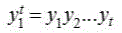Detailed Description
Reference will now be made in detail to the exemplary embodiments, examples of which are illustrated in the accompanying drawings. When the following description refers to the accompanying drawings, like numbers in different drawings represent the same or similar elements unless otherwise indicated. The implementations described in the exemplary embodiments below are not intended to represent all implementations consistent with embodiments of the present disclosure. Rather, they are merely examples of apparatus and methods consistent with certain aspects of the disclosed embodiments, as detailed in the attached application documents.
The embodiment of the present disclosure provides an information processing method, which is shown in fig. 1 and includes:
step S101, obtaining an observation sequence of information by a user according to the identification degree of the user and comment data of the user on the information; wherein the identification degree reflects the authentication ability of the user for information; the observation sequence comprises: the observation value of the user to the information indicates the attitude information of the user to the information, and the attitude information of the user to the information includes: negative attitude, neutral attitude and positive attitude;
step S102, inputting the observation sequence into a trained machine learning model to obtain a reliability probability value of the observation sequence;
and S103, obtaining the authenticity of the information according to the reliability probability value.
In the embodiment of the present disclosure, the information includes but is not limited to: blog information, picture information, video information, alone or in combination.
In the embodiment of the present disclosure, the user is an active user using an electronic information dissemination medium, and the active user in the electronic information dissemination medium may perform an individual or combined behavior of operation behaviors such as approval, collection, forwarding, and comment on the information. Because the user mostly reads the information and then carries out the operation behavior executed by the information, when the user reads the information, the user can carry out the identification and judgment of the authenticity of the information, and after the information is identified and judged, the information can be subjected to the preset operation behavior.
In the embodiment of the present disclosure, the electronic information propagation medium may be a social media that is semi-public but still has a certain propagation capability, such as a social media like WeChat and QQ; or social media that are fully public and have a high ability to travel, such as social media like microblogs, small red books, trembles, ins, Facebook, etc.
In the embodiment of the present disclosure, the recognition degree is a capability of the user to identify the information, for example, a capability of the user to judge authenticity or reliability of the information according to knowledge, professional experience or logic possessed by the user after reading the information. For example, a user in a medical profession may judge the authenticity of information related to medicine according to medical knowledge, medical experience, and medical logic possessed by the user, and if a reliability probability value obtained by the recognition degree of the user on the information is utilized, the authenticity of the information may be determined more accurately. Of course, the degree of recognition is not limited to the medical profession, and may be a degree of recognition that a user in another profession such as a historical profession or a legal profession judges authenticity of information in the profession to which the user belongs.
In the embodiment of the present disclosure, in step S101, an observation sequence of information by a user is obtained according to the recognition degree of the user and the comment data of the user on the information. In one embodiment, the method comprises the following steps: from the userK t Extracting characteristic values from the blog article corresponding to the personal data and the information F, and then using the trained classification model to perform classification on the userK t Classifying to obtain the identification degreex t Is taken as the value of (1) to obtain the degree of recognitionx t After the value is taken, active users can be obtained by using some existing opinion mining methods based on comments of the usersK t The attitude of (c).
In some embodiments, the opinion mining method may use natural language processing and emotion classifier to determine the attitudes of the user about opinions, such as: positive attitude, negative attitude, or neutral attitude, etc.
In the embodiment of the present disclosure, regarding the identification degree of the user, the number of fans of the user, the number of concerned users, whether the user is an authenticated user of a known blogger in a certain professional field or a general blogger in a certain professional field, the gender of the user, the number of user publishing and/or forwarding information, the registration time of the user, the number of pieces of information in which the authenticity of the information needs to be detected in the user publishing and/or forwarding blog text, and the behavior mode of the user on the information may be integrated to comprehensively measure whether the information attitude information of the user is negative attitude, neutral attitude, and positive attitude.
In some embodiments, order
y t Is shown as
tIndividual user
K t The resulting observations. When the user is
K t If F is in positive attitude, then observation value is obtained
(ii) a When the user is
K t If F is in negative attitude, then
(ii) a When the user is
K t When F is in neutral attitude, then
Wherein
and therefore, the first and second electrodes are,
y t integer values are taken. Order to
The length of the representation information F generated in the propagation process is
tThe observation sequence of (1). That is, the information F will experience in the process of being propagated by different users
tThe observed value of the information F may be the same or different between each user,
indicating information F in
tWhen the data is transmitted between the users, the users can,
tand the observation sequence is formed by the observation values of the information F of the users. Wherein,
t=1,2,3,···,
t。
in the embodiment of the present disclosure, in step S102, the observation sequence is input to a trained machine learning model, so as to obtain a reliability probability value of the observation sequence. Due to the observation sequence, the observed values of information between users may affect each other, e.g. the secondiThe observation value of the user on the information F shows that the user holds a positive attitude on the information F, and the observation value may be the first one concerned by the useri-the influence of 1 attitude information. Therefore, in one embodiment, the machine learning model comprises a Bi-directional long-short memory network Bi-LSTM layer, and due to the characteristic of bidirectional computation, attitude information of a vector before or after any vector in a prediction sequence can be obtained, so that influence factors between users on information can be considered.
In the embodiment of the disclosure, the machine learning model further comprises a Convolutional Neural Network (CNN) layer, the convolutional neural network layer comprises a convolutional layer, two pooling layers and an activation function layer, the observation sequence value is linearly input into the Bi-directional long and short memory network Bi-LSTM layer of the machine learning model and then input into the CNN layer, and then the probability value of the reliability is obtained. The activation function layer may be a softmax function layer.
In the embodiment of the present disclosure, in step S103, the authenticity of the information is obtained according to the reliability probability value. In one embodiment, according to the reliability probability value, when the reliability probability value is higher than a preset threshold, for example, the preset threshold is set between 0.6 and 0.9, and if the reliability probability value is higher than the preset threshold, the information is determined to be real information.
In one embodiment, the confidence probability value may be multiplied by 100 to obtain a confidence score, and when the confidence score is greater than a preset threshold, for example, when the preset threshold is set between 60 and 90, if the confidence score is higher than the preset threshold, the information is determined to be real information.
The calculation method of the plausibility of the information obtained by the reliability probability value in the embodiment of the present disclosure is not limited to the above-described embodiment.
In the embodiment of the disclosure, since the user, especially an active user, has a basic capability of determining or purifying the authenticity or falseness of the information, even some active users belong to users with rich professional knowledge and experience, and the recognition degree of the user is calculated based on attribute data such as the amount of the vermicelli of the user, the recognition degree level of the user can be effectively classified, for example, a user with a large amount of vermicelli, a long registration time and a large number of times of forwarding the information may be a user with both professional knowledge and influence, the higher the recognition degree level of such a user is, the stronger the capability of identifying the authenticity or falseness of the information is, therefore, the credibility value of the information is extracted by using the recognition degree of the active user on the information, the authenticity of the information is determined, the calculation amount can be saved, and effective information can be extracted, and the accuracy of reliability judgment is improved.
In the embodiment of the present disclosure, as shown in fig. 2, the method further includes:
step S1001, acquiring attribute data of a user who executes a preset operation behavior on the information; wherein the preset operational behavior is indicative of at least one of: the user approves, reviews or forwards the information; the attribute data of the user includes at least one of: the method comprises the following steps of (1) determining the amount of vermicelli of a user, the amount of attention of the user and the amount of information needing to judge the authenticity of the information in published or forwarded information of the user;
step S1002, acquiring a characteristic data set of the user according to the attribute data of the user;
step S1003, inputting the characteristic data set of the user into a classification model to obtain the identification degree of the user.
In this embodiment of the present disclosure, in step S1001, the obtaining of the attribute data of the user who has performed the preset operation behavior on the information refers to the attribute data of the user who has performed the positive preset operation behavior or the negative preset operation behavior on the information in the information transmission process. The positive preset operation behavior refers to positive preset operation behavior of the user on the information, and includes but is not limited to: behavior of praise, behavior of collecting, commenting on the front or combining with forwarding information; the negative preset operation behavior refers to negative preset operation behavior of the user on the information, and includes but is not limited to the following: and (4) clicking, negatively commenting, combining the information forwarding behavior and the information reporting behavior.
In one embodiment, even if the user a sees the information F, does not pay attention to the information F, does not take any action on the information F or takes an action, the attribute data of the user a does not need to be acquired, while the user B sees the information F but pays attention to the information F, and takes a positive preset operation action on the information F, such as a behavior of agreeing to, collecting, commenting positively or combining with forwarding information; or a negative preset operation behavior such as clicking, negative comment or behavior combined with forwarding information is taken, the attribute data of the user B needs to be acquired.
In the embodiment of the present disclosure, after the user determines the authenticity of the information, the user may take a certain preset operation action on the information according to the determination of the user, and the preset operation action taken by the user on the false information may be, but is not limited to: like behavior of likes, comments or forwards to information, e.g., comment that the false information is accompanied by a comment in the form of a package of similar emoticons such as surprise, incredibility, jeer, etc.; or the user can adopt the operation behavior reported on the internet for the false information, even call other related users to report the false information together, and black-draw or click on the operation behaviors of the bloggers who produce the false information, and the like.
In the embodiment of the present disclosure, if the user determines that the information is real, an active propagation behavior may be performed, for example, a praise behavior, a positive comment behavior, a comment behavior attached during silently forwarding or forwarding, and the like.
The preset operation behavior of the information taken by the user in the embodiment of the present disclosure is not limited to the above behaviors or forms alone or in combination.
In one embodiment, the user C is a famous blogger in a certain professional field, and has a large number of fans and a large amount of attention, for example, pays attention to other famous bloggers in many professional fields, and has a large amount of information for judging the authenticity of the information in the number of pieces of forwarded information; the fan amount of the user D is less than that of the user C, the attention amount is less, the user D does not belong to the authentication user in the professional field, the forwarding information is less, or the number of pieces of information which are falsely copied in the number of pieces of forwarding information is less, the user C is probably a user which is professionally falsely copied, the user D is a common user, and the identification degree of the user C is higher than that of the user D.
In this embodiment of the disclosure, in step S1002, a feature data set of a user is obtained according to attribute data of the user, that is, a feature data set composed of attribute feature values of each user is extracted according to a vermicelli amount, an attention amount, published or forwarded information of the user and an information amount, which is required to judge authenticity of the information, in the published or forwarded information, whether the attribute data set is an attribute data set that authenticates the user, gender of the user, time of registration, and the like, where the attribute feature values are elements placed in a feature vector, and a category and a corresponding amount of attribute data obtained after the attribute data of the user is extracted.
In the embodiment of the present disclosure, in step S1003, the feature data set of the user is input to the classification model, so as to obtain the recognition degree of the user. The classification model divides a plurality of users into different recognition levels, so that the feature data sets of the users are input into the classification model, and the classification model outputs the recognition levels of the users. The classification model is trained from data of sample users.
In the embodiment of the disclosure, since the user who has performed any preset operation on the information in the transmission process of the information is obtained, the attribute data of the user is obtained. Feature data sets are extracted from these attribute data, which feature data sets may simply be numerically labeled with the attributes of the user, after which these feature data sets are input into a classification model to derive the level of recognition of the user. And determining the user according to whether the user takes a preset operation behavior on certain information or not, extracting characteristic values according to attribute data of the user, and inputting a characteristic data set consisting of the characteristic values into a classification model to obtain a classification result of the recognition degree grade of the user. Therefore, the identification degree grade is obtained through the classification model, effective data can be obtained in huge data quantity, calculation cost is saved, attribute data of the user can be integrated, the identification ability of the user is represented by the identification degree, the identification degree preliminarily quantifies the false or real identification ability of the user to information, subsequent further calculation is facilitated, and the purification ability of the user to the false information in the social media is also preliminarily utilized.
In the embodiment of the present disclosure, the method further includes:
obtaining the identification degree of the user based on the characteristic data of the user by using a classification model; wherein the classification model is: and the test result output from a plurality of candidate models trained by using labels obtained by the clustering device is the one with the highest matching degree with the clustering device.
In the embodiment of the present disclosure, the clustering device clusters a plurality of different users into M different clusters according to the feature values extracted by using the attribute data of the users, so that each cluster corresponds to one recognition level, the recognition levels of active users in the same cluster are the same, and finally the active users in the same cluster are labeled with the same label. Since there are multiple clusters, there are multiple labels obtained using the clusterer.
At least the content of the attribute data includes but is not limited to at least one of:
the gender of the user;
the age of the user;
the user's occupation;
the education level of the user;
user preferences;
the customer is usually at the premises.
In the embodiment of the present disclosure, the clustering device is an algorithm for dividing data based on a clustering algorithm, and may be, but not limited to, a k-means clustering algorithm-based clustering device, a mean shift clustering algorithm, a density-based clustering algorithm (DBSCAN), a maximum Expectation (EM) clustering algorithm of a gaussian mixture model GMM, a coacervation hierarchy clustering algorithm, a graph group detection algorithm, and other existing clustering algorithms.
In the embodiment of the present disclosure, the multiple candidate models are candidate models used for classifying the degree of recognition of the user, and may be, but are not limited to: and inputting the labels obtained by using the clustering device and the user characteristic data sets corresponding to the labels into a plurality of different alternative models to obtain a plurality of test results under each alternative model, and taking the alternative model with the highest goodness of fit between the test results and the clustering device as the classification model.
In the embodiment of the present disclosure, the classification models of the alternative models include, but are not limited to: naive Bayes (NB), Decision Trees (DT), Support Vector Machines (SVM), and other common classification models.
In one embodiment, the labels obtained based on the clustering algorithm and the user data marked by the labels are used for training and testing classifiers based on different classification algorithms, and then the best classifier is selected as the classification model according to the matching degree of the test result and the clustering device.
In one embodiment, the slave userK t Extracting characteristic values from the personal attribute data and the information corresponding to the information F, and then using the trained optimal classifier to perform classification on the userK t Is classified to obtainx t The value of (a). In the embodiment of the present disclosure, the feature value is an element a placed in a feature vector represented by a category of attribute data to which a user belongs and a corresponding numerical value obtained after extracting attribute data of the userjWherein j =1, 2, 3, · · i. For example, a for user fans1Is shown as a1=50000 indicates that the number of fan-shaped fans of the user is 50000; whether or not the user is an authenticating user a2Is shown as a2If =1 indicates that the user is an authenticated user, a2If =0, it indicates that the user is not an authenticated user; a is3Representing the age of the user, a3=50 indicates that the user is 50 years old; a is4Representing the user's preferences, quantifying the user's preferences into five levels, a higher level indicating a higher degree of user preference, e.g., a4=4, indicating the degree of preference of the userIs the fourth grade. In the embodiment of the present disclosure, the attribute data of the user is data obtained by quantizing data related to the user attribute into specific data, and the feature value is data representing a category of the user attribute data and corresponding data.
In the embodiment of the disclosure, the label to which the user belongs is obtained through clustering, the label and the corresponding user characteristic data are input into the alternative models, one alternative model with the highest matching degree with the clustering device is selected as the optimal classification model according to the test result for classifying the identification degree of the user, and when the characteristic data set of the user is input into the trained classification model, the identification degree of the user can be obtained, so that the identification degree of the user can be conveniently calculated, and the calculated amount is properly reduced.
In the embodiment of the present disclosure, as shown in fig. 3, the step S101 includes:
step S1011, obtaining attitude information of the user to the information according to the identification degree of the user and the comment data of the user to the information;
step S1012, obtaining an observation sequence of the information by the user according to the attitude information of the information by the user.
In the embodiment of the disclosure, a plurality of users acquire a sequence of corresponding observed values for different attitude information held by the same information, and form an observation sequence of the information by the users.
In one embodiment, order
y t Is shown as
tIndividual user
K t The resulting observations. When the user is
K t If F is in positive attitude, then observation value is obtained
(ii) a When the user is
K t If F is in negative attitude, then
(ii) a When the user is
K t When F is in neutral attitude, then
Wherein
and therefore, the first and second electrodes are,
y t integer values are taken. Order to
The length of the representation information F generated in the propagation process is
tThe observation sequence of (1). That is, the information F will experience in the process of being propagated by different users
tThe observed value of the information F may be the same or different between each user,
indicating information F in
tWhen the data is transmitted between the users, the users can,
tand the observation sequence is formed by the observation values of the information F of the users. Wherein,
t=1,2,3,···,
t。
in the embodiment of the disclosure, based on the identification degree of the user and the attitude contained in the comment data, the attitude information of the user is represented by the observation value, and finally, an observation sequence formed by the observation values of the information of a plurality of users is obtained. The higher the recognition degree of the user is, the truer the comment data of the user on the information is, and the higher the corresponding observation value is. The attitude information of the user to the information is calculated according to the identification degree of the user and the comment data of the user to the information, for example, when the user holds a positive attitude, a negative attitude or a neutral attitude to the information, the observation values corresponding to the attitude information are different. Therefore, the data of the user can be comprehensively measured, and a more comprehensive and accurate observation sequence can be obtained.
In the embodiment of the present disclosure, as shown in fig. 4, the step S103 includes:
step S1031, obtaining the credibility score according to the credibility probability value;
step S1032, if the reliability score satisfies a condition that is greater than a preset threshold, the information is real information.
In the embodiment of the present disclosure, in step S1031, the reliability score is calculated by multiplying the reliability probability value by a preset full value. The range of the confidence probability value is 0 to 1, which is commonly used, and the value is decimal or fractional, for example, the value mode is 0.5, 1/2, 50%, and the like.
In some embodiments, the preset full-score value may be set to, but is not limited to, a full-score value of 1 point, 10 points, 100 points, etc. In one embodiment, when the predetermined full score is 1 score, the confidence score corresponds to the confidence probability value. In one embodiment, when the predetermined full score value is 100 points, the reliability score corresponds to the product of the reliability probability value and 100 points, for example, when the reliability probability value is 0.56, the reliability score is 56. The embodiments of the present disclosure are not limited to the above-described embodiments, with respect to the setting of the preset full score value and the calculation formula of the credibility score.
In this embodiment of the disclosure, in step S1032, if the reliability score meets a condition that is greater than a preset threshold, the information is real information, for example, when the preset full score is 100 minutes, the preset threshold is set within 100 minutes, for example, 60 minutes, 70 minutes, and the like. In one embodiment, when the preset full score is 100, the preset threshold is 60, and the reliability probability value of the information is 0.75, it can be determined that the reliability score is 75, and if the reliability score is greater than the preset threshold 60, the information is the real information.
In the embodiment of the disclosure, whether the information is false information is judged by calculating the credibility score and setting a preset threshold, so as to find out early and reduce the propagation rate and negative influence of the false information between users in social media, for example, false terrorism events possibly contained in false news information can affect the mental health of the users; false medical information may contain false medical hospitals or false treatment means, and the physical health of the user is damaged once the user mistakenly believes or even implements the treatment; the false contribution information and channels can damage the related benefits of the users and consume the same mood of the users. Therefore, detecting the authenticity of the information, cleansing the social media environment, may reduce the probability that the user's mental, physical health, or related benefits are compromised or lost.
In the embodiment of the present disclosure, as shown in fig. 5, the machine learning model includes:
receiving a bidirectional long and short memory network (BilSTM) of the observation sequence;
a convolutional neural network CNN connected with the long and short memory networks and outputting the reliability probability value; the CNN includes at least: the convolution layer and two pooling layers located at the rear end of the convolution layer.
In the embodiment of the present disclosure, after obtaining an observation sequence composed of observation values, the machine learning model receives the observation sequence, specifically, the machine learning model includes a bidirectional long and short memory network BiLSTM receiving the observation sequence, and the convolutional neural network CNN is followed by the long and short memory network.
In the embodiment of the disclosure, the bidirectional long-short memory network BiLSTM is a bidirectional long-short memory network LSTM, and the observed values are generally predicted from left to right relative to the LSTM, so that the observed values behind are more important than the observed values in front.
In the embodiment of the disclosure, because
tComments on information between individual users, e.g. users
tWill trust the user
t-1 published or forwarded information F, user
tPossibly forwarding the information F and commenting with the user
t1 attitude-like statements, or take user-like statements
t1 similar operational behavior. When observing the sequence
After the information is input into the bidirectional long and short memory network BilSTM layer, the information of the left sequence and the right sequence in the observed value can be obtained, and finally the bidirectional long and short memory network layer can output the characteristic matrix. The specific calculation formula is as follows:
In the above equation 1.1 and equation 1.2,
is shown as
iThe feature vector of the observation to the left of the individual observations,
is a transition from a current hidden layer to a next hidden layer
The matrix represents information connecting the left observations of the current word.
A feature vector representing the left observation of the previous word,
the feature vector representing the current observed value, similarly, can be calculated using equation 1.2
Feature vector of right-hand observation
。
In the embodiment of the present disclosure, the current observed value is obtained according to the above formula 1.1 and the above formula 1.2
The calculation formula is as follows:
In the embodiment of the present disclosure, the feature matrix output by the two-way long and short memory network layer is input into the CNN layer of the convolutional neural network, and as shown in fig. 5, the feature matrix is first convolved by the convolutional layer, and then sequentially pooled by the two pooling layers to obtain the feature vector matrix.
In the embodiment of the disclosure, the convolutional neural network further includes a full-link layer and a softmax layer, the softmax layer is connected to the full-link layer in a rear mode, the eigenvector matrix obtained through the convolutional layer and the two pooling layers is input into the full-link layer and the softmax layer, the full-link layer multiplies the weight matrix with the input eigenvector matrix and adds a bias term, and the full-link layer multiplies the weight matrix with the input eigenvector matrix and adds the bias term to the weight matrix
nAre a
Is mapped to as
kAn
Real (fractional), softmax layers will
kAn
Is mapped to real or fractional numbers of
kReal number (probability) of (0, 1) while ensuring
kThe sum of the real numbers (probabilities) is 1, and the specific calculation formula is as follows:
In the above-mentioned formula 1.4,
represents a probability value
yBelonging to the range of 0 to 1,
the dimension of the eigenvector matrix is the same as the dimension of the sequence eigenvector matrix Z,
represents the bias term and Z represents the sequence feature matrix.
In the embodiment of the disclosure, through the machine learning model, the feature vector can be extracted from the observation sequence for calculation, and finally, the probability value related to the observed value in the observation sequence is output, especially for a huge data amount in social media, for example, the machine learning model can efficiently calculate the probability value of the recognition degree.
In the embodiment of the present disclosure, as shown in fig. 5, the two pooling layers include:
a maximum pooling layer;
and the average pooling layer is positioned at the rear end of the maximum pooling layer.
In the embodiment of the present disclosure, a calculation formula of the Max pooling layer Max-pooling is as follows:
The average pooling layer Avg-pooling is calculated as follows:
The splicing formula of the maximum pooling layer and the average pooling layer is as follows:
In the embodiments of the present disclosure, it is,
the output of the maximum pooling is represented,
the output of the average pooling is represented,
it is shown that the operation of splicing,
indicating the sliding window size. By utilizing the method of splicing the maximum pooling and the average pooling, the defect that the information is lost because the maximum value can be taken only once in each maximum pooling operation is overcome. And the results of the two pooling operations are subjected to feature fusion, so that the integrity of sequence feature information is ensured, and more comprehensive and deep features are obtained.
In the embodiment of the present disclosure, as shown in fig. 5 and fig. 6, a training method is provided, where the method includes:
step S201, obtaining the identification degree of a sample user;
step S202, obtaining a sample of an observation sequence according to the evaluation data of the sample user;
step S203, training to obtain a machine learning model in the information processing method according to the sample of the observation sequence and the identification degree of the sample user.
In the embodiment of the present disclosure, the sample user in step S201 is a user different from the sample user in the information processing method. Thus, the sample of the observation sequence obtained from the evaluation data of the sample user in step S202 is different from the observation sequence in the information processing method,
in the embodiment of the disclosure, the attribute data and the evaluation data of the sample user are acquired from a large amount of popular real information collected on a social media, the data are preprocessed, and then the identification degree of the sample user is acquired.
In the embodiment of the disclosure, a user data set generated by collecting a large amount of popular real information is collected, then the data set is processed, the recognition degree of a user is proper by using a user recognition degree calculation method in an information processing method and an existing social media opinion mining method, then an observation value is constructed according to the recognition degree and attitude of the user, and finally a large amount of observation sequences generated by the popular real information are obtained and used as sample data of a training machine learning model.
In the embodiment of the disclosure, a large number of machine learning models trained by the observation sequences can effectively process a small number of extracted observation sequences and detect the authenticity or falseness of information.
In the embodiment of the present disclosure, as shown in fig. 5, the machine learning model includes:
receiving a bidirectional long and short memory network (BilSTM) of the observation sequence;
a convolutional neural network CNN connected with the long and short memory networks and outputting the reliability probability value; the CNN includes at least: the convolution layer and two pooling layers located at the rear end of the convolution layer.
In the embodiment of the present disclosure, after obtaining an observation sequence composed of observation values, the machine learning model receives the observation sequence, specifically, the machine learning model includes a bidirectional long and short memory network BiLSTM receiving the observation sequence, and the convolutional neural network CNN is followed by the long and short memory network.
In the embodiment of the disclosure, the bidirectional long-short memory network BiLSTM is a bidirectional long-short memory network LSTM, and the observed values are generally predicted from left to right relative to the LSTM, so that the observed values behind are more important than the observed values in front.
In the embodiment of the disclosure, because
tComments on information between individual users, e.g. users
tWill trust the user
t-1 published or forwarded information F, user
tPossibly forwarding the information F and commenting with the user
t1 attitude-like statements, or take user-like statements
t1 similar operational behavior. When observing the sequence
After being input into a bidirectional long and short memory network BilSTM layer, the information of the left sequence and the right sequence in the observation value can be obtained, and finally the bidirectional long and short memory networkThe envelope layer outputs a feature matrix. See equations 1.1 and 1.2 of the above example for specific calculation equations.
In the disclosed embodiment, the feature matrix output by the two-way long and short memory network layer is input into the convolutional neural network CNN layer, and as shown in fig. 5, the feature matrix is first convolved by the convolutional layer, and then enters the two pooling layers for feature screening, so as to obtain the feature vector matrix.
In the embodiment of the disclosure, the convolutional neural network further comprises a full connection layer and a softmax layer, the softmax layer is connected with the full connection layer in a rear mode, and finally the probability value of the reliability is output.
In the embodiment of the present disclosure, the structure of the machine learning model is the same as that in the embodiment of the information processing method, and the calculation principle corresponding to the structure is also the same.
In the embodiment of the present disclosure, as shown in fig. 5, the two pooling layers include:
a maximum pooling layer;
and the average pooling layer is positioned at the rear end of the maximum pooling layer.
In the embodiment of the present disclosure, a calculation formula of the maximum pooling layer is as follows:
The calculation formula of the average pooling layer is as follows:
The splicing formula of the maximum pooling layer and the average pooling layer is as follows:
In the embodiments of the present disclosure, it is,
the output of the maximum pooling is represented,
the output of the average pooling is represented,
it is shown that the operation of splicing,
indicating the sliding window size. By utilizing the method of splicing the maximum pooling and the average pooling, the defect that the information is lost because the maximum value can be taken only once in each maximum pooling operation is overcome. And the results of the two pooling operations are subjected to feature fusion, so that the integrity of sequence feature information is ensured, and more comprehensive and deep features are obtained.
In the embodiment of the present disclosure, as shown in fig. 7, the training method further includes:
step S204, based on the characteristic data set of the sample user, using a clustering device to classify the users according to the identification degrees, wherein the users with the same identification degree grade belong to the same label under the same category;
step S205, testing a plurality of different types of classification models based on the labels and the characteristic data sets of the users to obtain different test results;
and S206, based on the matching degree of the test result and the k-means clustering device, taking a classification model with high matching degree as a classification model for performing classification calculation on the recognition degree.
In the embodiment of the present disclosure, a clustering device clusters a plurality of different users into M different clusters, so that each cluster corresponds to one recognition level, the recognition levels of active users in the same cluster are the same, and finally, the active users in the same cluster are labeled with the same label. Since there are multiple clusters, there are multiple labels obtained using the clusterer.
In the embodiment of the present disclosure, the clustering device is an algorithm for dividing data based on a clustering algorithm, and may be, but not limited to, a k-means clustering algorithm-based clustering device, a mean shift clustering algorithm, a density-based clustering algorithm (DBSCAN), a maximum Expectation (EM) clustering algorithm of a gaussian mixture model GMM, a coacervation hierarchical clustering algorithm, a graph group detection algorithm, and the like.
In the embodiment of the present disclosure, the multiple candidate models are candidate models used for classifying the degree of recognition of the user, and may be, but are not limited to: and inputting the labels obtained by using the clustering device and the user characteristic data sets corresponding to the labels into a plurality of different alternative models to obtain a plurality of test results under each alternative model, and taking the alternative model with the highest goodness of fit between the test results and the clustering device as the classification model.
In the embodiment of the present disclosure, the classification models of the alternative models include, but are not limited to: naive Bayes (NB), Decision Trees (DT), Support Vector Machines (SVM), and other common classification models.
In one embodiment, the labels obtained based on the clustering algorithm and the user data marked by the labels are used for training and testing classifiers based on different classification algorithms, and then the best classifier is selected as the classification model according to the matching degree of the test result and the clustering device.
In one embodiment, the slave userK t Extracting characteristic values from the personal attribute data and the information corresponding to the information F, and then using the trained optimal classifier to perform classification on the userK t Is classified to obtainx t The value of (a).
In the embodiment of the disclosure, the label to which the user belongs is obtained through clustering, the label and the corresponding user characteristic data are input into the alternative models, one alternative model with the highest matching degree with the clustering device is selected as the optimal classification model according to the test result for classifying the identification degree of the user, and when the characteristic data set of the user is input into the trained classification model, the identification degree of the user can be obtained, so that the identification degree of the user can be conveniently calculated, and the calculated amount is properly reduced.
An example of an information processing method and a training method is provided in combination with the above embodiments:
example 1: provided are an information processing method and a training method.
The microblog is a social media which has a plurality of users, a wide range of relation and rapid information dissemination. The invention provides a microblog false information detection method in order to reduce the influence of false information on the public and enable microblogs to play a more positive role in production and life of people.
Because the microblog has the information purification function, when the information has obvious errors, the information cannot be widely spread, so that the false information of the microblog can be found early only by detecting the false information of the popular information on the microblog and if the credibility of the microblog information can be evaluated in real time.
Basic concepts and models:
(1) active users: the active users can judge the authenticity of the information, and the active users in the microblog can be divided into 3 types: users who only comment information and do not forward information, users who only forward information and do not comment information, users who add comments when forwarding information, and users who do not comment and do not forward information are excluded from active users.
(2) Information identification degree: the recognition ability of an active user to the truth of a certain piece of information is called recognition degree, wherein the higher the recognition degree is, the more correctly the user can recognize the false information. The identification degree of the active user is measured by the number of fans of the active user, the number of users concerned by the active user, whether the active user is an authentication user, the gender of the active user, the number of messages issued/forwarded by the active user, the registration time of the active user and the number of times of the tags of the active user appearing in the information of the subject relationship.
(3) Attitude of active users: in the process of information dissemination, the attitude of each active user of the information is different, and the attitude of the active user to the information can be determined according to the comments of the users, namely positive, negative or neutral. For users who only forward information and do not comment on the information, the attitude of the information is considered to be neutral. For active users who make comments, whether the attitude is positive or negative can be extracted by accessing the existing semantic analysis product interface. The attitude of the information is simply referred to as the attitude of the active user.
(4) Recognition level of active users: the invention uses a classification algorithm to automatically judge the recognition degree grade of the active user. Assuming that the recognition degree of the active users can be divided into M levels, when some information F is uploaded on a microblog, the order represents the second leveltAn active userK t The degree of recognition of the information F. Using a classification algorithm to automatically derive therefromK t Degree of recognition ofx t The method comprises the following steps:
(a) collecting relevant data of active users appearing in the propagation process of a large amount of real popular information on a microblog, and then extracting characteristic values of each active user, namely the number of fans of the active user, the number of users concerned by the active user, whether the active user is an authentication user, the gender of the active user, the number of messages issued/forwarded by the active user, the registration time of the active user and the number of times of the label of the active user appearing in the information of the subject relationship, wherein the number of times of the label of the active user appearing in the information of the subject relationship refers to the number of times of information needing to judge the authenticity or the false or false of the information in the information issued or forwarded by the active user;
(b) based on the characteristic values of the active users, clustering the active users in the step (a) into M different clusters by using a k-means clustering algorithm, enabling each cluster to correspond to one recognition degree grade, enabling the recognition degree grades of the active users in the same cluster to be the same, and finally marking the active users in the same cluster with the same class label;
(c) training and testing classifiers based on different classification algorithms using the labeled data of step (b), and then selecting the best classifier according to the test result;
(d) from active usersK t Extracting characteristic values from the Bo Wen corresponding to the personal data and the information F, and then using the trained optimal classifier pairK t Is classified to obtainx tThe value of (a).
(e) Is obtained byx tAfter the value is taken, active users can be obtained by using some existing microblog opinion mining methods based on comments of the usersK t The attitude of (c).
(5) Observation sequence: order to
y t Is shown as
tIndividual user
K t The resulting observations. When the user is
K t If F is in positive attitude, then observation value is obtained
(ii) a When the user is
K t If F is in negative attitude, then
(ii) a When the user is
K t When F is in neutral attitude, then
Wherein
and therefore, the first and second electrodes are,
y t integer values are taken. Order to
The length of the representation information F generated in the propagation process is
tThe observation sequence of (1). That is, the information F will experience in the process of being propagated by different users
tThe observed value of the information F may be the same or different between each user,
indicating information F in
tWhen the data is transmitted between the users, the users can,
tand the observation sequence is formed by the observation values of the information F of the users. Wherein,
t=1,2,3,···,
t。
it can also be understood as a concatenated vector of attitude values of information by multiple users.
(6) And (3) detecting the model: the invention provides a false information detection model combining Bi-LSTM and CNN. The model is shown in fig. 5. Firstly, a Bi-LSTM network is adopted to receive an observation sequence, and Bi-LSTM can acquire information of a left sequence and a right sequence of a target sequence due to the characteristic of bidirectional calculation. The specific calculation formula is as follows:
In the above equation 1.8 and equation 1.9,
is shown as
iThe feature vector of the observation to the left of the individual observations,
is a transition from a current hidden layer to a next hidden layer
The matrix represents information connecting the left observations of the current word.
A feature vector representing the left observation of the previous word,
the feature vector representing the current observed value, similarly, can be calculated using equation 1.9
Feature vector of right-hand observation
。
In the embodiment of the present disclosure, the current observed value is obtained according to the above formula 1.8 and the above formula 1.9
The calculation formula is as follows:
Secondly, inputting the feature matrix output by the Bi-LSTM network layer into the convolutional layer for convolution operation, and after the convolution operation, using the feature matrix for feature screening to further extract the correlation features of adjacent observed values in the sequence feature matrix, wherein the concrete calculation formula of the pooling part is as follows:
the maximum pooling layer is calculated as follows:
The calculation formula of the average pooling layer is as follows:
The splicing formula of the maximum pooling layer and the average pooling layer is as follows:
In the embodiments of the present disclosure, it is,
the output of the maximum pooling is represented,
the output of the average pooling is represented,
it is shown that the operation of splicing,
indicating the sliding window size. By utilizing the method of splicing the maximum pooling and the average pooling, the defect that the information is lost because the maximum value can be taken only once in each maximum pooling operation is overcome. And the results of the two pooling operations are subjected to feature fusion, so that the integrity of sequence feature information is ensured, and more comprehensive and deep features are obtained.
In the embodiment of the present disclosure, specifically referring to the dual pooling layer part in fig. 5, regarding feature fusion of the results of two pooling operations, the maximum pooling result and the average pooling result are spliced into a new feature, that is, the maximum pooling result obtains a k × m-dimensional vector, and the average pooling result obtains a k × m-dimensional vector, and then the maximum pooling result and the average pooling result are spliced after being aligned to generate a k × 2 m-dimensional vector, where k =1, 2, 3, ·, k; m =1, 2, 3, ·, m. For example, the maximum pooling result yields a 1 row by 5 column vector, and the average pooling result yields a 1 row by 5 column vector, and the concatenation of the maximum pooling result and the average pooling result yields a 1 row by 10 column vector. For example, the vector resulting from the maximum pooling result is: (a)1,a2,a3,a4,a5) (ii) a The vector obtained by averaging the pooling results is: (b)1,b2,b3,b4,b5) And the vector generated by splicing the maximum pooling result and the average pooling result is as follows: (a)1,a2,a3,a4,a5,b1,b2,b3,b4,b5)。
Finally, the feature expression of the sentence extracted by the double-pooling layer is used as the input of the Softmax layer, and the specific calculation formula of the classification process is shown as follows:
In the above-mentioned formula 2.5,
represents a probability value
yBelonging to the range of 0 to 1,
the dimension of the feature matrix is the same as the dimension of the sequence feature matrix Z,
represents the bias term and Z represents the sequence feature matrix.
In conjunction with fig. 5, the classification process of the features by the Softmax layer is a binary classification process.
The method comprises the following specific implementation steps:
and S1, data acquisition and preprocessing. Collecting a large amount of data sets generated by popular real information on a microblog, preprocessing the data sets, obtaining the recognition degree grade and attitude of an active user by utilizing the automatic distinguishing method of the recognition degree grade of the active user and the existing microblog opinion mining method, then constructing an observation value according to the recognition degree grade and attitude of the active user, and finally obtaining a large amount of observation sequences generated by the popular real information to be used as the data sets for model training;
s2, inputting the data set into the model shown in the figure 5 for training;
s3, false information detection. The observation sequence is input into the trained model, the model can calculate the credibility of each piece of information in real time and output credible and incredible scores (one percent in total), and whether the information is false information or not is judged by setting a threshold value, so that the information can be found as soon as possible.
The invention provides a data processing mode based on an information active user, which formalizes the microblog information transmission process by setting the information active user and converts the microblog information transmission process into an observation sequence, thereby facilitating the processing of various models. Meanwhile, a deep learning model is provided, false information detection is effectively carried out on the extracted observation sequence, and the influence of the false information on the public is reduced.
In the embodiment of the present disclosure, as shown in fig. 8, an information processing apparatus 300 is provided, where the apparatus 300 includes:
the first determining module 301 is configured to obtain an observation sequence of information by a user according to the identification degree of the user and comment data of the user on the information; wherein the identification degree reflects the authentication ability of the user for information; the observation sequence comprises: the observation value of the user to the information indicates the attitude information of the user to the information, and the attitude information of the user to the information includes: negative attitude, neutral attitude and positive attitude;
a second determining module 302, configured to input the observation sequence into a trained machine learning model, so as to obtain a reliability probability value of the observation sequence;
and a third determining module 303, configured to obtain authenticity of the information according to the reliability probability value.
In the embodiment of the present disclosure, the information processing apparatus 300 further includes:
a first data obtaining module 304, configured to obtain attribute data of a user who has performed a preset operation on the information; wherein the preset operational behavior is indicative of at least one of: the user approves, reviews or forwards the information; the attribute data of the user includes at least one of: the method comprises the following steps of (1) determining the amount of vermicelli of a user, the amount of attention of the user and the amount of information needing to judge the authenticity of the information in published or forwarded information of the user;
a first feature obtaining module 305, configured to obtain a feature data set of the user according to the attribute data of the user;
the second determining module 303 is configured to input the feature data set of the user into a classification model, so as to obtain the recognition degree of the user.
In an embodiment of the present disclosure, the second determining module 303 is further configured to:
the recognition degree of the user is obtained based on the characteristic data of the user by utilizing a classification model; wherein the classification model is: and the test result output from a plurality of candidate models trained by using labels obtained by the clustering device is the one with the highest matching degree with the clustering device.
In this embodiment of the present disclosure, the first determining module 301 is further configured to:
the information processing device is used for obtaining attitude information of the user to the information according to the identification degree of the user and comment data of the user to the information;
and the observation sequence of the information by the user is obtained according to the attitude information of the information by the user.
In an embodiment of the present disclosure, the third determining module 303 is further configured to:
the credibility score is obtained according to the credibility probability value;
and if the credibility score meets the condition that the credibility score is larger than a preset threshold value, the information is real information.
In the embodiment of the present disclosure, as shown in fig. 9, an exercise device 400 is provided, where the exercise device 400 includes:
an obtaining module 401, configured to obtain an identification degree of a sample user;
a fourth determining module 402, configured to obtain a sample of the observation sequence according to the evaluation data of the sample user;
and a training module 403, configured to train a machine learning model in the foregoing information processing method according to the sample of the observation sequence and the recognition degree of the sample user.
In an embodiment of the present disclosure, there is provided an electronic device including:
a processor;
a memory for storing processor-executable instructions;
wherein the processor is configured to implement the steps of the feedback method when running the computer service.
Those of ordinary skill in the art will understand that: all or part of the steps for implementing the method embodiments may be implemented by hardware related to program instructions, and the program may be stored in a computer readable storage medium, and when executed, the program performs the steps including the method embodiments; and the aforementioned storage medium includes: a mobile storage device, a Read-Only Memory (ROM), a Random Access Memory (RAM), a magnetic disk or an optical disk, and other various media capable of storing program codes.
In the embodiment of the present disclosure, a storage medium is provided, and the storage medium has computer-executable instructions, which are executed by a processor to implement the steps in the information processing method or the training method described above.
Alternatively, the integrated unit according to the embodiment of the present invention may be stored in a computer-readable storage medium if it is implemented in the form of a software functional module and sold or used as a separate product. Based on such understanding, the technical solutions of the embodiments of the present invention may be essentially implemented or a part contributing to the prior art may be embodied in the form of a software product, which is stored in a storage medium and includes several instructions for causing a computer device (which may be a personal computer, a server, or a network device) to execute all or part of the methods described in the embodiments of the present invention. And the aforementioned storage medium includes: a mobile storage device, a Read-Only Memory (ROM), a Random Access Memory (RAM), a magnetic disk or an optical disk, and other various media capable of storing program codes.
The above description is only for the specific embodiments of the present disclosure, but the scope of the present disclosure is not limited thereto, and any person skilled in the art can easily conceive of the changes or substitutions within the technical scope of the present disclosure, and all the changes or substitutions should be covered within the scope of the present disclosure. Therefore, the protection scope of the present disclosure shall be subject to the protection scope of the claims.