CN113221974B - Cross map matching incomplete multi-view clustering method and device - Google Patents
Cross map matching incomplete multi-view clustering method and device Download PDFInfo
- Publication number
- CN113221974B CN113221974B CN202110453720.3A CN202110453720A CN113221974B CN 113221974 B CN113221974 B CN 113221974B CN 202110453720 A CN202110453720 A CN 202110453720A CN 113221974 B CN113221974 B CN 113221974B
- Authority
- CN
- China
- Prior art keywords
- matrix
- missing
- data
- cross
- incomplete
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本申请公开了一种交叉图匹配不完整多视图聚类方法及装置,方法包括:建立不完整多模态数据的缺失值填充模型,多模态数据包括网页数据或者多媒体数据;建立不完整多模态数据的交叉图匹配模型;结合缺失值填充模型和交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;将交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;采用迭代算法求解三个子问题直到三个子问题收敛,求得最优解。本申请在减少缺失数据的影响的同时,利用模态间一致和互补的信息来使得聚类效果得到提升。

The present application discloses a method and device for clustering incomplete multi-views with cross graph matching. The method includes: establishing a missing value filling model for incomplete multi-modal data, where the multi-modal data includes web page data or multimedia data; Cross-graph matching model for modal data; combined with the objective functions of the missing value filling model and the cross-graph matching model, a cross-graph matching incomplete multi-view clustering model is established; the cross-graph matching incomplete multi-view clustering model is decomposed into three sub-sections The problem includes optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S; using an iterative algorithm to solve the three sub-problems until the three sub-problems converge, the optimal solution is obtained. While reducing the impact of missing data, the present application utilizes consistent and complementary information between modalities to improve the clustering effect.
Description
技术领域technical field
本申请涉及图像聚类技术领域,尤其涉及一种交叉图匹配不完整多视图聚类方法及装置。The present application relates to the technical field of image clustering, and in particular, to a method and device for multi-view clustering with incomplete cross-graph matching.
背景技术Background technique
在大数据时代,数据采集渠道与特征提取的种类日益多样,使得同一对象可以从多种数据源、特征进行描述,产生多模态数据,例如一个网页数据可以由文本来刻画,同时也可以由指向该页面的超链接来描述;一个多媒体片段数据可以由其视频和音频信号同时描述。在实际应用中,由于标签采集费时费力,往往只能采集到少量监督信息,而多模态半监督聚类方法能将有限的监督信息与大量的无监督信息结合起来学习,大大地提升了聚类效果。In the era of big data, the types of data collection channels and feature extraction are becoming more and more diverse, so that the same object can be described from multiple data sources and features, resulting in multi-modal data. A hyperlink to this page is described; a multimedia segment data can be described by its video and audio signals simultaneously. In practical applications, due to the time-consuming and labor-intensive label collection, only a small amount of supervised information can often be collected. However, the multimodal semi-supervised clustering method can combine limited supervised information with a large amount of unsupervised information to learn, which greatly improves the clustering performance. class effect.
然而在实际应用中,由于数据采集器的临时失效或者人为失误,导致某些模态的数据缺失,往往会得到不完整的多视图数据。现有的多模态聚类算法大多基于完整数据而设计,无法直接处理不完整多模态数据,因此不完整多模态聚类应运而生,旨在减少缺失数据的影响的同时,利用模态间一致和互补的信息来使得聚类效果得到提升。However, in practical applications, due to the temporary failure of the data collector or human error, the data of some modalities is missing, and incomplete multi-view data is often obtained. Most of the existing multimodal clustering algorithms are designed based on complete data, and cannot directly deal with incomplete multimodal data. Therefore, incomplete multimodal clustering emerges as the times require. The consistent and complementary information between states can improve the clustering effect.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种交叉图匹配不完整多视图聚类方法及装置,使得在减少缺失数据的影响的同时,利用模态间一致和互补的信息来使得聚类效果得到提升。Embodiments of the present application provide a method and apparatus for multi-view clustering with incomplete cross graph matching, so that the clustering effect can be improved by using consistent and complementary information between modalities while reducing the impact of missing data.
有鉴于此,本申请第一方面提供了一种交叉图匹配不完整多视图聚类方法,所述方法包括:In view of this, a first aspect of the present application provides a multi-view clustering method for incomplete cross graph matching, the method comprising:
建立不完整多模态数据的缺失值填充模型,所述多模态数据包括网页数据或者多媒体数据;establishing a missing value filling model for incomplete multimodal data, where the multimodal data includes web page data or multimedia data;
建立不完整多模态数据的交叉图匹配模型;Build a cross-graph matching model for incomplete multimodal data;
结合所述缺失值填充模型和所述交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;In combination with the objective function of the missing value filling model and the cross-graph matching model, a multi-view clustering model with incomplete cross-graph matching is established;
将所述交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;Decomposing the multi-view clustering model with incomplete cross graph matching into three sub-problems, including optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S;
采用迭代算法求解所述三个子问题直到三个子问题收敛,求得最优解。The three sub-problems are solved by an iterative algorithm until the three sub-problems converge, and an optimal solution is obtained.
可选的,所述缺失值填充模型的目标函数为:Optionally, the objective function of the missing value filling model is:

式中,X(v)为不完整模态数据,X(v)∈Rdv×N,dv是第v个模态的特征维度,{E(1),E(2),...,E(m)}表示多个模态的缺失数据,其中E(v)∈Rdv×nv,nv是第v个模态的缺失样本数,(N-nv)是第v个模态实际样本数;关系矩阵W(v)∈Rnv×N,如果E(v)中第i个节点是X(v)中第j个节点,那么

可选的,所述交叉图匹配模型的目标函数为:Optionally, the objective function of the cross graph matching model is:

式中,λ2>0是权衡参数;




可选的,所述交叉图匹配不完整多视图聚类模型的目标函数为:Optionally, the objective function of the cross graph matching incomplete multi-view clustering model is:

可选的,所述采用迭代算法求解所述三个子问题直到三个子问题收敛,求得最优解,包括:Optionally, the iterative algorithm is used to solve the three sub-problems until the three sub-problems converge, and an optimal solution is obtained, including:
初始化连接矩阵S;Initialize the connection matrix S;
固定映射空间U(v)和连接矩阵S(v),更新缺失矩阵E(v);Fix the mapping space U (v) and the connection matrix S (v) , update the missing matrix E (v) ;
固定缺失矩阵E(v)和连接矩阵S(v),更新映射空间U(v);Fix the missing matrix E (v) and the connection matrix S (v) , update the mapping space U (v) ;
固定缺失矩阵E(v)和映射空间U(v),通过迭代算法求解连接矩阵S(v)的目标方程。The missing matrix E (v) and the mapping space U (v) are fixed, and the objective equation of the connection matrix S (v) is solved by an iterative algorithm.
可选的,所述初始化连接矩阵S包括:Optionally, the initialization connection matrix S includes:

其中,

式中,

可选的,所述固定映射空间U(v)和连接矩阵S(v),更新缺失矩阵E(v),包括:Optionally, the fixed mapping space U (v) and the connection matrix S (v) update the missing matrix E (v) , including:

可选的,所述固定缺失矩阵E(v)和连接矩阵S(v),更新映射空间U(v),包括Optionally, the fixed missing matrix E (v) and the connection matrix S (v) update the mapping space U (v) , including

可选的,固定缺失矩阵E(v)和映射空间U(v),通过迭代算法求解连接矩阵S(v)的目标方程,包括:Optionally, fix the missing matrix E (v) and the mapping space U (v) , and solve the objective equation of the connection matrix S (v) by an iterative algorithm, including:

式中,




本申请第二方面提供一种交叉图匹配不完整多视图聚类装置,所述装置包括:A second aspect of the present application provides an incomplete multi-view clustering apparatus for cross graph matching, the apparatus comprising:
第一建立单元,用于建立不完整多模态数据的缺失值填充模型,所述多模态数据包括网页数据或者多媒体数据;a first establishment unit, configured to establish a missing value filling model for incomplete multimodal data, where the multimodal data includes web page data or multimedia data;
第二建立单元,用于建立不完整多模态数据的交叉图匹配模型;The second establishment unit is used to establish a cross-graph matching model of incomplete multimodal data;
第三建立单元,用于结合所述缺失值填充模型和所述交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;a third establishment unit, configured to establish a multi-view clustering model with incomplete cross-graph matching in combination with the objective function of the missing value filling model and the cross-graph matching model;
分解单元,用于将所述交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;a decomposition unit, configured to decompose the incomplete multi-view clustering model of cross graph matching into three sub-problems, including optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S;
求解单元,用于采用迭代算法求解所述三个子问题直到三个子问题收敛求得最优解。The solving unit is used for solving the three sub-problems by using an iterative algorithm until the three sub-problems converge to obtain an optimal solution.
从以上技术方案可以看出,本申请具有以下优点:As can be seen from the above technical solutions, the present application has the following advantages:
本申请中,提供了一种交叉图匹配不完整多视图聚类方法及装置,方法包括:建立不完整多模态数据的缺失值填充模型,多模态数据包括网页数据或者多媒体数据;建立不完整多模态数据的交叉图匹配模型;结合缺失值填充模型和交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;将交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;采用迭代算法求解三个子问题直到三个子问题收敛,求得最优解。In the present application, a method and device for clustering incomplete multi-views with cross graph matching are provided. The method includes: establishing a missing value filling model for incomplete multi-modal data, where the multi-modal data includes web page data or multimedia data; Cross-graph matching model for complete multimodal data; combined with the objective functions of the missing value filling model and the cross-graph matching model, a cross-graph matching incomplete multi-view clustering model is established; the cross-graph matching incomplete multi-view clustering model is decomposed into Three sub-problems, including optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S; using an iterative algorithm to solve the three sub-problems until the three sub-problems converge, the optimal solution is obtained.
本申请将缺失数据作为优化量,使得缺失值满足视图的潜在特征结构,从而降低缺失数据对聚类的影响。同时运用图学习方法,创新性地将可能变化的视图表示转化为具有不变性的图连接强度,并最小化不同视图之间的成对连接图的差异达到视图共识目标,从而有效的减少缺失数据的影响的同时,利用模态间一致和互补的信息来使得聚类效果得到提升。In this application, missing data is used as an optimization amount, so that missing values satisfy the latent feature structure of the view, thereby reducing the impact of missing data on clustering. At the same time, the graph learning method is used to innovatively transform the possibly changing view representation into an invariant graph connection strength, and minimize the difference of pairwise connection graphs between different views to achieve the goal of view consensus, thereby effectively reducing missing data. At the same time, the consistent and complementary information between modalities is used to improve the clustering effect.
附图说明Description of drawings
图1为本申请一种交叉图匹配不完整多视图聚类方法的一个实施例中的方法流程图;FIG. 1 is a flow chart of a method in an embodiment of a method for multi-view clustering with incomplete cross graph matching according to the present application;
图2为本申请一种交叉图匹配不完整多视图聚类装置的一个实施例的装置结构图;FIG. 2 is a device structure diagram of an embodiment of an incomplete multi-view clustering device for cross graph matching according to the present application;
图3为本申请实施例中采用交叉图匹配不完整多视图聚类算法的流程实例图。FIG. 3 is an example flowchart of an incomplete multi-view clustering algorithm using cross graph matching in an embodiment of the present application.
具体实施方式Detailed ways
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。In order to make those skilled in the art better understand the solutions of the present application, the technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present application. Obviously, the described embodiments are only It is a part of the embodiments of the present application, but not all of the embodiments. Based on the embodiments in the present application, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present application.
请参阅图1,图1为本申请一种交叉图匹配不完整多视图聚类方法的一个实施例的方法流程图,如图1所示,图1中包括:Please refer to FIG. 1. FIG. 1 is a method flowchart of an embodiment of an incomplete multi-view clustering method for cross graph matching according to the present application. As shown in FIG. 1, FIG. 1 includes:
101、建立不完整多模态数据的缺失值填充模型,多模态数据包括网页数据或者多媒体数据;101. Establish a missing value filling model for incomplete multimodal data, where the multimodal data includes web page data or multimedia data;
需要说明的是,本申请中的多模态数据可以包括网页数据或者多媒体数据等,例如一个网页数据可以由文本来刻画,同时也可以由指向该页面的超链接来描述;一个多媒体片段数据可以由其视频和音频信号同时描述。本申请就是对这一类数据进行聚类处理。It should be noted that the multimodal data in this application may include web page data or multimedia data, etc. For example, a web page data can be described by text, and can also be described by a hyperlink pointing to the page; a multimedia segment data can be Described by its video and audio signals simultaneously. This application is to perform clustering processing on this type of data.
具体的,对于给定具有N个样本、m个模态的多模态数据{X(1),X(2),...,X(m)},其中X(v)∈Rdv×N,dv是第v个模态的特征维度,每个模态的缺失样本用0表示。{E(1),E(2),...,E(m)}表示多个模态的缺失数据,其中E(v)∈Rdv×nv,nv是第v个模态的缺失样本数,(N-nv)是第v个模态实际样本数。Specifically, for a given multimodal data {X (1) , X (2) , . . . , X (m) } with N samples and m modalities, where X (v) ∈ R dv× N , d v are the feature dimensions of the vth modality, and the missing samples of each modality are denoted by 0. {E (1) , E (2) ,...,E (m) } denotes missing data for multiple modalities, where E (v) ∈ R dv×nv , n v is the missing of the vth modality Number of samples, (Nn v ) is the actual number of samples for the vth mode.
本申请可以将缺失数据{E(v),v=1,2,...,m}看作可优化变量,使其在聚类的同时,遵循各自模态下的特征分布进行优化更新,即利用了缺失数据隐藏的语义信息。缺失值填充模型为:In this application, the missing data {E (v) , v=1, 2, . That is, the semantic information hidden by the missing data is exploited. The missing value filling model is:

其中,缺失值{E(v),v=1,2,...,m}可以初始化为相关模态的平均值。关系矩阵W(v)∈Rnv×N,如果E(v)中第i个节点是X(v)中第j个节点,那么
即E(v)W(v)可以正好对应于模态缺失数据,即对应图3左半部分所示的缺失部分,由图3可知,X(v)+E(v)W(v)可以表示填充后的完整模态信息。







102、建立不完整多模态数据的交叉图匹配模型;102. Establish a cross graph matching model for incomplete multimodal data;
需要说明的是,可以令{U(v)∈Rdv×N,v=1,2,...,m}表示多模态的映射空间。这种方式将原始特征作为表示学习的重要依据,U(v)应与X(v)相近,否则会破坏拓扑结构。此外,还应考虑每个样本之间的相似性:如果两个样本在一个模态中具有较高的相似度,那么它们的表示





其中,





和多视图聚类一样,不完整多视图聚类仍要解决两个挑战:1)如何挖掘一致的信息;2)如何表达视图之间的关系。本申请中通过约束映射空间构建的多个连接图之间两两匹配,即最小化任意两个连接图之间的差异,构建视图共识。最小化视图间差异:Like multi-view clustering, incomplete multi-view clustering still has two challenges to solve: 1) how to mine consistent information; 2) how to express the relationship between views. In this application, pairwise matching between multiple connection graphs constructed by constraining the mapping space, that is, minimizing the difference between any two connection graphs, and constructing a view consensus. Minimize differences between views:

即所述交叉图匹配模型的目标函数为:That is, the objective function of the cross graph matching model is:

103、结合缺失值填充模型和交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;103. Combine the objective function of the missing value filling model and the cross-graph matching model to establish a multi-view clustering model with incomplete cross-graph matching;

104、将交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;104. Decompose the incomplete multi-view clustering model of cross graph matching into three sub-problems, including optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S;
需要说明的是,本申请可以将交叉图匹配不完整多视图聚类模型分解为三个子问题,分别包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S。It should be noted that this application can decompose the multi-view clustering model with incomplete cross graph matching into three sub-problems, including optimizing the missing matrix E, solving the mapping space U, and updating the connection matrix S, respectively.
105、采用迭代算法求解三个子问题直到三个子问题收敛,求得最优解。105. Use an iterative algorithm to solve the three sub-problems until the three sub-problems converge, and obtain the optimal solution.
需要说明的是,本申请可以采用迭代算法求解三个子问题直到三个子问题收敛,求得最优解,包括:It should be noted that this application can use an iterative algorithm to solve the three sub-problems until the three sub-problems converge, and obtain the optimal solution, including:
501、初始化连接矩阵S;501. Initialize the connection matrix S;
需要说明的是,本申请首先可以初始化连接矩阵S,具体的,为减少缺失值对构图的影响,可以采用实际样本数据X(v)∈Rdv×N-nv构建相似图


若两个节点









由于最终需要更新完整视图S(v),因此为得到完整图S(v),对

其中,

502、固定映射空间U(v)和连接矩阵S(v),更新缺失矩阵E(v);502. Fix the mapping space U (v) and the connection matrix S (v) , and update the missing matrix E (v) ;
需要说明的是,不完整多模态数据矩阵X(v)中对应于缺失矩阵E(v)中的缺失部分均为0,因此更新E(v)的目标方程式可改为:It should be noted that the missing parts in the incomplete multimodal data matrix X (v) corresponding to the missing matrix E (v) are all 0, so the objective equation for updating E (v) can be changed to:

求

使得偏导

503、固定缺失矩阵E(v)和连接矩阵S(v),更新映射空间U(v);503. Fix the missing matrix E (v) and the connection matrix S (v) , and update the mapping space U (v) ;
需要说明的是,求解U(v)的目标方程为:It should be noted that the objective equation for solving U (v) is:

其中

504、固定缺失矩阵E(v)和映射空间U(v),通过迭代算法求解连接矩阵S(v)的目标方程。504. Fix the missing matrix E(v) and the mapping space U(v), and solve the objective equation of the connection matrix S(v) through an iterative algorithm.
需要说明的是,求解S(v)的目标方程式为:It should be noted that the objective equation for solving S (v) is:

令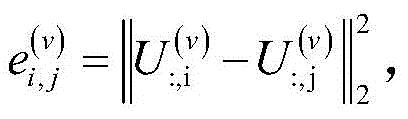

可以通过迭代方法求解出S(v),直到连接矩阵收敛S(v)。S (v) can be solved iteratively until the connection matrix converges S (v) .
本申请将缺失数据作为优化量,使得缺失值满足视图的潜在特征结构,从而降低缺失数据对聚类的影响。同时运用图学习方法,创新性地将可能变化的视图表示转化为具有不变性的图连接强度,并最小化不同视图之间的成对连接图的差异达到视图共识目标,从而有效的减少缺失数据的影响的同时,利用模态间一致和互补的信息来使得聚类效果得到提升。In this application, missing data is used as an optimization amount, so that missing values satisfy the latent feature structure of the view, thereby reducing the impact of missing data on clustering. At the same time, the graph learning method is used to innovatively transform the possibly changing view representation into an invariant graph connection strength, and minimize the difference of pairwise connection graphs between different views to achieve the goal of view consensus, thereby effectively reducing missing data. At the same time, the consistent and complementary information between modalities is used to improve the clustering effect.
以上是本申请的方法的实施例,本申请还提供了一种交叉图匹配不完整多视图聚类装置的实施例,如图2所示,图2中包括:The above are the embodiments of the method of the present application, and the present application also provides an embodiment of an incomplete multi-view clustering apparatus for cross graph matching, as shown in FIG. 2 , which includes:
201、第一建立单元,用于建立不完整多模态数据的缺失值填充模型,多模态数据包括网页数据或者多媒体数据;201. A first establishment unit, configured to establish a missing value filling model for incomplete multimodal data, where the multimodal data includes web page data or multimedia data;
202、第二建立单元,用于建立不完整多模态数据的交叉图匹配模型;202. A second establishment unit, configured to establish a cross-graph matching model of incomplete multimodal data;
203、第三建立单元,用于结合缺失值填充模型和交叉图匹配模型的目标函数,建立交叉图匹配不完整多视图聚类模型;203. A third establishment unit, configured to combine the objective function of the missing value filling model and the cross-graph matching model to establish a multi-view clustering model with incomplete cross-graph matching;
204、分解单元,用于将交叉图匹配不完整多视图聚类模型分解为三个子问题,包括优化缺失矩阵E,求解映射空间U以及更新连接矩阵S;204. A decomposition unit, which is used to decompose the multi-view clustering model with incomplete cross-graph matching into three sub-problems, including optimizing the missing matrix E, solving the mapping space U and updating the connection matrix S;
205、求解单元,用于采用迭代算法求解三个子问题直到三个子问题收敛,求得最优解。205. A solving unit, used to solve the three sub-problems by using an iterative algorithm until the three sub-problems converge, and obtain an optimal solution.
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and brevity of description, the specific working process of the system, device and unit described above may refer to the corresponding process in the foregoing method embodiments, which will not be repeated here.
本申请的说明书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。The terms "first", "second", "third", "fourth", etc. in the description of the present application and the above-mentioned drawings are used to distinguish similar objects, and are not necessarily used to describe a specific order or sequence. . It is to be understood that data so used may be interchanged under appropriate circumstances such that the embodiments of the application described herein can, for example, be practiced in sequences other than those illustrated or described herein. Furthermore, the terms "comprising" and "having", and any variations thereof, are intended to cover non-exclusive inclusion, for example, a process, method, system, product or device comprising a series of steps or units is not necessarily limited to those expressly listed Rather, those steps or units may include other steps or units not expressly listed or inherent to these processes, methods, products or devices.
应当理解,在本申请中,“至少一个(项)”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系,例如,“A和/或B”可以表示:只存在A,只存在B以及同时存在A和B三种情况,其中A,B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”,其中a,b,c可以是单个,也可以是多个。It should be understood that, in this application, "at least one (item)" refers to one or more, and "a plurality" refers to two or more. "And/or" is used to describe the relationship between related objects, indicating that there can be three kinds of relationships, for example, "A and/or B" can mean: only A, only B, and both A and B exist , where A and B can be singular or plural. The character "/" generally indicates that the associated objects are an "or" relationship. "At least one item(s) below" or similar expressions thereof refer to any combination of these items, including any combination of single item(s) or plural items(s). For example, at least one (a) of a, b or c, can mean: a, b, c, "a and b", "a and c", "b and c", or "a and b and c" ", where a, b, c can be single or multiple.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in this application, it should be understood that the disclosed system, apparatus and method may be implemented in other manners. For example, the apparatus embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined or Can be integrated into another system, or some features can be ignored, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of devices or units, and may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present application may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit. The above-mentioned integrated units may be implemented in the form of hardware, or may be implemented in the form of software functional units.
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。As mentioned above, the above embodiments are only used to illustrate the technical solutions of the present application, but not to limit them; although the present application has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand: The technical solutions described in the embodiments are modified, or some technical features thereof are equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions in the embodiments of the present application.
Claims (6)








































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110453720.3A CN113221974B (en) | 2021-04-26 | 2021-04-26 | Cross map matching incomplete multi-view clustering method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110453720.3A CN113221974B (en) | 2021-04-26 | 2021-04-26 | Cross map matching incomplete multi-view clustering method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113221974A CN113221974A (en) | 2021-08-06 |
| CN113221974B true CN113221974B (en) | 2022-02-08 |
Family
ID=77089186
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110453720.3A Active CN113221974B (en) | 2021-04-26 | 2021-04-26 | Cross map matching incomplete multi-view clustering method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113221974B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113947135B (en) * | 2021-09-27 | 2022-07-08 | 华东师范大学 | Incomplete multi-view clustering method based on missing image reconstruction and self-adaptive neighbor |
| CN114461961B (en) * | 2021-12-30 | 2024-08-20 | 大连理工大学 | Incomplete multi-mode media data clustering method based on NMF and low-rank tensor |
| CN114882317B (en) * | 2022-05-24 | 2025-03-25 | 北京百度网讯科技有限公司 | Data processing method, device, electronic device and storage medium |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109508752A (en) * | 2018-12-20 | 2019-03-22 | 西北工业大学 | A kind of quick self-adapted neighbour's clustering method based on structuring anchor figure |
| CN109993214A (en) * | 2019-03-08 | 2019-07-09 | 华南理工大学 | Multiple view clustering method based on Laplace regularization and order constraint |
| CN110175631A (en) * | 2019-04-28 | 2019-08-27 | 南京邮电大学 | A multi-view clustering method based on jointly learned subspace structure and cluster indicator matrix |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102129477B (en) * | 2011-04-23 | 2013-01-09 | 山东大学 | Multimode-combined image reordering method |
| US10681060B2 (en) * | 2015-05-05 | 2020-06-09 | Balabit S.A. | Computer-implemented method for determining computer system security threats, security operations center system and computer program product |
| US10304263B2 (en) * | 2016-12-13 | 2019-05-28 | The Boeing Company | Vehicle system prognosis device and method |
| CN107492101B (en) * | 2017-09-07 | 2020-06-05 | 四川大学 | Multi-modal nasopharyngeal tumor segmentation algorithm based on self-adaptive constructed optimal graph |
| US10885379B2 (en) * | 2018-09-04 | 2021-01-05 | Inception Institute of Artificial Intelligence, Ltd. | Multi-view image clustering techniques using binary compression |
| CN111079565B (en) * | 2019-11-27 | 2023-07-07 | 深圳市华汉伟业科技有限公司 | Construction method and identification method of view two-dimensional attitude template and positioning grabbing system |
-
2021
- 2021-04-26 CN CN202110453720.3A patent/CN113221974B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109508752A (en) * | 2018-12-20 | 2019-03-22 | 西北工业大学 | A kind of quick self-adapted neighbour's clustering method based on structuring anchor figure |
| CN109993214A (en) * | 2019-03-08 | 2019-07-09 | 华南理工大学 | Multiple view clustering method based on Laplace regularization and order constraint |
| CN110175631A (en) * | 2019-04-28 | 2019-08-27 | 南京邮电大学 | A multi-view clustering method based on jointly learned subspace structure and cluster indicator matrix |
Non-Patent Citations (5)
| Title |
|---|
| A study of graph-based system for multi-view clustering;Hao Wang 等;《Knowledge-Based Systems》;20181028;第1009-1019页 * |
| Adaptive Graph Completion Based Incomplete Multi-View Clustering;Jie Wen 等;《IEEE TRANSACTIONS ON MULTIMEDIA》;20200803;第2493-2504页 * |
| Multi-view semi-supervised learning for classification on dynamic networks;Chuan Chen 等;《Knowledge-Based Systems》;20200227;第1-9页 * |
| Unified Embedding Alignment with Missing Views Inferring for Incomplete Multi-View Clustering;Jie Wen 等;《The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)》;20190717;第5393-5400页 * |
| 多视图构建模型研究;常晓静;《中国优秀硕士学位论文全文数据库信息科技辑》;20200315;第1-46页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113221974A (en) | 2021-08-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113221974B (en) | Cross map matching incomplete multi-view clustering method and device | |
| Tang et al. | Unified one-step multi-view spectral clustering | |
| Huang et al. | Auto-weighted multi-view co-clustering with bipartite graphs | |
| CN110674407B (en) | Hybrid recommendation method based on graph convolutional neural network | |
| CN109284406B (en) | Intention identification method based on difference cyclic neural network | |
| CN110084296A (en) | A kind of figure expression learning framework and its multi-tag classification method based on certain semantic | |
| CN112862092B (en) | Training method, device, equipment and medium for heterogeneous graph convolution network | |
| Qi et al. | Two-dimensional multilabel active learning with an efficient online adaptation model for image classification | |
| Zhuge et al. | Unsupervised single and multiple views feature extraction with structured graph | |
| CN114117142A (en) | Label perception recommendation method based on attention mechanism and hypergraph convolution | |
| CN111985520B (en) | Multi-mode classification method based on graph convolution neural network | |
| CN107256271A (en) | Cross-module state Hash search method based on mapping dictionary learning | |
| CN113672811A (en) | Hypergraph convolution collaborative filtering recommendation method and system based on topology information embedding and computer readable storage medium | |
| CN112487200B (en) | Improved deep recommendation method containing multi-side information and multi-task learning | |
| CN112581515A (en) | Outdoor scene point cloud registration method based on graph neural network | |
| Bu | A high-order clustering algorithm based on dropout deep learning for heterogeneous data in cyber-physical-social systems | |
| Zou et al. | Revisiting multi-view learning: A perspective of implicitly heterogeneous graph convolutional network | |
| Huang et al. | Community detection based on modularized deep nonnegative matrix factorization | |
| Liu et al. | Neural extraction of multiscale essential structure for network dismantling | |
| CN113378934B (en) | Small sample image classification method and system based on semantic perception map neural network | |
| CN115983341B (en) | A node classification method based on relational aggregation hypergraph | |
| WO2020049666A1 (en) | Time-series data processing device | |
| Wang et al. | Generative partial multi-view clustering | |
| CN119311950A (en) | An image recommendation method based on graph neural network | |
| Zheng et al. | Instance-Wise Weighted Nonnegative Matrix Factorization for Aggregating Partitions with Locally Reliable Clusters. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |