CN108399127B - Class integration test sequence generation method - Google Patents
Class integration test sequence generation method Download PDFInfo
- Publication number
- CN108399127B CN108399127B CN201810140091.7A CN201810140091A CN108399127B CN 108399127 B CN108399127 B CN 108399127B CN 201810140091 A CN201810140091 A CN 201810140091A CN 108399127 B CN108399127 B CN 108399127B
- Authority
- CN
- China
- Prior art keywords
- class
- test
- classes
- test sequence
- complexity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/36—Prevention of errors by analysis, debugging or testing of software
- G06F11/3668—Testing of software
- G06F11/3672—Test management
- G06F11/3684—Test management for test design, e.g. generating new test cases
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/12—Computing arrangements based on biological models using genetic models
- G06N3/126—Evolutionary algorithms, e.g. genetic algorithms or genetic programming
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Quality & Reliability (AREA)
- Computer Hardware Design (AREA)
- Physiology (AREA)
- Genetics & Genomics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
技术领域technical field
本发明属于软件测试技术领域,特别是在集成测试中类测试序列生成问题中,一种类测试序列的生成方法。The invention belongs to the technical field of software testing, and particularly relates to a method for generating a test-like sequence in the problem of generating a test-like sequence in an integration test.
背景技术Background technique
面向对象程序不像面向过程程序那样有明显的层次化模块结构,对象之间的联系通过消息传递的方式,一条消息会引起连锁反应进而形成一条方法调用链,体现调用关系的静态结构是一个错综复杂的网状结构。因此,从哪里开始测试以及如何确定一个集成测试序列是需要进一步研究的问题。类的测试顺序关系到软件缺陷发现的时间和测试成本,因此,确定类的集成测试序列成为集成测试中的一个重要研究问题。Object-oriented programs do not have an obvious hierarchical module structure like process-oriented programs. The connection between objects is through message passing. A message will cause a chain reaction and form a method call chain. The static structure that reflects the call relationship is a complex network structure. Therefore, where to start testing and how to determine an integration test sequence are questions for further study. The test sequence of classes is related to the time and cost of software defect discovery. Therefore, it is an important research problem to determine the integration test sequence of classes.
现有工作主要通过测试桩成本的大小来衡量一个类集成测试序列的优劣。生成一个类测试序列需要打破一些类间依赖关系,直至没有环路。打破类间依赖关系的过程意味着需要构建测试桩,花费一定的成本。因此,当消除所有的类间依赖关系构成的环路时,满足构建测试桩所花费的成本越小越好。然而,通常无法直接测量或估计测试桩成本,需要借助一定的指标。目前主要从两个方面评价测试桩成本的指标:集成测试测试序列生成过程中构建的测试桩总体复杂度或者所构建的测试桩的个数。The existing work mainly measures the pros and cons of a class integration test sequence by the size of the test pile cost. Generating a class test sequence requires breaking some inter-class dependencies until there are no loops. The process of breaking dependencies between classes means building test stubs, at a cost. Therefore, while eliminating all the loops of inter-class dependencies, the less expensive it is to build test stubs, the better. However, it is usually impossible to directly measure or estimate the cost of test piles, and certain indicators are required. At present, the indicators for evaluating the cost of test piles are mainly from two aspects: the overall complexity of the test piles constructed during the generation process of the integration test test sequence or the number of the test piles constructed.
类集成测试序列的生成问题本质上是一个优化问题,同时也是一个NP-完全(难)问题。目前已有的解决方法包括基于图论的方法和基于搜索的方法。其中,基于图论的方法由于自身的局限性,无法适用于大型程序,只能针对小规模程序。已有的基于搜索的方法包括基于遗传算法的方法,基于模拟退火算法的方法、基于粒子群算法的方法、基于蚁群算法的方法和NSGA-II。最优的类集成测试序列的生成需要进行多次变换,并且“仅当变换数至少是解空间规模的平方次时,模拟退火算法才能任意逼近平稳分布”。对于类集成测试序列的生成问题来说,解空间规模是类个数的阶乘,因此变换次数的规模近似于类个数的指数次。如果采用任意近似逼近的方式,生成收敛于全局的最优类集成测试序列,模拟退火算法的执行时间将呈指数级增长方式。对于类个数较多的待测系统来说,运行时间难于承受,导致算法不可行。在NP问题中能在有限时间内收敛得到较理想的解。如当类的数量过大时,形成的类序列成指数关系增长,大大增加解空间的规模,对于使用粒子群优化算法进行求解时,容易陷入局部最优解。采用蚁群算法不能保证找到问题的最优解,而是只能保证找到问题的较优解或可接受解。遗传算法有较好的稳健性,在NP问题中能在有限时间内收敛得到较理想的解。适应度函数的选取直接影响遗传算法的收敛速度以及能否找到最优解。已有方案往往以测试桩的总体复杂度作为适应度函数,来评价个体(类集成测试序列)的优劣。然而,单纯以构建的测试桩总体复杂度或者测试桩的个数作为适应度函数都是片面的、不准确的,导致寻优效果不佳,一定程度上制约最优解的生成,因此,已有的以测试桩的总体复杂度作为适应度函数的类测试序列生成方法不能满足实际需要,而应该综合考虑构建的测试桩总体复杂度和测试桩的个数这两个指标,因此,需要设计合理的适应度函数,来评估类集成测试序列的优劣。The generation problem of class integration test sequence is essentially an optimization problem, and it is also an NP-complete (hard) problem. The existing solutions include graph theory-based methods and search-based methods. Among them, the method based on graph theory cannot be applied to large-scale programs due to its own limitations, and can only be used for small-scale programs. Existing search-based methods include methods based on genetic algorithm, methods based on simulated annealing algorithm, methods based on particle swarm optimization, methods based on ant colony algorithm and NSGA-II. The generation of optimal class ensemble test sequences requires multiple transformations, and "simulated annealing algorithms can arbitrarily approximate a stationary distribution only if the number of transformations is at least the square of the size of the solution space". For the generation of class integration test sequences, the size of the solution space is the factorial of the number of classes, so the scale of the number of transformations is approximately the exponential of the number of classes. If an arbitrary approximation method is used to generate the optimal class integration test sequence that converges to the global, the execution time of the simulated annealing algorithm will increase exponentially. For a system under test with a large number of classes, the running time is unbearable, making the algorithm infeasible. In the NP problem, it can converge in a finite time to get an ideal solution. For example, when the number of classes is too large, the formed class sequence grows exponentially, which greatly increases the scale of the solution space. When using the particle swarm optimization algorithm to solve, it is easy to fall into the local optimal solution. The use of ant colony algorithm cannot guarantee to find the optimal solution of the problem, but can only guarantee to find the better or acceptable solution of the problem. Genetic algorithm has better robustness and can converge to obtain ideal solution in finite time in NP problems. The selection of the fitness function directly affects the convergence speed of the genetic algorithm and whether it can find the optimal solution. Existing schemes often use the overall complexity of the test pile as a fitness function to evaluate the quality of an individual (class integration test sequence). However, simply taking the overall complexity of the constructed test piles or the number of test piles as the fitness function is one-sided and inaccurate, resulting in poor optimization results and restricting the generation of optimal solutions to a certain extent. Some test-like sequence generation methods that use the overall complexity of the test pile as the fitness function cannot meet the actual needs, but should comprehensively consider the overall complexity of the built test pile and the number of test piles. Therefore, it is necessary to design Reasonable fitness function to evaluate the pros and cons of class integration test sequences.
发明内容SUMMARY OF THE INVENTION
针对面向对象程序类规模大、类间关系复杂等特点,对于类集成测试序列确定难度大的问题,克服现有技术寻优效果不佳的问题,本发明提供一种基于遗传算法的类集成测试序列生成方法,利用遗传算法中种群进化特性,逐次产生最优解,解决面向对象程序集成测试中的类测试序列生成问题。Aiming at the characteristics of large scale of object-oriented program classes and complex relationships between classes, and the difficulty of determining the class integration test sequence, and overcoming the problem of poor optimization effect in the prior art, the present invention provides a class integration test based on genetic algorithm The sequence generation method utilizes the evolutionary characteristics of the population in the genetic algorithm to generate the optimal solution one by one, and solves the problem of generating class test sequences in the integration testing of object-oriented programs.
本发明按以下技术方案实现:The present invention is realized according to the following technical solutions:
一种类集成测试序列生成方法,包括:A kind of integration test sequence generation method, including:
数据收集模块,用于获取类及类间关系信息,获取类优先级表;以及A data collection module for obtaining class and inter-class relationship information, and obtaining a class priority table; and
类集成测试序列生成模块,其实现如下:The class integration test sequence generation module is implemented as follows:
步骤A、读取所述数据收集模块中的所有类及类间关系信息;Step A, read all classes and inter-class relationship information in the data collection module;
步骤B、读取所述数据收集模块中的类优先级表,Step B, read the class priority table in the described data collection module,
步骤C、通过遗传算法自动生成类集成测试序列。Step C. Automatically generate a class integration test sequence through a genetic algorithm.
优选的是,所述步骤C具体实现过程为:Preferably, the specific implementation process of the step C is:
步骤一:对类进行编码;Step 1: Encode the class;
步骤二:在类优先级表所给的优先级信息的约束下随机生成规模为类个数的2-3倍数量的初始种群P;Step 2: Randomly generate an initial population P whose size is 2-3 times the number of classes under the constraints of the priority information given by the class priority table;
步骤三:构造适应度函数,用于评价个体的优劣;Step 3: Construct a fitness function to evaluate the pros and cons of individuals;
步骤四:计算种群P中每个个体的适应度值,以测试桩总体复杂度和测试桩的总个数的加权平均作为个体评价标准;Step 4: Calculate the fitness value of each individual in the population P, and use the weighted average of the overall complexity of the test piles and the total number of test piles as the individual evaluation criteria;
步骤五:针对每个个体的适应度值对个体赋予不同的选择概率Ps,采用轮盘赌的方式从初始种群P中选择类个数的2-3倍数量的个体,生成新的种群P’;Step 5: According to the fitness value of each individual, assign different selection probabilities Ps to the individual, and select 2-3 times the number of classes from the initial population P by roulette to generate a new population P' ;
步骤六:根据输入的交叉概率Pc,使种群P’中的父代个体进行两两交叉,对交叉后的个体进行合法性检验,保留合法的个体,舍弃不合法的个体;Step 6: According to the input crossover probability Pc, make the parent individuals in the population P' to cross each other in pairs, carry out the legality test of the crossed individuals, retain the legal individuals, and discard the illegal individuals;
步骤七:根据输入的变异概率Pm,对父代个体进行基因段重排,对生成新的个体进行合法性检验;Step 7: According to the input mutation probability Pm, rearrange the gene segment of the parent individual, and perform the legitimacy test of the generated new individual;
步骤八:重复步骤四至步骤七多次,最后得到的类测试序列结果即为最优解,最优测试序列使得构建测试桩的所花费的测试代价最小。Step 8: Repeat steps 4 to 7 for several times, and the final result of the class test sequence is the optimal solution, and the optimal test sequence minimizes the testing cost of constructing the test pile.
优选的是,步骤三中,构造用于评价个体优劣的适应度函数时,综合考虑构建测试桩所花费的总体复杂度和构建的测试桩的个数两个指标;Preferably, in step 3, when constructing the fitness function for evaluating the strengths and weaknesses of the individual, two indicators, the overall complexity of constructing the test piles and the number of the constructed test piles, are comprehensively considered;
其中测试桩的总体复杂度的计算需要借助所构造的所有的单个测试桩的复杂度,而在度量单个测试桩的复杂度时,采用的是客观的熵权法来确定所使用的属性复杂度和方法复杂度的权值。The calculation of the overall complexity of the test pile needs to rely on the complexity of all the single test piles constructed, and when measuring the complexity of a single test pile, the objective entropy weight method is used to determine the attribute complexity used. and weights of method complexity.
优选的是,步骤三中,适应度函数表示方法如下:Preferably, in step 3, the fitness function representation method is as follows:

其中,Fitness代表适应度函数,等式右边代表测试桩总体复杂度和测试桩的总个数的加权平均;OCplx和NStub分别为生成一个类集成测试序列所花费的测试桩总体复杂度和测试桩的总个数;WOCplx和WNStub分别为测试桩总体复杂度和测试桩的总数的权重,取值在[0,1]之间,且满足WOCplx+WNStub=1。Among them, Fitness represents the fitness function, and the right side of the equation represents the weighted average of the overall complexity of the test piles and the total number of test piles; OCplx and NStub are the overall complexity of the test piles and the test piles spent to generate a class integration test sequence, respectively. The total number of ; W OCplx and W NStub are the weights of the overall complexity of the test piles and the total number of test piles, respectively, the value is between [0, 1], and satisfies W OCplx + W NStub =1.
优选的是,步骤五中,Preferably, in step five,

其中,Fi表示第i个个体的适应度值,N表示种群中个体的数量。Among them, Fi represents the fitness value of the ith individual, and N represents the number of individuals in the population.
优选的是,所述步骤六中,交叉概率Pc取0.5。Preferably, in the sixth step, the crossover probability Pc is 0.5.
优选的是,所述步骤七中,变异概率Pm取1/G;Preferably, in the seventh step, the mutation probability Pm is taken as 1/G;
其中,G为一个个体中基因的个数,即类的个数。Among them, G is the number of genes in an individual, that is, the number of classes.
优选的是,所述数据收集模块获取类及类间关系信息具体实现如下:Preferably, the data collection module obtains the class and the relationship information between classes and is specifically implemented as follows:
从面向对象系统的源代码获取所有类信息、描述类间关系的三元组和类间耦合信息。Obtain all class information, triples describing inter-class relationships, and inter-class coupling information from the source code of an object-oriented system.
优选的是,所有类信息、描述类间关系的三元组和类间耦合信息是通过开放源码分析工具SOOT从待测程序的源代码中所获取;所有类信息、描述类间关系的三元组和类间耦合信息分别保存在类信息文件和类间关系的三元组信息文件中。Preferably, all class information, triples describing relationships between classes, and coupling information between classes are obtained from the source code of the program to be tested through the open source analysis tool SOOT; all class information, triples describing relationships between classes are obtained from the source code of the program under test; The group and inter-class coupling information is stored in the class information file and the triple information file of the inter-class relationship, respectively.
优选的是,所述数据收集模块获取类优先级表具体实现如下:Preferably, the specific implementation of the data collection module for obtaining the class priority table is as follows:
从面向对象系统的UML设计文档中的类图获得类优先级表。Obtain the class priority table from the class diagram in the UML design document of the object-oriented system.
本发明有益效果:Beneficial effects of the present invention:
(1)类集成测试序列的生成问题是NP问题,目前的方法主要是基于图论的方法和基于搜索的方法。其中,基于图论的方法由于自身的局限性,无法适用于大型程序,只能解决小规模程序的类集成测试序列的生成问题。已有的基于搜索的方法收敛到最优解较慢,与实际应用还有较大的距离。本发明通过基于遗传算法的类集成测试序列生成技术,利用遗传算法中的编码、生成初始种群、适应度函数的设计、个体评价、选择、交叉、变异等对种群不断进化,逐步产生最优解,解决类集成测试序列生成问题。(1) The generation problem of class integration test sequence is an NP problem, and the current methods are mainly based on graph theory and search-based methods. Among them, the method based on graph theory cannot be applied to large-scale programs due to its own limitations, and can only solve the problem of generating integration test sequences for small-scale programs. Existing search-based methods are slow to converge to the optimal solution, and are still far from practical applications. Through the generation technology of class integration test sequence based on genetic algorithm, the invention utilizes coding in genetic algorithm, generation of initial population, design of fitness function, individual evaluation, selection, crossover, mutation, etc. to continuously evolve the population, and gradually generate the optimal solution , to solve the class integration test sequence generation problem.
(2)本发明结合相关的参数配置,运用遗传算法,对待测系统的类进行排序,为测试人员对系统进行集成测试提供科学方案。本发明提供的基于遗传算法的类集成测试序列的生成技术,在生成初始种群时考虑了类的优先级信息,在类优先级的约束下生成初始种群,克服了以往的初始种群没有任何约束条件,个体适应度值较低,整体质量较差,影响收敛速度及寻优结果的问题,既不失随机性,又提高了种群整体质量,加强了遗传算法的寻优能力。(2) The present invention combines relevant parameter configuration, uses genetic algorithm to sort the classes of the system to be tested, and provides a scientific solution for testers to perform integrated testing of the system. The generation technology of the class integration test sequence based on the genetic algorithm provided by the invention considers the priority information of the class when generating the initial population, and generates the initial population under the constraint of the class priority, which overcomes the previous initial population without any constraints. , the individual fitness value is low, and the overall quality is poor, which affects the convergence speed and optimization results. It not only loses randomness, but also improves the overall quality of the population and strengthens the optimization ability of the genetic algorithm.
(3)本发明综合考虑了构建的测试桩总体复杂度和构建的测试桩的个数,将这两个指标共同作为个体优劣评价标准,既打破了现有技术不允许删除继承、聚集等强依赖关系的限制,又克服了以往的以构建的测试桩花费的总体复杂度或者构建的测试桩的个数作为个体评价标准,导致寻优效果不够准确,一定程度上制约最优解的生成的问题,更加合理,更能满足实际需要。(3) The present invention comprehensively considers the overall complexity of the constructed test piles and the number of constructed test piles, and uses these two indicators as the evaluation criteria of individual strengths and weaknesses, which not only breaks the prior art that does not allow deletion, inheritance, aggregation, etc. The limitation of strong dependencies also overcomes the previous use of the overall complexity of the constructed test piles or the number of constructed test piles as the individual evaluation criteria, resulting in an inaccurate optimization effect, which restricts the generation of the optimal solution to a certain extent. The problem is more reasonable and can better meet the actual needs.
附图说明Description of drawings
图1为本发明的结构图;Fig. 1 is the structure diagram of the present invention;
图2为图1中数据收集模块中获取类及其相关信息的流程图;Fig. 2 is the flow chart of obtaining class and its related information in the data collection module in Fig. 1;
图3为图1中数据收集模块中获取类优先级表的流程图;Fig. 3 is the flow chart of obtaining the class priority table in the data collection module in Fig. 1;
图4为图1中使用遗传算法的类集成测试序列生成模块的实现流程图。FIG. 4 is a flow chart of the realization of the class integration test sequence generation module using the genetic algorithm in FIG. 1 .
具体实施方式Detailed ways
以下结合附图,通过具体实施例对本发明作进一步的说明。The present invention will be further described below through specific embodiments in conjunction with the accompanying drawings.
如图1所示,本发明包括数据收集模块和使用遗传算法的类集成测试序列生成模块两部分,其中:As shown in Figure 1, the present invention includes two parts: a data collection module and a class integration test sequence generation module using a genetic algorithm, wherein:
数据收集模块:用于获取类及类间关系信息,获取类优先级表。该模块作为类集成测试序列生成模块的输入信息,为类集成测试序列生成模块提供基础信息和优先级信息,作为类集成测试序列生成模块中生成初始种群的约束信息。Data collection module: used to obtain class and inter-class relationship information, and class priority table. This module serves as the input information of the class integration test sequence generation module, provides basic information and priority information for the class integration test sequence generation module, and serves as the constraint information for generating the initial population in the class integration test sequence generation module.
类集成测试序列生成模块:读取数据收集模块中的所有类、类间关系、类间耦合信息及优先级信息。输入生成测试序列时所设置的参数N,I,Pc,Pm,N代表种群大小,I代表迭代次数,Pc代表交叉概率,Pm代表变异概率,调用遗传算法,输出的结果即为最优的类集成测试序列。Class integration test sequence generation module: Read all classes, inter-class relationships, inter-class coupling information and priority information in the data collection module. Input the parameters N, I, Pc, Pm set when generating the test sequence, N represents the population size, I represents the number of iterations, Pc represents the crossover probability, Pm represents the mutation probability, call the genetic algorithm, and the output result is the optimal class Integration test sequence.
如图2所示,本发明中数据收集模块(获取类及其相关信息)的具体实现如下:从面向对象系统的源代码获取所有类信息、描述类间关系的三元组和类间耦合信息(包括属性复杂度和方法复杂度)。As shown in Figure 2, the specific implementation of the data collection module (acquiring classes and their related information) in the present invention is as follows: obtain all class information, triples describing the relationship between classes, and coupling information between classes from the source code of the object-oriented system (including property complexity and method complexity).
如图3所示,本发明中数据收集模块(获取类优先级表)的具体实现如下:从面向对象系统的UML设计文档中的类图获得类优先级表。As shown in FIG. 3 , the specific implementation of the data collection module (obtaining the class priority table) in the present invention is as follows: the class priority table is obtained from the class diagram in the UML design document of the object-oriented system.
如图4所示,本发明中使用遗传算法的类集成测试序列生成模块的具体实现如下:As shown in Figure 4, the concrete realization of the class integration test sequence generation module using genetic algorithm in the present invention is as follows:
1)读取所述数据收集模块中的所有类及类间关系信息;1) Read all classes and inter-class relationship information in the data collection module;
2)读取所述数据收集模块中的类优先级表,2) read the class priority table in the data collection module,
3)通过遗传算法自动生成类集成测试序列,包括编码、生成初始种群、构造适应度函数、评价个体、选择操作、交叉操作和变异操作等八个步骤,如图4所示。3) Automatically generate class integration test sequence through genetic algorithm, including eight steps, including encoding, generating initial population, constructing fitness function, evaluating individual, selecting operation, crossover operation and mutation operation, as shown in Figure 4.
类集成测试序列生成模块具体实现过程为:The specific implementation process of the class integration test sequence generation module is as follows:
步骤一:对类进行编码:一组用标签表示的类表示一个个体,如一个类簇{A,B,C},一个可能的个体为(B,C,A)序列,一个可能的种群为{(B C A),(B A C),…};Step 1: Encode the class: a set of classes represented by labels represents an individual, such as a class cluster {A, B, C}, a possible individual is (B, C, A) sequence, and a possible population is {(B C A),(B A C),…};
步骤二:输入生成测试序列时所设置的参数N,I,Pc,Pm,读取数据收集模块中的类信息及其优先级信息,在类优先级的约束下生成规模为N(N为类个数的2-3倍)的初始种群P(一组类测试序列);Step 2: Input the parameters N, I, Pc, Pm set when generating the test sequence, read the class information and its priority information in the data collection module, and generate a scale of N under the constraint of class priority (N is the class 2-3 times the number) of the initial population P (a set of class test sequences);
步骤三:构造适应度函数,用于评价个体的优劣,构造方法如下所示:Step 3: Construct a fitness function, which is used to evaluate the pros and cons of individuals. The construction method is as follows:
一个个体表示一个类集成测试序列,适应度函数表示方法如公式(1)所示。其中Fitness代表适应度函数,等式右边代表测试桩总体复杂度和测试桩的总个数的加权平均。An individual represents a class integration test sequence, and the fitness function representation method is shown in formula (1). Among them, Fitness represents the fitness function, and the right side of the equation represents the weighted average of the overall complexity of the test piles and the total number of test piles.

其中,OCplx和NStub分别为生成一个类集成测试序列所花费的测试桩总体复杂度和测试桩的总个数;WOCplx和WNStub分别为测试桩总体复杂度和测试桩的总数的权重,取值在[0,1]之间,且满足WOCplx+WNStub=1,本发明取WOCplx=WNStub=0.5。Among them, OCplx and NStub are the overall complexity of the test piles and the total number of test piles to generate a class integration test sequence respectively; W OCplx and W NStub are the weight of the overall complexity of the test piles and the total number of test piles, respectively, take The value is between [0, 1] and satisfies W OCplx +W NStub =1, the present invention takes W OCplx =W NStub =0.5.
公式(1)中的

其中,OCplxmin=Min{OCplx(ok),k=1,2,...}和OCplxmax=Max{OCplx(ok),k=1,2,...},k为类测试序列的个数。where OCplx min =Min{OCplx(ok ), k =1,2,...} and OCplx max =Max{OCplx(ok ), k =1,2,...}, k is the class test the number of sequences.
其中,对于生成一个测试序列所花费的测试桩的总体复杂度OCplx()的计算方法如公式(3):Among them, the calculation method of the overall complexity OCplx() of the test piles spent to generate a test sequence is as formula (3):

其中,t表示类间关系的个数,测试桩复杂度SCplx(i,j)表示存在依赖关系的两个类i,j之间的耦合程度,即单个测试桩的复杂度,可以通过标准化的加权几何平均计算,如公式(4):Among them, t represents the number of relationships between classes, and the test pile complexity SCplx(i,j) represents the degree of coupling between two classes i, j with dependencies, that is, the complexity of a single test pile, which can be calculated by standardized Weighted geometric mean calculation, such as formula (4):

其中,A(i,j)和M(i,j)分别为在数据收集模块中获取的属性复杂度和方法复杂度;WA和WM分别为属性复杂度和方法复杂度的权重,取值在[0,1]之间,且WA+WM=1。Among them, A(i,j) and M(i,j) are the attribute complexity and method complexity obtained in the data collection module respectively; W A and W M are the weights of the attribute complexity and method complexity, respectively, take The value is between [0,1] and W A + W M =1.
为了更为客观,本发明采用熵权法来确定WA和WM的具体的值。具体如下:In order to be more objective, the present invention adopts the entropy weight method to determine the specific values of W A and W M. details as follows:
假设有m个类间关系(m的取值根据待测系统来确定),n个评价指标,本发明有2个评价指标,即属性复杂度A(i,j)和方法复杂度M(i,j),那么n=2;构造一个标准的矩阵R=(rxy)m*n,如公式(5)所示:Assuming that there are m inter-class relationships (the value of m is determined according to the system to be tested) and n evaluation indicators, the present invention has two evaluation indicators, namely attribute complexity A(i,j) and method complexity M(i ,j), then n=2; construct a standard matrix R=(r xy ) m*n , as shown in formula (5):

其中,m表示待测系统中的类间关系的个数,rxy表示第y个指标下的第x个类间关系的评价值,这里,y=1,2,当y=1时,rx1表示第x个类间关系的属性复杂度的影响力;当y=2时,rx2表示第x个类间关系的方法复杂度的影响力,1≤x≤m;Among them, m represents the number of inter-class relationships in the system to be tested, r xy represents the evaluation value of the x-th inter-class relationship under the y-th index, here, y=1, 2, when y=1, r x1 represents the influence of the attribute complexity of the x-th inter-class relationship; when y=2, r x2 represents the influence of the method complexity of the x-th inter-class relationship, 1≤x≤m;
然后,计算第y(y=1,2)个指标下第x个类间关系的指标值的比重pxy:Then, calculate the proportion p xy of the index value of the x-th inter-class relationship under the y-th (y=1,2) index:

第y个指标的信息熵ej,如公式(7)所示。The information entropy e j of the y-th index is shown in formula (7).

最后,计算第y个指标的权重,如公式(8)所示:Finally, the weight of the y-th indicator is calculated, as shown in formula (8):

其中,当y=1时,w1表示属性复杂度指标的权重WA,当y=2时,w2表示方法复杂度指标的权重WM。Wherein, when y=1, w1 represents the weight W A of the attribute complexity index, and when y=2, w2 represents the weight W M of the method complexity index.
公式(1)中的

其中,NStubmin=Min{NStub(ok),k=1,2,...}和NStubmax=Max{NStub(ok),k=1,2,...},k为类测试序列的个数。Among them, NStub min =Min{NStub(o k ),k=1,2,...} and NStub max =Max{NStub(o k ),k=1,2,...}, k is the class test the number of sequences.
步骤四:计算种群P中每个个体的适应度值,以步骤三中构造的适应度函数作为评价标准,即,将测试桩总体复杂度和测试桩的总个数的加权平均作为个体适应度值的计算方法;Step 4: Calculate the fitness value of each individual in the population P, take the fitness function constructed in step 3 as the evaluation standard, that is, take the weighted average of the overall complexity of the test piles and the total number of test piles as the individual fitness the calculation method of the value;
步骤五:针对每个个体的适应度值对个体赋予不同的选择概率Ps(计算方法如下公式所示,其中,Fi表示第i个个体的适应度值,N表示种群中个体的数量),采用轮盘赌的方式从初始种群P中选择类个数的2-3倍数量的个体,生成新的种群P’;Step 5: According to the fitness value of each individual, assign different selection probability Ps to the individual (the calculation method is shown in the following formula, where Fi represents the fitness value of the ith individual, and N represents the number of individuals in the population), using The roulette method selects individuals with 2-3 times the number of classes from the initial population P to generate a new population P';
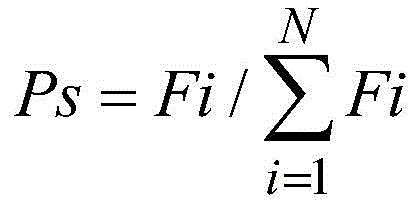
步骤六:根据输入的交叉概率Pc(取0.5),使种群P’中的父代个体进行两两交叉,对交叉后的个体进行合法性检验,保留合法的个体,舍弃不合法的个体;Step 6: According to the input crossover probability Pc (take 0.5), the parent individuals in the population P' are crossed in pairs, and the legality of the crossed individuals is checked, the legal individuals are retained, and the illegal individuals are discarded;
步骤七:根据输入的变异概率Pm(取1/G,G为一个个体中基因的个数,即类的个数),对父代个体进行基因段重排,对生成新的个体进行合法性检验;Step 7: According to the input mutation probability Pm (take 1/G, G is the number of genes in an individual, that is, the number of classes), rearrange the gene segments of the parent individual, and verify the legitimacy of generating a new individual test;
步骤八:重复步骤四至步骤七100次,得到的类集成测试序列即为最优解。Step 8: Repeat steps 4 to 7 for 100 times, and the obtained quasi-integration test sequence is the optimal solution.
下面给出将本发明的类集成测试序列生成方法应用到具体例中:The following provides that the class integration test sequence generation method of the present invention is applied to a specific example:
我们针对JBoss、JHotDraw和MyBatis三个系统进行了实验。这三个系统的详细信息如表1所示。We conducted experiments on three systems: JBoss, JHotDraw and MyBatis. The details of these three systems are shown in Table 1.
表1实验对象信息Table 1 Information of experimental subjects

a http://www.jboss.org/jbossas/downloads.html–subsystem used:management of JBoss(version 6.0.0M5):is a Java application server;a http://www.jboss.org/jbossas/downloads.html–subsystem used:management of JBoss(version 6.0.0M5):is a Java application server;
b http://sourceforge.net/projects/jhotdraw/–package used:org.jhotdraw.draw of JHotDraw(version 7.5.1):framework for the creation ofdrawing editors;b http://sourceforge.net/projects/jhotdraw/–package used:org.jhotdraw.draw of JHotDraw(version 7.5.1):framework for the creation ofdrawing editors;
c http://code.google.com/p/mybatis/downloads/list:data mapperframework that makes easier the use a relational database with OOapplication;c http://code.google.com/p/mybatis/downloads/list:data mapperframework that makes easier the use a relational database with OOapplication;
上述三个网址给出了JBoss、JHotDraw和MyBatis三个系统的来源。The above three URLs give the sources of three systems: JBoss, JHotDraw and MyBatis.
实验所用操作系统为Windows 8,CPU为酷睿i5双核(2.6GHz),物理内存为4G。生成类测试序列所需要运行的时间如表2所示。与以测试桩的总体复杂度作为适应度的类集成测试序列生成方法相比,在相同的种群数量下,本发明可以更快找到最优的类集成测试序列。The operating system used in the experiment is Windows 8, the CPU is Core i5 dual-core (2.6GHz), and the physical memory is 4G. The running time required to generate the class test sequence is shown in Table 2. Compared with the generation method of the class integration test sequence which takes the overall complexity of the test pile as the fitness, the present invention can find the optimal class integration test sequence faster under the same population number.
表2运行时间(毫秒)Table 2 Run time (ms)

现有技术相比:Compared to the existing technology:
本发明在一定程度上解决了类集成测试序列问题中初始种群没有任何约束条件,初始种群整体质量较差,进而影响收敛速度及寻优结果的问题以及个体评价标准的片面性和不合理性所导致的寻优效果不够准确的问题。不仅提高了种群整体质量,加快了收敛速度,而且加强了遗传算法的寻优能力,提高了寻优的准确性,进而提高了测试效率和精度,更能满足实际需要。The invention solves the problem that the initial population does not have any constraint conditions in the class integration test sequence problem to a certain extent, and the overall quality of the initial population is poor, which further affects the convergence speed and the optimization result, and the one-sidedness and irrationality of individual evaluation standards. The optimization effect is not accurate enough. It not only improves the overall quality of the population and accelerates the convergence speed, but also strengthens the optimization ability of the genetic algorithm, improves the accuracy of optimization, and further improves the test efficiency and accuracy, and can better meet the actual needs.
以上仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。The above are only the preferred embodiments of the present invention, it should be pointed out: for those of ordinary skill in the art, under the premise of not departing from the principles of the present invention, several improvements and modifications can also be made, and these improvements and modifications should also be regarded as It is the protection scope of the present invention.
Claims (9)


Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810140091.7A CN108399127B (en) | 2018-02-09 | 2018-02-09 | Class integration test sequence generation method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810140091.7A CN108399127B (en) | 2018-02-09 | 2018-02-09 | Class integration test sequence generation method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108399127A CN108399127A (en) | 2018-08-14 |
| CN108399127B true CN108399127B (en) | 2020-06-23 |
Family
ID=63095919
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810140091.7A Expired - Fee Related CN108399127B (en) | 2018-02-09 | 2018-02-09 | Class integration test sequence generation method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108399127B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113377651A (en) * | 2021-06-10 | 2021-09-10 | 中国矿业大学 | Class integration test sequence generation method based on reinforcement learning |
| CN113868113B (en) * | 2021-06-22 | 2024-09-06 | 中国矿业大学 | A method for generating class integration test sequences based on Actor-Critic algorithm |
| CN117909249B (en) | 2024-03-20 | 2024-07-02 | 中国汽车技术研究中心有限公司 | A method and device for generating test cases for autonomous driving scenarios |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102323906A (en) * | 2011-09-08 | 2012-01-18 | 哈尔滨工程大学 | A method for automatic generation of MC/DC test data based on genetic algorithm |
| CN104063778A (en) * | 2014-07-08 | 2014-09-24 | 深圳市远望谷信息技术股份有限公司 | Method for allocating cargo positions for cargoes in three-dimensional warehouse |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009135168A1 (en) * | 2008-05-01 | 2009-11-05 | Icosystem Corporation | Methods and systems for the design of choice experiments and deduction of human decision-making heuristics |
-
2018
- 2018-02-09 CN CN201810140091.7A patent/CN108399127B/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102323906A (en) * | 2011-09-08 | 2012-01-18 | 哈尔滨工程大学 | A method for automatic generation of MC/DC test data based on genetic algorithm |
| CN104063778A (en) * | 2014-07-08 | 2014-09-24 | 深圳市远望谷信息技术股份有限公司 | Method for allocating cargo positions for cargoes in three-dimensional warehouse |
Non-Patent Citations (1)
| Title |
|---|
| "基于依赖性分析的面向对象程序测试技术研究";张艳梅;《中国博士学位论文全文数据库 信息科技辑》;20121015(第2012年10期);正文第67-75页,图6-2 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108399127A (en) | 2018-08-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Dwork et al. | Outcome indistinguishability | |
| Rajpal et al. | Not all bytes are equal: Neural byte sieve for fuzzing | |
| CN102855185B (en) | Pair-wise test method based on priority | |
| CN108399127B (en) | Class integration test sequence generation method | |
| CN115221675B (en) | Helium resource scale sequence determination method, device and equipment | |
| CN110516757A (en) | A transformer fault detection method and related device | |
| CN114490404A (en) | A test case determination method, device, electronic device and storage medium | |
| CN102541736A (en) | Acceleration test method in software reliability execution process | |
| CN116307352A (en) | A method and system for estimating engineering quantity indicators based on machine learning | |
| CN107729555A (en) | A kind of magnanimity big data Distributed Predictive method and system | |
| CN104699595B (en) | A kind of method for testing software of software-oriented upgrading | |
| CN115239122A (en) | Method and device recommended by testers of digital grid software project | |
| CN117992330A (en) | A Combinatorial Formal Analysis Method Based on Multi-task Bayesian Graph Neural Network | |
| CN113723536A (en) | Power inspection target identification method and system | |
| Sun et al. | Combining bootstrap and genetic programming for feature discovery in diesel engine diagnosis | |
| CN103729297A (en) | Test case generation method based on hierarchic genetic algorithm | |
| CN115965082B (en) | Phylogenetic tree construction method and system based on deep learning and beam search | |
| CN115658484B (en) | Unstructured data-oriented fuzzy test method | |
| CN117633534A (en) | Fault sample generation method, device, electronic equipment and readable storage medium | |
| Souza et al. | Machine learning prediction of the most intense peak of the absorption spectra of organic molecules | |
| CN119889544B (en) | A material structure segmentation encoding method for machine learning | |
| CN119759796B (en) | Software testing method and system based on digital fingerprint | |
| CN121117020B (en) | Data query and real-time visualization system and method based on educational large language model | |
| CN120725715B (en) | Quick cost evaluation method and system in engineering change management | |
| CN118568007B (en) | Software testing quality evaluation system and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20200623 Termination date: 20220209 |