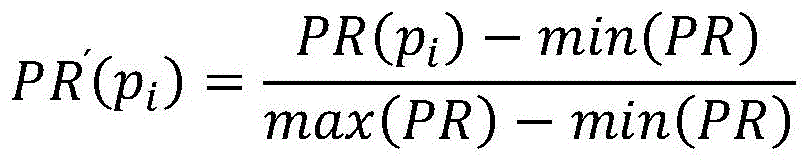Disclosure of Invention
The embodiment of the invention provides a method and a device for judging webpage categories based on node extraction and a terminal device, which can improve the accuracy of webpage category distinguishing.
In order to solve the above problem, an embodiment of the present invention provides a method, an apparatus, and a terminal device for determining a webpage category based on node extraction, including:
extracting a plurality of webpage information, and acquiring first content and second content of each webpage according to the plurality of webpage information; the acquisition time nodes of the first content and the second content are different;
respectively calculating the similarity between the first content and the second content in each webpage;
respectively calculating the PageRank value of each first content and the PageRank value of each second content to obtain a first PR value and a second PR value corresponding to each webpage, and calculating a first parameter of an external link node in each webpage; wherein, the first parameter is a parameter that the outer chain points back to itself;
according to the first PR value, the second PR value, the first parameter and the similarity corresponding to each webpage, combining a preset weighting algorithm to obtain the score of each webpage, and according to the scores of all the webpages, distinguishing the webpage categories of each webpage; the web page category comprises a list page and a text page.
As an improvement of the above scheme, the extracting the information of the multiple web pages and acquiring the first content and the second content of each web page according to the information of the multiple web pages specifically includes:
extracting width data, height data and a plurality of node data of each webpage according to the plurality of webpage information; each node data comprises position data, label name data and text content data of one node;
calculating the position data of the central point according to the width data and the height data acquired from each webpage;
calculating distance data from the node to the central point according to the position data of the node acquired in each webpage;
determining a first node according to the distance data in each webpage, and acquiring text content of each webpage through the first node as the first content of each webpage; after a first preset time interval, re-extracting the width data, the height data and the node data of the multiple webpages to obtain the second content of each webpage; wherein the text content comprises: a first text content and a second text content.
As an improvement of the above scheme, the determining a first node according to the distance data in each web page and acquiring the text content of each web page through the first node specifically includes:
selecting the node with the minimum distance data in each webpage as a first node;
if the tag name data of the first node is a paragraph element, merging the text content data of all nodes with tag names of the paragraph elements to obtain a first text content of each webpage;
if the label name of the first node is not paragraph data, determining a central area according to the position data of the central point, and combining text content data of the nodes in the central area to obtain second text content of each webpage.
As an improvement of the above scheme, the determining a center region according to the position data of the center point, and combining text contents of nodes in the center region specifically include:
determining a rectangular central area at the position of the central point; wherein, the rectangle central region is demarcated according to the golden ratio of mathematics, and r% ═ 0.382, the formula is:
where centerX, centerY is position data of the center point, width is width data of the page, height is height data of the page, and X isiAnd YiWidth data and height data of the central region are distinguished.
As an improvement of the above scheme, the calculating the similarity between the first content and the second content in each web page respectively specifically includes:
vectorizing the first content and the second content by TFIDF;
similarity calculation is carried out on the first content and the second content which are subjected to vectorization processing, and first similarity is obtained, wherein a calculation formula is as follows:
wherein Sim (pi) is the similarity, CT0(pi)For vectorization of the first content, CT(pi)Vectorizing the second content;
processing the first similarity to obtain a second similarity, wherein a calculation formula is as follows:
Sim′(pi)=1-Sim(pi)
in the formula, Sim' (p)i) For the second degree of similarity, Sim (p)i) Is a first similarity; wherein the second similarity is a similarity between the first content and the second content.
As an improvement of the above scheme, the step of calculating the PageRank value of each first content and the PageRank value of each second content respectively to obtain a first PR value and a second PR value corresponding to each web page specifically includes:
calculating the PageRank value of the first content to obtain a third PR value, and calculating the PageRank value of the second content to obtain a fourth PR value;
respectively carrying out normalization processing on the third PR value and the fourth PR value to obtain a first PR value and a second PR value, wherein the formula of the normalization processing is as follows:
of formula (II) PR'o(pi) Is the first PR value, PR' (p)i) Is the second PR value, PRo(pi) Is the third PR value, PR (p)i) The fourth PR value, max (PR), min (PR), is the maximum value and the minimum value of the second PR values corresponding to all the web pages; max (PR)o)、min(PRo) Is the maximum and minimum of the corresponding first PR values for all web pages.
As an improvement of the above scheme, the obtaining of the score of each web page according to the first PR value, the second PR value, the first parameter and the similarity corresponding to each web page in combination with a preset weighting algorithm and the distinguishing of the web page categories according to the scores of all the web pages specifically include:
carrying out weighted calculation on the first PR value, the second PR value, the first parameter and the similarity of each webpage, and obtaining the fixed weight value of each dimension according to a grid search method, thereby weighting each dimension and obtaining the score of each page;
sorting the scores of all the pages from high to low, wherein the top N% of the pages are judged as list pages, and the rest are judged as content pages; wherein N is a positive number.
Correspondingly, the invention also provides a device for judging the webpage category based on node extraction, which comprises the following steps: the system comprises an information extraction module, a similarity module, a PR value calculation module and a distinguishing module;
the information extraction module is used for extracting a plurality of webpage information and acquiring first content and second content of each webpage according to the plurality of webpage information; the acquisition time nodes of the first content and the second content are different;
as an improvement of the above scheme, the information extraction module includes: the system comprises a webpage information extraction unit, a first position calculation unit, a second position calculation unit and a text content unit;
the webpage information extraction unit is used for extracting width data, height data and a plurality of node data of each webpage according to the plurality of webpage information; each node data comprises position data, label name data and text content data of one node;
the first position calculation unit is used for calculating the position data of the central point according to the width data and the height data acquired in each webpage;
the second position calculation unit is used for calculating distance data from the node to the central point according to the position data of the node acquired in each webpage;
the text content unit is used for determining a first node according to the distance data in each webpage and acquiring the text content of each webpage through the first node as the first content of each webpage; after a first preset time interval, re-extracting the width data, the height data and the node data of the multiple webpages to obtain the second content of each webpage; wherein the text content comprises: a first text content and a second text content.
As an improvement of the above scheme, the determining a first node according to the distance data in each web page and acquiring the text content of each web page through the first node specifically includes:
selecting the node with the minimum distance data in each webpage as a first node;
if the tag name data of the first node is a paragraph element, merging the text content data of all nodes with tag names of the paragraph elements to obtain a first text content of each webpage;
if the label name of the first node is not paragraph data, determining a central area according to the position data of the central point, and combining text content data of the nodes in the central area to obtain second text content of each webpage.
As an improvement of the above scheme, the determining a center region according to the position data of the center point, and combining text contents of nodes in the center region specifically include:
determining a rectangular central area at the position of the central point; wherein, the rectangle central region is demarcated according to the golden ratio of mathematics, and r% ═ 0.382, the formula is:
where centerX, centerY is position data of the center point, width is width data of the page, height is height data of the page, and X isiAnd YiWidth data and height data of the central region are distinguished.
The similarity module is used for respectively calculating the similarity between the first content and the second content in each webpage;
as an improvement of the above, the similarity module includes: the device comprises a preprocessing unit, a first similarity unit and a second similarity unit.
The pre-processing unit is configured to vectorize the first content and the second content by TFIDF;
the first similarity unit is used for performing similarity calculation on the first content and the second content which are subjected to vectorization processing to obtain a first similarity, and the calculation formula is as follows:
wherein Sim (pi) is the similarity, CT0(pi)For vectorization of the first content, CT(pi)Vectorizing the second content;
the second similarity unit is configured to process the first similarity to obtain a second similarity, and a calculation formula is as follows:
Sim′(pi)=1-Sim(pi)
in the formula, Sim' (p)i) For the second degree of similarity, Sim (p)i) Is a first similarity; wherein the second similarity is a similarity between the first content and the second content.
The PR value calculation module is used for calculating the PageRank value of each first content and the PageRank value of each second content respectively, obtaining a first PR value and a second PR value corresponding to each webpage, and calculating a first parameter of an external link node in each webpage;
as an improvement of the above scheme, the PR value calculation module includes: an initial value calculation unit and a normalization unit;
the initial value calculating unit is used for calculating the PageRank value of the first content to obtain a third PR value, calculating the PageRank value of the second content to obtain a fourth PR value;
the normalization unit is used for respectively performing normalization processing on the third PR value and the fourth PR value to obtain a first PR value and a second PR value, wherein the formula of the normalization processing is as follows:
of formula (II) PR'o(pi) Is the first PR value, PR' (p)i) Is the second PR value, PRo(pi) Is the third PR value, PR (p)i) The fourth PR value, max (PR), min (PR), is the maximum value and the minimum value of the second PR values corresponding to all the web pages; max (PR)o)、min(PRo) Is the maximum and minimum of the corresponding first PR values for all web pages.
The distinguishing module is used for obtaining the score of each webpage according to the first PR value, the second PR value, the first parameter and the similarity corresponding to each webpage by combining a preset weighting algorithm and distinguishing the webpage category of each webpage; the web page category comprises a list page and a text page.
As an improvement of the above scheme, the distinguishing module includes: a score calculating unit and a sorting unit;
the score calculating unit is used for carrying out weighting calculation on the first PR value, the second PR value, the first parameter and the similarity of each webpage, and obtaining the fixed weight value of each dimension according to a grid searching method, so that each dimension is weighted and the score of each page is obtained;
the sorting unit is used for sorting the scores of all the pages from high to low, the top N% of the pages are judged as list pages, and the rest are judged as content pages; wherein N is a positive number.
Accordingly, the present invention further provides a computer terminal device, which includes a processor, a memory, and a computer program stored in the memory and configured to be executed by the processor, and when the processor executes the computer program, the processor implements a method for determining a web page category based on node extraction according to any one of the present invention.
Correspondingly, the present invention further provides a computer-readable storage medium, where the computer-readable storage medium includes a stored computer program, where when the computer program runs, a device in which the computer-readable storage medium is located is controlled to execute the method for determining a web page category based on node extraction according to any one of the present invention.
Therefore, the invention has the following beneficial effects:
the invention provides a webpage category judgment method and device based on node extraction and terminal equipment. By distinguishing the webpage categories, the extraction times of the web crawler to the list pages can be reduced, and the resource loss is reduced. And meanwhile, the system has more memories to analyze and extract the content of the text page, so that the accuracy rate of text extraction is improved.
Detailed Description
The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention, and it is obvious that the described embodiments are only a part of the embodiments of the present invention, and not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present invention.
Example one
Referring to fig. 1, fig. 1 is a schematic flowchart of a method for determining a webpage category based on node extraction according to an embodiment of the present invention, as shown in fig. 1, the present embodiment includes steps 101 to 104, and each step specifically includes the following steps:
step 101: extracting a plurality of webpage information, and acquiring first content and second content of each webpage according to the plurality of webpage information; wherein the acquisition time nodes of the first content and the second content are different.
As a preferred scheme of this embodiment, extracting a plurality of pieces of web page information, and acquiring a first content and a second content of each web page according to the plurality of pieces of web page information specifically includes: extracting width data, height data and a plurality of node data of each webpage according to the information of the plurality of webpages; each node data comprises position data, label name data and text content data of one node; calculating the position data of the central point according to the width data and the height data acquired from each webpage; calculating distance data from the node to the central point according to the position data of the node acquired in each webpage; determining a first node according to the distance data in each webpage, and acquiring text content of each webpage through the first node as the first content of each webpage; after a first preset time interval, re-extracting the width data, the height data and the node data of the multiple webpages to obtain the second content of each webpage; wherein the text content comprises: a first text content and a second text content.
As a preferred scheme of this embodiment, determining a first node according to the distance data in each web page, and acquiring text content of each web page through the first node specifically includes: selecting a node with the minimum distance data in each webpage as a first node; if the tag name data of the first node is a paragraph element, merging the text content data of all nodes with tag names of the paragraph elements to obtain a first text content of each webpage; if the label name of the first node is not paragraph data, determining a central area according to the position data of the central point, and combining text content data of the nodes in the central area to obtain second text content of each webpage.
As a preferred scheme of this embodiment, determining a center region according to the position data of the center point, and combining text contents of nodes in the center region specifically includes: determining a rectangular central area at the position of the central point; wherein, the rectangle central region is demarcated according to the golden ratio of mathematics, and r% ═ 0.382, the formula is:
where centerX, centerY is position data of the center point, width is width data of the page, height is height data of the page, and X isiAnd YiWidth data and height data of the central region are distinguished.
As a preferred scheme of this embodiment, according to information of a plurality of web pages, width data, height data, and a plurality of node data of each web page are extracted, specifically: determining the width and height of the page or screen, calculating the center point of the centrX, the centrY: centerX is width/2; centerY ═ height/2;
acquiring all nodes D containing contents in a webpage: { diI ∈ 1, 2, 3, …, N }, and node diCoordinates of vertices (top)i,bottomi,lefti,righti) Calculating distance between the node and the central pointi:
Xi=(righti-lefti)/2.0+lefti
Yi=(bottomi-topi)/2.0+topi
If the following conditions are met: top isi≤centerX and bottomiNot less than or equal to the centerX, and simultaneously satisfies the following conditions: lefti≤centerY and rightiNot less than centerY, then distancei=0;
If the following conditions are met: top isi≤centerX and bottomiNot less than centrX, then distancei=|Yi-centerY|;
If the following conditions are met: lefti≤centerY and rightiNot less than centrery, then distanccei=|Xi-centerX|;
If none of the three conditions is satisfied, then
As a preferred scheme of this embodiment, a web crawler is used to capture web page content, extract all links of a web page, and distinguish nodes into directory nodes and text nodes by whether the links exist in a directory set.
Step 102: and respectively calculating the similarity between the first content and the second content in each webpage.
As a preferable solution of this embodiment, the first content and the second content are vectorized by TFIDF; similarity calculation is carried out on the first content and the second content which are subjected to vectorization processing, and first similarity is obtained, wherein a calculation formula is as follows:
wherein Sim (pi) is the similarity, CT0(pi)For vectorization of the first content, CT(pi) Vectorizing the second content; processing the first similarity to obtain a second similarity, wherein a calculation formula is as follows:
Sim′(pi)=1-Sim(pi)
in the formula, Sim' (p)i) For the second degree of similarity, Sim (p)i) Is a first similarity; wherein the second similarity is a similarity between the first content and the second content.
As a preferable solution of this embodiment, the first content and the second content are vectorized by TFIDF, and a calculation formula is:
in the formula, WiWord sets, w, for the main content of a web pageikIs a word subset of the main contents of the web page, T is a set of all the main contents of the web page, TwkTo include the word wkCT(pi)Vectorization of the main content of a web page.
Step 103: respectively calculating the PageRank value of each first content and the PageRank value of each second content to obtain a first PR value and a second PR value corresponding to each webpage, and calculating a first parameter of an external link node in each webpage; wherein, the first parameter is a parameter that the outer chain points back to itself.
As a preferred scheme of this embodiment, the step of calculating the PageRank value of each first content and the PageRank value of each second content respectively includes: assume that web site W has N web pages P: { piI ∈ 1, 2, 3, …, N }, where M (p)i) Is all to piSet of web pages with out-links, L (p)j) Is pjAll the out-link webpage sets of the webpages; PR at time point when t is set to 00(pi) Is x, the damping coefficient is alpha, and the PageRank value PR at the iteration time t is calculatedt(pi):
And giving a minimum value E, stopping iteration if the difference between the PageRank value at the iteration t time and the PageRank value at the iteration t-1 time is infinitesimally small, otherwise, continuing the iteration:
PR(pi)=PRt(pi),if|PRt(pi)-PRt-1(pi)|<∈
and obtaining the PageRank value of the webpage content according to the iteration result, thereby calculating and obtaining the PageRank of the first content and the second content.
As a preferred scheme of this embodiment, a PageRank value of a first content is calculated to obtain a third PR value, and a PageRank value of a second content is calculated to obtain a fourth PR value; respectively carrying out normalization processing on the third PR value and the fourth PR value to obtain a first PR value and a second PR value, wherein the formula of the normalization processing is as follows:
of formula (II) PR'o(pi) Is the first PR value, PR' (p)i) Is the second PR value, PRo(pi) Is the third PR value, PR (p)i) The fourth PR value, max (PR), min (PR), is the maximum value and the minimum value of the second PR values corresponding to all the web pages; max (PH)o)、min(PRo) Is the maximum and minimum of the corresponding first PR values for all web pages.
As a preferred scheme of this embodiment, calculating a first parameter of an out-link node in each web page specifically includes: judging whether the nodes of the external link point back to the external link, wherein the calculation formula is as follows:
if pointing back to itself, the first parameter ML (p)i) Is 1, otherwise the first parameter ML (p)i) Is 0.
Step 104: according to the first PR value, the second PR value, the first parameter and the similarity corresponding to each webpage, combining a preset weighting algorithm to obtain the score of each webpage, and according to the scores of all the webpages, distinguishing the webpage categories of each webpage; the web page category comprises a list page and a text page.
As a preferred scheme of this embodiment, a weighting calculation is performed on the first PR value, the second PR value, the first parameter, and the similarity of each web page, and a weighting value of each dimension is obtained according to a web search method, so that each dimension is weighted and a score of each page is obtained; sorting the scores of all the pages from high to low, wherein the top N% of the pages are judged as list pages, and the rest are judged as content pages; wherein N is a positive number.
As a preferred scheme of this embodiment, a grid search method is used to perform optimal coefficient fitting on the manually labeled webpage result set and verification set to obtain the fixed weights a, b, c, and d, and the weighted calculation formula is:
Score(pi)=aPR(pi)+bPR′o(pi)+cSim′(pi)+dML(pi)
thereby obtaining a Score (p) of each web pagei) Wherein, PR'o(pi) Is the first PR value, PR' (p)i) Is a second PR value, Sim' (p)i) For similarity, ML (p)i) Is the first parameter.
As a preferable mode of this embodiment, N may be any number between 1 and 20.
The embodiment of the invention has the following effects:
therefore, the invention discloses a webpage category judgment method based on node extraction. The method comprises the steps of carrying out multi-dimensional calculation on two times of main contents extracted from the webpage, obtaining a fixed weight value aiming at each dimension, weighting each dimension through the fixed weight value to obtain the score of the webpage, and judging the list webpage and the text webpage of the webpage. By judging the webpage categories, the web crawler can be prevented from repeatedly crawling all the webpages, the resource consumption for acquiring the text webpage content is reduced, meanwhile, the analysis of the text webpage content can be more concentrated, and the accuracy of the text webpage content analysis is improved.
Example two
Referring to fig. 2, fig. 2 is a schematic structural diagram of a device for determining a category of a web page based on node extraction according to an embodiment of the present invention, including: the invention also provides a device for judging the webpage category based on node extraction, which comprises the following components: an information extraction module 201, a similarity module 202, a PR value calculation module 203 and a distinguishing module 204;
the information extraction module 201 is configured to extract a plurality of pieces of web page information, and obtain a first content and a second content of each web page according to the plurality of pieces of web page information; the acquisition time nodes of the first content and the second content are different;
as an improvement of the above solution, the information extraction module 201 includes: the system comprises a webpage information extraction unit, a first position calculation unit, a second position calculation unit and a text content unit;
the webpage information extraction unit is used for extracting width data, height data and a plurality of node data of each webpage according to the plurality of webpage information; each node data comprises position data, label name data and text content data of one node;
the first position calculation unit is used for calculating the position data of the central point according to the width data and the height data acquired in each webpage;
the second position calculation unit is used for calculating distance data from the node to the central point according to the position data of the node acquired in each webpage;
the text content unit is used for determining a first node according to the distance data in each webpage and acquiring the text content of each webpage through the first node as the first content of each webpage; after a first preset time interval, re-extracting the width data, the height data and the node data of the multiple webpages to obtain the second content of each webpage; wherein the text content comprises: a first text content and a second text content.
As an improvement of the above scheme, the determining a first node according to the distance data in each web page and acquiring the text content of each web page through the first node specifically includes:
selecting the node with the minimum distance data in each webpage as a first node;
if the tag name data of the first node is a paragraph element, merging the text content data of all nodes with tag names of the paragraph elements to obtain a first text content of each webpage;
if the label name of the first node is not paragraph data, determining a central area according to the position data of the central point, and combining text content data of the nodes in the central area to obtain second text content of each webpage.
As an improvement of the above scheme, the determining a center region according to the position data of the center point, and combining text contents of nodes in the center region specifically include:
determining a rectangular central area at the position of the central point; wherein, the rectangle central region is demarcated according to the golden ratio of mathematics, and r% ═ 0.382, the formula is:
where centerX, centerY is position data of the center point, width is width data of the page, height is height data of the page, and X isiAnd YiWidth data and height data of the central region are distinguished.
The similarity module 202 is configured to calculate a similarity between the first content and the second content in each web page respectively;
as an improvement of the above scheme, the similarity module 202 includes: the device comprises a preprocessing unit, a first similarity unit and a second similarity unit.
The pre-processing unit is configured to vectorize the first content and the second content by TFIDF;
the first similarity unit is used for performing similarity calculation on the first content and the second content which are subjected to vectorization processing to obtain a first similarity, and the calculation formula is as follows:
wherein Sim (pi) is the similarity, CT0(pi)For vectorization of the first content, CT(pi)Vectorizing the second content;
the second similarity unit is configured to process the first similarity to obtain a second similarity, and a calculation formula is as follows:
Sim′(pi)=1-Sim(pi)
in the formula, Sim' (p)i) For the second degree of similarity, Sim (p)i) Is a first similarity; wherein the second similarity is a similarity between the first content and the second content.
The PR value calculating module 203 is configured to calculate a PageRank value of each first content and a PageRank value of each second content, obtain a first PR value and a second PR value corresponding to each web page, and calculate a first parameter of an external link node in each web page;
as an improvement of the above scheme, the PR value calculation module 203 includes: an initial value calculation unit and a normalization unit;
the initial value calculating unit is used for calculating the PageRank value of the first content to obtain a third PR value, calculating the PageRank value of the second content to obtain a fourth PR value;
the normalization unit is used for respectively performing normalization processing on the third PR value and the fourth PR value to obtain a first PR value and a second PR value, wherein the formula of the normalization processing is as follows:
of formula (II) PR'o(pi) Is the first PR value, PR' (p)i) Is the second PR value, PRo(pi) Is the third PR value, PR (p)i) The fourth PR value, max (PR), min (PR), is the maximum value and the minimum value of the second PR values corresponding to all the web pages; max (PR)o)、min(PRo) Is the maximum and minimum of the corresponding first PR values for all web pages.
The distinguishing module 204 is configured to obtain a score of each web page according to the first PR value, the second PR value, the first parameter, and the similarity corresponding to each web page, in combination with a preset weighting algorithm, and distinguish a category of each web page; the web page category comprises a list page and a text page.
As an improvement of the above solution, the distinguishing module 204 includes: a score calculating unit and a sorting unit;
the score calculating unit is used for carrying out weighting calculation on the first PR value, the second PR value, the first parameter and the similarity of each webpage, and obtaining the fixed weight value of each dimension according to a grid searching method, so that each dimension is weighted and the score of each page is obtained;
the sorting unit is used for sorting the scores of all the pages from high to low, the top N% of the pages are judged as list pages, and the rest are judged as content pages; wherein N is a positive number.
By implementing the embodiment of the invention, the webpage category can be well judged, the information module extracts the webpage content, the text content of the webpage is obtained through judgment of the visual center, the similarity module and the PR value calculation module are used for obtaining the parameters, and then the distinguishing module obtains the weighting value to perform weighting calculation on the parameters, so that the judgment score of each webpage is obtained, the efficiency of webpage content analysis is favorably improved in an auxiliary manner, and the resource consumption is saved.
EXAMPLE III
Referring to fig. 3, fig. 3 is a schematic structural diagram of a terminal device according to an embodiment of the present invention.
A terminal device of this embodiment includes: a processor 301, a memory 302 and a computer program stored in said memory 302 and executable on said processor 301. The processor 301, when executing the computer program, implements the steps of the above-mentioned various methods for determining a category of a web page based on node extraction in embodiments, such as all the steps of the method for determining a category of a web page based on node extraction shown in fig. 1. Alternatively, the processor, when executing the computer program, implements the functions of the modules in the device embodiments, for example: all the modules of the apparatus for determining a category of a web page based on node extraction shown in fig. 2.
In addition, an embodiment of the present invention further provides a computer-readable storage medium, where the computer-readable storage medium includes a stored computer program, where when the computer program runs, a device in which the computer-readable storage medium is located is controlled to execute the method for determining a webpage category based on node extraction according to any of the above embodiments.
It will be appreciated by those skilled in the art that the schematic diagram is merely an example of a terminal device and does not constitute a limitation of a terminal device, and may include more or less components than those shown, or combine certain components, or different components, for example, the terminal device may also include input output devices, network access devices, buses, etc.
The Processor 301 may be a Central Processing Unit (CPU), other general purpose Processor, a Digital Signal Processor (DSP), an Application Specific Integrated Circuit (ASIC), an off-the-shelf Programmable Gate Array (FPGA) or other Programmable logic device, discrete Gate or transistor logic, discrete hardware components, etc. The general processor may be a microprocessor or the processor may be any conventional processor or the like, and the processor 301 is a control center of the terminal device and connects various parts of the whole terminal device by using various interfaces and lines.
The memory 302 can be used for storing the computer programs and/or modules, and the processor 301 implements various functions of the terminal device by running or executing the computer programs and/or modules stored in the memory and calling the data stored in the memory 302. The memory 302 may mainly include a program storage area and a data storage area, wherein the program storage area may store an operating system, an application program required by at least one function (such as a sound playing function, an image playing function, etc.), and the like; the storage data area may store data (such as audio data, a phonebook, etc.) created according to the use of the cellular phone, and the like. In addition, the memory may include high speed random access memory, and may also include non-volatile memory, such as a hard disk, a memory, a plug-in hard disk, a Smart Media Card (SMC), a Secure Digital (SD) Card, a Flash memory Card (Flash Card), at least one magnetic disk storage device, a Flash memory device, or other volatile solid state storage device.
Wherein, the terminal device integrated module/unit can be stored in a computer readable storage medium if it is implemented in the form of software functional unit and sold or used as a stand-alone product. Based on such understanding, all or part of the flow of the method according to the embodiments of the present invention may also be implemented by a computer program, which may be stored in a computer-readable storage medium, and when the computer program is executed by a processor, the steps of the method embodiments may be implemented. Wherein the computer program comprises computer program code, which may be in the form of source code, object code, an executable file or some intermediate form, etc. The computer-readable medium may include: any entity or device capable of carrying the computer program code, recording medium, usb disk, removable hard disk, magnetic disk, optical disk, computer Memory, Read-Only Memory (ROM), Random Access Memory (RAM), electrical carrier wave signals, telecommunications signals, software distribution medium, and the like.
It should be noted that the above-described device embodiments are merely illustrative, where the units described as separate parts may or may not be physically separate, and the parts displayed as units may or may not be physical units, may be located in one place, or may be distributed on multiple network units. Some or all of the modules may be selected according to actual needs to achieve the purpose of the solution of the present embodiment. In addition, in the drawings of the embodiment of the apparatus provided by the present invention, the connection relationship between the modules indicates that there is a communication connection between them, and may be specifically implemented as one or more communication buses or signal lines. One of ordinary skill in the art can understand and implement it without inventive effort.
While the foregoing is directed to the preferred embodiment of the present invention, it will be understood by those skilled in the art that various changes and modifications may be made without departing from the spirit and scope of the invention.