均增益水平的平均增益水平。更具体地,可将用户的个人平均增益水平确定为第三组的平均增益水平。例如,第三组滤波器可具有对应于第三组802听力损失曲线的平均增益水平。可在注册程序的第二级期间探索第三组的音频滤波器中的一个或多个,如下所述。Selection of
在注册过程的第二级中,用户可探索所确定组的水平和频率相关的音频滤波器以选择个人增益轮廓。个人增益轮廓可对应于根据用户喜好调节音频输入信号音调特征的用户优选增益轮廓(平坦轮廓、凹口轮廓或倾斜轮廓)。In the second stage of the registration process, the user may explore the determined set of level and frequency dependent audio filters to select an individual gain profile. The personal gain profile may correspond to a user-preferred gain profile (flat profile, notched profile, or sloping profile) that adjusts the tonal characteristics of the audio input signal according to the user's preference.
参考图13,示出了根据一方面的用于控制第二音频信号的输出的用户界面的示图。在注册过程期间,媒体系统100可使用一组水平和频率相关的音频滤波器来输出第二音频信号。第二音频信号可表示音乐,例如包含所录制音乐的音乐文件。音乐在音色之间提供良好的对比度(与语音相比),并且因此可有利于在注册过程的第二级期间选择适当的增益轮廓。更具体地,在第二级期间播放音乐而不是语音允许准确地确定用户的音色或音调偏好。Referring to FIG. 13, a diagram of a user interface for controlling output of a second audio signal is shown according to an aspect. During the registration process, the
在第二级期间,可针对用户以不同的音调增强设置顺序地再现音频输入信号404。更具体地,使用响应于第一阶段可听度选择1200、第二阶段可听度选择1204或第二阶段不可听度选择1206而确定的水平和频率相关的音频滤波器组来输出第二音频信号。组中的每个成员都可具有不同的增益轮廓。例如,每个组(除零增益音频滤波器之外)都可包括对应于常见听力损失曲线的平坦损失轮廓的平坦音频滤波器、对应于常见听力损失曲线的凹口损失轮廓的凹口音频滤波器以及对应于常见听力损失曲线的倾斜损失轮廓的倾斜音频滤波器。应当理解,参考上面的损失轮廓以及损失轮廓与相应增益轮廓之间的反比关系,平坦音频滤波器的增益轮廓在低频带下具有最高增益,凹口音频滤波器的增益轮廓在中频带下具有最高增益,并且倾斜音频滤波器的增益轮廓在高频带下具有最高增益。将音频滤波器应用于第二音频信号以回放音频信号,使得对应于不同听力损失轮廓的不同频率是明显的。During the second stage, the
用户可选择当前调谐元素1304以利用第一回放设置来播放第二音频信号。例如,当在图12中进行第一阶段可听度选择1200时,可在无音频滤波(零增益滤波器)作为当前调谐的情况下回放第二音频信号。用户可选择更改后的调谐元素1306以利用具有相应增益轮廓的第二音频滤波器来播放第二音频信号,该相应增益轮廓不同于第一设置的增益轮廓。例如,更改后的调谐可利用(1F)音频滤波器播放第二音频信号。当用户已识别出优选设置(例如,允许用户更好地收听第二音频信号的音乐的调谐)时,用户可选择选择元素1106。另选地,用户可通过物理开关进行选择,诸如通过轻击音频信号设备102或音频输出设备104上的按钮。The user may select the
参考图14A,示出了根据一方面的具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。在注册过程的第二级期间,向用户呈现不同的增强设置,并且要求用户选择优选设置。增强设置包括基于在注册过程的第一级期间作出的选择而应用于第二音频信号的水平和频率相关的音频滤波器组。该组中的音频滤波器可对应于具有不同损失轮廓的听力损失曲线。Referring to FIG. 14A, a diagram is shown of a selection of level and frequency dependent audio filters with different gain profiles, according to an aspect. During the second stage of the registration process, the user is presented with different enhanced settings and asked to select a preferred setting. The enhancement settings include a level and frequency dependent audio filter bank applied to the second audio signal based on selections made during the first stage of the registration process. The audio filters in this set may correspond to hearing loss curves with different loss profiles.
在例示的示例中,在图12中进行第二阶段可听度选择1204。因此,该系统可选择第二组水平和频率相关的音频滤波器进行探索。对当前调谐元素1304的选择使用对应于图7的平坦损失轮廓706的平坦增益轮廓(2F)音频滤波器来回放第二音频信号。相比之下,对更改后的调谐元素1306的选择使用对应于图7的凹口损失轮廓708的凹口增益轮廓(2N)音频滤波器来回放第二音频信号。用户可选择优选设置,然后选择选择元素1106以前进到第二级中的下一操作。例如,用户可(如图所示)选择当前调谐元素1304以选择对应于平坦损失轮廓的滤波器并继续进行下一操作。In the illustrated example, a second
注册过程的第二级可能需要在跨图14A的网格的竖直方向上呈现所有增益轮廓设置。更具体地,即使当用户在第二级期间选择当前调谐(例如,(2F)音频滤波器)时,注册过程也可提供当前调谐与后续调谐之间的附加比较。在图14A的网格的列中示出可应用于第二音频信号的后续调谐。更具体地,附加的更改后的调谐可对应于可能的平均增益水平设置中的每一个的倾斜损失轮廓。The second stage of the registration process may require presenting all gain profile settings in the vertical direction across the grid of Figure 14A. More specifically, even when the user selects the current tuning (eg, (2F) audio filter) during the second stage, the registration process may provide additional comparisons between the current tuning and subsequent tunings. Subsequent tunings applicable to the second audio signal are shown in the columns of the grid of Figure 14A. More specifically, the additional modified tuning may correspond to the tilt loss profile for each of the possible average gain level settings.
参考图14B,示出了根据一方面的具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。在注册的第二级中的下一操作处,可通过对应于先前选择的增益轮廓设置和下一增益轮廓设置(2S)的(2F)水平和频率相关的音频滤波器来修改第二音频信号。在一方面,在注册的第二级期间应用于第二音频信号的所有调谐都具有相同的平均增益水平。更具体地,应用于第二音频信号以用于比较音调调节的平坦增益轮廓(2F)、凹口增益轮廓(2N)和倾斜增益轮廓(2S)可全部具有在注册的第一级期间所确定的个人平均增益水平。个人平均增益水平可对应于例如轻度至中度听力损失组曲线的平均增益损失704。当用户已收听到由所有滤波器更改的第二音频信号时,用户可选择优选调谐(例如,更改后的调谐1306)。媒体系统100可接收用户选择作为个人增益轮廓1402的选择。例如,个人增益轮廓1402可为倾斜增益轮廓(2S)。Referring to FIG. 14B, a diagram is shown of a selection of level and frequency dependent audio filters with different gain profiles, according to an aspect. At the next operation in the second stage of registration, the second audio signal may be modified by a (2F) level and frequency dependent audio filter corresponding to the previously selected gain profile setting and the next gain profile setting (2S) . In one aspect, all tunings applied to the second audio signal during the second stage of registration have the same average gain level. More specifically, the flat gain profile (2F), notch gain profile (2N), and sloping gain profile (2S) applied to the second audio signal for comparison pitch adjustment may all have the values determined during the first stage of registration. the average individual gain level. The individual average gain level may correspond to, for example, the
与注册过程的第一级相比,可在第二音频信号的输出期间启用媒体系统100的音量调节。允许音量调节可有助于区分不同音频信号调节的音调特征。更具体地,允许用户使用音量控件1302(图13)调节媒体系统100的音量可允许用户听到每个音调设置之间的差异。因此,注册过程的第二级允许用户使用激励可听频率范围内的所有频率的音乐刺激来探索增益轮廓,并且鼓励音量变化以允许用户区分更改后的音乐刺激的音调特征。Compared to the first stage of the registration process, volume adjustment of the
滤波后的音频信号的呈现序列允许用户逐步通过注册过程以首先确定个人平均增益水平,然后确定个人增益轮廓。更具体地,用户可首先通过选择第一音频信号可听的设置来选择个人平均增益水平,然后通过在沿形状轴的竖直方向上逐步通过网格来选择个人增益轮廓1402。网格的每个正方形都表示具有相应平均增益水平和增益轮廓的水平和频率相关的音频滤波器,并且因此,例示的示例(3×3网格)假设由注册过程产生的个人水平和频率相关的音频滤波器402将是对应于9个常见听力损失曲线的9个水平和频率相关的音频滤波器中的一个。该粒度水平(例如,三个水平组和三个轮廓组)已被示出为一致地引导用户选择用户一致优选的预设,无论所选择的预设是否与其听力损失曲线精确匹配。然而,应当理解,注册过程中使用的预设数量可变化。例如,注册过程的第一级可允许用户逐步通过四个或更多个预先确定的增益水平,以驱动具有个人平均增益水平的音频滤波器组的选择。类似地,可跨网格的形状轴表示更多或更少的增益轮廓,以允许用户评估不同的音调增强。The presentation sequence of the filtered audio signal allows the user to step through the registration process to first determine the personal average gain level and then the personal gain profile. More specifically, the user may first select the personal average gain level by selecting a setting where the first audio signal is audible, and then select the
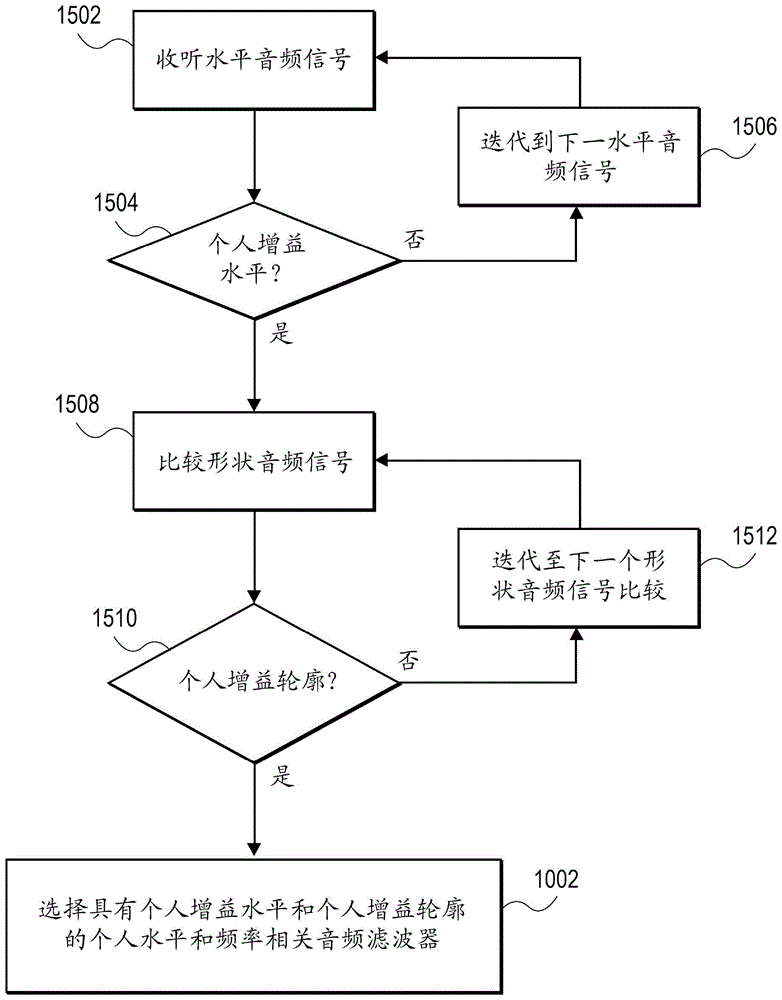
参考图15,示出了根据一方面的选择具有个人平均增益水平和个人增益轮廓的个人水平和频率相关的音频滤波器的方法的流程图。该流程图示出了用于从具有列和行的音频滤波器网格中选择水平和频率相关的音频滤波器的注册过程级。15, a flowchart of a method of selecting a personal level and frequency dependent audio filter having a personal average gain level and a personal gain profile is shown, according to an aspect. The flowchart shows the registration process stages for selecting level and frequency dependent audio filters from an audio filter grid with columns and rows.
如上所述,注册过程允许用户首先探索水平以确定音频滤波器网格内的正确列,以进一步探索轮廓。在操作1502处,在注册过程的第一级中,用户收听预先确定的水平(例如,40dB水平)的音频信号。预定水平是由应用于语音音频信号的预定增益水平产生的呈现水平。在操作1504处,媒体系统100确定用户是否可收听到当前呈现水平。例如,如果用户可收听到由预先确定的增益水平音频滤波器产生的40dB水平,则用户选择可听度选择元素1102以将当前水平识别为对应于个人平均增益水平。在这种情况下,该系统确定个人平均增益水平为零增益滤波器或(1F、1N、1S)音频滤波器组的平均增益水平。然而,如果用户选择不可听度选择元素1104,则在操作1506处,第一决策序列迭代至下一预定水平(例如,55dB水平)。下一预定水平是由应用于语音音频信号的下一预定增益水平产生的呈现水平。可在操作1502处以下一预定水平呈现音频信号。在操作1504处,媒体系统100确定用户是否可收听到当前水平。如果用户可收听到当前水平,则用户选择可听度选择元素1102以将当前水平识别为对应于个人平均增益水平。在这种情况下,系统确定个人平均增益水平是(2F、2N、2S)音频滤波器组的平均增益水平。然而,如果用户选择不可听度选择元素1104,则系统确定个人平均增益水平是(3F、3N、3S)音频滤波器组的平均增益水平。用户在迭代期间将哪一个水平选择为可听的都可用于驱动个人平均增益水平的确定。当用户选择可听水平时,该系统可确定具有对应于所选择的预先确定的增益水平的平均增益水平的用于进一步探索的音频滤波器组。更具体地,可根据可听度选择确定个人平均增益水平,并且注册过程可继续到第二级。As mentioned above, the registration process allows the user to first explore the levels to determine the correct column within the audio filter grid to further explore the contours. At
如上所述,注册过程允许用户探索所选择的音频滤波器组内的增益轮廓以确定音频滤波器网格内的正确行,并且因此到达网格内表示个人水平和频率相关的音频滤波器402的正方形。在操作1508处,在注册过程的第二级中,用户比较若干形状音频信号。As described above, the registration process allows the user to explore the gain profile within the selected audio filter bank to determine the correct row within the audio filter grid, and thus to reach the position within the grid representing the individual level and frequency dependent
在特殊情况下,用户进行第一阶段可听度选择1200,并且系统确定零增益音频滤波器或(1F、1N、1S)音频滤波器组对应于用户的个人平均增益水平。在这种情况下,在决策序列1508处播放音乐文件。在决策序列1508处,可在应用于音乐音频信号的零增益音频滤波器(或无滤波器)与应用于音乐音频信号的低增益平坦音频滤波器(1F)之间进行比较。如果例如经由当前调谐元素1304再次选择零增益音频滤波器,则该过程可迭代以将零增益音频滤波器与低增益凹口音频滤波器(1N)进行比较。如果例如经由当前调谐元素1304再次选择零增益音频滤波器,则注册过程可结束并且不将音频滤波器应用于音频输入信号404。更具体地,当流程图前进通过其中用户选择对应于听力损失曲线的若干水平和相关的音频滤波器上的零增益音频滤波器的序列时,媒体系统100确定用户具有正常听力并且不对系统的默认音频设置进行调节。也可将其构造为个人平均增益水平为零且个人增益轮廓为非调节的个人水平和频率相关的音频滤波器。In a special case, the user makes a first
然而,在用户选择非零个人平均增益水平的情况下,例如,在第一级期间选择第二阶段可听度选择1204或第二阶段不可听度选择1206,或者在第二级的初始操作1508处选择(1F)或(1N)音频滤波器,操作1508处的形状音频信号比较在应用于音乐音频信号的非零增益音频滤波器之间进行。例如,如果第二阶段可听度选择1204驱动对(2F、2N、2S)音频滤波器组的选择以用于进一步探索,则在操作1508处,可将(2F)音频滤波器应用于音乐音频信号作为当前调谐,并且可将低水平凹口音频滤波器(2N)应用于音乐音频信号作为更改后的调谐。可将滤波后的音频信号作为相应的形状音频信号呈现给用户。在操作1510处,媒体系统100确定用户是否已选择了个人增益轮廓1402。在用户已收听所有形状音频信号并选择优选形状音频信号之后,选择个人增益轮廓1402。例如,如果用户在操作1508处选择(2F)音频滤波器而不是(2N)音频滤波器,则(2F)音频滤波器是个人增益轮廓1402的候选者。在操作1512处,第二级迭代至下一形状音频信号比较。例如,可将在先前迭代期间所选择的(2F)音频滤波器应用于音乐音频信号,并且可将低水平倾斜音频滤波器(2S)应用于音乐音频信号。在操作1508处,可将滤波后的音频信号作为相应的形状音频信号呈现给用户,并且用户可选择优选的形状音频信号。在操作1510处,媒体系统100确定用户是否已选择了个人增益轮廓1402。例如,如果用户选择(2S)音频滤波器,则媒体系统100将该选择识别为个人增益轮廓1402,只要用户选择了音频滤波器并且所有形状音频信号都已被呈现给用户以供选择。However, where the user selects a non-zero personal average gain level, for example, during the first stage, the second
在探索水平和轮廓设置之后,在操作1002处,媒体系统选择个人水平和频率相关的音频滤波器402。更具体地,用户例如部分地基于具有从第一级确定的个人平均增益水平的个人水平和频率相关的音频滤波器402,并且部分地基于具有从第二级确定的个人增益轮廓1402的个人水平和频率相关的音频滤波器402来识别网格中的特定正方形。该过程可在验证操作中使用所选择的具有个人平均增益水平和个人增益轮廓1402的滤波器。在验证操作中,可由媒体系统100使用在注册过程期间识别的个人水平和频率相关的音频滤波器402来输出和回放音频信号(例如,音乐音频信号)。验证操作允许用户在所选择的预设播放和正常播放(无调节)之间进行调节,使得用户可确认调节实际上是改进的。当用户同意个人水平和频率相关的音频滤波器改善收听体验时,用户可选择元素(例如,“完成”)以完成注册过程。After exploring level and contour settings, at
在注册过程结束时,个人水平和频率相关的音频滤波器402被识别为具有用户的优选个人平均增益和/或个人增益轮廓1402的音频滤波器。因此,在操作1002处,媒体系统100可部分地基于具有个人平均增益水平的个人水平和频率相关的音频滤波器402并且部分地基于具有个人增益轮廓1402的个人水平和频率相关的音频滤波器402来选择个人水平和频率相关的音频滤波器402,如由注册过程所确定的。At the end of the registration process, the personal level and frequency dependent
在另选的实施方案中,注册程序可不同于以上相对于图11至图15所述的过程。以下相对于图16至图20描述另选的实施方案。与图11和图15的实施方案类似,图16至图20的实施方案允许用户选择水平和频率相关的音频滤波器中的一个或多个,并且通过用户选择,媒体系统100可确定和/或选择适当的个人水平和频率相关的音频滤波器以应用于用户的音频输入信号。参考16,示出了根据一方面的用于控制第一音频信号的输出的用户界面的示图。在注册过程期间,媒体系统100可使用第一组水平和频率相关的音频滤波器来输出第一音频信号。例如,第一音频信号可表示语音(例如,语音文件),其包含所录制的以来自世界各地的语言说出的问候语。语音在增益水平之间具有良好的对比度(与音乐相比),并且因此可在注册过程的第一级期间促进对适当的平均增益水平的选择。在第一级期间,可针对用户以不同的增强设置顺序地再现音频输入信号404。更具体地,可将具有不同平均增益水平的水平和频率相关的音频滤波器应用于第一音频信号,以在对应于不同平均听力损失水平(例如,水平604、704或804)的不同平均增益水平下回放音频信号。In alternative embodiments, the registration procedure may differ from the process described above with respect to FIGS. 11-15 . Alternative embodiments are described below with respect to FIGS. 16-20 . Similar to the embodiments of Figures 11 and 15, the embodiments of Figures 16-20 allow the user to select one or more of the level and frequency dependent audio filters, and through the user selection, the
用户可选择在媒体系统100的音频信号设备102上显示的图形用户界面的当前调谐元素1602来以第一放大水平播放第一音频信号。在收听第一设置之后,用户可选择图形用户界面的更改后的调谐元素1604来以高于第一放大水平的第二放大水平播放第一音频信号。当用户已识别出优选设置(例如,允许用户更好地收听第一音频信号的语音的调谐)时,用户可选择图形用户界面的选择元素1606。另选地,用户可通过物理开关进行选择,诸如通过轻击音频信号设备102或音频输出设备104上的按钮。如果用户在启用了当前调谐元素1602时选择选择元素1606,则该选择可以是个人平均增益水平1702。更具体地,当用户决定使用当前调谐继续注册过程时,个人平均增益水平1702可以是应用于第一音频信号的平均增益水平。另选地,用户可选择继续注册,其中启用了更改后的调谐元素1604。在这种情况下,该选择使注册过程前进到第一级中的下一操作。在下一操作中,可由另一对水平和频率相关的音频滤波器再现第一音频信号。The user may select the
参考图17A,示出了根据一方面的具有不同平均增益水平的水平和频率相关的音频滤波器的选择的示图。在注册过程的第一级期间,向听众呈现不同的增强设置,并且要求听众选择优选设置。增强设置包括应用于第一音频信号的第一组水平和频率相关的音频滤波器,并且这些滤波器可对应于具有不同平均增益水平的听力损失曲线。例如,当前调谐最初可以是零平均增益水平(无增益水平应用到输入信号、或“关”)。更改后的调谐可以是对应于图6的第一组602中的损失轮廓中的一个(第一水平,平坦轮廓)的水平和频率相关的音频滤波器(1F)。应当理解,在图17A的网格的顶行中示出可应用于第一音频信号的后续调谐。更具体地,附加的更改后的调谐(2F)和(3F)对应于图7的第二组702的损失轮廓(第二水平,平坦轮廓)和图8的第三组802的损失轮廓(第三水平,平坦轮廓)。在图17A所示的第一级,用户可收听具有当前调谐和所应用的更改后的调谐的第一音频信号,并且选择更改后的调谐,从而指示用户偏好将更多增益应用于第一音频信号。参考图17B,示出了根据一方面的具有不同平均增益水平的水平和频率相关的音频滤波器的选择的示图。在注册的第一级中的下一操作处,可由(1F)水平和频率相关的音频滤波器作为当前调谐来修改第一音频信号。也可由(2F)水平和频率相关的音频滤波器作为更改后的调谐来修改第一音频信号。在一方面,在注册的第一级期间应用于第一音频信号的所有调谐都具有相同的增益轮廓。例如,调谐可以是对应于图6至图8所示的平坦损失轮廓的滤波器,并且因此可全部具有平坦增益轮廓(与平坦损失轮廓负相关)。因此,图17B中的当前调谐可具有对应于图6的平均损失水平604的平均增益水平,并且更改后的调谐可具有对应于图7的平均损失水平704的平均增益水平。当用户已收听到由这两个滤波器更改后的第一音频信号时,用户可选择当前调谐作为优选调谐。媒体系统100可接收用户选择作为对个人平均增益水平1702的选择(例如,20dB)。Referring to FIG. 17A, a diagram is shown of a selection of level and frequency dependent audio filters with different average gain levels, according to an aspect. During the first stage of the registration process, the listener is presented with different enhancement settings and asked to select a preferred setting. The enhancement settings include a first set of level and frequency dependent audio filters applied to the first audio signal, and these filters may correspond to hearing loss curves having different average gain levels. For example, the current tuning may initially be a zero average gain level (no gain level applied to the input signal, or "off"). The modified tuning may be a level and frequency dependent audio filter (IF) corresponding to one of the loss profiles in the
应当理解,如果用户更喜欢图17B中的更改后的调谐,则选择更改后的调谐将使得注册过程前进到第一级中的下一操作。在下一操作中,可使用对应于图7和图8中的损失轮廓的水平和频率相关的音频滤波器(2F)和(3F)来再现第一音频信号。为简明起见,这里省略了对这种操作的描述。It should be understood that if the user prefers the modified tuning in Figure 17B, selecting the modified tuning will cause the registration process to advance to the next operation in the first level. In the next operation, the first audio signal may be reproduced using level and frequency dependent audio filters ( 2F ) and ( 3F ) corresponding to the loss profiles in FIGS. 7 and 8 . For the sake of brevity, the description of such operations is omitted here.
在一方面,使用第一组的水平和频率相关音频滤波器以平均增益水平增大的顺序将第一音频信号输出给用户。例如,在图17A中,呈现具有零增益的当前调谐和对应于图6的平均听力损失604(例如,20dB的平均增益水平)的更改后的调谐(1F)的第一音频信号。在图17B中,呈现具有对应于图6和图7的平均听力损失(例如,20dB和35dB的平均增益水平)的调谐(1F)和(2F)的第一音频信号。因此,可以增益增大的顺序呈现音频信号更改。应当理解,如上所述,以增大顺序呈现音频信号水平比较可加快注册过程。更具体地,由于用户想要第三增益水平比想要第一增益水平更多,但不是想要第二增益水平比想要第一增益水平更多的情况不常见,因此如果用户已选择第一增益水平而不是第二增益水平,则呈现第三增益水平没有意义。消除附加比较(将第三增益水平与第一增益水平进行比较)可缩短注册过程。In one aspect, the first audio signal is output to the user in order of increasing average gain level using the first set of level and frequency dependent audio filters. For example, in FIG. 17A , a first audio signal with a current tuning of zero gain and an altered tuning (IF) corresponding to the
在一方面,第一音频信号可嵌入有一些噪声以便为收听体验提供真实感。以举例的方式,第一音频信号可包括表示语音的语音信号和表示噪声的噪声信号。语音信号和噪声信号可以特定比率嵌入,使得第一音频信号的水平的增加引起语音文件中的语音和噪声音频内容两者的水平的上升。例如,语音信号与噪声信号的比率可在10dB至30dB的范围内(例如,15dB)。该比率可足够高,使得噪声不会使语音过功率。然而,随着平均增益水平的每次增加,噪声的渐进式放大可阻止用户选择不必要地提高音频信号的音量的水平和频率相关的音频滤波器。更具体地,嵌入噪声提供真实感以帮助用户选择补偿但不过度补偿用户的听力损失的放大水平。In an aspect, the first audio signal may have some noise embedded in it to provide realism to the listening experience. By way of example, the first audio signal may include a speech signal representing speech and a noise signal representing noise. The speech signal and the noise signal may be embedded at a certain ratio such that an increase in the level of the first audio signal causes an increase in the level of both speech and noise audio content in the speech file. For example, the ratio of speech signal to noise signal may be in the range of 10dB to 30dB (eg, 15dB). The ratio can be high enough so that the noise does not overpower the speech. However, with each increase in the average gain level, the progressive amplification of noise may prevent the user from selecting levels and frequency dependent audio filters that unnecessarily increase the volume of the audio signal. More specifically, the embedded noise provides a sense of realism to help the user select a level of amplification that compensates for, but does not overcompensate for, the user's hearing loss.
可将第一音频信号设置在校准水平,并且因此可不允许注册过程的第一级期间的音量调节。更具体地,媒体系统100的一个或多个处理器可在第一音频信号的输出期间禁用媒体系统100的音量调节。通过在注册过程的第一级期间锁定媒体系统100的音量控件,可将补偿听力损失的增益水平设置为对应于正测试的常见听力损失曲线的水平和频率相关的音频滤波器的平均增益水平。因此,可使用固定水平的语音刺激来探索水平。The first audio signal may be set at a calibration level, and therefore volume adjustment during the first stage of the registration process may not be allowed. More specifically, one or more processors of the
除了允许在第一级期间选择个人平均增益水平1702之外,注册过程还可包括第二级以选择个人增益轮廓。个人增益轮廓可对应于根据用户喜好调节音频输入信号音调特征的用户优选增益轮廓(平坦轮廓、凹口轮廓或倾斜轮廓)。In addition to allowing selection of a personal
参考18,示出了根据一方面的用于控制第二音频信号的输出的用户界面的示图。在注册过程期间,媒体系统100可使用第二组水平和频率相关的音频滤波器来输出第二音频信号。第二音频信号可表示音乐,例如包含所录制音乐的音乐文件。音乐在音色之间提供良好的对比度(与语音相比),并且因此可有利于在注册过程的第二级期间选择适当的增益轮廓。更具体地,在第二级期间播放音乐而不是语音允许准确地确定用户的音色或音调偏好。Referring to 18, an illustration of a user interface for controlling output of a second audio signal is shown according to an aspect. During the registration process, the
在第二级期间,可针对用户以不同的音调增强设置顺序地再现音频输入信号404。更具体地,用于输出第二音频信号的第二组水平和频率相关的音频滤波器可具有不同的增益轮廓。第二组可包括对应于常见听力损失曲线的平坦损失轮廓的平坦音频滤波器、对应于常见听力损失曲线的凹口损失轮廓的凹口音频滤波器以及对应于常见听力损失曲线的倾斜损失轮廓的倾斜音频滤波器。应当理解,参考上面的损失轮廓以及损失轮廓与相应增益轮廓之间的反比关系,平坦音频滤波器的增益轮廓在低频带下具有最高增益,凹口音频滤波器的增益轮廓在中频带下具有最高增益,并且倾斜音频滤波器的增益轮廓在高频带下具有最高增益。将音频滤波器应用于第二音频信号以回放音频信号,使得对应于不同听力损失轮廓的不同频率是明显的。During the second stage, the
用户可选择当前调谐元素1602以利用具有相应增益轮廓的第一音频滤波器播放第二音频信号。在收听第一设置之后,用户可选择更改后的调谐元素1604以利用具有相应增益轮廓的第二音频滤波器播放第二音频信号,该相应增益轮廓不同于第一音频滤波器的增益轮廓。当用户已识别出优选设置(例如,允许用户更好地收听第二音频信号的音乐的调谐)时,用户可选择选择元素1606。另选地,用户可通过物理开关进行选择,诸如通过轻击音频信号设备102或音频输出设备104上的按钮。The user may select the
参考图19A,示出了根据一方面的具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。在注册过程的第二级期间,向听众呈现不同的增强设置,并且要求听众选择优选设置。增强设置包括应用于第二音频信号的第二组水平和频率相关的音频滤波器,并且这些滤波器可对应于具有不同损失轮廓的听力损失曲线。例如,当前调谐最初可以是对应于图6的平坦损失轮廓606的平坦增益轮廓(1F)。更改后的调谐可以是对应于图6的凹口损失轮廓608的(1N)水平和频率相关的音频滤波器。用户可能更喜欢对应于平坦损失轮廓的滤波器,并且可选择选择元素1606以前进到第二级中的下一操作。Referring to FIG. 19A, a diagram is shown of a selection of level and frequency dependent audio filters with different gain profiles, according to an aspect. During the second stage of the registration process, the listener is presented with different enhancement settings and asked to select a preferred setting. The enhancement settings include a second set of level and frequency dependent audio filters applied to the second audio signal, and these filters may correspond to hearing loss curves with different loss profiles. For example, the current tuning may initially be a flat gain profile ( IF ) corresponding to
注册过程的第一级不需要呈现所有平均增益水平设置(如在跨图17A的网格的水平方向上所表示),而注册过程的第二级可能需要在跨图19A的网格的竖直方向上呈现所有增益轮廓设置。更具体地,即使当用户在第二级期间选择当前调谐时,注册过程也可提供当前调谐与后续调谐之间的附加比较。在图19A的网格的列中示出可应用于第二音频信号的后续调谐。更具体地,附加的更改后的调谐可对应于可能的平均增益水平设置中的每一个的倾斜损失轮廓。The first stage of the registration process need not present all average gain level settings (as represented in the horizontal direction across the grid of FIG. 17A ), while the second stage of the registration process may need to be in the vertical direction across the grid of FIG. 19A All gain profile settings are rendered in the direction. More specifically, even when the user selects the current tuning during the second stage, the registration process may provide additional comparisons between the current tuning and subsequent tunings. Subsequent tunings applicable to the second audio signal are shown in the columns of the grid of Figure 19A. More specifically, the additional modified tuning may correspond to the tilt loss profile for each of the possible average gain level settings.
参考图14B,示出了根据一方面的具有不同增益轮廓的水平和频率相关的音频滤波器的选择的示图。在注册的第二级中的下一操作处,可通过对应于先前选择的增益轮廓设置和下一增益轮廓设置(1S)的(1F)水平和频率相关的音频滤波器来修改第二音频信号。在一方面,在注册的第二级期间应用于第二音频信号的所有调谐都具有相同的平均增益水平。更具体地,应用于第二音频信号以用于比较音调调节的平坦增益轮廓(1F)、凹口增益轮廓(1N)和倾斜增益轮廓(1S)可全部具有在注册的第一级期间所选择的个人平均增益水平1702。当用户已收听到由所有滤波器更改的第二音频信号时,用户可选择优选调谐(例如,更改后的调谐)。媒体系统100可接收用户选择作为个人增益轮廓1902的选择。例如,个人增益轮廓1902可为倾斜增益轮廓(1S)。Referring to FIG. 14B, a diagram is shown of a selection of level and frequency dependent audio filters with different gain profiles, according to an aspect. At the next operation in the second stage of registration, the second audio signal may be modified by a (1F) level and frequency dependent audio filter corresponding to the previously selected gain profile setting and the next gain profile setting (1S) . In one aspect, all tunings applied to the second audio signal during the second stage of registration have the same average gain level. More specifically, the flat gain profile (1F), the notch gain profile (1N), and the sloping gain profile (1S) applied to the second audio signal for comparison pitch adjustment may all have the ones selected during the first stage of registration The average personal gain level of 1702. When the user has heard the second audio signal modified by all filters, the user may select a preferred tuning (eg, modified tuning). The
与注册过程的第一级相比,可在第二音频信号的输出期间启用媒体系统100的音量调节。允许音量调节可有助于区分不同音频信号调节的音调特征。更具体地,允许用户使用音量控件2302(图18)调节媒体系统100的音量可允许用户听到每个音调设置之间的差异。因此,注册过程的第二级允许用户使用激励可听频率范围内的所有频率的音乐刺激来探索增益轮廓,并且鼓励音量变化以允许用户区分更改后的音乐刺激的音调特征。Compared to the first stage of the registration process, volume adjustment of the
滤波后的音频信号的呈现序列允许用户在第一级期间在水平方向上逐步通过网格,并且在第二级期间在竖直方向上逐步通过网格。更具体地,用户可首先通过沿水平轴在水平方向上逐步通过网格来选择个人平均增益水平1702,然后通过沿形状轴在竖直方向上逐步通过网格来选择个人增益轮廓1902。网格的每个正方形都表示具有相应平均增益水平和增益轮廓的水平和频率相关的音频滤波器,并且因此,例示的示例(3×3网格)假设由注册过程产生的个人水平和频率相关的音频滤波器402将是对应于9个常见听力损失曲线的9个水平和频率相关的音频滤波器中的一个。该粒度水平(例如,三个水平组和三个轮廓组)已被示出为一致地引导用户选择用户一致优选的预设,无论所选择的预设是否与其听力损失曲线精确匹配。然而,应当理解,注册过程中使用的预设数量可变化。例如,注册过程的第一级可允许用户跨具有更多列的网格逐步通过四个或更多个平均增益水平。类似地,可跨网格的形状轴表示更多或更少的增益轮廓,以允许用户评估不同的音调增强。The presentation sequence of the filtered audio signal allows the user to step through the grid in the horizontal direction during the first stage and vertically through the grid during the second stage. More specifically, the user may first select the personal
参考图20,示出了根据一方面的选择具有个人平均增益水平和个人增益轮廓的个人水平和频率相关的音频滤波器的方法的流程图。该流程图示出了用于从具有列和行的音频滤波器网格中选择水平和频率相关的音频滤波器的注册过程级。Referring to FIG. 20, a flow diagram of a method of selecting a personal level and frequency dependent audio filter having a personal average gain level and a personal gain profile is shown, according to an aspect. The flowchart shows the registration process stages for selecting level and frequency dependent audio filters from an audio filter grid with columns and rows.
如上所述,注册过程允许用户首先探索水平以确定音频滤波器网格内的正确列。在操作2002处,在注册过程的第一级中,用户比较若干水平音频信号,例如当前增益水平和下一增益水平。例如,可将零增益音频滤波器(无增益或“关”)作为当前增益水平应用于语音音频信号,并且可将低增益平坦音频滤波器(1F)作为下一增益水平应用于语音音频信号。可将滤波后的音频信号作为相应水平音频信号呈现给用户。在操作2004处,媒体系统100确定用户是否对当前水平满意。例如,如果用户对零增益音频滤波器满意,则用户选择零增益音频滤波器作为个人增益水平1702。然而,如果用户在操作2006处选择下一音频水平(例如(1F)水平和频率相关的音频滤波器),则第一决策序列迭代至下一水平音频信号比较。例如,可将(1F)滤波器作为当前增益水平应用于语音音频信号,并且可将中等增益平坦音频滤波器(2F)作为下一增益水平应用于语音音频信号。可在操作2002处将滤波后的音频信号作为相应水平音频信号呈现给用户,并且用户可选择优选水平音频信号。在操作2004处,媒体系统100确定用户是否对当前水平满意。如果用户对当前水平满意,则用户选择当前水平,系统将该当前水平确定为个人增益水平1702。如果用户对下一水平更满意,则用户选择下一增益水平,并且系统迭代以允许比较下一组水平音频信号。例如,该序列前进以允许用户还比较中等增益平坦音频滤波器(2F)和高增益平坦音频滤波器(3F)。用户在迭代期间所选择的当前水平中无论哪一个都可被确定为个人平均增益水平1702。更具体地,当用户在该过程中在所选择的滤波器为当前音频滤波器(与下一音频滤波器相比)时的点处选择零增益音频滤波器、(1F)滤波器、(2F)滤波器或(3F)滤波器时,可确定所选择的音频滤波器具有个人增益轮廓1702并且该注册过程可继续到第二级。As mentioned above, the registration process allows the user to first explore the levels to determine the correct column within the audio filter grid. At
如上所述,注册过程允许用户探索所选择的增益水平内的增益轮廓以确定音频滤波器网格内的正确行,并且因此到达网格内表示个人水平和频率相关的音频滤波器402的正方形。在操作2008处,在注册过程的第二级中,用户比较若干形状音频信号。As described above, the registration process allows the user to explore the gain profile within the selected gain level to determine the correct row within the audio filter grid, and thus arrive at the square within the grid representing the personal level and frequency dependent audio filters 402 . At
在特殊情况下,用户在第一级期间选择零增益音频滤波器作为个人增益水平。在这种情况下,在决策序列2008处播放语音文件。与决策序列2002类似,在决策序列2008处,可在应用于语音音频信号的零增益音频滤波器与应用于语音音频信号的低增益凹口音频滤波器(1N)之间进行比较。如果再次选择零增益音频滤波器,则该过程可迭代以将零增益音频滤波器与高增益倾斜音频滤波器(1S)进行比较。如果再次选择零增益音频滤波器,则该注册过程可结束并且不将音频滤波器应用于音频输入信号404。更具体地,当流程图前进通过其中用户选择对应于听力损失曲线的若干水平和相关的音频滤波器上的零增益音频滤波器的序列时,媒体系统100确定用户具有正常听力并且不对系统的默认音频设置进行调节。In special cases, the user selects a zero-gain audio filter as the personal gain level during the first stage. In this case, at
在用户在第一级期间选择非零个人增益水平的情况下,操作2008处的形状音频信号比较在应用于音乐音频信号的非零增益音频滤波器之间进行。例如,如果在操作2004处选择(1F)音频滤波器作为个人增益水平,则在操作2008处,可将(1F)音频滤波器应用于音乐音频信号并且可将低水平凹口音频滤波器(1N)应用于音乐音频信号。可将滤波后的音频信号作为相应的形状音频信号呈现给用户。在操作2010处,媒体系统100确定用户是否已选择了个人增益轮廓1902。在用户已收听所有形状音频信号并选择优选形状音频信号之后,选择个人增益轮廓1902。例如,如果用户在操作2008处选择(1F)音频滤波器而不是(1N)音频滤波器,则(1F)音频滤波器是个人增益轮廓1902的候选者。在操作2012处,第二级迭代至下一形状音频信号比较。例如,可将在先前迭代期间所选择的(1F)音频滤波器应用于音乐音频信号,并且可将低水平倾斜音频滤波器(1S)应用于音乐音频信号。可在操作2008处将滤波后的音频信号作为相应形状音频信号呈现给用户,并且用户可选择优选的形状音频信号。在操作2010处,媒体系统100确定用户是否已选择个人增益轮廓1902。例如,如果用户选择(1S)音频滤波器,则媒体系统100将该选择识别为个人增益轮廓1902,只要用户选择了音频滤波器并且所有形状音频信号都已被呈现给用户以供选择。Where the user selects a non-zero personal gain level during the first stage, the shape audio signal comparison at
在探索水平和轮廓设置之后,在操作1002处,媒体系统选择个人水平和频率相关的音频滤波器402。更具体地,用户例如部分地基于具有个人平均增益水平1702的个人水平和频率相关的音频滤波器402,并且部分地基于具有个人增益轮廓1902的个人水平和频率相关的音频滤波器402来识别网格中的特定正方形。该过程可在验证操作中使用所选择的具有个人增益水平1702和个人增益轮廓1902的滤波器。在验证操作中,可由媒体系统100使用在注册过程期间识别的个人水平和频率相关的音频滤波器402来输出和回放音频信号(例如,音乐音频信号)。验证操作允许用户在所选择的预设播放和正常播放(无调节)之间进行调节,使得用户可确认调节实际上是改进的。当用户同意个人水平和频率相关的音频滤波器改善收听体验时,用户可选择元素(例如,“完成”)以完成注册过程。After exploring level and contour settings, at
在注册过程结束时,个人水平和频率相关的音频滤波器402被识别为具有用户的优选个人平均增益水平1702和个人增益轮廓1902的音频滤波器。因此,在操作1002处,媒体系统100可部分地基于具有个人平均增益水平1702的个人水平和频率相关的音频滤波器402并且部分地基于具有个人增益轮廓1902的个人水平和频率相关的音频滤波器402来选择个人水平和频率相关的音频滤波器402,如由注册过程所确定的。At the end of the registration process, the personal level and frequency
上述注册过程驱动媒体系统100基于假设用户的实际听力损失将类似于由系统存储的常见听力损失曲线预设来选择个人水平和频率相关的音频滤波器402。完成注册过程不需要知道用户的个人听力图500。然而,当个人听力图500可用时,其可导致与上述选择过程一样好或更好的结果。The registration process described above drives the
参考图21A至图21B,分别示出了根据一方面的基于个人听力图确定若干听力损失曲线的方法的流程图和示图。Referring to FIGS. 21A-21B , a flowchart and diagram, respectively, of a method of determining several hearing loss curves based on a personal audiogram according to an aspect are shown.
与存储用于上述注册过程的一般预设相比,个人听力图500可用于确定特定于用户的预设。例如,如果个人听力图500是已知的,则媒体系统100可选择涵盖已知听力图的听力损失曲线预设以及对应的水平和频率相关的音频滤波器。对特定于用户的预设的确定可约束在注册过程期间可供选择的水平和频率相关的音频滤波器的范围,这可允许用户对个人预设的选择具有更大的粒度。The
在一方面,使用个人听力图500来驱动在注册过程期间可供选择的预设对于具有不常见的听力损失曲线的用户可能特别有帮助。媒体系统100可在操作2102处接收个人听力图500。在操作2104处,媒体系统100可基于个人听力图500来确定若干听力损失曲线2110。类似地,在操作2106处,媒体系统100可确定对应于特定于用户的听力损失曲线预设的水平和频率相关的音频滤波器。所确定的听力损失曲线和/或水平和频率相关的音频滤波器可以是针对用户而个性化的特定于用户的预设,以确保良好的收听体验。例如,可从个人听力图500确定用户的平均听力损失504,并且所确定的若干特定于用户的预设可包括听力损失曲线,这些听力损失曲线各自具有类似于个人听力图500的平均听力损失值的平均听力损失值。在一方面,特定于用户的预设中的每一个的平均听力损失值在个人听力图500的平均听力损失值的预定差异内(例如,+/-10dB听力损失)。如图21B所示,特定于用户的预设中的每一个都可具有不同的听力损失轮廓,即使预设的平均损失水平相似。例如,听力损失曲线中的一个可具有随频率增加而逐渐减小的平坦损失轮廓2112,听力损失曲线中的一个可具有在约4kHz处具有向上拐点的平坦损失轮廓2114,并且听力损失曲线中的一个可具有在约2kHz处具有向下拐点的平坦损失轮廓2116。此类损失轮廓在人群中可能是不常见的,但媒体系统100可在注册过程期间使用对应于不常见轮廓的音频滤波器。In one aspect, using the
在一方面,将所确定的对应于特定于用户的预设的水平和频率相关的音频滤波器应用于语音和/或音乐音频信号。更具体地,可在决策树诸如相对于图20所述的序列中评估音频滤波器。使用注册过程,用户可将音频滤波器中的一个识别为用于补偿用户的听力损失的个人水平和频率相关的音频滤波器402。因此,在操作2108处,从若干水平和频率相关的音频滤波器2110中选择个人水平和频率相关的音频滤波器402以供在操作1004(图10)处使用。In one aspect, the determined level and frequency dependent audio filter corresponding to the user-specific preset is applied to the speech and/or music audio signal. More specifically, audio filters may be evaluated in a decision tree such as the sequence described with respect to FIG. 20 . Using the registration process, the user may identify one of the audio filters as a personal level and frequency
参考图22A至图22B,分别示出了根据一方面的基于个人听力图确定个人听力损失曲线的方法的流程图和示图。可使用个人听力图500来从音频信号设备102存储和/或可用的预设范围中选择特定的听力损失曲线和对应的水平和频率相关的音频滤波器。更具体地,可使用个人听力图500来确定最密切对应于已知听力图的预设。Referring to FIGS. 22A-22B , a flowchart and diagram, respectively, of a method for determining an individual's hearing loss profile based on an individual's audiogram according to an aspect are shown. The
在一方面,在操作2202处,媒体系统100可接收个人听力图500。在操作2204处,媒体系统100可基于个人听力图500确定和/或选择个人听力损失曲线2205。例如,可从媒体系统100存储或可用的若干听力损失曲线中选择个人听力损失曲线2205。可通过用于将个人听力图500拟合到已知听力损失曲线的算法驱动对个人听力损失曲线2205的选择。更具体地,媒体系统100可选择具有与个人听力图500相同的平均听力损失和听力损失曲线的个人听力损失曲线2205。当找到最密切匹配时,媒体系统100可选择个人听力损失曲线2205并且确定对应于个人听力损失曲线2205的水平和频率相关的音频滤波器。更具体地,在操作2206处,媒体系统100可选择或确定对应于个人听力损失曲线2205的个人水平和频率相关的音频滤波器402,这可用于补偿用户的听力损失。In an aspect, at
在操作1004(图10)处,将使用上述选择过程中的一个所选择的个人水平和频率相关的音频滤波器402应用于音频输入信号404。将个人水平和频率相关的音频滤波器402应用于音频输入信号404可生成音频输出信号406。更具体地,个人水平和频率相关的音频滤波器402可基于音频输入信号404的输入水平902和输入频率904来放大音频输入信号404。放大可以允许用户正常感知音频输入信号404的方式增强音频输入信号404。At operation 1004 (FIG. 10), a personal level and frequency
在操作1006(图10)处,由媒体系统100的一个或多个处理器输出音频输出信号406。可输出音频输出信号406以供输出设备回放。例如,音频信号设备102可通过有线或无线连接将音频输出信号406传输到音频输出设备104。音频输出设备104可接收音频输出信号406并向用户播放音频内容。再现的音频可以是来自电话呼叫的音频、由个人媒体设备播放的音乐、虚拟助理的语音或由音频信号设备102递送到音频输出设备104的任何其他音频内容。At operation 1006 ( FIG. 10 ), an
参考图23,示出了根据一方面的媒体系统的框图。音频信号设备102可以是具有适于特定功能的电路的若干类型的便携式设备或装置中的任一种。因此,提供图示的电路作为实施例而非限制。音频信号设备102可包括一个或多个设备处理器2302以执行指令,从而执行以上所述的不同功能和能力。可从设备存储器2304检索由音频信号设备102的设备处理器2302执行的指令,该设备存储器可包括非暂态机器可读介质或非暂态计算机可读介质。指令可为具有设备驱动程序和/或可访问性引擎的操作系统程序的形式,该可访问性引擎用于根据上述方法执行注册过程并且基于个人水平和频率相关的音频滤波器402来调谐音频输入信号404。设备处理器2302还可从设备存储器2304检索音频数据2306,包括与电话相关联的听力图或音频信号和/或由操作系统顶部运行的电话或音乐应用控制的音乐回放功能。为了执行此类功能,设备处理器2302可直接或间接地实现控制回路并从其他电子部件接收输入信号和/或向其他电子部件提供输出信号。例如,音频信号设备102可从麦克风、菜单按钮或物理开关接收输入信号。音频信号设备102可生成音频输出信号406并将其输出到音频信号设备102的设备扬声器(其可为内部音频输出设备104)和/或输出到外部音频输出设备104。例如,音频输出设备104可以是有线或无线听筒,以经由有线或无线通信链路接收音频输出信号406。更具体地,音频信号设备102和音频输出设备104的处理器可连接到相应的RF电路以接收和处理音频信号。例如,可通过使用蓝牙标准的无线连接来建立通信链路,并且设备处理器2302可经由通信链路将音频输出信号406无线传输到音频输出设备104。无线输出设备可接收并处理音频输出信号406以将音频内容播放为声音,例如电话呼叫、播客、音乐等。更具体地,音频输出设备104可接收并回放音频输出信号406以播放来自听筒扬声器的声音。23, a block diagram of a media system according to an aspect is shown. The
音频输出设备104可包括听筒处理器2320和听筒存储器2322。听筒处理器2320和听筒存储器2322可执行由上述设备处理器2302和设备存储器2304执行的功能。例如,音频信号设备102可将音频输入信号404、听力损失曲线或水平和频率相关的音频滤波器中的一者或多者传输到听筒处理器2320,并且音频输出设备104可在注册过程和/或音频再现过程中使用输入信号来使用个人水平和频率相关的音频滤波器402生成音频输出信号406。更具体地,听筒处理器2320可被配置为生成音频输出信号406并经由听筒扬声器呈现信号以进行音频回放。媒体系统100可包括若干听筒部件,但在图23中仅示出了单个听筒。因此,第一音频输出设备104可被配置为呈现左声道音频输出,并且第二音频输出设备104可被配置为呈现右声道音频输出。
如上所述,本发明技术的一个方面在于收集和使用得自各种来源的数据以执行个性化媒体增强。本公开预期,在一些实例中,这些所采集的数据可包括唯一地识别或可用于联系或定位特定人员的个人信息数据。此类个人信息数据可包括人口统计数据、基于位置的数据、电话号码、电子邮件地址、TWITTER ID、家庭地址、与用户的健康或健身等级相关的数据或记录(例如,听力图、生命信号测量、药物信息、锻炼信息)、出生日期、或任何其他识别信息或个人信息。As described above, one aspect of the present technology resides in the collection and use of data from various sources to perform personalized media enhancements. This disclosure contemplates that, in some instances, these collected data may include personal information data that uniquely identifies or may be used to contact or locate a particular person. Such personal information data may include demographic data, location-based data, phone numbers, email addresses, TWITTER IDs, home addresses, data or records related to the user's health or fitness level (eg, audiograms, vital signal measurements) , medication information, exercise information), date of birth, or any other identifying or personal information.
本公开认识到在本发明技术中使用此类个人信息数据可用于使用户受益。例如,个人信息数据可用于执行个性化媒体增强。相应地,此类个人信息数据的使用使得用户能够具有改善的音频收听体验。此外,本公开还预期个人信息数据有益于用户的其他用途。例如,健康和健身数据可用于向用户的总体健康状况提供见解,或者可用作使用技术来追求健康目标的个人的积极反馈。This disclosure recognizes that the use of such personal information data in the present technology can be used to benefit users. For example, personal information data can be used to perform personalized media enhancements. Accordingly, the use of such personal information data enables the user to have an improved audio listening experience. In addition, this disclosure also contemplates other uses of personal information data that benefit the user. For example, health and fitness data can be used to provide insights into a user's overall health, or can be used as positive feedback for individuals using technology to pursue health goals.
本公开设想负责采集、分析、公开、传输、存储或其他使用此类个人信息数据的实体将遵守既定的隐私政策和/或隐私实践。具体地,此类实体应当实行并坚持使用被公认为满足或超出对维护个人信息数据的隐私性和安全性的行业或政府要求的隐私政策和实践。此类政策应该能被用户方便地访问,并应随着数据的采集和/或使用变化而被更新。来自用户的个人信息应当被收集用于实体的合法且合理的用途,并且不在这些合法使用之外共享或出售。此外,应在收到用户知情同意后进行此类采集/共享。此外,此类实体应考虑采取任何必要步骤,保卫和保障对此类个人信息数据的访问,并确保有权访问个人信息数据的其他人遵守其隐私政策和流程。另外,这种实体可使其本身经受第三方评估以证明其遵守广泛接受的隐私政策和实践。此外,应当调整政策和实践,以便采集和/或访问的特定类型的个人信息数据,并适用于包括管辖范围的具体考虑的适用法律和标准。例如,在美国,对某些健康数据的收集或获取可能受联邦和/或州法律的管辖,诸如健康保险流通和责任法案(HIPAA);而其他国家的健康数据可能受到其他法规和政策的约束并应相应处理。因此,在每个国家应为不同的个人数据类型保持不同的隐私实践。This disclosure contemplates that entities responsible for collecting, analyzing, disclosing, transmitting, storing, or otherwise using such personal information data will comply with established privacy policies and/or privacy practices. Specifically, such entities should implement and adhere to privacy policies and practices that are recognized as meeting or exceeding industry or governmental requirements for maintaining the privacy and security of personal information data. Such policies should be easily accessible to users and should be updated as data collection and/or usage changes. Personal information from users should be collected for the entity's lawful and reasonable uses and not shared or sold outside of those lawful uses. In addition, such collection/sharing should take place after the informed consent of the user has been received. In addition, such entities should consider taking any necessary steps to safeguard and secure access to such personal information data and ensure that others who have access to personal information data comply with their privacy policies and procedures. Additionally, such entities may subject themselves to third-party assessments to demonstrate compliance with generally accepted privacy policies and practices. In addition, policies and practices should be adjusted for the specific types of personal information data collected and/or accessed, and for applicable laws and standards including jurisdiction-specific considerations. For example, in the United States, the collection or acquisition of certain health data may be governed by federal and/or state laws, such as the Health Insurance Portability and Accountability Act (HIPAA); while health data in other countries may be governed by other regulations and policies and should be dealt with accordingly. Therefore, different privacy practices should be maintained in each country for different types of personal data.
不管前述情况如何,本公开还预期用户选择性地阻止使用或访问个人信息数据的各方面。即本公开预期可提供硬件元件和/或软件元件,以防止或阻止对此类个人信息数据的访问。例如,就个性化媒体增强而言,本发明技术可被配置为在注册服务期间或之后任何时候允许用户选择“选择加入”或“选择退出”参与对个人信息数据的收集。除了提供“选择加入”和“选择退出”选项外,本公开设想提供与访问或使用个人信息相关的通知。例如,可在下载应用时向用户通知其个人信息数据将被访问,然后就在个人信息数据被应用访问之前再次提醒用户。Regardless of the foregoing, the present disclosure also contemplates that users selectively block aspects of the use or access to personal information data. That is, the present disclosure contemplates that hardware elements and/or software elements may be provided to prevent or block access to such personal information data. For example, with respect to personalized media enhancements, the present techniques may be configured to allow a user to choose to "opt-in" or "opt-out" of participation in the collection of personal information data during registration for the service or at any time thereafter. In addition to providing "opt-in" and "opt-out" options, this disclosure contemplates providing notices related to access or use of personal information. For example, the user can be notified when the application is downloaded that their personal information data will be accessed, and then the user is reminded again just before the personal information data is accessed by the application.
此外,本公开的目的是应管理和处理个人信息数据以最小化无意或未经授权访问或使用的风险。一旦不再需要数据,通过限制数据收集和删除数据可最小化风险。此外,并且当适用时,包括在某些健康相关应用程序中,数据去标识可用于保护用户的隐私。可在适当时通过移除特定标识符(例如,出生日期等)、控制所存储数据的量或特异性(例如,在城市级别而不是在地址级别收集位置数据)、控制数据如何被存储(例如,在用户之间聚合数据)、和/或其他方法来促进去标识。Furthermore, the purpose of this disclosure is that personal information data should be managed and processed to minimize the risk of unintentional or unauthorized access or use. Risk is minimized by limiting data collection and deleting data once it is no longer needed. Additionally, and when applicable, including in certain health-related applications, data de-identification may be used to protect the privacy of users. This can be done by removing specific identifiers (eg, date of birth, etc.), controlling the amount or specificity of data stored (eg, collecting location data at the city level instead of the address level), controlling how the data is stored (eg, , aggregate data among users), and/or other methods to facilitate de-identification.
因此,虽然本公开广泛地覆盖了使用个人信息数据来实现一个或多个各种所公开的方面,但本公开还预期各种方面也可在无需访问此类个人信息数据的情况下被实现。即,本发明技术的各种方面不会由于缺少此类个人信息数据的全部或一部分而无法正常进行。例如,可基于非个人信息数据或绝对最小量的个人信息(诸如用户的大致年龄、设备处理器可用的其他非个人信息或公开可用信息)来确定注册过程。Thus, while this disclosure broadly covers the use of personal information data to implement one or more of the various disclosed aspects, this disclosure also contemplates that various aspects may also be implemented without access to such personal information data. That is, various aspects of the present technology do not fail due to the lack of all or part of such personal information data. For example, the registration process may be determined based on non-personal information data or an absolute minimum amount of personal information, such as the user's approximate age, other non-personal information available to the device processor, or publicly available information.
为了帮助专利局和本申请中发布的任何专利的任何读者解译所附权利要求书,申请人希望注意到它们并不意欲所附权利要求书中的任一个或权利要求要素调用35U.S.C.112(f),除非在特定权利要求中明确使用字词“用于……的装置”或“用于……的步骤”。To assist the Patent Office and any reader of any patents issued in this application in interpreting the appended claims, applicants wish to note that they do not intend any of the appended claims or claim elements to invoke 35 U.S.C. 112 (f), unless the words "means for" or "step for" are expressly used in a particular claim.
在前述说明书中,已参考其具体示例性方面描述了本发明。将明显的是,可在不脱离如在以下权利要求中阐述的本发明的更广泛的实质和范围的情况下对具体示例性方面作出各种修改。相应地,说明书和附图被视为是例示性意义而不是限定性意义。In the foregoing specification, the invention has been described with reference to specific exemplary aspects thereof. It will be apparent that various modifications may be made in the specific exemplary aspects without departing from the broader spirit and scope of the invention as set forth in the following claims. Accordingly, the specification and drawings are to be regarded in an illustrative rather than a restrictive sense.
Claims (41)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210104034.XA CN114422934B (en) | 2019-06-01 | 2020-06-01 | Media systems and methods adapted to hearing loss |
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962855951P | 2019-06-01 | 2019-06-01 | |
| US62/855,951 | 2019-06-01 | ||
| US16/872,068 | 2020-05-11 | ||
| US16/872,068 US11418894B2 (en) | 2019-06-01 | 2020-05-11 | Media system and method of amplifying audio signal using audio filter corresponding to hearing loss profile |
| CN202210104034.XA CN114422934B (en) | 2019-06-01 | 2020-06-01 | Media systems and methods adapted to hearing loss |
| CN202010482726.9A CN112019974B (en) | 2019-06-01 | 2020-06-01 | Media system and method for adaptation to hearing loss |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010482726.9A Division CN112019974B (en) | 2019-06-01 | 2020-06-01 | Media system and method for adaptation to hearing loss |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114422934A true CN114422934A (en) | 2022-04-29 |
| CN114422934B CN114422934B (en) | 2024-11-15 |
Family
ID=73264435
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010482726.9A Active CN112019974B (en) | 2019-06-01 | 2020-06-01 | Media system and method for adaptation to hearing loss |
| CN202210104034.XA Active CN114422934B (en) | 2019-06-01 | 2020-06-01 | Media systems and methods adapted to hearing loss |
| CN202411731130.2A Pending CN119629545A (en) | 2019-06-01 | 2020-06-01 | Media systems and methods adapted to hearing loss |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010482726.9A Active CN112019974B (en) | 2019-06-01 | 2020-06-01 | Media system and method for adaptation to hearing loss |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202411731130.2A Pending CN119629545A (en) | 2019-06-01 | 2020-06-01 | Media systems and methods adapted to hearing loss |
Country Status (3)
| Country | Link |
|---|---|
| KR (1) | KR102376227B1 (en) |
| CN (3) | CN112019974B (en) |
| DE (1) | DE102020114026A1 (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113362839B (en) * | 2021-06-01 | 2024-10-01 | 平安科技(深圳)有限公司 | Audio data processing method, device, computer equipment and storage medium |
| EP4117308A1 (en) * | 2021-07-08 | 2023-01-11 | Audientes A/S | Adaptation methods for hearing aid and hearing aid incorporating such adaptation methods |
| CN113936628B (en) * | 2021-10-12 | 2025-06-13 | 腾讯音乐娱乐科技(深圳)有限公司 | Audio synthesis method, device, equipment and computer readable storage medium |
| CN116778949A (en) * | 2022-03-10 | 2023-09-19 | 广州视源电子科技股份有限公司 | Personalized loudness compensation method, device, computer equipment and storage medium |
| CN121011194A (en) * | 2024-05-24 | 2025-11-25 | 哈曼国际工业有限公司 | Audio enhancement methods and apparatus |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102724360A (en) * | 2012-06-05 | 2012-10-10 | 创扬通信技术(深圳)有限公司 | Method and device for implementation of hearing-aid function of mobile phone and hearing-aid mobile phone |
| CN103155598A (en) * | 2010-10-14 | 2013-06-12 | 峰力公司 | Method of adjusting a hearing device and hearing device operable according to the method |
| CN103222283A (en) * | 2010-11-19 | 2013-07-24 | Jacoti有限公司 | Personal communication device with hearing support and method for providing the same |
| CN104937954A (en) * | 2013-01-09 | 2015-09-23 | 听优企业 | Method and system for self-managed sound enhancement |
| WO2018172111A1 (en) * | 2017-03-24 | 2018-09-27 | Sennheiser Electronic Gmbh & Co. Kg | Apparatus and method for processing audio signals for improving speech intelligibility |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2568281C2 (en) * | 2013-05-31 | 2015-11-20 | Александр Юрьевич Бредихин | Method for compensating for hearing loss in telephone system and in mobile telephone apparatus |
| EP3276983A1 (en) * | 2016-07-29 | 2018-01-31 | Mimi Hearing Technologies GmbH | Method for fitting an audio signal to a hearing device based on hearing-related parameter of the user |
| TWI623234B (en) * | 2016-09-26 | 2018-05-01 | 宏碁股份有限公司 | Hearing aid and its automatic frequency division filtering gain control method |
| CN108024178A (en) * | 2016-10-28 | 2018-05-11 | 宏碁股份有限公司 | Electronic device and frequency division filtering gain optimization method thereof |
| KR102583931B1 (en) * | 2017-01-25 | 2023-10-04 | 삼성전자주식회사 | Sound output apparatus and control method thereof |
| DK3484173T3 (en) * | 2017-11-14 | 2022-07-11 | Falcom As | Hearing protection system with own voice estimation and related methods |
-
2020
- 2020-05-26 DE DE102020114026.6A patent/DE102020114026A1/en active Pending
- 2020-05-29 KR KR1020200064781A patent/KR102376227B1/en active Active
- 2020-06-01 CN CN202010482726.9A patent/CN112019974B/en active Active
- 2020-06-01 CN CN202210104034.XA patent/CN114422934B/en active Active
- 2020-06-01 CN CN202411731130.2A patent/CN119629545A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103155598A (en) * | 2010-10-14 | 2013-06-12 | 峰力公司 | Method of adjusting a hearing device and hearing device operable according to the method |
| CN103222283A (en) * | 2010-11-19 | 2013-07-24 | Jacoti有限公司 | Personal communication device with hearing support and method for providing the same |
| CN102724360A (en) * | 2012-06-05 | 2012-10-10 | 创扬通信技术(深圳)有限公司 | Method and device for implementation of hearing-aid function of mobile phone and hearing-aid mobile phone |
| CN104937954A (en) * | 2013-01-09 | 2015-09-23 | 听优企业 | Method and system for self-managed sound enhancement |
| WO2018172111A1 (en) * | 2017-03-24 | 2018-09-27 | Sennheiser Electronic Gmbh & Co. Kg | Apparatus and method for processing audio signals for improving speech intelligibility |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112019974B (en) | 2022-02-18 |
| KR102376227B1 (en) | 2022-03-17 |
| KR20200138674A (en) | 2020-12-10 |
| DE102020114026A1 (en) | 2020-12-03 |
| CN112019974A (en) | 2020-12-01 |
| CN119629545A (en) | 2025-03-14 |
| CN114422934B (en) | 2024-11-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2021204971B2 (en) | Media system and method of accommodating hearing loss | |
| CN112019974B (en) | Media system and method for adaptation to hearing loss | |
| US10356535B2 (en) | Method and system for self-managed sound enhancement | |
| US8447042B2 (en) | System and method for audiometric assessment and user-specific audio enhancement | |
| US9943253B2 (en) | System and method for improved audio perception | |
| US7190795B2 (en) | Hearing adjustment appliance for electronic audio equipment | |
| KR101521030B1 (en) | Method and system for self-managed sound enhancement | |
| US7936888B2 (en) | Equalization apparatus and method based on audiogram | |
| Kates et al. | Using objective metrics to measure hearing aid performance | |
| US20090285406A1 (en) | Method of fitting a portable communication device to a hearing impaired user | |
| HK1212534A1 (en) | Method and system for self-managed sound enhancement | |
| US20180098720A1 (en) | A Method and Device for Conducting a Self-Administered Hearing Test | |
| US20060215844A1 (en) | Method and device to optimize an audio sound field for normal and hearing-impaired listeners | |
| KR100929617B1 (en) | Audiogram based equalization system using network | |
| JP7196184B2 (en) | A live public address method in headsets that takes into account the hearing characteristics of the listener | |
| WO2023278062A1 (en) | In-situ hearing assessment and customized fitting of hearing devices | |
| HK1185206A (en) | Method and system for self-managed sound enhancement | |
| HK1185206B (en) | Method and system for self-managed sound enhancement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |