CN111461110A - Small target detection method based on multi-scale image and weighted fusion loss - Google Patents
Small target detection method based on multi-scale image and weighted fusion loss Download PDFInfo
- Publication number
- CN111461110A CN111461110A CN202010134062.7A CN202010134062A CN111461110A CN 111461110 A CN111461110 A CN 111461110A CN 202010134062 A CN202010134062 A CN 202010134062A CN 111461110 A CN111461110 A CN 111461110A
- Authority
- CN
- China
- Prior art keywords
- image
- convolution
- feature
- output
- layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/25—Determination of region of interest [ROI] or a volume of interest [VOI]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/26—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion
- G06V10/267—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion by performing operations on regions, e.g. growing, shrinking or watersheds
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Multimedia (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
本发明属于图像、视频处理领域,涉及一种基于多尺度图像和加权融合损失的小目标检测方法,包括:基于改进Mask RCNN模型对多种不同尺度图像提取多组特征向量,对多组特征向量进行融合,构造特征金字塔;基于特征金字塔生成候选检测框并筛选得到建议检测框;将建议检测框对应回特征金字塔中产生它们的特征图中,在特征图上对齐截取;将对齐后的建议检测框输入分类器层,得到建议检测框的类别置信度和位置偏移量;在测试阶段,根据建议检测框的类别置信度得分大小筛选一定的建议检测框,并做非极大值抑制;在训练阶段,对检测小目标特征层计算出的损失函数进行加权,并与检测大、中目标层的损失函数融合,增强模型对小目标物体的敏感程度。

The invention belongs to the field of image and video processing, and relates to a small target detection method based on multi-scale images and weighted fusion loss. Perform fusion to construct a feature pyramid; generate candidate detection frames based on the feature pyramid and filter to obtain suggested detection frames; map the suggested detection frames back to the feature map to generate them in the feature pyramid, align and intercept on the feature map; detect the aligned suggestions The box is input into the classifier layer, and the category confidence and position offset of the proposed detection box are obtained; in the testing phase, certain suggested detection boxes are screened according to the category confidence score of the proposed detection box, and non-maximum value suppression is performed; In the training stage, the loss function calculated by the feature layer for detecting small targets is weighted and fused with the loss function for detecting large and medium target layers to enhance the sensitivity of the model to small target objects.
Description
技术领域technical field
本发明属于图像、视频处理领域,涉及一种基于多尺度图像和加权融合损失的小目标检测方法。The invention belongs to the field of image and video processing, and relates to a small target detection method based on multi-scale images and weighted fusion loss.
背景技术Background technique
随着机器学习、深度学习的发展,依靠卷积神经网络强大的学习能力,模式识别、计算机视觉领域得到空前的关注与热度。在机器自动化、人工智能广泛普及的时代,摄像头扮演的角色愈发等同于人的眼睛,计算机视觉领域的发展显得尤其重要,并且得到了工业界和学术界的广泛关注。其中,目标检测在计算机视觉领域成果显著,并在不断进步当中。然而,图片、视频中的目标物体,绝大部分以极其微小的形式出现。通常有很多物体在一帧图片中所占像素极低,大部分像素低于49px,检测微小物体的任务显得艰巨而又十分重要。With the development of machine learning and deep learning, relying on the powerful learning ability of convolutional neural networks, the fields of pattern recognition and computer vision have received unprecedented attention and popularity. In the era of widespread machine automation and artificial intelligence, the role of the camera is increasingly equal to that of the human eye. The development of computer vision is particularly important and has received extensive attention from industry and academia. Among them, target detection has achieved remarkable results in the field of computer vision and is constantly improving. However, most of the target objects in pictures and videos appear in extremely tiny forms. Usually there are many objects occupying very low pixels in a frame of pictures, most of the pixels are less than 49px, the task of detecting tiny objects is arduous and very important.
小目标检测的难点在于尺度,以单一尺寸输入网络模型提取特征信息,往往不能照顾到各个尺度大小的目标。虽然现有Mask RCNN模型在目标检测取得了不错的效果,但仍存在输入图像尺度单一、分辨率具有不确定性、上下文信息利用不充分、对小目标物体检测不敏感等问题。The difficulty of small target detection lies in the scale. Inputting the network model with a single size to extract feature information often cannot take care of the targets of various scales. Although the existing Mask RCNN model has achieved good results in object detection, there are still problems such as single input image scale, uncertain resolution, insufficient use of context information, and insensitivity to small object detection.
发明内容SUMMARY OF THE INVENTION
针对现有Mask RCNN模型的不足,本发明提供一种基于多尺度图像和加权融合损失的小目标检测方法。Aiming at the shortcomings of the existing Mask RCNN model, the present invention provides a small target detection method based on multi-scale images and weighted fusion loss.
本发明采用如下技术方案实现:The present invention adopts the following technical scheme to realize:
一种基于多尺度图像和加权融合损失的小目标检测方法,基于改进Mask RCNN模型实现,包括:A small object detection method based on multi-scale images and weighted fusion loss, implemented based on the improved Mask RCNN model, including:
S1、搭建改进的Mask RCNN模型;所述改进的Mask RCNN模型包括:残差骨干网络、特征金字塔网络层、区域生成网络层、感兴趣框对齐层、分类器层、损失函数计算层和测试层;S1. Build an improved Mask RCNN model; the improved Mask RCNN model includes: a residual backbone network, a feature pyramid network layer, a region generation network layer, a frame of interest alignment layer, a classifier layer, a loss function calculation layer and a test layer ;
S2、构建图像金字塔:对原始图像进行缩放处理,将原始图像、缩小尺寸后的图像、放大尺寸后图像一起构成图像金字塔;S2. Constructing an image pyramid: scaling the original image, and combining the original image, the reduced-sized image, and the enlarged-sized image together to form an image pyramid;
S3、将图像金字塔中的图像进行随机裁剪;S3. Randomly crop the images in the image pyramid;
S4、将随机裁剪后的图像送入残差骨干网络进行卷积、批归一化、池化操作,输出多组不同尺寸的特征图;S4. Send the randomly cropped image to the residual backbone network for convolution, batch normalization, and pooling operations, and output multiple sets of feature maps of different sizes;
S5、将多组不同尺度的特征图进行融合,并进一步处理得到特征图P2-P6;S5. Fusion of multiple sets of feature maps of different scales, and further processing to obtain feature maps P2-P6;
S6、对特征图P2-P6分别生成未筛选的候选检测框;S6. Generate unscreened candidate detection frames for the feature maps P2-P6 respectively;
S7、将特征图P2-P6输入区域生成网络层,通过一系列卷积操作,得到候选检测框的偏移量以及置信度;S7. Generate the network layer from the input area of the feature map P2-P6, and obtain the offset and confidence of the candidate detection frame through a series of convolution operations;
S8、把S7的候选检测框的偏移量与S6得到的未筛选的候选检测框数据结合,筛选出设定量的候选检测框作为感兴趣检测框;S8, combine the offset of the candidate detection frame of S7 with the unscreened candidate detection frame data obtained in S6, and screen out the set amount of candidate detection frames as the detection frame of interest;
S9、将感兴趣检测框分别对应回特征图P2-P6,并进行对齐操作;S9. Corresponding the detection frames of interest back to the feature maps P2-P6 respectively, and perform an alignment operation;
S10、将对齐操作的结果输入到分类层,输出预测的感兴趣检测框类别得分、类别概率、坐标偏移量;S10. Input the result of the alignment operation to the classification layer, and output the predicted interest detection frame category score, category probability, and coordinate offset;
S11、将预测的感兴趣检测框类别得分、类别概率、坐标偏移量输入测试层,在测试层对类别概率取最大值进行筛选,选出感兴趣检测框对应的预测目标类别,进一步通过非极大值抑制过滤出多余的感兴趣检测框,最后在测试层得到最终预测的感兴趣检测框和对应的预测目标类别。S11. Input the predicted interest detection frame category score, category probability, and coordinate offset into the test layer, select the maximum value of the category probability in the test layer, select the predicted target category corresponding to the interest detection frame, and further pass the non- The maximum value suppression filters out redundant interest detection frames, and finally obtains the final predicted interest detection frame and the corresponding predicted target category in the test layer.
进一步地,在训练阶段还包括:Further, the training phase also includes:
S12、将S10中预测的感兴趣检测框类别得分输入损失函数计算层,与实际类别标签一起作为交叉熵函数的输入,用来计算分类损失值,得到特征图P2-P6的类别预测损失;S12. Input the category score of the detection frame of interest predicted in S10 into the loss function calculation layer, and use it as the input of the cross-entropy function together with the actual category label to calculate the classification loss value, and obtain the category prediction loss of the feature maps P2-P6;
将S10中预测的感兴趣检测框坐标偏移量与真实目标框偏移量一起作为回归损失函数的输入,得到特征图P2-P6的回归预测损失;The coordinate offset of the detection frame of interest predicted in S10 and the offset of the real target frame are used as the input of the regression loss function, and the regression prediction loss of the feature maps P2-P6 is obtained;
S13、将特征图P2、特征图P3的类别预测损失分别进行加权,并与特征图P4、特征图P5、特征图P6的类别预测损失相加得到总的类别预测损失;S13, weight the category prediction losses of the feature map P2 and the feature map P3 respectively, and add them to the category prediction losses of the feature map P4, the feature map P5, and the feature map P6 to obtain the total category prediction loss;
将特征图P2、特征图P3的回归预测损失分别进行加权,并与特征图P4、特征图P5、特征图P6的回归预测损失相加得到总的回归预测损失;The regression prediction loss of the feature map P2 and the feature map P3 are weighted respectively, and the total regression prediction loss is obtained by adding the regression prediction loss of the feature map P4, the feature map P5, and the feature map P6;
S14、通过反向传播对改进Mask RCNN模型参数、权重进行迭代更新,具体地,总的类别预测损失与总的回归预测损失分别被利用,进行优化迭代、改变改进Mask RCNN模型的权重值。S14. Iteratively update the parameters and weights of the improved Mask RCNN model through backpropagation. Specifically, the total category prediction loss and the total regression prediction loss are respectively used to perform optimization iterations and change the weight value of the improved Mask RCNN model.
进一步地,改进的Mask RCNN模型所作改进包括:Further, the improvements made by the improved Mask RCNN model include:
①、感兴趣检测框对齐不再统一对齐,而是分开对不同特征层进行对齐,对齐过后没有直接融合传入损失函数计算层,而是分别输入分类器层进行分别分类和回归,最终分开输入损失函数计算层,对检测小目标特征层计算出的损失函数进行加权,并与检测大、中目标层的损失函数融合;1. The alignment of the detection frames of interest is no longer unified, but the different feature layers are aligned separately. After alignment, the incoming loss function calculation layer is not directly integrated, but is input to the classifier layer for separate classification and regression, and finally separate input The loss function calculation layer weights the loss function calculated by the feature layer for detecting small targets, and fuses it with the loss function for detecting large and medium target layers;
②、在原有Mask RCNN模型中增加一层有效特征层P6;2. Add a layer of effective feature layer P6 to the original Mask RCNN model;
③、去除原有Mask RCNN中图像分割模块,取消掩膜支路。3. Remove the image segmentation module in the original Mask RCNN and cancel the mask branch.
优选地,S2中对原始图像进行缩放处理包括:Preferably, scaling the original image in S2 includes:
缩放图片的公式表述为:The formula for scaling an image is:
Image_New=Image*scale (1)Image_New=Image*scale (1)
其中:Image_New代表缩放后的图片,Image代表缩放前的图片,scale表示缩放尺度;Among them: Image_New represents the zoomed image, Image represents the image before zooming, and scale represents the zoom scale;
缩放尺度scale由以下因素决定:The scaling scale is determined by the following factors:
设缩放完成后最小边的长度不能小于min_dim,min()表示取最小值运算,h表示原图的高,w表示原图宽,则的当min_dim大于min(h,w)时,After the scaling is completed, the length of the minimum side cannot be less than min_dim, min() means taking the minimum value operation, h means the height of the original image, w means the width of the original image, then when min_dim is greater than min(h, w),
scale=min_dim/min(h,w) (2)scale=min_dim/min(h, w) (2)
否则scale=1;otherwise scale=1;
设缩放完成后最长边的长度为max_dim,如果按照式(2)来进行缩放图片,若缩放后的图片的最长边已经超过了max_dim时,则令:Set the length of the longest side after scaling is max_dim, if the image is scaled according to formula (2), if the longest side of the scaled image has exceeded max_dim, then make:
scale=max_dim/image_max (3)scale=max_dim/image_max (3)
否则继续按scale=min_dim/min(h,w)来进行缩放;Otherwise, continue to scale by scale=min_dim/min(h, w);
最后的缩放完成的图片大小尺寸为max_dim*max_dim,另外,如果最后缩放的尺度scale大于1,即放大原图,则将用双线性插值法进行放大;对于最后缩放后的图片不足max_dim*max_dim的部分,采用零值填充像素值。The size of the final scaled picture is max_dim*max_dim. In addition, if the scale of the final scaled scale is greater than 1, that is, the original picture is enlarged, it will be enlarged by bilinear interpolation; the final scaled picture is less than max_dim*max_dim part, padded pixel values with zero values.
优选地,S3中随机裁剪图片的公式表述如下:Preferably, the formula for randomly cropping pictures in S3 is expressed as follows:
Y1=randi([0,image_size(1)-crop_size(1)]) (4)Y 1 =randi([0,image_size(1)-crop_size(1)]) (4)
X1=randi([0,image_size(2)-crop_size(2)]) (5)X 1 =randi([0,image_size(2)-crop_size(2)]) (5)
其中:Y1和X1分别表示裁剪图片开始的左下角纵坐标和左下角横坐标;randi表示随机取数,取数范围是小括号里面的范围;image_size是裁剪前的图片尺寸,第一维存放图片宽度,第二维存放图片长度;crop_size是需要裁剪出来的区域尺寸,第一维存放区域宽度,第二维存放区域长度;Among them: Y1 and X1 represent the ordinate and abscissa of the lower left corner of the beginning of the cropped image, respectively; randi represents a random number, and the range of the number is the range in the parentheses; image_size is the size of the image before cropping, and the first dimension stores the image width, the second dimension stores the image length; crop_size is the size of the area to be cropped, the first dimension storage area width, and the second dimension storage area length;
Y2=min(image_size(1),Y1+crop_size(1)) (6)Y 2 =min(image_size(1),Y1+crop_size(1)) (6)
X2=min(image_size(2),X1+crop_size(2)) (7)X 2 =min(image_size(2),X1+crop_size(2)) (7)
其中:Y2和X2分别表示裁剪图片开始的右上角纵坐标和右上角横坐标;randi表示随机取数;min()表示取最小值;Among them: Y2 and X2 represent the upper right ordinate and upper right abscissa of the beginning of the cropped image, respectively; randi means random number; min() means the minimum value;
利用式(4)-式(7)求得的两个坐标确定裁剪的具体位置,如果裁剪区域溢出原图,将进行pad填充,得到裁剪后的图像。Use the two coordinates obtained from equations (4) to (7) to determine the specific position of the cropping. If the cropping area overflows the original image, pad filling will be performed to obtain the cropped image.
优选地,残差骨干网络的卷积包括block1、block2两类卷积模块,其中:Preferably, the convolution of the residual backbone network includes two types of convolution modules, block1 and block2, wherein:
卷积模块block1工作流程包括:The convolution module block1 workflow includes:
①、对于分支1,输出与输入保持一致不变;①. For branch 1, the output and input remain the same;
②、对于分支2,依次使用1*1卷积核、3*3卷积核、1*1卷积核进行卷积操作,并在每次卷积完成后对输出的特征向量进行均值归一化;②. For branch 2, use 1*1 convolution kernel, 3*3 convolution kernel, and 1*1 convolution kernel to perform convolution operation in turn, and perform mean normalization on the output feature vector after each convolution is completed. change;
卷积模块block2工作流程包括:The convolution module block2 workflow includes:
①、对于分支1,使用1*1卷积核进行卷积操作,紧接着对输出的特征向量进行均值归一化;1. For branch 1, use a 1*1 convolution kernel to perform the convolution operation, and then perform mean normalization on the output feature vector;
②、对于分支2,依次使用1*1卷积核、3*3卷积核、1*1卷积核进行卷积操作,并在每次卷积完成后对输出的特征向量进行均值归一化。②. For branch 2, use 1*1 convolution kernel, 3*3 convolution kernel, and 1*1 convolution kernel to perform convolution operation in turn, and perform mean normalization on the output feature vector after each convolution is completed. change.
优选地,S4中输出多组不同尺寸的特征图包括:Preferably, outputting multiple sets of feature maps of different sizes in S4 includes:
对于原图输入,构成五层特征图输出:C2、C3、C4、C5、C6;对于相对原图缩小一倍的输入,构成五层特征图输出:C2s、C3s、C4s、C5s、C6s;对于相对原图放大一倍的输入,构成五层特征图输出:C2l、C3l、C4l、C5l、C6l。For the original image input, five layers of feature map output are formed: C2, C3, C4, C5, C6; for input that is doubled from the original image, five layers of feature map output are formed: C2s, C3s, C4s, C5s, C6s; for The input that is doubled relative to the original image constitutes five-layer feature map output: C2l, C3l, C4l, C5l, C6l.
优选地,步骤S5包括:Preferably, step S5 includes:
S51、对C2s-C6s进行基于插值原理的上采样,将C2s-C6s扩大一倍;S51. Perform upsampling based on the interpolation principle on C2s-C6s, and double the C2s-C6s;
S52、将C2l-C6l进行最大值池化,将C2l-C6l缩小一倍;S52, perform maximum pooling on C2l-C6l, and double the size of C2l-C6l;
S53、将C2-C6与扩大一倍后的C2s-C6s和缩小一倍后的C2l-C6l相加,得到融合了不同尺度图像特征的C2-C6;S53, adding C2-C6, doubled C2s-C6s and doubled C2l-C6l to obtain C2-C6 fused with image features of different scales;
S54、对融合了不同尺度图像特征的C2-C6进一步处理得到特征图P2-P6。S54, further processing C2-C6 fused with image features of different scales to obtain feature maps P2-P6.
优选地,S54包括:Preferably, S54 includes:
用256个1*1卷积核对融合了不同尺度图像特征的C6进行卷积得到输出为16*16*256的特征图P6;Use 256 1*1 convolution kernels to convolve C6 that incorporates image features of different scales to obtain a feature map P6 with an output of 16*16*256;
用256个1*1卷积核对融合了不同尺度图像特征的C5进行卷积后与将P6进行上采样两倍后的输出相加,再进行3*3卷积得到输出为32*32*256的特征图P5;Use 256 1*1 convolution kernels to convolve C5 that incorporates image features of different scales and add the output of P6 upsampling twice, and then perform 3*3 convolution to obtain an output of 32*32*256 The feature map P5 of;
用256个1*1卷积核对融合了不同尺度图像特征的C4进行卷积后与将P5进行上采样两倍后的输出相加,再进行3*3卷积得到输出为64*64*256的特征图P4;Use 256 1*1 convolution kernels to convolve C4 that combines image features of different scales and add the output of P5 upsampling twice, and then perform 3*3 convolution to obtain an output of 64*64*256 The feature map P4 of;
用256个1*1卷积核对融合了不同尺度图像特征的C3进行卷积后与将P4进行上采样两倍后的输出相加,再进行3*3卷积得到输出为128*128*256的特征图P3;Use 256 1*1 convolution kernels to convolve C3, which combines image features of different scales, and add the output of P4 upsampling twice, and then perform 3*3 convolution to obtain an output of 128*128*256 The feature map P3 of ;
用256个1*1卷积核对融合了不同尺度图像特征的C2进行卷积后与将P3进行上采样两倍的输出相加,再进行3*3卷积得到输出为256*256*256的特征图P2。Use 256 1*1 convolution kernels to convolve C2, which combines image features of different scales, and add the output of P3 upsampling twice, and then perform 3*3 convolution to obtain an output of 256*256*256 Feature map P2.
优选地,候选检测框的高度h、宽度w为:Preferably, the height h and width w of the candidate detection frame are:


其中:scale_length表示当候选检测框为高度与宽度相等的方框时,高度和宽度对应于原图的像素级大小。Among them: scale_length indicates that when the candidate detection frame is a box with the same height and width, the height and width correspond to the pixel-level size of the original image.
本发明与现有Mask RCNN模型小目标检测相比,具有如下有益效果:Compared with the small target detection of the existing Mask RCNN model, the present invention has the following beneficial effects:
(1)提出构造图像金字塔作为Mask RCNN模型输入的方法,一张图像经过预处理变成多种尺度作为输入而并非单一尺度,增强了对小目标物体特征提取的能力。(1) A method of constructing an image pyramid as the input of the Mask RCNN model is proposed. An image is preprocessed into multiple scales as input instead of a single scale, which enhances the ability to extract features of small objects.
(2)去除原有Mask RCNN模型中图像分割模块,取消了Mask(掩膜)支路,减少了网络参数,使得训练分类和回归部分更加高效。(2) Remove the image segmentation module in the original Mask RCNN model, cancel the Mask (mask) branch, reduce the network parameters, and make the training classification and regression part more efficient.
(3)感兴趣区域对齐不再统一对齐,而是分开对不同特征层进行对齐,进而再输入分类层进行分别分类和回归,最终分开输入损失函数计算层,对检测小目标特征层计算出的损失函数进行加权,并与检测大、中目标层的损失函数融合,增强了小目标物体对模型损失函数的影响,让模型更好地学习到关于检测小目标物体的特征。(3) The alignment of the region of interest is no longer unified, but to align different feature layers separately, and then input the classification layer for separate classification and regression, and finally separate the input loss function calculation layer to detect the small target feature layer. The loss function is weighted and fused with the loss function of detecting large and medium target layers, which enhances the influence of small target objects on the model loss function, and allows the model to better learn the characteristics of detecting small target objects.
(4)在原有Mask RCNN模型中增加一层有效特征层P6,在提高小目标物体检测精度的同时确保对大物体的检测精度不下降,最终达到了提高目标检测中对小目标物体的检测准确性和精度的提升。(4) A layer of effective feature layer P6 is added to the original Mask RCNN model, which improves the detection accuracy of small target objects and ensures that the detection accuracy of large objects does not decrease, and finally achieves the improvement of the detection accuracy of small target objects in target detection. Improved performance and precision.
附图说明Description of drawings
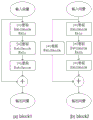
图1为本发明一个实施例中改进的Mask RCNN模型结构图;1 is a structural diagram of an improved Mask RCNN model in an embodiment of the present invention;
图2为本发明一个实施例中改进的Mask RCNN模型中卷积块示意图;2 is a schematic diagram of a convolution block in an improved Mask RCNN model in an embodiment of the present invention;
图3为本发明一个实施例中小目标检测实现流程图。FIG. 3 is a flowchart for realizing small target detection in an embodiment of the present invention.
具体实施方式Detailed ways
下面结合附图和具体实施例对本发明作进一步说明。The present invention will be further described below with reference to the accompanying drawings and specific embodiments.
一种基于多尺度图像和加权融合损失的小目标检测方法,基于改进Mask RCNN模型实现,包括:A small object detection method based on multi-scale images and weighted fusion loss, implemented based on the improved Mask RCNN model, including:
S1、搭建改进的Mask RCNN模型。S1. Build an improved Mask RCNN model.
在一个优选的实施例中,改进的Mask RCNN模型包括骨干网络部分、候选窗口生成部分和分类层部分,利用keras平台搭建,包括:残差骨干网络、特征金字塔网络层、区域建议层、感兴趣框对齐层、分类器层、损失函数计算层、测试层。相对于原有Mask RCNN所作改进包括:In a preferred embodiment, the improved Mask RCNN model includes a backbone network part, a candidate window generation part and a classification layer part, built using the keras platform, including: a residual backbone network, a feature pyramid network layer, a region proposal layer, an interesting Box alignment layer, classifier layer, loss function calculation layer, test layer. Compared with the original Mask RCNN, the improvements include:
①、感兴趣区域对齐不再统一对齐,而是分开对不同特征层进行对齐,对齐过后没有直接融合传入损失函数,而是分别输入分类器层进行分别分类和回归,最终分开输入损失函数计算层,对检测小目标特征层计算出的损失函数进行加权,并与检测大、中目标层的损失函数融合,增强了小目标物体对模型损失函数的影响,让模型更好地学习到关于检测小目标物体的特征。①. The alignment of the region of interest is no longer unified, but to align different feature layers separately. After alignment, the incoming loss function is not directly integrated, but is input to the classifier layer for separate classification and regression, and finally the input loss function is calculated separately. layer, weights the loss function calculated by the feature layer for detecting small targets, and integrates it with the loss function for detecting large and medium target layers, enhancing the influence of small target objects on the loss function of the model, allowing the model to better learn about detection. Characteristics of small target objects.
②、在原有Mask RCNN模型中增加一层有效特征层P6,在提高小目标物体检测精度的同时确保对大物体的检测精度不下降,最终达到提高目标检测中对小目标物体的检测准确性和精度的提升。2. Add a layer of effective feature layer P6 to the original Mask RCNN model to improve the detection accuracy of small target objects while ensuring that the detection accuracy of large objects does not decrease, and ultimately improve the detection accuracy of small target objects in target detection. Accuracy improvements.
③、去除原有Mask RCNN中图像分割模块,取消了Mask(掩膜)支路,从而减少网络参数,使得训练分类和回归部分更加高效。3. Remove the image segmentation module in the original Mask RCNN and cancel the Mask (mask) branch, thereby reducing the network parameters and making the training classification and regression parts more efficient.
S2、构建图像金字塔。S2. Build an image pyramid.
将原始图像数据分别进行缩小图像尺寸一倍和放大一倍处理,并保留原始尺寸图像数据,原图、缩小图像、放大图像一起构成图像金字塔。The original image data is reduced by one time and enlarged by one time, and the original image data is retained. The original image, the reduced image, and the enlarged image together form an image pyramid.
改变图片尺寸的第一步要进行图片的缩放,缩放图片的公式表述为:The first step to change the image size is to zoom the image. The formula for zooming the image is expressed as:
Image_New=Image*scale (1)Image_New=Image*scale (1)
其中:Image_New代表缩放后的图片,Image代表缩放前的图片,scale表示缩放尺度。缩放尺度scale由以下因素决定:Among them: Image_New represents the zoomed image, Image represents the image before zooming, and scale represents the zoom scale. The scaling scale is determined by the following factors:
设缩放完成后最小边的长度不能小于min_dim,min()表示取最小值运算,h表示原图的高,w表示原图宽,则的当min_dim大于min(h,w)时,After the scaling is completed, the length of the minimum side cannot be less than min_dim, min() means taking the minimum value operation, h means the height of the original image, w means the width of the original image, then when min_dim is greater than min(h, w),
scale=min_dim/min(h,w) (2)scale=min_dim/min(h, w) (2)
否则scale=1。Otherwise scale=1.
设缩放完成后最长边的长度为max_dim,如果按照式(2)来进行缩放图片,若缩放后的图片的最长边已经超过了max_dim时,则令:Set the length of the longest side after scaling is max_dim, if the image is scaled according to formula (2), if the longest side of the scaled image has exceeded max_dim, then make:
scale=max_dim/image_max (3)scale=max_dim/image_max (3)
否则继续按scale=min_dim/min(h,w)来进行缩放。Otherwise, continue to scale according to scale=min_dim/min(h, w).
最后的缩放完成的图片大小尺寸为max_dim*max_dim,另外,如果最后缩放的尺度scale大于1,即放大原图,则将用双线性插值法进行放大。对于最后缩放后的图片不足max_dim*max_dim的部分,采用零值填充像素值。The size of the final scaled image is max_dim*max_dim. In addition, if the scale of the final scaled scale is greater than 1, that is, the original image is enlarged, it will be enlarged by bilinear interpolation. For the part of the final scaled image that is less than max_dim*max_dim, the pixel value is filled with zero value.
S3、将图像金字塔中的原图、缩小图像、放大图像进行512*512的随机裁剪,作为一次训练输入。S3. Perform random cropping of 512*512 on the original image, the reduced image, and the enlarged image in the image pyramid as a training input.
随机裁剪图片的公式表述如下:The formula for randomly cropping a picture is as follows:
Y1=randi([0,image_size(1)-crop_size(1)]) (4)Y 1 =randi([0,image_size(1)-crop_size(1)]) (4)
X1=randi([0,image_size(2)-crop_size(2)]) (5)X 1 =randi([0,image_size(2)-crop_size(2)]) (5)
其中:Y1和X1分别表示裁剪图片开始的左下角纵坐标和左下角横坐标;randi表示随机取数,取数范围是小括号里面的范围;image_size是裁剪前的图片尺寸,第一维存放图片宽度,第二维存放图片长度;crop_size是需要裁剪出来的区域尺寸,第一维存放区域宽度,第二维存放区域长度。Among them: Y1 and X1 represent the ordinate and abscissa of the lower left corner of the beginning of the cropped image, respectively; randi represents a random number, and the range of the number is the range in the parentheses; image_size is the size of the image before cropping, and the first dimension stores the image Width, the second dimension stores the image length; crop_size is the size of the area to be cropped, the first dimension stores the width of the area, and the second dimension stores the length of the area.
Y2=min(image_size(1),Y1+crop_size(1)) (6)Y 2 =min(image_size(1),Y1+crop_size(1)) (6)
X2=min(image_size(2),X1+crop_size(2)) (7)X 2 =min(image_size(2),X1+crop_size(2)) (7)
其中:Y2和X2分别表示裁剪图片开始的右上角纵坐标和右上角横坐标;randi表示随机取数,取数范围是小括号里面的范围,min()表示取最小值,小括号里面是比较的两个数。Among them: Y2 and X2 represent the upper right ordinate and upper right abscissa of the beginning of the cropped image, respectively; randi means random number, the range of the number is the range in the parentheses, min() means the minimum value, and the parentheses are the comparison the two numbers.
利用上述求得的两个坐标确定裁剪的具体位置,如果裁剪区域溢出原图,将进行pad填充,得到裁剪后的图像。pad填充将对溢出区域进行像素三通道的零填充,即为每个通道赋值0。Use the two coordinates obtained above to determine the specific position of the cropping. If the cropping area overflows the original image, pad filling will be performed to obtain the cropped image. Pad padding will zero-pad the overflow area with three channels of pixels, that is, assign 0 to each channel.
S4、将裁剪后的图像进行送入残差骨干网络进行卷积、批归一化、池化操作,输出三组不同尺寸的特征图。S4. Send the cropped image to the residual backbone network for convolution, batch normalization, and pooling operations, and output three sets of feature maps of different sizes.
在一个优选的实施例中,残差骨干网络一共进行60次卷积,以及开始的一次最大值池化和末尾的平均值池化,每次卷积过后进行一次批归一化。利用特定的卷积模块,按照卷积后特征图的大小关系,对于原图输入,构成五层特征图输出:C2、C3、C4、C5、C6;对于相对原图缩小一倍的输入,构成五层特征图输出:C2s、C3s、C4s、C5s、C6s;对于相对原图放大一倍的输入,构成五层特征图输出:C2l、C3l、C4l、C5l、C6l。In a preferred embodiment, the residual backbone network performs a total of 60 convolutions, as well as a maximum pooling at the beginning and an average pooling at the end, and a batch normalization is performed after each convolution. Using a specific convolution module, according to the size relationship of the feature map after convolution, for the original image input, five layers of feature map output are formed: C2, C3, C4, C5, C6; for the input that is doubled compared to the original image, the composition Five-layer feature map output: C2s, C3s, C4s, C5s, C6s; for the input that is doubled relative to the original image, five-layer feature map output is formed: C2l, C3l, C4l, C5l, C6l.
卷积公式表述如下:The convolution formula is expressed as follows:

其中,Output是卷积输出的特征图中每个点的值,wi,j是n*n大小卷积核在(i,j)位置的权重;Inputi',j'是输入卷积核的图在与卷积核位置(i,j)对应位置的像素值。Among them, Output is the value of each point in the feature map of the convolution output, w i, j is the weight of the n*n size convolution kernel at the (i, j) position; Input i', j' is the input convolution kernel The pixel value of the map at the position corresponding to the convolution kernel position (i, j).
对于最大值池化操作,选用3*3大小的核、以2大小的步长在输入图中滑动,选出滑动的3*3局部接收域内的最大值作为输出图对应点的值,公式表述为:For the maximum pooling operation, a kernel of size 3*3 is selected, and the input graph is slid with a step size of 2, and the maximum value in the sliding 3*3 local receptive field is selected as the value of the corresponding point of the output graph. The formula expresses for:
Outputmax=max(Areainput) (9)Output max = max(Area input ) (9)
其中:Areainput表示局部接收域中所有像素点的值。Where: Area input represents the value of all pixels in the local receptive field.
对于平均值池化操作,则是对输入特征图所有像素点的值进行求和后再平均,最终得到1*1的输出,不改变通道数。公式表述如下:For the average pooling operation, the values of all pixels in the input feature map are summed and then averaged, and finally a 1*1 output is obtained without changing the number of channels. The formula is expressed as follows:

其中:Inputi,j是输入图在像素点(i,j)的像素值,n*n指输入特征图的尺寸。Among them: Input i, j is the pixel value of the input image at the pixel point (i, j), and n*n refers to the size of the input feature map.
批归一化是指对深度神经网络每一隐藏层输出的卷积图的每个点的值分布变换为以0为均值,单位方差的正态分布数值时,可以加速网络收敛。对于一批输入,假设有n个样本,在某隐藏层I的输出为:{z(1),z(2),z(3),z(4),...,z(n)},对这批输出进行求均值:Batch normalization refers to transforming the value distribution of each point of the convolution graph output by each hidden layer of the deep neural network into a normal distribution value with 0 as the mean and unit variance, which can speed up the network convergence. For a batch of inputs, assuming there are n samples, the output in a hidden layer I is: {z (1) ,z (2) ,z (3) ,z (4) ,...,z (n) } , and average the batch of outputs:

求方差:Find the variance:

对输出均一化(批归一化)即对每个送进样本的输出进行如下操作:The output normalization (batch normalization) is to perform the following operations on the output of each input sample:

其中:∈是为了防止方差为0时产生无效计算而设置。Among them: ∈ is set to prevent invalid calculation when the variance is 0.
将I层输出进行批归一化为均值为0、方差为1的分布后,改变了原有数据的信息表达,使得底层网络学习到的参数信息丧失,导致数据表达能力缺失。基于此不足,本发明引入两个可学习的参数γ和β,从而对上述得到的批归一化输出进行如下操作:After batch normalizing the output of the I layer to a distribution with a mean of 0 and a variance of 1, the information expression of the original data is changed, so that the parameter information learned by the underlying network is lost, resulting in a lack of data expression ability. Based on this deficiency, the present invention introduces two learnable parameters γ and β, so as to perform the following operations on the batch normalized output obtained above:

以此恢复数据本身表达能力。This restores the expressiveness of the data itself.
在一个优选的实施例中,改进的Mask RCNN模型的激活函数统一用Sigmoid函数,其数学表达式为:In a preferred embodiment, the activation function of the improved Mask RCNN model uses the Sigmoid function uniformly, and its mathematical expression is:

S5、将S4中得到的三组不同尺度的特征图C2s-C6s、C2-C6、C2l-C6l进行融合,并再进一步得到特征图P2-P6。具体操作方式如下:S5, fuse the three sets of feature maps C2s-C6s, C2-C6, C2l-C6l obtained in S4 with different scales, and further obtain feature maps P2-P6. The specific operation method is as follows:
②、对C2s-C6s进行基于插值原理的上采样,将C2s-C6s扩大一倍;2. Upsampling C2s-C6s based on the interpolation principle to double C2s-C6s;
②、将C2l-C6l进行最大值池化,将C2l-C6l缩小一倍;2. Perform maximum pooling on C2l-C6l and double the size of C2l-C6l;
最大值池化的原理如下:选用3*3大小的核、以2大小的步长在输入图中滑动,选出滑动的3*3区域内的最大值作为输出图对应点的值,公式表述为:The principle of maximum pooling is as follows: select a 3*3 kernel, slide in the input graph with a step size of 2, and select the maximum value in the sliding 3*3 area as the value of the corresponding point in the output graph. The formula expresses for:
Outputmax=max(Areainput) (16)Output max = max(Area input ) (16)
其中:Areainput表示局部接收域中所有像素点的值。Where: Area input represents the value of all pixels in the local receptive field.
③、将C2-C6与扩大一倍后的C2s-C6s和缩小一倍后的C2l-C6l相加,得到融合了不同尺度图像特征的C2-C6。③. Add C2-C6 to the doubled C2s-C6s and the doubled C2l-C6l to obtain the C2-C6 fused with image features of different scales.
此时的C2-C6已与S4中的C2-C6时有所不同,此时的C2-C6融合了不同尺度图像提取出的特征。At this time, C2-C6 is different from C2-C6 in S4. At this time, C2-C6 combines the features extracted from images of different scales.
④、对融合了不同尺度图像特征的C2-C6进一步处理得到特征图P2-P6。④. Further processing the C2-C6 fused with image features of different scales to obtain feature maps P2-P6.
具体地:用256个1*1卷积核对融合了不同尺度图像特征的C6进行卷积得到输出为16*16*256的特征图P6。Specifically: 256 1*1 convolution kernels are used to convolve C6 that incorporates image features of different scales to obtain a feature map P6 with an output of 16*16*256.
用256个1*1卷积核对融合了不同尺度图像特征的C5进行卷积后与将P6进行上采样两倍后的输出相加,再进行3*3卷积得到输出为32*32*256的特征图P5。Use 256 1*1 convolution kernels to convolve C5 that incorporates image features of different scales and add the output of P6 upsampling twice, and then perform 3*3 convolution to obtain an output of 32*32*256 The feature map of P5.
用256个1*1卷积核对融合了不同尺度图像特征的C4进行卷积后与将P5进行上采样两倍后的输出相加,再进行3*3卷积得到输出为64*64*256的特征图P4。Use 256 1*1 convolution kernels to convolve C4 that combines image features of different scales and add the output of P5 upsampling twice, and then perform 3*3 convolution to obtain an output of 64*64*256 The feature map of P4.
用256个1*1卷积核对融合了不同尺度图像特征的C3进行卷积后与将P4进行上采样两倍后的输出相加,再进行3*3卷积得到输出为128*128*256的特征图P3。Use 256 1*1 convolution kernels to convolve C3, which combines image features of different scales, and add the output of P4 upsampling twice, and then perform 3*3 convolution to obtain an output of 128*128*256 The feature map of P3.
用256个1*1卷积核对融合了不同尺度图像特征的C2进行卷积后与将P3进行上采样两倍的输出相加,再进行3*3卷积得到输出为256*256*256的特征图P2。Use 256 1*1 convolution kernels to convolve C2, which combines image features of different scales, and add the output of P3 upsampling twice, and then perform 3*3 convolution to obtain an output of 256*256*256 Feature map P2.
上述得到的P2-P6一起合并构成特征图矩阵。The P2-P6 obtained above are combined together to form a feature map matrix.
S6、在S5得到的特征图P2-P6上生成未筛选的候选检测框。S6. Generate unscreened candidate detection frames on the feature maps P2-P6 obtained in S5.
候选检测框的高度h、宽度w为:The height h and width w of the candidate detection frame are:


其中:scale_length表示当候选检测框为高度与宽度相等的方框时,高度和宽度对应于原图的像素级大小。对于P2到P6,分别是32、64、128、256、512。ratios表示每种尺寸候选检测框的三种尺度:0.5、1、2。Among them: scale_length indicates that when the candidate detection frame is a box with the same height and width, the height and width correspond to the pixel-level size of the original image. For P2 to P6, 32, 64, 128, 256, 512, respectively. ratios represents the three scales of each size candidate detection box: 0.5, 1, 2.
对特征图P2-P6以像素点为中心,生成不同大小、不同尺度的候选检测框,特征图上的每个像素点都会生成候选检测框。候选检测框中心坐标为每层特征图的每个像素点。The feature maps P2-P6 are centered on the pixel points to generate candidate detection frames of different sizes and scales, and each pixel point on the feature map will generate a candidate detection frame. The coordinates of the center of the candidate detection frame are each pixel of the feature map of each layer.
S7、将S5得到的特征图P2-P6输入RPN(Region Proposal Network,区域生成网络层),用相同的卷积层对特征图P2-P6进行卷积,但不改变特征图大小。紧接着对卷积完后的特征图用1*1的卷积核进行卷积后得到rpn_score,再进行softmax操作,则输出通道数为(2*每个像素点候选检测框数量)的候选检测框置信度rpn_pro,在此基础上通过1*1卷积核再进行卷积,输出通道数为(4*每个像素点未筛选的候选检测框数量)的候选检测框偏移量信息rpn_bbox。S7. Input the feature maps P2-P6 obtained in S5 into RPN (Region Proposal Network, region generation network layer), and use the same convolution layer to convolve the feature maps P2-P6, but do not change the size of the feature map. Immediately after the convolution, the feature map is convolved with a 1*1 convolution kernel to obtain rpn_score, and then the softmax operation is performed, and the number of output channels is (2* the number of candidate detection frames per pixel) candidate detection The frame confidence rpn_pro, on this basis, is convolved through a 1*1 convolution kernel, and the output channel number is (4* the number of candidate detection frames that are not screened for each pixel) candidate detection frame offset information rpn_bbox.
S8、把S7的rpn_bbox与S6得到的未筛选的候选检测框数据结合,生成最后的感兴趣检测框(又称ROI框或建议检测框)rpn box(完整的、经过筛选后的侯选检测框),并由S7得到的rpn_score得到感兴趣检测框得分,按照感兴趣检测框得分从大到小排列、作非极大值抑制,最终保留前面1500个感兴趣检测框(rpn box)。S8. Combine the rpn_bbox of S7 with the unscreened candidate detection frame data obtained in S6 to generate the final interesting detection frame (also known as ROI frame or suggested detection frame) rpn box (complete, filtered candidate detection frame) ), and obtain the score of the detection frame of interest from the rpn_score obtained by S7, arrange the scores of the detection frame of interest from large to small, do non-maximum suppression, and finally retain the first 1500 detection boxes of interest (rpn boxes).
S9、对于S8中的得到的1500个感兴趣检测框,分别对应回P2到P6特征图进行对齐操作。S9. For the 1500 detection frames of interest obtained in S8, perform an alignment operation corresponding to the feature maps from P2 to P6 respectively.
对于P5特征层,其检测目标大小平均值是224*224,在对齐时相对于原图,P5层的感受野为32,因此应对齐到(224/32=7)*(224/32=7)即7*7的大小。P2到P6层的感受野成2倍关系递增,以此类推,P2、P3、P4和P6也将对齐到7*7大小。对齐完成后输出分别为:align_p2、align_p3、align_p4、align_p5、align_p6。For the P5 feature layer, the average size of the detection target is 224*224. When aligning, the receptive field of the P5 layer is 32 compared to the original image, so it should be aligned to (224/32=7)*(224/32=7 ) is the size of 7*7. The receptive fields of layers P2 to P6 increase in a 2-fold relationship, and so on, P2, P3, P4, and P6 will also be aligned to a size of 7*7. After the alignment is completed, the outputs are: align_p2, align_p3, align_p4, align_p5, and align_p6.
S10、将S9中对齐完成后输出align_p2、align_p3、align_p4、align_p5、align_p6输入到分类层,将align_p2、align_p3、align_p4、align_p5、align_p6用卷积操作转换成向量,输出预测感兴趣检测框的类别得分、类别概率、坐标偏移量。S10. After the alignment in S9 is completed, output align_p2, align_p3, align_p4, align_p5, and align_p6 and input them to the classification layer, convert align_p2, align_p3, align_p4, align_p5, and align_p6 into vectors by convolution operation, and output the category score that predicts the detection frame of interest , class probability, coordinate offset.
具体地,用7*7的卷积把向量(x,256,7,7)转化成(x,256,1,1)的数据,再用全连接把向量(x,256,1,1)转化成(x,81),输出为类别得分,其中81代表的是ROI框81个类别;对向量(x,81)进行softmax操作,输出为类别概率;再用全连接操作,把(x,256,1,1)转化成(x,81*4),其中4代表的是ROI框81个类别的4个坐标偏移量。注意,上面“x”表示每一层特征图感兴趣检测框的数量,在不同层,“x”的值大小可能不同。Specifically, use 7*7 convolution to convert the vector (x, 256, 7, 7) into (x, 256, 1, 1) data, and then use full connection to convert the vector (x, 256, 1, 1) Converted to (x, 81), the output is the category score, of which 81 represents the 81 categories of the ROI box; the softmax operation is performed on the vector (x, 81), and the output is the category probability; then the full connection operation is used to put (x, 256, 1, 1) into (x, 81*4), where 4 represents the 4 coordinate offsets of the 81 categories of the ROI box. Note that "x" above represents the number of interesting detection frames in each layer of feature maps. In different layers, the value of "x" may be different.
S11、在测试阶段,到S10后,将类别得分、类别概率、坐标偏移量输入测试层,其中在测试层将对类别概率取最大值进行筛选,选出感兴趣检测框对应预测的目标类别,又进一步用0.7大小的阈值进行非极大值抑制过滤出多余的感兴趣检测框。最后在测试层会得出最终的预测的感兴趣检测框和对应的预测目标类别。S11. In the testing stage, after reaching S10, input the category score, category probability, and coordinate offset into the test layer, wherein the maximum value of the category probability is screened in the test layer, and the target category corresponding to the prediction of the interesting detection frame is selected. , and further use a threshold of 0.7 for non-maximum suppression to filter out redundant detection frames of interest. Finally, the final predicted interest detection frame and the corresponding predicted target category will be obtained in the test layer.
在训练阶段,还包括:During the training phase, it also includes:
对检测小目标特征层计算出的损失函数进行加权,并与检测大、中目标层的损失函数融合,增强小目标物体对模型损失函数的影响,让改进的Mask RCNN模型更好地学习到关于检测小目标物体的特征。The loss function calculated by the feature layer for detecting small targets is weighted and fused with the loss function for detecting large and medium target layers to enhance the influence of small target objects on the loss function of the model, so that the improved Mask RCNN model can better learn about Detect features of small target objects.
具体地,包括:Specifically, including:
S12、将S10中每层特征图P2-P6中每一个感兴趣检测框输出的81个类别得分,输入损失函数计算层,与实际类别标签一起作为交叉熵函数的输入,用来计算分类损失值,得到类别预测损失。其中交叉熵函数表示为:S12. Input the 81 category scores output by each interest detection frame in the feature maps P2-P6 of each layer in S10 into the loss function calculation layer, and use the actual category labels as the input of the cross entropy function to calculate the classification loss value , get the class prediction loss. where the cross entropy function is expressed as:

其中:y'i为真实类别标签中第i个值,c表示类别标签的总数,yi为预测类别经过softmax归一化后向量中对应的值,分类越准确,yi越接近1,损失函数值Lossy′(y)越小。Among them: y' i is the ith value in the true category label, c indicates the total number of category labels, y i is the corresponding value in the vector after the softmax normalization of the predicted category, the more accurate the classification, the closer yi i is to 1, the loss The function value Loss y' (y) is smaller.
对S10中每层特征图每一个感兴趣检测框输出的81类别的4个坐标偏移量,与真实目标框偏移量一起作为回归损失函数smooth_l1的输入,得到回归预测损失。其函数表示为:The 4 coordinate offsets of 81 categories output by each interesting detection frame of each layer feature map in S10 are used as the input of the regression loss function smooth_l1 together with the real target frame offset to obtain the regression prediction loss. Its function is expressed as:

其中:x表示预测感兴趣检测框偏移坐标与真实目标框偏移坐标的差值。Among them: x represents the difference between the offset coordinates of the predicted detection frame of interest and the offset coordinates of the real target frame.
S13、将S12中输出P2、P3层的类别预测损失Loss_class_P2、Loss_class_P3分别进行加权,并与Loss_class_P4、Loss_class_P5、Loss_class_P6相加得到总的类别预测损失:S13. Weight the class prediction losses Loss_class_P2 and Loss_class_P3 of the output P2 and P3 layers in S12 respectively, and add them to Loss_class_P4, Loss_class_P5, and Loss_class_P6 to obtain the total class prediction loss:
Loss_class_P2'=4*Loss_class_P2Loss_class_P2'=4*Loss_class_P2
Loss_class_P3'=2*Loss_class_P3Loss_class_P3'=2*Loss_class_P3
Loss_class=Loss_class_P2'+Loss_class_P3'+Loss_class_P4+Loss_class_P5+Loss_class_P6Loss_class=Loss_class_P2'+Loss_class_P3'+Loss_class_P4+Loss_class_P5+Loss_class_P6
(21) (twenty one)
将S12中输出P2、P3层的回归预测损失Loss_reg_P2、Loss_reg_P3分别进行加权,并与Loss_reg_P4、Loss_reg_P5、Loss_reg_P6相加得到回归预测损失:The regression prediction losses Loss_reg_P2 and Loss_reg_P3 of the output P2 and P3 layers in S12 are weighted respectively, and added to Loss_reg_P4, Loss_reg_P5, and Loss_reg_P6 to obtain the regression prediction loss:
Loss_reg_P2'=4*Loss_reg_P2Loss_reg_P2'=4*Loss_reg_P2
Loss_reg_P3'=2*Loss_reg_P3Loss_reg_P3'=2*Loss_reg_P3
Loss_reg=Loss_reg_P2'+Loss_reg_P3'+Loss_reg_P4+Loss_reg_P5+Loss_reg_P6Loss_reg=Loss_reg_P2'+Loss_reg_P3'+Loss_reg_P4+Loss_reg_P5+Loss_reg_P6
(22) (twenty two)
最终Loss_class与Loss_reg分别被利用,进行优化迭代、修改改进的MaskRCNN模型的权重值,达到改进的Mask RCNN模型的学习目的。In the end, Loss_class and Loss_reg are used respectively to perform optimization iteration, modify the weight value of the improved MaskRCNN model, and achieve the learning purpose of the improved MaskRCNN model.
下面结合附图对本发明作进一步详细地说明。The present invention will be described in further detail below with reference to the accompanying drawings.
参见图1-3,一种基于多尺度图像和加权融合损失的小目标检测方法,包括:See Figure 1-3, a small object detection method based on multi-scale images and weighted fusion loss, including:
(1)、基于改进的Mask RCNN模型的残差骨干网络对原图、放大一倍和缩小一倍的图像进行特征提取,得到三组不同尺度的特征,对三组不同尺度的特征进行特征融合,得到融合了不同尺度特征的输出向量图C2、C3、C4、C5和C6。(1) The residual backbone network based on the improved Mask RCNN model performs feature extraction on the original image, doubled and doubled images, and obtains three sets of features of different scales, and performs feature fusion on the three sets of features of different scales , to obtain output vector graphs C2, C3, C4, C5 and C6 that incorporate features of different scales.
在一个优选的实施例中,主要利用不同的卷积模块提取不同尺度图片的特征。特征提取层(残差骨干网络)中的卷积模块如图2所示,共有两种,分别以“block1”和“block2”简称。In a preferred embodiment, different convolution modules are mainly used to extract features of pictures of different scales. The convolution modules in the feature extraction layer (residual backbone network) are shown in Figure 2, and there are two types, referred to as "block1" and "block2" for short.
卷积模块block1工作流程包括:The convolution module block1 workflow includes:
①、对于分支1,输出与输入保持一致不变。①. For branch 1, the output and input remain the same.
②、对于分支2,依次使用1*1卷积核、3*3卷积核、1*1卷积核进行卷积操作,并在每次卷积完成后对输出的特征向量进行均值归一化。具体来看,每一次卷积操作完成后的特征向量通道数目成1:1:4的比例关系。②. For branch 2, use 1*1 convolution kernel, 3*3 convolution kernel, and 1*1 convolution kernel to perform convolution operation in turn, and perform mean normalization on the output feature vector after each convolution is completed. change. Specifically, the number of feature vector channels after each convolution operation is completed is in a ratio of 1:1:4.
卷积模块block2工作流程包括:The convolution module block2 workflow includes:
①、对于分支1,使用1*1卷积核进行卷积操作,紧接着对输出的特征向量进行均值归一化。①. For branch 1, use a 1*1 convolution kernel to perform the convolution operation, and then perform mean normalization on the output feature vector.
②、对于分支2,依次使用1*1卷积核、3*3卷积核、1*1卷积核进行卷积操作,并在每次卷积完成后对输出的特征向量进行均值归一化。具体来看,每一次卷积操作完成后的特征向量通道数目成1:1:4的比例关系。②. For branch 2, use 1*1 convolution kernel, 3*3 convolution kernel, and 1*1 convolution kernel to perform convolution operation in turn, and perform mean normalization on the output feature vector after each convolution is completed. change. Specifically, the number of feature vector channels after each convolution operation is completed is in a ratio of 1:1:4.
在一个具体的实施例中,假设图片以x*x*3输入,注意到对于原图,将图片尺寸统一为1024*1024的标准尺寸,即x=1024,缩小一倍后x=512,放大一倍后x=2048。为简便,下面将省略描述每次卷积操作后都必将进行的均值归一化操作,并且卷积及池化中若填充参数为0、步数参数为1也将省略描述。In a specific embodiment, assuming that the picture is input as x*x*3, it is noted that for the original picture, the size of the picture is unified to the standard size of 1024*1024, that is, x=1024, and x=512 after doubling, and zooming in x=2048 after doubling. For simplicity, the description of the mean normalization operation that must be performed after each convolution operation will be omitted below, and if the padding parameter is 0 and the step parameter is 1 in the convolution and pooling, the description will also be omitted.
在残差骨干网络开始前对图片进行预处理,具体地:将输入的三种不同尺度的图片用7*7*64的卷积核,填充为3,步数为2进行卷积,输出

在C2层中,依次包含一个block2、一个block1、一个bock1、一个block2,输出为




(2)接下来是特征金字塔网络层,本发明对上一步骤中五层特征向量输出进行1*1卷积改变通道数为256后,采用第n层与第(n+1)层进行相加融合输出的特征向量作为Pn特征层输出,对于最高层P6,则直接输出。另外,此处可为增加更多候选检测框,对P6进行步数为2的最大值池化,得到P7特征向量输出,为节省训练空间,本实施例未采取该做法。(2) Next is the feature pyramid network layer. The present invention performs 1*1 convolution on the output of the five-layer feature vector in the previous step to change the number of channels to 256, and uses the nth layer and the (n+1)th layer to perform phase comparison. The feature vector of the fusion output is output as the Pn feature layer, and for the highest layer P6, it is directly output. In addition, more candidate detection frames can be added here, and the maximum value pooling with a step number of 2 is performed on P6 to obtain the output of the P7 feature vector. In order to save training space, this method is not adopted in this embodiment.
(3)通过在P2到P6特征图上生成候选检测框,对每一特征图以每一像素点为中心,生成三种比例、三种长宽比的候选检测框,根据P2到P6特征图大小的比例关系,将候选检测框的长度、宽度、中心坐标统一缩放到0到1区间。(3) By generating candidate detection frames on the feature maps from P2 to P6, and taking each pixel as the center for each feature map, generate candidate detection frames with three scales and three aspect ratios. According to the feature maps from P2 to P6 The proportional relationship of the size, the length, width, and center coordinates of the candidate detection frame are uniformly scaled to the range of 0 to 1.
(4)紧跟着在RPN层,通过一系列卷积操作,生成候选检测框的偏移量以及置信度,与候选检测框相结合,通过对置信度进行从高到低排列,以及非极大值抑制算法筛选出1500个最终的建议检测框。(4) Followed by the RPN layer, through a series of convolution operations, the offset and confidence of the candidate detection frame are generated, combined with the candidate detection frame, by arranging the confidence from high to low, and non-polar The large value suppression algorithm filters out 1500 final proposed detection boxes.
(5)接下来对1500个建议检测框,分别对应回原来的P2、P3、P4、P5、P6特征图进行对齐操作,即根据建议检测框尺寸大小,找回它所属特征层,然后在对应特征图上使用非线性插值算法截取对应建议检测框。每个特征图所包含的建议检测框对齐后的输出都为7*7*256。(5) Next, align the 1500 recommended detection frames corresponding to the original P2, P3, P4, P5, and P6 feature maps, that is, according to the size of the recommended detection frame, retrieve the feature layer to which it belongs, and then use the corresponding On the feature map, a nonlinear interpolation algorithm is used to intercept the corresponding suggested detection frame. The aligned output of the proposed detection boxes contained in each feature map is 7*7*256.
(6)将建议检测框对齐层的输出再输入到分类器层中。分类器层采用7*7的卷积输入的7*7特征向量转换为1*1的特征向量但通道数不变,再分别使用全连接,转换为81个类的类别得分输出和每一类的四个坐标位置偏移量;对81个类得分输出向量进行softmax操作,输出为类别概率。(6) The output of the proposed detection frame alignment layer is then input into the classifier layer. The classifier layer uses the 7*7 feature vector of the 7*7 convolution input to convert the 7*7 feature vector to 1*1 feature vector but the number of channels is unchanged, and then uses the full connection respectively to convert it into the category score output of 81 classes and each class. The four coordinate position offsets of ; the softmax operation is performed on the 81 class score output vectors, and the output is the class probability.
(7)测试阶段,利用分类器层得到的类别得分信息以及位置偏移信息输入测试层,其中在测试层将对类别概率取最大值进行筛选,选出感兴趣检测框对应预测的目标类别,又进一步用0.7大小的阈值进行非极大值抑制过滤出多余的感兴趣检测框。最后在测试层会得出最终的预测的检测框和对应的预测目标类别。(7) In the test phase, the category score information and position offset information obtained by the classifier layer are used to input the test layer, wherein the maximum value of the category probability is screened in the test layer, and the target category corresponding to the prediction of the interesting detection frame is selected, Further non-maximum suppression is performed with a threshold of 0.7 to filter out redundant detection frames of interest. Finally, the final predicted detection frame and the corresponding predicted target category are obtained in the test layer.
训练阶段,在损失函数计算层,利用分类器层得到的类别得分信息以及位置偏移信息,计算与真实信息的损失大小,再通过反向传播对模型参数、权重进行修改。In the training phase, in the loss function calculation layer, the class score information and position offset information obtained by the classifier layer are used to calculate the loss size of the real information, and then the model parameters and weights are modified through back propagation.
具体应用上:For specific applications:
步骤一、得到一张包含大量小目标物体的图片,修改成标准尺寸,分别进行上采样一倍和下采样一倍,与原图组成图像金字塔作为改进Mask RCNN模型的输入。Step 1: Obtain a picture containing a large number of small target objects, modify it to a standard size, double upsampling and double downsampling, and form an image pyramid with the original image as the input to the improved Mask RCNN model.
步骤二、将图像金字塔输入改进Mask RCNN模型的残差骨干网络中,对图像金字塔中三种不同尺度图像进行特征的提取,输出三组特征向量。Step 2: Input the image pyramid into the residual backbone network of the improved Mask RCNN model, extract features from images of three different scales in the image pyramid, and output three sets of feature vectors.
步骤三、通过特征金字塔网络层对三组特征向量进行融合,构造特征金字塔。Step 3: Integrate three sets of feature vectors through the feature pyramid network layer to construct a feature pyramid.
步骤四、在特征金字塔的每一层生成候选检测框,送入RPN层。Step 4: Generate candidate detection frames at each layer of the feature pyramid and send them to the RPN layer.
步骤五、在RPN层,相应为每个候选检测框生成置信度和位置偏移信息,并且根据置信度高低排序以及非极大值抑制,筛选出一定量有效的建议检测框。Step 5: At the RPN layer, correspondingly generate confidence and position offset information for each candidate detection frame, and screen out a certain number of effective suggested detection frames according to the confidence level and non-maximum suppression.
步骤六、对于筛选出的建议检测框,对应回特征金字塔中产生它们的特征图中,在特征图上对齐截取出来,并且统一调整为固定大小,但还是按特征层不同分开放置。Step 6. For the screened suggested detection frames, corresponding to the feature maps that generated them in the feature pyramid, aligned and cut out on the feature maps, and uniformly adjusted to a fixed size, but they are still placed separately according to different feature layers.
步骤七、最后将对齐后的建议检测框输入进去分类器层,得到建议检测框的各个类别置信度和位置偏移量信息。根据类别概率最大值确定建议检测框的类别;然后认为建议检测框的偏移量是其中类别最大值对应的偏移量,对建议检测框的位置进行调整;去除各个建议检测框中属于背景的对象,然后根据各个建议检测框的最大类别的置信度得分大小,取0.7的阈值,然后筛选出来一定的ROI(Region of interest,感兴趣区域),并做非极大值抑制。Step 7: Finally, input the aligned suggested detection frame into the classifier layer, and obtain each category confidence and position offset information of the suggested detection frame. Determine the category of the suggested detection frame according to the maximum value of the category probability; then consider that the offset of the suggested detection frame is the offset corresponding to the maximum value of the category, and adjust the position of the suggested detection frame; remove the background of each suggested detection frame. Then, according to the confidence score of the largest category of each proposed detection frame, take a threshold of 0.7, and then filter out a certain ROI (Region of interest, region of interest), and do non-maximum suppression.
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。The above-mentioned embodiments are preferred embodiments of the present invention, but the embodiments of the present invention are not limited by the above-mentioned embodiments, and any other changes, modifications, substitutions, combinations, The simplification should be equivalent replacement manners, which are all included in the protection scope of the present invention.
Claims (10)


Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010134062.7A CN111461110B (en) | 2020-03-02 | 2020-03-02 | Small target detection method based on multi-scale image and weighted fusion loss |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010134062.7A CN111461110B (en) | 2020-03-02 | 2020-03-02 | Small target detection method based on multi-scale image and weighted fusion loss |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111461110A true CN111461110A (en) | 2020-07-28 |
| CN111461110B CN111461110B (en) | 2023-04-28 |
Family
ID=71682457
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010134062.7A Expired - Fee Related CN111461110B (en) | 2020-03-02 | 2020-03-02 | Small target detection method based on multi-scale image and weighted fusion loss |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111461110B (en) |
Cited By (63)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112016467A (en) * | 2020-08-28 | 2020-12-01 | 展讯通信(上海)有限公司 | Traffic sign recognition model training method, recognition method, system, device and medium |
| CN112052787A (en) * | 2020-09-03 | 2020-12-08 | 腾讯科技(深圳)有限公司 | Target detection method and device based on artificial intelligence and electronic equipment |
| CN112132206A (en) * | 2020-09-18 | 2020-12-25 | 青岛商汤科技有限公司 | Image recognition method and related model training method and related devices and equipment |
| CN112215179A (en) * | 2020-10-19 | 2021-01-12 | 平安国际智慧城市科技股份有限公司 | In-vehicle face recognition method, device, apparatus and storage medium |
| CN112257809A (en) * | 2020-11-02 | 2021-01-22 | 浙江大华技术股份有限公司 | Target detection network optimization method and device, storage medium and electronic equipment |
| CN112307976A (en) * | 2020-10-30 | 2021-02-02 | 北京百度网讯科技有限公司 | Target detection method, target detection device, electronic equipment and storage medium |
| CN112381030A (en) * | 2020-11-24 | 2021-02-19 | 东方红卫星移动通信有限公司 | Satellite optical remote sensing image target detection method based on feature fusion |
| CN112419310A (en) * | 2020-12-08 | 2021-02-26 | 中国电子科技集团公司第二十研究所 | Target detection method based on intersection and fusion frame optimization |
| CN112418108A (en) * | 2020-11-25 | 2021-02-26 | 西北工业大学深圳研究院 | A multi-class target detection method in remote sensing images based on sample reweighting |
| CN112508863A (en) * | 2020-11-20 | 2021-03-16 | 华南理工大学 | Target detection method based on RGB image and MSR image dual channels |
| CN112613544A (en) * | 2020-12-16 | 2021-04-06 | 北京迈格威科技有限公司 | Target detection method, device, electronic equipment and computer readable medium |
| CN112634313A (en) * | 2021-01-08 | 2021-04-09 | 云从科技集团股份有限公司 | Target occlusion assessment method, system, medium and device |
| CN112841154A (en) * | 2020-12-29 | 2021-05-28 | 长沙湘丰智能装备股份有限公司 | Disease and pest control system based on artificial intelligence |
| CN112950703A (en) * | 2021-03-11 | 2021-06-11 | 江苏禹空间科技有限公司 | Small target detection method and device, storage medium and equipment |
| CN112949520A (en) * | 2021-03-10 | 2021-06-11 | 华东师范大学 | Aerial photography vehicle detection method and detection system based on multi-scale small samples |
| CN113160141A (en) * | 2021-03-24 | 2021-07-23 | 华南理工大学 | Steel sheet surface defect detecting system |
| CN113326734A (en) * | 2021-04-28 | 2021-08-31 | 南京大学 | Rotary target detection method based on YOLOv5 |
| CN113408429A (en) * | 2021-06-22 | 2021-09-17 | 深圳市华汉伟业科技有限公司 | Target detection method and system with rotation adaptability |
| CN113469100A (en) * | 2021-07-13 | 2021-10-01 | 北京航科威视光电信息技术有限公司 | Method, device, equipment and medium for detecting target under complex background |
| CN113538331A (en) * | 2021-05-13 | 2021-10-22 | 中国地质大学(武汉) | Metal surface damage target detection and identification method, device, equipment and storage medium |
| CN113628250A (en) * | 2021-08-27 | 2021-11-09 | 北京澎思科技有限公司 | Target tracking method and device, electronic equipment and readable storage medium |
| CN113657174A (en) * | 2021-07-21 | 2021-11-16 | 北京中科慧眼科技有限公司 | Vehicle pseudo-3D information detection method and device and automatic driving system |
| CN113657214A (en) * | 2021-07-30 | 2021-11-16 | 哈尔滨工业大学 | Mask RCNN-based building damage assessment method |
| CN113705387A (en) * | 2021-08-13 | 2021-11-26 | 国网江苏省电力有限公司电力科学研究院 | Method for detecting and tracking interferent for removing foreign matters on overhead line by laser |
| CN113743521A (en) * | 2021-09-10 | 2021-12-03 | 中国科学院软件研究所 | Target detection method based on multi-scale context sensing |
| CN113870254A (en) * | 2021-11-30 | 2021-12-31 | 中国科学院自动化研究所 | Target object detection method, device, electronic device and storage medium |
| CN113963274A (en) * | 2021-12-22 | 2022-01-21 | 中国人民解放军96901部队 | Satellite image target intelligent identification system and method based on improved SSD algorithm |
| CN114037648A (en) * | 2021-02-04 | 2022-02-11 | 广州睿享网络科技有限公司 | Intelligent rate parameter control method based on similar Softmax function information entropy |
| CN114067110A (en) * | 2021-07-13 | 2022-02-18 | 广东国地规划科技股份有限公司 | Method for generating instance segmentation network model |
| CN114067228A (en) * | 2021-10-26 | 2022-02-18 | 神思电子技术股份有限公司 | Target detection method and system for enhancing foreground and background discrimination |
| CN114202649A (en) * | 2021-12-15 | 2022-03-18 | 南京理工大学 | Target positioning method and system based on multi-scale attention constraint |
| US11403069B2 (en) | 2017-07-24 | 2022-08-02 | Tesla, Inc. | Accelerated mathematical engine |
| US11409692B2 (en) | 2017-07-24 | 2022-08-09 | Tesla, Inc. | Vector computational unit |
| CN114898092A (en) * | 2022-04-15 | 2022-08-12 | 南京理工大学 | A Method for Simultaneous Detection and Segmentation of Spatial Objects |
| US11487288B2 (en) | 2017-03-23 | 2022-11-01 | Tesla, Inc. | Data synthesis for autonomous control systems |
| WO2022227770A1 (en) * | 2021-04-28 | 2022-11-03 | 北京百度网讯科技有限公司 | Method for training target object detection model, target object detection method, and device |
| CN115330724A (en) * | 2022-08-15 | 2022-11-11 | 浙江理工大学 | Fabric image flaw detection method based on OCRA-YOLOv5 |
| US11537811B2 (en) | 2018-12-04 | 2022-12-27 | Tesla, Inc. | Enhanced object detection for autonomous vehicles based on field view |
| US11562231B2 (en) | 2018-09-03 | 2023-01-24 | Tesla, Inc. | Neural networks for embedded devices |
| US11561791B2 (en) | 2018-02-01 | 2023-01-24 | Tesla, Inc. | Vector computational unit receiving data elements in parallel from a last row of a computational array |
| US11567514B2 (en) | 2019-02-11 | 2023-01-31 | Tesla, Inc. | Autonomous and user controlled vehicle summon to a target |
| US11610117B2 (en) | 2018-12-27 | 2023-03-21 | Tesla, Inc. | System and method for adapting a neural network model on a hardware platform |
| US11636333B2 (en) | 2018-07-26 | 2023-04-25 | Tesla, Inc. | Optimizing neural network structures for embedded systems |
| US11665108B2 (en) | 2018-10-25 | 2023-05-30 | Tesla, Inc. | QoS manager for system on a chip communications |
| JP2023527615A (en) * | 2021-04-28 | 2023-06-30 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | Target object detection model training method, target object detection method, device, electronic device, storage medium and computer program |
| CN116524338A (en) * | 2023-05-06 | 2023-08-01 | 杭州意能电力技术有限公司 | Improved method and system for detecting dangerous behaviors of large-size small targets of YOLOX |
| CN116580725A (en) * | 2023-05-08 | 2023-08-11 | 科大讯飞股份有限公司 | A voice endpoint detection method, device, equipment and storage medium |
| US11734562B2 (en) | 2018-06-20 | 2023-08-22 | Tesla, Inc. | Data pipeline and deep learning system for autonomous driving |
| CN116645523A (en) * | 2023-07-24 | 2023-08-25 | 济南大学 | A Fast Target Detection Method Based on Improved RetinaNet |
| US11748620B2 (en) | 2019-02-01 | 2023-09-05 | Tesla, Inc. | Generating ground truth for machine learning from time series elements |
| US11790664B2 (en) | 2019-02-19 | 2023-10-17 | Tesla, Inc. | Estimating object properties using visual image data |
| US11816585B2 (en) | 2018-12-03 | 2023-11-14 | Tesla, Inc. | Machine learning models operating at different frequencies for autonomous vehicles |
| US11841434B2 (en) | 2018-07-20 | 2023-12-12 | Tesla, Inc. | Annotation cross-labeling for autonomous control systems |
| US11893774B2 (en) | 2018-10-11 | 2024-02-06 | Tesla, Inc. | Systems and methods for training machine models with augmented data |
| US11893393B2 (en) | 2017-07-24 | 2024-02-06 | Tesla, Inc. | Computational array microprocessor system with hardware arbiter managing memory requests |
| US12014553B2 (en) | 2019-02-01 | 2024-06-18 | Tesla, Inc. | Predicting three-dimensional features for autonomous driving |
| CN118628724A (en) * | 2024-08-14 | 2024-09-10 | 绍兴文理学院 | A method and system for extracting image interest regions based on weak label data |
| US12216610B2 (en) | 2017-07-24 | 2025-02-04 | Tesla, Inc. | Computational array microprocessor system using non-consecutive data formatting |
| US12307350B2 (en) | 2018-01-04 | 2025-05-20 | Tesla, Inc. | Systems and methods for hardware-based pooling |
| US12462575B2 (en) | 2021-08-19 | 2025-11-04 | Tesla, Inc. | Vision-based machine learning model for autonomous driving with adjustable virtual camera |
| CN120912875A (en) * | 2025-10-11 | 2025-11-07 | 合肥智能语音创新发展有限公司 | Small object detection method, small object detection device, electronic device, storage medium and program product |
| US12522243B2 (en) | 2021-08-19 | 2026-01-13 | Tesla, Inc. | Vision-based system training with simulated content |
| US12591240B2 (en) | 2021-10-22 | 2026-03-31 | Tesla, Inc. | Multi-channel sensor simulation for autonomous control systems |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170124415A1 (en) * | 2015-11-04 | 2017-05-04 | Nec Laboratories America, Inc. | Subcategory-aware convolutional neural networks for object detection |
| CN110348445A (en) * | 2019-06-06 | 2019-10-18 | 华中科技大学 | A kind of example dividing method merging empty convolution sum marginal information |
| CN110738642A (en) * | 2019-10-08 | 2020-01-31 | 福建船政交通职业学院 | Mask R-CNN-based reinforced concrete crack identification and measurement method and storage medium |
-
2020
- 2020-03-02 CN CN202010134062.7A patent/CN111461110B/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170124415A1 (en) * | 2015-11-04 | 2017-05-04 | Nec Laboratories America, Inc. | Subcategory-aware convolutional neural networks for object detection |
| CN110348445A (en) * | 2019-06-06 | 2019-10-18 | 华中科技大学 | A kind of example dividing method merging empty convolution sum marginal information |
| CN110738642A (en) * | 2019-10-08 | 2020-01-31 | 福建船政交通职业学院 | Mask R-CNN-based reinforced concrete crack identification and measurement method and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| JIAXIANG LUO ET AL.: "A Fast Circle Detection Method Based on a Tri-Class Thresholding for High Detail FPC Images", 《IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT》 * |
Cited By (99)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11487288B2 (en) | 2017-03-23 | 2022-11-01 | Tesla, Inc. | Data synthesis for autonomous control systems |
| US12020476B2 (en) | 2017-03-23 | 2024-06-25 | Tesla, Inc. | Data synthesis for autonomous control systems |
| US12536131B2 (en) | 2017-07-24 | 2026-01-27 | Tesla, Inc. | Vector computational unit |
| US12086097B2 (en) | 2017-07-24 | 2024-09-10 | Tesla, Inc. | Vector computational unit |
| US11403069B2 (en) | 2017-07-24 | 2022-08-02 | Tesla, Inc. | Accelerated mathematical engine |
| US12554467B2 (en) | 2017-07-24 | 2026-02-17 | Tesla, Inc. | Accelerated mathematical engine |
| US11409692B2 (en) | 2017-07-24 | 2022-08-09 | Tesla, Inc. | Vector computational unit |
| US12216610B2 (en) | 2017-07-24 | 2025-02-04 | Tesla, Inc. | Computational array microprocessor system using non-consecutive data formatting |
| US11893393B2 (en) | 2017-07-24 | 2024-02-06 | Tesla, Inc. | Computational array microprocessor system with hardware arbiter managing memory requests |
| US12307350B2 (en) | 2018-01-04 | 2025-05-20 | Tesla, Inc. | Systems and methods for hardware-based pooling |
| US12455739B2 (en) | 2018-02-01 | 2025-10-28 | Tesla, Inc. | Instruction set architecture for a vector computational unit |
| US11797304B2 (en) | 2018-02-01 | 2023-10-24 | Tesla, Inc. | Instruction set architecture for a vector computational unit |
| US11561791B2 (en) | 2018-02-01 | 2023-01-24 | Tesla, Inc. | Vector computational unit receiving data elements in parallel from a last row of a computational array |
| US11734562B2 (en) | 2018-06-20 | 2023-08-22 | Tesla, Inc. | Data pipeline and deep learning system for autonomous driving |
| US11841434B2 (en) | 2018-07-20 | 2023-12-12 | Tesla, Inc. | Annotation cross-labeling for autonomous control systems |
| US12079723B2 (en) | 2018-07-26 | 2024-09-03 | Tesla, Inc. | Optimizing neural network structures for embedded systems |
| US11636333B2 (en) | 2018-07-26 | 2023-04-25 | Tesla, Inc. | Optimizing neural network structures for embedded systems |
| US11562231B2 (en) | 2018-09-03 | 2023-01-24 | Tesla, Inc. | Neural networks for embedded devices |
| US12346816B2 (en) | 2018-09-03 | 2025-07-01 | Tesla, Inc. | Neural networks for embedded devices |
| US11983630B2 (en) | 2018-09-03 | 2024-05-14 | Tesla, Inc. | Neural networks for embedded devices |
| US11893774B2 (en) | 2018-10-11 | 2024-02-06 | Tesla, Inc. | Systems and methods for training machine models with augmented data |
| US11665108B2 (en) | 2018-10-25 | 2023-05-30 | Tesla, Inc. | QoS manager for system on a chip communications |
| US12367405B2 (en) | 2018-12-03 | 2025-07-22 | Tesla, Inc. | Machine learning models operating at different frequencies for autonomous vehicles |
| US11816585B2 (en) | 2018-12-03 | 2023-11-14 | Tesla, Inc. | Machine learning models operating at different frequencies for autonomous vehicles |
| US11908171B2 (en) | 2018-12-04 | 2024-02-20 | Tesla, Inc. | Enhanced object detection for autonomous vehicles based on field view |
| US12198396B2 (en) | 2018-12-04 | 2025-01-14 | Tesla, Inc. | Enhanced object detection for autonomous vehicles based on field view |
| US11537811B2 (en) | 2018-12-04 | 2022-12-27 | Tesla, Inc. | Enhanced object detection for autonomous vehicles based on field view |
| US12136030B2 (en) | 2018-12-27 | 2024-11-05 | Tesla, Inc. | System and method for adapting a neural network model on a hardware platform |
| US11610117B2 (en) | 2018-12-27 | 2023-03-21 | Tesla, Inc. | System and method for adapting a neural network model on a hardware platform |
| US12014553B2 (en) | 2019-02-01 | 2024-06-18 | Tesla, Inc. | Predicting three-dimensional features for autonomous driving |
| US12223428B2 (en) | 2019-02-01 | 2025-02-11 | Tesla, Inc. | Generating ground truth for machine learning from time series elements |
| US11748620B2 (en) | 2019-02-01 | 2023-09-05 | Tesla, Inc. | Generating ground truth for machine learning from time series elements |
| US12164310B2 (en) | 2019-02-11 | 2024-12-10 | Tesla, Inc. | Autonomous and user controlled vehicle summon to a target |
| US11567514B2 (en) | 2019-02-11 | 2023-01-31 | Tesla, Inc. | Autonomous and user controlled vehicle summon to a target |
| US12236689B2 (en) | 2019-02-19 | 2025-02-25 | Tesla, Inc. | Estimating object properties using visual image data |
| US11790664B2 (en) | 2019-02-19 | 2023-10-17 | Tesla, Inc. | Estimating object properties using visual image data |
| CN112016467B (en) * | 2020-08-28 | 2022-09-20 | 展讯通信(上海)有限公司 | Traffic sign recognition model training method, recognition method, system, device and medium |
| CN112016467A (en) * | 2020-08-28 | 2020-12-01 | 展讯通信(上海)有限公司 | Traffic sign recognition model training method, recognition method, system, device and medium |
| CN112052787A (en) * | 2020-09-03 | 2020-12-08 | 腾讯科技(深圳)有限公司 | Target detection method and device based on artificial intelligence and electronic equipment |
| CN112132206A (en) * | 2020-09-18 | 2020-12-25 | 青岛商汤科技有限公司 | Image recognition method and related model training method and related devices and equipment |
| CN112215179B (en) * | 2020-10-19 | 2024-04-19 | 平安国际智慧城市科技股份有限公司 | In-vehicle face recognition method, device, apparatus and storage medium |
| CN112215179A (en) * | 2020-10-19 | 2021-01-12 | 平安国际智慧城市科技股份有限公司 | In-vehicle face recognition method, device, apparatus and storage medium |
| CN112307976B (en) * | 2020-10-30 | 2024-05-10 | 北京百度网讯科技有限公司 | Target detection method, target detection device, electronic equipment and storage medium |
| CN112307976A (en) * | 2020-10-30 | 2021-02-02 | 北京百度网讯科技有限公司 | Target detection method, target detection device, electronic equipment and storage medium |
| CN112257809A (en) * | 2020-11-02 | 2021-01-22 | 浙江大华技术股份有限公司 | Target detection network optimization method and device, storage medium and electronic equipment |
| CN112508863B (en) * | 2020-11-20 | 2023-07-18 | 华南理工大学 | A dual-channel target detection method based on RGB images and MSR images |
| CN112508863A (en) * | 2020-11-20 | 2021-03-16 | 华南理工大学 | Target detection method based on RGB image and MSR image dual channels |
| CN112381030B (en) * | 2020-11-24 | 2023-06-20 | 东方红卫星移动通信有限公司 | A Method of Target Detection in Satellite Optical Remote Sensing Images Based on Feature Fusion |
| CN112381030A (en) * | 2020-11-24 | 2021-02-19 | 东方红卫星移动通信有限公司 | Satellite optical remote sensing image target detection method based on feature fusion |
| CN112418108A (en) * | 2020-11-25 | 2021-02-26 | 西北工业大学深圳研究院 | A multi-class target detection method in remote sensing images based on sample reweighting |
| CN112419310A (en) * | 2020-12-08 | 2021-02-26 | 中国电子科技集团公司第二十研究所 | Target detection method based on intersection and fusion frame optimization |
| CN112419310B (en) * | 2020-12-08 | 2023-07-07 | 中国电子科技集团公司第二十研究所 | A Target Detection Method Based on Intersection and Fusion Frame Selection |
| CN112613544A (en) * | 2020-12-16 | 2021-04-06 | 北京迈格威科技有限公司 | Target detection method, device, electronic equipment and computer readable medium |
| CN112841154A (en) * | 2020-12-29 | 2021-05-28 | 长沙湘丰智能装备股份有限公司 | Disease and pest control system based on artificial intelligence |
| CN112634313B (en) * | 2021-01-08 | 2021-10-29 | 云从科技集团股份有限公司 | Target occlusion assessment method, system, medium and device |
| CN112634313A (en) * | 2021-01-08 | 2021-04-09 | 云从科技集团股份有限公司 | Target occlusion assessment method, system, medium and device |
| CN114037648A (en) * | 2021-02-04 | 2022-02-11 | 广州睿享网络科技有限公司 | Intelligent rate parameter control method based on similar Softmax function information entropy |
| CN114037648B (en) * | 2021-02-04 | 2025-09-02 | 杭州追猎科技有限公司 | Intelligent rate parameter control method based on information entropy of Softmax-like function |
| CN112949520A (en) * | 2021-03-10 | 2021-06-11 | 华东师范大学 | Aerial photography vehicle detection method and detection system based on multi-scale small samples |
| CN112949520B (en) * | 2021-03-10 | 2022-07-26 | 华东师范大学 | Aerial photography vehicle detection method and detection system based on multi-scale small samples |
| CN112950703A (en) * | 2021-03-11 | 2021-06-11 | 江苏禹空间科技有限公司 | Small target detection method and device, storage medium and equipment |
| CN112950703B (en) * | 2021-03-11 | 2024-01-19 | 无锡禹空间智能科技有限公司 | Small target detection method, device, storage medium and equipment |
| CN113160141A (en) * | 2021-03-24 | 2021-07-23 | 华南理工大学 | Steel sheet surface defect detecting system |
| JP2023527615A (en) * | 2021-04-28 | 2023-06-30 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | Target object detection model training method, target object detection method, device, electronic device, storage medium and computer program |
| CN113326734A (en) * | 2021-04-28 | 2021-08-31 | 南京大学 | Rotary target detection method based on YOLOv5 |
| CN113326734B (en) * | 2021-04-28 | 2023-11-24 | 南京大学 | A rotating target detection method based on YOLOv5 |
| WO2022227770A1 (en) * | 2021-04-28 | 2022-11-03 | 北京百度网讯科技有限公司 | Method for training target object detection model, target object detection method, and device |
| CN113538331A (en) * | 2021-05-13 | 2021-10-22 | 中国地质大学(武汉) | Metal surface damage target detection and identification method, device, equipment and storage medium |
| CN113408429A (en) * | 2021-06-22 | 2021-09-17 | 深圳市华汉伟业科技有限公司 | Target detection method and system with rotation adaptability |
| CN113408429B (en) * | 2021-06-22 | 2023-06-09 | 深圳市华汉伟业科技有限公司 | Target detection method and system with rotation adaptability |
| CN114067110A (en) * | 2021-07-13 | 2022-02-18 | 广东国地规划科技股份有限公司 | Method for generating instance segmentation network model |
| CN113469100A (en) * | 2021-07-13 | 2021-10-01 | 北京航科威视光电信息技术有限公司 | Method, device, equipment and medium for detecting target under complex background |
| CN113657174A (en) * | 2021-07-21 | 2021-11-16 | 北京中科慧眼科技有限公司 | Vehicle pseudo-3D information detection method and device and automatic driving system |
| CN113657214B (en) * | 2021-07-30 | 2024-04-02 | 哈尔滨工业大学 | Building damage assessment method based on Mask RCNN |
| CN113657214A (en) * | 2021-07-30 | 2021-11-16 | 哈尔滨工业大学 | Mask RCNN-based building damage assessment method |
| CN113705387A (en) * | 2021-08-13 | 2021-11-26 | 国网江苏省电力有限公司电力科学研究院 | Method for detecting and tracking interferent for removing foreign matters on overhead line by laser |
| CN113705387B (en) * | 2021-08-13 | 2023-11-17 | 国网江苏省电力有限公司电力科学研究院 | An interference detection and tracking method for laser removal of foreign objects on overhead lines |
| US12462575B2 (en) | 2021-08-19 | 2025-11-04 | Tesla, Inc. | Vision-based machine learning model for autonomous driving with adjustable virtual camera |
| US12522243B2 (en) | 2021-08-19 | 2026-01-13 | Tesla, Inc. | Vision-based system training with simulated content |
| CN113628250A (en) * | 2021-08-27 | 2021-11-09 | 北京澎思科技有限公司 | Target tracking method and device, electronic equipment and readable storage medium |
| CN113743521A (en) * | 2021-09-10 | 2021-12-03 | 中国科学院软件研究所 | Target detection method based on multi-scale context sensing |
| CN113743521B (en) * | 2021-09-10 | 2023-06-27 | 中国科学院软件研究所 | Target detection method based on multi-scale context awareness |
| US12591240B2 (en) | 2021-10-22 | 2026-03-31 | Tesla, Inc. | Multi-channel sensor simulation for autonomous control systems |
| CN114067228B (en) * | 2021-10-26 | 2024-11-29 | 神思电子技术股份有限公司 | Target detection method and system for enhancing foreground and background distinction |
| CN114067228A (en) * | 2021-10-26 | 2022-02-18 | 神思电子技术股份有限公司 | Target detection method and system for enhancing foreground and background discrimination |
| CN113870254A (en) * | 2021-11-30 | 2021-12-31 | 中国科学院自动化研究所 | Target object detection method, device, electronic device and storage medium |
| CN114202649B (en) * | 2021-12-15 | 2025-05-13 | 南京理工大学 | A target localization method and system based on multi-scale attention constraints |
| CN114202649A (en) * | 2021-12-15 | 2022-03-18 | 南京理工大学 | Target positioning method and system based on multi-scale attention constraint |
| CN113963274B (en) * | 2021-12-22 | 2022-03-04 | 中国人民解放军96901部队 | Satellite image target intelligent identification system and method based on improved SSD algorithm |
| CN113963274A (en) * | 2021-12-22 | 2022-01-21 | 中国人民解放军96901部队 | Satellite image target intelligent identification system and method based on improved SSD algorithm |
| CN114898092B (en) * | 2022-04-15 | 2025-05-06 | 南京理工大学 | A method for simultaneous detection and segmentation of space targets |
| CN114898092A (en) * | 2022-04-15 | 2022-08-12 | 南京理工大学 | A Method for Simultaneous Detection and Segmentation of Spatial Objects |
| CN115330724A (en) * | 2022-08-15 | 2022-11-11 | 浙江理工大学 | Fabric image flaw detection method based on OCRA-YOLOv5 |
| CN116524338A (en) * | 2023-05-06 | 2023-08-01 | 杭州意能电力技术有限公司 | Improved method and system for detecting dangerous behaviors of large-size small targets of YOLOX |
| CN116580725A (en) * | 2023-05-08 | 2023-08-11 | 科大讯飞股份有限公司 | A voice endpoint detection method, device, equipment and storage medium |
| CN116645523A (en) * | 2023-07-24 | 2023-08-25 | 济南大学 | A Fast Target Detection Method Based on Improved RetinaNet |
| CN116645523B (en) * | 2023-07-24 | 2023-12-01 | 江西蓝瑞存储科技有限公司 | Rapid target detection method based on improved RetinaNet |
| CN118628724A (en) * | 2024-08-14 | 2024-09-10 | 绍兴文理学院 | A method and system for extracting image interest regions based on weak label data |
| CN120912875A (en) * | 2025-10-11 | 2025-11-07 | 合肥智能语音创新发展有限公司 | Small object detection method, small object detection device, electronic device, storage medium and program product |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111461110B (en) | 2023-04-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111461110A (en) | Small target detection method based on multi-scale image and weighted fusion loss | |
| JP7523711B2 (en) | Image processing device and image processing method | |
| CN109299274B (en) | Natural scene text detection method based on full convolution neural network | |
| CN113762409B (en) | A UAV target detection method based on event camera | |
| WO2021244079A1 (en) | Method for detecting image target in smart home environment | |
| CN112329658A (en) | An Improved Method of Detection Algorithm for YOLOV3 Network | |
| CN113052210A (en) | Fast low-illumination target detection method based on convolutional neural network | |
| CN111160407B (en) | Deep learning target detection method and system | |
| WO2021249255A1 (en) | Grabbing detection method based on rp-resnet | |
| CN112949520B (en) | Aerial photography vehicle detection method and detection system based on multi-scale small samples | |
| CN112364931A (en) | Low-sample target detection method based on meta-feature and weight adjustment and network model | |
| CN117456330A (en) | A low-light target detection method based on MSFAF-Net | |
| CN110175504A (en) | A kind of target detection and alignment schemes based on multitask concatenated convolutional network | |
| CN110163836A (en) | Based on deep learning for the excavator detection method under the inspection of high-altitude | |
| CN116758340A (en) | Small target detection method based on super-resolution feature pyramid and attention mechanism | |
| CN110443763A (en) | A kind of Image shadow removal method based on convolutional neural networks | |
| CN119314141B (en) | Lightweight parking detection method based on multi-scale attention mechanism | |
| CN101339661B (en) | A real-time human-computer interaction method and system based on handheld device motion detection | |
| CN119131085B (en) | A target tracking method based on gated attention mechanism and spatiotemporal memory network | |
| CN118898545A (en) | A multi-level collaborative mapping method for fusion of hyperspectral and multispectral remote sensing images | |
| CN114708615A (en) | Human body detection method based on image enhancement in low-illumination environment, electronic equipment and storage medium | |
| CN115063890A (en) | Human body posture estimation method based on two-stage weighted mean square loss function | |
| CN115410089B (en) | Optical remote sensing small-scale target detection method with self-adaptive local context embedding | |
| Xiong et al. | Bi-directional skip connection feature pyramid network and sub-pixel convolution for high-quality object detection | |
| CN117853582B (en) | Star sensor rapid star image extraction method based on improved Faster R-CNN |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20230428 |