CN112507248A - Tourist attraction recommendation method based on user comment data and trust relationship - Google Patents
Tourist attraction recommendation method based on user comment data and trust relationship Download PDFInfo
- Publication number
- CN112507248A CN112507248A CN202010984598.8A CN202010984598A CN112507248A CN 112507248 A CN112507248 A CN 112507248A CN 202010984598 A CN202010984598 A CN 202010984598A CN 112507248 A CN112507248 A CN 112507248A
- Authority
- CN
- China
- Prior art keywords
- user
- trust
- words
- attribute
- score
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9537—Spatial or temporal dependent retrieval, e.g. spatiotemporal queries
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24147—Distances to closest patterns, e.g. nearest neighbour classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/14—Travel agencies
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Artificial Intelligence (AREA)
- Tourism & Hospitality (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Economics (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
一种基于用户评论数据和信任关系的旅游景点推荐方法,包括获取用户对景点的评论和评分信息、用户和景点属性信息以及用户好友关注列表;对评论信息进行文本预处理;提取评论中的属性‑情感词对并对情感词进行量化,构建主题情感向量;结合用户评分和主题情感向量建立用户偏好分布;计算不同用户之间偏好分布的相似度;结合用户关注列表信息建立目标用户的信任关系集合并计算信任度;结合用户相似度和信任度进行推荐;本发明充分利用用户评论信息进行主题提取,并对用户的评论进行情感分析与量化,同时结合评分数据,时间信息来更好建模用户偏好模型,另外通过构建用户信任关系集合来优化最近邻居选择,从而达到提高推荐准确率的目的。

A method for recommending tourist attractions based on user review data and trust relationship, including obtaining user's review and rating information on scenic spots, user and scenic spot attribute information, and user's friend follow list; text preprocessing on review information; and extracting attributes in reviews ‑Sentiment words are paired and quantified to construct topic sentiment vectors; combine user ratings and topic sentiment vectors to establish user preference distributions; calculate the similarity of preference distributions between different users; combine user follow list information to establish target users’ trust relationships Set and calculate the trust degree; combine user similarity and trust degree for recommendation; the present invention makes full use of user comment information for topic extraction, performs sentiment analysis and quantification on user comments, and combines scoring data and time information to better model User preference model, in addition to optimize the nearest neighbor selection by building a user trust relationship set, so as to achieve the purpose of improving the recommendation accuracy.
Description
技术领域technical field
本发明属于数据处理技术领域,具体涉及一种基于用户评论数据和信任关系的旅游景点推荐方法;The invention belongs to the technical field of data processing, and in particular relates to a method for recommending tourist attractions based on user comment data and trust relationship;
背景技术Background technique
互联网与大数据技术的迅速发展丰富了人们获取信息的方式和途径,与之相伴随的,信息的迅速膨胀使得人们在享受信息高速流通带来的便利的同时不得不消耗更多的精力去寻找自己想要获取的信息,甚至使得人们在面对海量信息的过程中无法清晰辨认出自己的目标和明确自己的需求,这就是“信息过载”现象;“信息过载”不但使人们获取自己感兴趣内容的效率变得更低外,而且使得信息空间中大量具有价值的信息无法被及时利用而造成浪费;面对以上这些现象,目前主要采用个性化推荐系统来缓解;The rapid development of the Internet and big data technology has enriched the ways and means for people to obtain information. Accompanying this, the rapid expansion of information makes people have to spend more energy to find the convenience while enjoying the convenience brought by the high-speed circulation of information. The information they want to obtain even makes people unable to clearly identify their own goals and clarify their needs in the process of facing massive amounts of information. This is the phenomenon of "information overload"; "information overload" not only makes people interested in obtaining information about themselves The efficiency of the content has become lower, and a large amount of valuable information in the information space cannot be used in time, resulting in waste; in the face of the above phenomena, the personalized recommendation system is mainly used to alleviate it;
个性化推荐技术目前常用的算法有基于协同过滤的推荐、基于内容的推荐和基于关联规则的推荐;其中,协同过滤算法由于其与项目的具体内容无关的特性,大大简化了技术人员所需要的项目相关的专业知识,已经成为推荐系统的一个主流技术并且得到了广泛的应用;但由于该算法过于依赖历史评分数据的特性使得本技术存在一些局限性;由于每个用户所能接触到的信息有限以及大部分冷门项目很少被浏览而产生历史数据稀疏的问题,从而导致推荐精度严重下降;另外新加入系统的用户或项目由于没有历史信息而产生冷启动的问题;以及随着用户量和商品量的增加,推荐系统的性能也会下降,影响了系统的扩展性;在当今互联网大数据技术不断发展的背景下,数据稀疏的情况是无法避免的,导致产生的目标用户的邻近用户集合选择出现误差,进而会造成推荐质量不高,随着数据规模的扩大,这个问题会更加突出;Personalized recommendation technology currently commonly used algorithms include collaborative filtering-based recommendation, content-based recommendation, and association rule-based recommendation; among them, collaborative filtering algorithm greatly simplifies the needs of technical personnel due to its characteristics that it has nothing to do with the specific content of the project. Project-related expertise has become a mainstream technology in recommender systems and has been widely used; however, due to the fact that the algorithm relies too much on historical scoring data, this technology has some limitations; due to the information that each user can access Limited and most unpopular items are rarely viewed, resulting in sparse historical data, resulting in a serious drop in recommendation accuracy; in addition, new users or items that join the system have a cold start problem because they have no historical information; With the increase in the quantity of commodities, the performance of the recommendation system will also decline, which affects the scalability of the system; under the background of the continuous development of Internet big data technology, the situation of data sparseness is unavoidable, resulting in the generation of a set of adjacent users of the target user. Errors in selection will result in poor recommendation quality. With the expansion of data scale, this problem will become more prominent;
发明内容SUMMARY OF THE INVENTION
为了克服上述现有技术的不足,本发明的目的是提供一种基于用户评论数据和信任关系的旅游景点推荐方法,为了提高推荐系统的准确率,弥补传统协同过滤中严重依赖评分数据导致应用过程中存在诸如数据稀疏性、冷启动、用户兴趣偏移问题;本发明充分利用用户评论信息进行主题提取,并对用户的评论进行情感分析与量化,同时结合评分数据,时间信息来更好建模用户偏好模型,另外通过构建用户信任关系集合来优化最近邻居选择,从而达到提高推荐准确率的目的;In order to overcome the above-mentioned deficiencies of the prior art, the purpose of the present invention is to provide a method for recommending tourist attractions based on user review data and trust relationship, in order to improve the accuracy of the recommendation system, to make up for the application process caused by the heavy reliance on scoring data in traditional collaborative filtering There are problems such as data sparsity, cold start, and user interest offset in the system; the present invention makes full use of user comment information for topic extraction, performs sentiment analysis and quantification on user comments, and combines scoring data and time information to better model User preference model, in addition to optimize the selection of nearest neighbors by building a user trust relationship set, so as to achieve the purpose of improving the recommendation accuracy;
一种基于用户评论数据和信任关系的旅游景点推荐方法,其特征在于,包括以下步骤:A method for recommending tourist attractions based on user review data and trust relationship, characterized in that it includes the following steps:
步骤1,获取用户对景点的评论信息和评分信息、用户属性信息和景点属性信息以及用户好友关注列表;
步骤2,对评论信息进行文本预处理;Step 2, perform text preprocessing on the comment information;
首先利用Jieba分词对旅游景点的在线评论进行分词和词性标注以及停用词删除.分词和词性标注是将以句子形式表示的评论都分解成以若干词语的形式表示,并且在每个词后标注相应的词性;停用词删除是指将出现频率高,但又没有实际意义的词删除,参照中文停用词表中的停用词(保留标点符号)进行删除;Firstly, Jieba word segmentation is used to perform word segmentation and part-of-speech tagging and stop word removal for online reviews of tourist attractions. Word segmentation and part-of-speech tagging are to decompose comments expressed in sentence form into several words, and label each word after Corresponding part of speech; stop word deletion refers to the deletion of words with high frequency but no actual meaning, referring to the stop words in the Chinese stop word list (retaining punctuation marks) to delete;
步骤3,提取评论中的属性-情感词对并对情感词进行量化,构建主题情感向量;包括:Step 3: Extract attribute-sentiment word pairs in the comments and quantify the sentiment words to construct topic sentiment vectors; including:
1)提取评论中的属性词-情感词对:给出属性词和情感词的定义,属性词表示用户评论中用于描述景点某一特性的词,例如“景色”、“价格”;情感词表示用户对属性词的积极或者消极的情绪、态度和情感,例如“满意”、“失望”等;1) Extract attribute word-sentiment word pairs in comments: give definitions of attribute words and sentiment words, attribute words represent words used to describe a certain feature of scenic spots in user reviews, such as "scenery", "price"; sentiment words Indicates the user's positive or negative emotions, attitudes and emotions towards attribute words, such as "satisfaction", "disappointment", etc.;
首先,用户评论中的属性词和情感词往往是成对出现的,所以情感词通常出现在属性词的附近;其次,注意挖掘修饰情感词的副词,它是情感量化的关键,副词是区分正面情感和负面情感的重要依据,也是判断情感程度的重要信息源;在提取过程中加入了情感词的种子词库,采用句法分析器对句子进行依存句法解析,然后根据所需要的依存关系进行过滤;在整个提取过程中主要涉及两种依存关系:一是副词修饰形容词的状中关系,二是形容词修饰名词的定中关系;First, attribute words and sentiment words in user reviews often appear in pairs, so sentiment words usually appear near the attribute words; second, pay attention to the adverbs that modify sentiment words, which are the key to sentiment quantification, and adverbs are used to distinguish positive It is an important basis for emotion and negative emotion, and also an important information source for judging the degree of emotion; in the extraction process, a seed vocabulary of emotion words is added, and a syntactic analyzer is used to analyze the dependency syntax of the sentence, and then filter according to the required dependencies. ; There are mainly two kinds of dependencies involved in the whole extraction process: one is the adverb-modified adjective's central relationship, and the other is the adjective-modified noun's central relationship;
2)量化评论中属性词对应情感词的情感倾向:首先引入一个用户评论中常用副词的词库,并为每一类副词设定一个程度的值,用于描述用户的情感倾向的程度;设定情感词的词性为两个方面,正面倾向和负面倾向,正面倾向的情感词赋值为1,负面倾向的情感词赋值为-1,否定词赋值为一1,对应属性情感倾向量化值为:V=词性值×副词的词性程序百分比×否定词词性值;最终求得用户ui对景点rj的属性wn的情感倾向值Sijn;2) Quantify the sentimental tendency of attribute words in comments corresponding to sentimental words: firstly introduce a thesaurus of common adverbs in user comments, and set a degree value for each type of adverbs to describe the degree of user's emotional tendency; There are two parts of speech to determine the sentiment words, positive tendency and negative tendency, the positive tendency sentiment words are assigned as 1, the negative tendency sentiment words are assigned as -1, the negative words are assigned as one 1, and the corresponding attribute sentiment tendency quantification value is: V = part-of-speech value × part-of-speech program percentage of adverbs × negative part-of-speech value; finally, the emotional tendency value S ijn of user ui to attribute wn of scenic spot r j is obtained;
3)构建用户的主题情感向量:给出主题的概念,不同用户在进行评论时描述旅游景点的同一属性可能使用不同的词,如景致、景观和风景等都表示景色,因此需要对描述旅游景点同一属性的词进行合并;利用LDA主题模型可以将属性词聚集成潜在主题,并量化用户在对应主题下情感倾向分值进而量化用户主题情感词向量;首先将提取出的属性词作为LDA主题模型中的特征词汇,利用LDA算法将相关词汇归属到相应的主题,从而属性词被聚集成K个潜在主题,其中每个主题表现为属性词的概率分布,从而将属性词和主题相关联,然后根据主题-属性词分布得到用户ui对景点rj的主题fk的情感倾向值Vijk,具体计算公式如下:3) Constructing the user's topic emotion vector: Given the concept of topic, different users may use different words to describe the same attribute of tourist attractions when commenting, such as scenery, landscape and scenery, etc. The words of the same attribute are combined; the attribute words can be aggregated into potential topics by using the LDA topic model, and the user's emotional tendency score under the corresponding topic can be quantified to quantify the user's topic sentiment word vector; first, the extracted attribute words are used as the LDA topic model The feature words in , use the LDA algorithm to attribute the related words to the corresponding topics, so that the attribute words are aggregated into K potential topics, each of which is expressed as a probability distribution of the attribute words, so as to associate the attribute words with the topic, and then According to the topic-attribute word distribution, the sentiment tendency value V ijk of the user ui to the topic f k of the scenic spot r j is obtained, and the specific calculation formula is as follows:

其中φkn表示属性词wn属于主题fk的概率;where φ kn represents the probability that the attribute word w n belongs to the topic f k ;
步骤4,结合用户评分和主题情感向量建立用户偏好分布,包括:Step 4, combine user ratings and topic sentiment vectors to establish user preference distribution, including:
为了获得更准确的用户偏好,将用户在评分集合上的平均评分值作为衡量用户对不同景点偏好的标准,同时引入sigmoid函数来计算用户主观评分可信度,用户主观评分可信度的定义为:In order to obtain a more accurate user preference, the average rating value of the user on the rating set is used as the criterion to measure the user's preference for different scenic spots, and the sigmoid function is introduced to calculate the user's subjective rating reliability. The definition of the user's subjective rating reliability is :

其中

用户主观评分可信度的取值范围是从0到1;当用户对景点的评分与用户在景点评分集合上的平均评分值之间的差值越大,说明用户对该景点越喜好/厌恶,景点对应的属性分布越符合/不符合用户的偏好;The value range of the user's subjective rating reliability is from 0 to 1; when the difference between the user's rating on the scenic spot and the user's average rating value on the scenic spot rating set is larger, it indicates that the user likes/dislikes the scenic spot more. , the attribute distribution corresponding to the scenic spot is more in line with/in line with the user's preference;
另一方面,利用用户客观评分可信度来衡量用户评分的可靠性;如果用户对景点的评分接近景点的平均得分,则表示用户相对客观,反之亦然;用户客观评分可信度定义为:On the other hand, the reliability of the user's objective rating is used to measure the reliability of the user's rating; if the user's rating of the scenic spot is close to the average score of the scenic spot, it means that the user is relatively objective, and vice versa; the user's objective rating reliability is defined as:

用户客观评分可信度的取值范围为0到1,用户对景点的评分和景点的平均评分之间的差异越小,说明用户越客观;换言之,用户的客观评分可信度相对较高;The user's objective rating reliability ranges from 0 to 1. The smaller the difference between the user's rating of the scenic spot and the average rating of the scenic spot, the more objective the user is; in other words, the user's objective rating reliability is relatively high;
考虑到用户兴趣偏移的问题,加入时间修正权重来计算用户偏好分布时,使得越靠近当前时间的评分与评论的权重增加,因为其更能反映用户当下的偏好;首先将用户评分和评论的时间跨度通过标准化转换的方法映射到[-1,1]的变化范围,然后将映射后的时间用logistic函数处理后得到用户在不同时间段评分和评论的权重,不同时间段的权值计算公式如下:Considering the problem of user interest offset, when adding time correction weights to calculate user preference distribution, the weights of ratings and comments closer to the current time are increased, because they can better reflect the user's current preferences; The time span is mapped to the variation range of [-1, 1] through the method of standardized transformation, and then the mapped time is processed by the logistic function to obtain the weight of the user's ratings and comments in different time periods, and the calculation formula of the weights of different time periods. as follows:

其中


将用户主题情感向量、用户评分、时间加权因子、用户主观评分可信度、用户客观评分可信度结合起来,得到最终的用户偏好分布,计算公式如下:Combining the user topic sentiment vector, user rating, time weighting factor, user subjective rating credibility, and user objective rating credibility to obtain the final user preference distribution, the calculation formula is as follows:

其中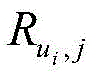


步骤5,计算不同用户之间偏好分布的相似度,包括:Step 5: Calculate the similarity of preference distributions between different users, including:
在获得用户对景点不同特征的偏好分布后,采用JS散度来计算用户之间的相似性;根据JS散度可以得到用户ui和uj之间的用户相似度,计算公式如下:After obtaining the user's preference distribution for different features of scenic spots, JS divergence is used to calculate the similarity between users; according to the JS divergence, the user similarity between users u i and u j can be obtained, and the calculation formula is as follows:

其中,
其中,
步骤6,结合用户关注列表信息建立目标用户的信任关系集合并计算信任度,包括:Step 6, establishing a trust relationship set of the target user in combination with the user attention list information and calculating the trust degree, including:
获取用户关注列表信息,得到全局信任网络包括用户结点的属性与结点之间的信任关系,将全局信任网络中的用户属性以及信任关系信息存储为树结构,获取以目标用户为根结点的子树,即目标用户局部信任网络;以目标结点为A结点为例,根据“六度分割理论”,将距离节点A的最短路径小于6的所有节点视作A的信任节点(包括直接信任和间接信任),从而得到用户A的信任节点集合;Obtain user watchlist information, obtain the global trust network including the attributes of user nodes and the trust relationship between nodes, store the user attributes and trust relationship information in the global trust network as a tree structure, and obtain the target user as the root node. The subtree of the target user, that is, the local trust network of the target user; taking the target node as node A as an example, according to the "six degrees of division theory", all nodes with the shortest path from node A less than 6 are regarded as trust nodes of A (including Direct trust and indirect trust), so as to obtain the set of trust nodes of user A;
计算信任度的方法主要分为两步:The method of calculating the trust degree is mainly divided into two steps:
步骤1:将目标用户设置为起始节点,假设目标用户完全信任自己,设置初始信任度为1;Step 1: Set the target user as the starting node, assume that the target user completely trusts himself, and set the initial trust degree to 1;
步骤2:为目标用户(起始节点)的直接信任用户和间接信任用户分配信任度,计算公式如下:Step 2: Assign the trust degree to the direct trust user and indirect trust user of the target user (starting node), the calculation formula is as follows:
trustcur=trustpre*wi,j trust cur = trust pre *w i,j

当前结点的信任度的值是前一结点的信任度与权重的乘积,其中l表示用户在网络中的层数;The value of the trust degree of the current node is the product of the trust degree and the weight of the previous node, where l represents the number of layers of the user in the network;
步骤7,结合用户相似度和信任度进行推荐,包括:Step 7, combine user similarity and trust to recommend, including:
1)生成邻居集合,采用在当前用户的信任列表中,选择信任度最高的N个用户作为当前用户的邻居,若该用户的信任列表中用户数量不足N,则采用JS散度来计算当前用户ui与其他用户uj的相似度,选择相似度最高的K个用户补充进来,作为该用户的最近邻居;1) Generate a neighbor set, use the current user's trust list, and select the N users with the highest trust degree as the current user's neighbors. If the number of users in the user's trust list is less than N, the JS divergence is used to calculate the current user. The similarity between u i and other users u j , select the K users with the highest similarity as the nearest neighbors of the user;
2)结合相似度和用户信任度来计算推荐的权重,计算公式如下:2) Combine the similarity and user trust to calculate the recommended weight. The calculation formula is as follows:

其中


3)采用协同过滤中的Resnick公式来计算当前用户对目标景点的预测评分值;3) Using the Resnick formula in collaborative filtering to calculate the current user's predicted rating value for the target scenic spot;

其中

进一步地,所述的用户属性信息包括用户ID和用户名;用户评论评分信息包括用户对景点的所有评论与评分信息以及评论和评分的时间信息;景点属性信息包括景点名称和景点ID;用户好友关注信息包括用户关注的所有好友的id和名称;获取数据的方式为利用网络爬虫。Further, the user attribute information includes user ID and user name; user comment rating information includes all comments and rating information of users on scenic spots and time information of comments and ratings; scenic spot attribute information includes scenic spot name and scenic spot ID; user friends The following information includes the ids and names of all friends followed by the user; the way to obtain the data is to use a web crawler.
本发明的有益效果是:The beneficial effects of the present invention are:
1)本发明结合用户评分和用户评论,对评论中的情感信息进行提取与量化,同时引入用户主观评分可信度和客观评分可信度来避免错误评论和恶意随机评论的影响,运用LDA概率模型挖掘出用户潜在的主题情感倾向,构建准确的用户偏好分布。本发明还考虑了用户偏好随时间偏移的问题,将用户评分和评论的时间跨度用logistic函数处理后得到用户在不同时间段评分和评论的权重,时间距当下越近,权重越大。1) The present invention combines user ratings and user reviews to extract and quantify emotional information in reviews, and introduces user subjective rating reliability and objective rating reliability to avoid the influence of erroneous reviews and malicious random reviews, and uses LDA probability. The model digs out the user's potential topic emotional tendency and constructs an accurate user preference distribution. The invention also considers the problem of user preference shifting with time, and processes the time span of user ratings and comments with a logistic function to obtain the weights of user ratings and comments in different time periods. The closer the time is to the present, the greater the weight.
2)通过本发明可有效解决传统协同过滤算法应用时存在的数据稀疏性的问题。即在数据稀疏情况下,一方面,若相似度无法计算,系统就无法对这些用户进行推荐;另一方面,当用户间共同评价的景点数量很少时,计算出的相似度也存在一定的误差。本发明通过获取用户的关注列表,构建目标用户的信任结点集合并计算信任度,通过融合相似度和信任度用来计算推荐权重,提高了推荐的准确性。2) The present invention can effectively solve the problem of data sparsity existing in the application of traditional collaborative filtering algorithms. That is, in the case of sparse data, on the one hand, if the similarity cannot be calculated, the system cannot recommend these users; on the other hand, when the number of scenic spots jointly evaluated by users is small, the calculated similarity also has a certain degree of similarity. error. The invention obtains the user's attention list, constructs the trust node set of the target user, calculates the trust degree, and uses the similarity and the trust degree to calculate the recommendation weight, thereby improving the accuracy of the recommendation.
附图说明Description of drawings
图1为本发明的流程示意图;Fig. 1 is the schematic flow chart of the present invention;
图2为全局信任网络示意图;Figure 2 is a schematic diagram of a global trust network;
图3为以目标节点为根结点的局部信任网络示意图;3 is a schematic diagram of a local trust network with a target node as a root node;
图4为目标用户与其信任用户之间以同心圆的形式展示的网络结构示意图。FIG. 4 is a schematic diagram of a network structure shown in the form of concentric circles between a target user and its trusted users.
具体实施方式Detailed ways
以下结合附图对本发明进一步叙述。The present invention is further described below in conjunction with the accompanying drawings.
如图1至图3所示,如图1至图3所示,包括以下步骤:As shown in Figure 1 to Figure 3, as shown in Figure 1 to Figure 3, including the following steps:
步骤1,获取用户对景点的评论信息和评分信息、用户和景点属性信息以及用户好友关注列表。In
所获取的用户属性信息包括用户ID和用户名;用户评论评分信息包括用户对景点的所有评论与评分信息以及评论和评分的时间信息;景点属性信息包括景点名称和景点ID;用户关注好友信息包括用户关注的所有好友的id和名称;获取数据的方式为利用网络爬虫。The acquired user attribute information includes user ID and user name; user comment rating information includes all user comments and ratings information on scenic spots and time information of comments and ratings; scenic spot attribute information includes scenic spot name and scenic spot ID; user follow friend information includes The ids and names of all friends the user follows; the way to obtain data is to use web crawlers.
步骤2,对评论信息进行文本预处理。Step 2, perform text preprocessing on the comment information.
文本预处理首先利用Jieba分词对旅游景点的在线评论进行分词和词性标注以及停用词删除。分词和词性标注是将以句子形式表示的评论都分解成以若干词语的形式表示,并且在每个词后标注相应的词性。停用词删除是指将出现频率高,但又没有实际意义的词删除,参照中文停用词表中的停用词(保留标点符号)进行删除。The text preprocessing first uses Jieba word segmentation to perform word segmentation and part-of-speech tagging and stop word removal for online reviews of tourist attractions. Word segmentation and part-of-speech tagging is to decompose comments expressed in sentence form into several words, and mark the corresponding part-of-speech after each word. Stop word deletion refers to the deletion of words with high frequency but no actual meaning, referring to the stop words in the Chinese stop word list (retaining punctuation marks) for deletion.
步骤3,提取评论中的属性-情感词对并对情感词进行量化,构建主题情感向量。Step 3: Extract attribute-sentiment word pairs in the comments and quantify the sentiment words to construct topic sentiment vectors.
1)提取评论中的属性词-情感词对:给出属性词和情感词的定义,属性词表示用户评论中用于描述景点某一特性的词,例如“景色”、“价格”等。情感词表示用户对属性词的积极或者消极的情绪、态度和情感,例如“满意”、“失望”等。1) Extract attribute word-sentiment word pairs in comments: give definitions of attribute words and sentiment words, attribute words represent words used to describe a certain feature of scenic spots in user reviews, such as "scenery", "price", etc. Sentiment words represent the user's positive or negative emotions, attitudes and emotions towards attribute words, such as "satisfaction", "disappointment" and so on.
首先,用户评论中的属性词和情感词往往是成对出现的,所以情感词通常出现在属性词的附近;其次,注意挖掘修饰情感词的副词,它是情感量化的关键,副词是区分正面情感和负面情感的重要依据,也是判断情感程度的重要信息源。在提取过程中加入了情感词的种子词库,采用句法分析器对句子进行依存句法解析,然后根据所需要的依存关系进行过滤。在整个提取过程中主要涉及两种依存关系:一是副词修饰形容词的状中关系,二是形容词修饰名词的定中关系。First, attribute words and sentiment words in user reviews often appear in pairs, so sentiment words usually appear near the attribute words; second, pay attention to the adverbs that modify sentiment words, which are the key to sentiment quantification, and adverbs are used to distinguish positive It is an important basis for emotion and negative emotion, and it is also an important information source for judging the degree of emotion. In the extraction process, a seed lexicon of sentiment words is added, and a syntactic analyzer is used to parse the sentence dependencies, and then filter according to the required dependencies. The whole extraction process mainly involves two kinds of dependencies: one is the adverb-modified adjective's central relationship, and the other is the adjective-modified noun's central relationship.
2)量化评论中属性词对应情感词的情感倾向:首先引入一个用户评论中常用副词的词库,并为每一类副词设定一个程度的值,用于描述用户的情感倾向的程度。设定情感词的词性为两个方面,正面倾向和负面倾向,正面倾向的情感词赋值为1,负面倾向的情感词赋值为-1,否定词赋值为-1,对应属性情感倾向量化值为:V=词性值×副词的词性程序百分比×否定词词性值。最终求得用户ui对景点rj的属性wn的情感倾向值Sijn。2) Quantify the sentiment tendency of the attribute words in the comments corresponding to the sentiment words: firstly, a thesaurus of common adverbs in user comments is introduced, and a degree value is set for each type of adverbs to describe the degree of the user's emotional tendency. The part of speech of sentiment words is set as two aspects, positive tendency and negative tendency, the positive tendency sentiment word is assigned as 1, the negative tendency sentiment word is assigned as -1, the negative word is assigned as -1, and the corresponding attribute sentiment tendency is quantified as 1. : V = part-of-speech value × part-of-speech program percentage of adverbs × negative part-of-speech value. Finally, the emotional tendency value S ijn of the user ui to the attribute wn of the scenic spot r j is obtained.
3)构建用户的主题情感向量:给出主题的概念,不同用户在进行评论时描述旅游景点的同一属性可能使用不同的词,如景致、景观和风景等都表示景色,因此需要对描述旅游景点同一属性的词进行合并。利用LDA主题模型可以将属性词聚集成潜在主题,并量化用户在对应主题下情感倾向分值进而量化用户主题情感词向量。首先将提取出的属性词作为LDA主题模型中的特征词汇,利用LDA算法将相关词汇归属到相应的主题,从而属性词被聚集成K个潜在主题,其中每个主题表现为属性词的概率分布,从而将属性词和主题相关联,然后根据主题-属性词分布得到用户ui对景点rj的fk主题的情感倾向值Vijk,具体计算公式如下:3) Constructing the user's topic emotion vector: Given the concept of topic, different users may use different words to describe the same attribute of tourist attractions when commenting, such as scenery, landscape and scenery, etc. Words of the same attribute are merged. Using the LDA topic model, attribute words can be aggregated into potential topics, and the user's sentiment tendency score under the corresponding topic can be quantified to quantify the user's topic sentiment word vector. First, the extracted attribute words are used as the feature words in the LDA topic model, and the related words are attributed to the corresponding topics by using the LDA algorithm, so that the attribute words are aggregated into K potential topics, and each topic is represented by the probability distribution of the attribute words. , so as to associate the attribute word with the topic, and then according to the topic-attribute word distribution, the sentiment tendency value V ijk of the user ui to the f k topic of the scenic spot r j is obtained. The specific calculation formula is as follows:

其中φkn表示属性词wn属于主题fk的概率。where φ kn represents the probability that the attribute word w n belongs to the topic f k .
步骤4,结合用户评分和主题情感向量建立用户偏好分布。Step 4, combining user ratings and topic sentiment vectors to establish user preference distribution.
为了获得更准确的用户偏好,将用户在评分集合上的平均评分值作为衡量用户对不同景点偏好的标准,同时引入sigmoid函数来计算用户主观评分可信度,用户主观评分可信度的定义为:In order to obtain a more accurate user preference, the average rating value of the user on the rating set is used as the criterion to measure the user's preference for different scenic spots, and the sigmoid function is introduced to calculate the user's subjective rating reliability. The definition of the user's subjective rating reliability is :

其中

用户主观评分可信度的取值范围是从0到1。当用户对景点的评分与用户在景点评分集合上的平均评分值之间的差值越大,说明用户对该景点越喜好/厌恶,景点对应的属性分布越符合/不符合用户的偏好。The user's subjective rating reliability ranges from 0 to 1. When the difference between the user's rating on the scenic spot and the user's average rating value on the scenic spot rating set is larger, it indicates that the user likes/dislikes the scenic spot more, and the attribute distribution corresponding to the scenic spot is more in line with/dislike the user's preference.
另一方面,利用用户客观评分可信度来衡量用户评分的可靠性。如果用户对景点的评分接近景点的平均得分,则表示用户相对客观,反之亦然。用户客观评分可信度定义为:On the other hand, the reliability of user ratings is measured by the reliability of user objective ratings. If the user's rating of the attraction is close to the average score of the attraction, it means that the user is relatively objective, and vice versa. User objective rating reliability is defined as:

用户客观评分可信度的取值范围为0到1,用户对景点的评分和景点的平均评分之间的差异越小,说明用户越客观。换言之,用户的客观评分可信度相对较高。The value range of the user's objective rating reliability is 0 to 1. The smaller the difference between the user's rating of the scenic spot and the average rating of the scenic spot, the more objective the user is. In other words, the user's objective rating reliability is relatively high.
考虑到用户兴趣偏移的问题,加入时间修正权重来计算用户偏好分布时,使得越靠近当前时间的评分与评论的权重增加,因为其更能反映用户当下的偏好。首先将用户评分和评论的时间跨度通过标准化转换的方法映射到[-1,1]的变化范围,然后将映射后的时间用logistic函数处理后得到用户在不同时间段评分和评论的权重,不同时间段的权值计算公式如下:Considering the problem of user interest offset, when adding time correction weights to calculate user preference distribution, the weights of ratings and comments closer to the current time are increased, because they can better reflect the user's current preferences. First, the time span of user ratings and comments is mapped to the variation range of [-1, 1] by the method of standardized transformation, and then the mapped time is processed with the logistic function to obtain the weights of user ratings and comments in different time periods. The formula for calculating the weight of the time period is as follows:

其中


将用户主题情感向量、用户评分、时间加权因子、用户主观评分可信度、用户客观评分可信度结合起来,得到最终的用户偏好分布,计算公式如下:Combining the user topic sentiment vector, user rating, time weighting factor, user subjective rating credibility, and user objective rating credibility to obtain the final user preference distribution, the calculation formula is as follows:

其中



步骤5,计算不同用户之间偏好分布的相似度。Step 5: Calculate the similarity of preference distributions among different users.
在获得用户对景点不同特征的偏好分布后,采用JS散度来计算用户之间的相似性。根据JS散度可以得到用户ui和uj之间的用户相似度,计算公式如下:After obtaining the user's preference distribution for different features of scenic spots, JS divergence is used to calculate the similarity between users. According to the JS divergence, the user similarity between users u i and u j can be obtained. The calculation formula is as follows:

其中,
其中,
步骤6,结合用户关注列表信息建立目标用户的信任关系集合并计算信任度。Step 6, establishing a trust relationship set of the target user in combination with the user attention list information and calculating the trust degree.
如果用户A关注了用户B,则用户A和用户B有直接信任关系,如果用户B关注了用户C,则用户B和用户C也有直接信任关系,同时用户A和用户C之间通过用户B产生间接信任关系。所以信任网络中各节点的信任性质上可分为两种:直接信任和间接信任。根据提取的各个用户的关注列表信息,构建初始的信任网络。在信任网络中,为了形式化表示用户之间的信任关系,采用节点代表用户并使用有向边代表一个用户对另一个用户的直接信任关系,则用户的信任网络可记为G(V,E),V表示用户节点的集合,E表示信任关系的集合。若A信任B,则可用A→B表示。两用户互相信任的情况,可以被看做是单向信任的特殊情况,可用双向有向边表示,即
将全局信任网络中的用户属性以及信任关系信息存储为树结构,获取以目标用户为根结点的子树,即目标用户局部信任网络,如图3所示。以目标结点为A结点为例,根据“六度分割理论”,将距离节点A的最短路径小于6的所有节点视作A的信任节点(包括直接信任和间接信任),从而得到用户A的信任节点集合。为了更清晰地表示,将用户A与其信任用户之间的网络结构以同心圆的形式表示,如图4所示,其中第1层为用户A,第2层为用户A的直接信赖的用户,第3层及以外的节点为用户A通过其他用户而间接信任的用户。The user attributes and trust relationship information in the global trust network are stored as a tree structure, and the subtree with the target user as the root node is obtained, that is, the local trust network of the target user, as shown in Figure 3. Taking the target node as node A as an example, according to the "six degrees of division theory", all nodes whose shortest path from node A is less than 6 are regarded as trust nodes of A (including direct trust and indirect trust), so as to obtain user A. set of trusted nodes. For a clearer representation, the network structure between user A and its trusted users is represented in the form of concentric circles, as shown in Figure 4, where the first layer is user A, and the second layer is user A's directly trusted users. Nodes at layer 3 and beyond are users that User A indirectly trusts through other users.
计算信任度的方法主要分为两步:The method of calculating the trust degree is mainly divided into two steps:
步骤1:将目标用户设置为起始节点,假设目标用户完全信任自己,设置初始信任度为1。Step 1: Set the target user as the starting node, assuming that the target user completely trusts himself, and set the initial trust degree to 1.
步骤2:为目标用户(起始节点)的直接信任用户和间接信任用户分配信任度,计算公式如下:Step 2: Assign the trust degree to the direct trust user and indirect trust user of the target user (starting node), the calculation formula is as follows:
trustcur=trustpre*wi,j trust cur = trust pre *w i,j

当前结点的信任度的值是前一结点的信任度与权重的乘积,其中l表示用户在网络中的层数。The value of the trust degree of the current node is the product of the trust degree of the previous node and the weight, where l represents the number of layers of the user in the network.
步骤7,结合用户相似度和信任度进行推荐。Step 7, combine user similarity and trust to recommend.
1)生成邻居集合,采用在当前用户的信任列表中,选择信任度最高的N个用户作为当前用户的邻居,若该用户的信任列表中用户数量不足N,则采用JS散度来计算当前用户ui与其他用户uj的相似度,选择相似度最高的K个用户补充进来,作为该用户的最近邻居。1) Generate a neighbor set, use the current user's trust list, and select the N users with the highest trust degree as the current user's neighbors. If the number of users in the user's trust list is less than N, the JS divergence is used to calculate the current user. The similarity between u i and other users u j is determined by selecting the K users with the highest similarity as the nearest neighbors of the user.
2)结合相似度和用户信任度来计算推荐的权重,计算公式如下:2) Combine the similarity and user trust to calculate the recommended weight. The calculation formula is as follows:
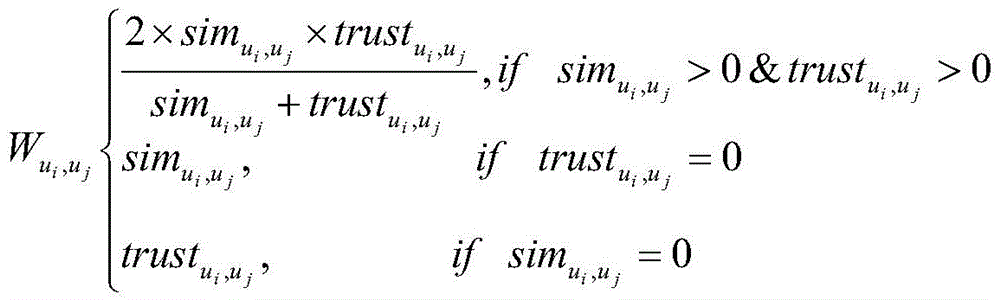
其中


3)采用协同过滤中的Resnick公式来计算当前用户对目标景点的预测评分值。3) Using the Resnick formula in collaborative filtering to calculate the current user's predicted rating value for the target scenic spot.

其中

Claims (2)


























Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010984598.8A CN112507248A (en) | 2020-09-18 | 2020-09-18 | Tourist attraction recommendation method based on user comment data and trust relationship |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010984598.8A CN112507248A (en) | 2020-09-18 | 2020-09-18 | Tourist attraction recommendation method based on user comment data and trust relationship |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112507248A true CN112507248A (en) | 2021-03-16 |
Family
ID=74953472
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010984598.8A Pending CN112507248A (en) | 2020-09-18 | 2020-09-18 | Tourist attraction recommendation method based on user comment data and trust relationship |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112507248A (en) |
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112883282A (en) * | 2021-03-30 | 2021-06-01 | 辽宁工程技术大学 | Group recommendation method based on sparrow search optimization clustering |
| CN113254800A (en) * | 2021-06-03 | 2021-08-13 | 武汉卓尔数字传媒科技有限公司 | Information recommendation method and device, electronic equipment and storage medium |
| CN113298367A (en) * | 2021-05-12 | 2021-08-24 | 北京信息科技大学 | Theme park perception value evaluation method |
| CN113407842A (en) * | 2021-06-28 | 2021-09-17 | 携程旅游信息技术(上海)有限公司 | Model training method, method and system for obtaining theme recommendation reason and electronic equipment |
| CN113792118A (en) * | 2021-09-08 | 2021-12-14 | 浙江力石科技股份有限公司 | Satisfaction improving system and method based on scenic spot evaluation |
| CN113821727A (en) * | 2021-09-24 | 2021-12-21 | 武汉卓尔数字传媒科技有限公司 | Item recommendation method, computer device, and computer-readable storage medium |
| CN114048378A (en) * | 2021-11-10 | 2022-02-15 | 四川泛华航空仪表电器有限公司 | BTM model-based personalized recommendation method |
| CN114429384A (en) * | 2021-12-30 | 2022-05-03 | 杭州盟码科技有限公司 | Intelligent product recommendation method and system based on e-commerce platform |
| CN114931753A (en) * | 2022-03-30 | 2022-08-23 | 网易(杭州)网络有限公司 | Friend recommendation method and device in game |
| CN114997723A (en) * | 2022-06-30 | 2022-09-02 | 辽宁大学 | Construction method of multi-source heterogeneous blockchain quality assessment model for enterprise business activities |
| CN115018584A (en) * | 2022-06-13 | 2022-09-06 | 浙江理工大学 | Recommendation method integrating comment text subject word emotional tendency and user trust relationship |
| CN115187361A (en) * | 2022-06-16 | 2022-10-14 | 平安银行股份有限公司 | Credit card recommendation method, device, electronic device and storage medium |
| CN116628317A (en) * | 2023-04-19 | 2023-08-22 | 上海顺多网络科技有限公司 | Method for analyzing user group preference by using small amount of information |
| CN116662556A (en) * | 2023-08-02 | 2023-08-29 | 天河超级计算淮海分中心 | Text data processing method integrating user attributes |
| CN117333203A (en) * | 2023-12-01 | 2024-01-02 | 广东付惠吧数据服务有限公司 | An affiliate marketing platform combined with business marketing solutions |
| CN119537704A (en) * | 2025-01-22 | 2025-02-28 | 山东科技大学 | A time-aware user portrait modeling method based on sentiment analysis |
| CN120354011A (en) * | 2025-06-26 | 2025-07-22 | 山东征途信息科技股份有限公司 | Behavior analysis and medical service pushing method and system based on big data |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102929931A (en) * | 2012-09-24 | 2013-02-13 | 上海师范大学 | Information credibility assessment method based on body in semantic net |
| CN105049354A (en) * | 2015-08-14 | 2015-11-11 | 电子科技大学 | Trustful routing method based on OSPF |
| CN107330461A (en) * | 2017-06-27 | 2017-11-07 | 安徽师范大学 | Collaborative filtering recommending method based on emotion with trust |
| CN111061962A (en) * | 2019-11-25 | 2020-04-24 | 上海海事大学 | A Recommendation Method Based on User Score Analysis |
-
2020
- 2020-09-18 CN CN202010984598.8A patent/CN112507248A/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102929931A (en) * | 2012-09-24 | 2013-02-13 | 上海师范大学 | Information credibility assessment method based on body in semantic net |
| CN105049354A (en) * | 2015-08-14 | 2015-11-11 | 电子科技大学 | Trustful routing method based on OSPF |
| CN107330461A (en) * | 2017-06-27 | 2017-11-07 | 安徽师范大学 | Collaborative filtering recommending method based on emotion with trust |
| CN111061962A (en) * | 2019-11-25 | 2020-04-24 | 上海海事大学 | A Recommendation Method Based on User Score Analysis |
Non-Patent Citations (2)
| Title |
|---|
| 王春旭: "基于用户评论的公园推荐算法研究", 《中国优秀硕士学位论文全文数据库》 * |
| 赵文涛: "基于Logistic时间函数和用户特征的协同过滤算法", 《计算机应用与软件》 * |
Cited By (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112883282A (en) * | 2021-03-30 | 2021-06-01 | 辽宁工程技术大学 | Group recommendation method based on sparrow search optimization clustering |
| CN112883282B (en) * | 2021-03-30 | 2023-12-22 | 辽宁工程技术大学 | A group recommendation method based on sparrow search optimization clustering |
| CN113298367A (en) * | 2021-05-12 | 2021-08-24 | 北京信息科技大学 | Theme park perception value evaluation method |
| CN113298367B (en) * | 2021-05-12 | 2023-12-12 | 北京信息科技大学 | Theme park perception value evaluation method |
| CN113254800A (en) * | 2021-06-03 | 2021-08-13 | 武汉卓尔数字传媒科技有限公司 | Information recommendation method and device, electronic equipment and storage medium |
| CN113407842A (en) * | 2021-06-28 | 2021-09-17 | 携程旅游信息技术(上海)有限公司 | Model training method, method and system for obtaining theme recommendation reason and electronic equipment |
| CN113407842B (en) * | 2021-06-28 | 2024-03-22 | 携程旅游信息技术(上海)有限公司 | Model training method, theme recommendation reason acquisition method and system and electronic equipment |
| CN113792118A (en) * | 2021-09-08 | 2021-12-14 | 浙江力石科技股份有限公司 | Satisfaction improving system and method based on scenic spot evaluation |
| CN113821727A (en) * | 2021-09-24 | 2021-12-21 | 武汉卓尔数字传媒科技有限公司 | Item recommendation method, computer device, and computer-readable storage medium |
| CN114048378A (en) * | 2021-11-10 | 2022-02-15 | 四川泛华航空仪表电器有限公司 | BTM model-based personalized recommendation method |
| CN114048378B (en) * | 2021-11-10 | 2024-05-14 | 四川泛华航空仪表电器有限公司 | Personalized recommendation method based on BTM model |
| CN114429384B (en) * | 2021-12-30 | 2022-12-09 | 杭州盟码科技有限公司 | Intelligent product recommendation method and system based on e-commerce platform |
| CN114429384A (en) * | 2021-12-30 | 2022-05-03 | 杭州盟码科技有限公司 | Intelligent product recommendation method and system based on e-commerce platform |
| CN114931753A (en) * | 2022-03-30 | 2022-08-23 | 网易(杭州)网络有限公司 | Friend recommendation method and device in game |
| CN115018584A (en) * | 2022-06-13 | 2022-09-06 | 浙江理工大学 | Recommendation method integrating comment text subject word emotional tendency and user trust relationship |
| CN115187361A (en) * | 2022-06-16 | 2022-10-14 | 平安银行股份有限公司 | Credit card recommendation method, device, electronic device and storage medium |
| CN114997723A (en) * | 2022-06-30 | 2022-09-02 | 辽宁大学 | Construction method of multi-source heterogeneous blockchain quality assessment model for enterprise business activities |
| CN116628317A (en) * | 2023-04-19 | 2023-08-22 | 上海顺多网络科技有限公司 | Method for analyzing user group preference by using small amount of information |
| CN116662556A (en) * | 2023-08-02 | 2023-08-29 | 天河超级计算淮海分中心 | Text data processing method integrating user attributes |
| CN116662556B (en) * | 2023-08-02 | 2023-10-20 | 天河超级计算淮海分中心 | Text data processing method integrating user attributes |
| CN117333203A (en) * | 2023-12-01 | 2024-01-02 | 广东付惠吧数据服务有限公司 | An affiliate marketing platform combined with business marketing solutions |
| CN117333203B (en) * | 2023-12-01 | 2024-04-16 | 广东付惠吧数据服务有限公司 | Member marketing platform combined with business marketing solution |
| CN119537704A (en) * | 2025-01-22 | 2025-02-28 | 山东科技大学 | A time-aware user portrait modeling method based on sentiment analysis |
| CN120354011A (en) * | 2025-06-26 | 2025-07-22 | 山东征途信息科技股份有限公司 | Behavior analysis and medical service pushing method and system based on big data |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112507248A (en) | Tourist attraction recommendation method based on user comment data and trust relationship | |
| Dhelim et al. | Personality-aware product recommendation system based on user interests mining and metapath discovery | |
| Sang et al. | Context-dependent propagating-based video recommendation in multimodal heterogeneous information networks | |
| CN108256093B (en) | A Collaborative Filtering Recommendation Algorithm Based on User's Multi-interest and Interest Change | |
| CN110377840B (en) | Music list recommendation method and system based on long-term and short-term preference of user | |
| Tsur et al. | What's in a hashtag? Content based prediction of the spread of ideas in microblogging communities | |
| CN114201682B (en) | Graph neural network recommendation method and system fusing social relations and semantic relations | |
| Lin et al. | Heterogeneous knowledge-based attentive neural networks for short-term music recommendations | |
| CN111061962B (en) | A recommendation method based on user rating analysis | |
| Zhang et al. | Joint Personalized Markov Chains with social network embedding for cold-start recommendation | |
| CN112507246B (en) | Social recommendation method fusing global and local social interest influence | |
| CN112069290B (en) | A Recommendation Method for Academic Papers Based on Graph Local Structure and Text Semantic Similarity | |
| CN110275964A (en) | Recommendation Model Based on Knowledge Graph and Recurrent Neural Network | |
| CN109933664A (en) | A kind of fine granularity mood analysis improved method based on emotion word insertion | |
| CN112861541A (en) | Commodity comment sentiment analysis method based on multi-feature fusion | |
| CN109598586B (en) | Recommendation method based on attention model | |
| Sharma et al. | A multi-criteria review-based hotel recommendation system | |
| Zhou et al. | Domain-constrained advertising keyword generation | |
| CN110069713A (en) | A kind of personalized recommendation method based on user's context perception | |
| CN107818183A (en) | A kind of Party building video pushing method based on three stage combination recommended technologies | |
| CN112464108A (en) | Resource recommendation method for crowdsourcing knowledge sharing community | |
| CN114153965B (en) | A method, system, and terminal for recommending public opinion events that combines content and graphs. | |
| CN111061958A (en) | Information recommendation method and system based on user viewpoint and emotional tendency | |
| Mariani et al. | NLP4NLP+ 5: The deep (r) evolution in speech and language processing | |
| CN113392319A (en) | Academic paper recommendation method based on network representation and auxiliary information embedding |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| WD01 | Invention patent application deemed withdrawn after publication | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Application publication date: 20210316 |