CN108228782B - A Deep Learning-Based Approach for Implicit Relationship Discovery - Google Patents
A Deep Learning-Based Approach for Implicit Relationship Discovery Download PDFInfo
- Publication number
- CN108228782B CN108228782B CN201711469074.XA CN201711469074A CN108228782B CN 108228782 B CN108228782 B CN 108228782B CN 201711469074 A CN201711469074 A CN 201711469074A CN 108228782 B CN108228782 B CN 108228782B
- Authority
- CN
- China
- Prior art keywords
- matrix
- author
- probability
- mentor
- paper
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G06F40/35—Discourse or dialogue representation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2465—Query processing support for facilitating data mining operations in structured databases
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/40—Business processes related to social networking or social networking services
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Data Mining & Analysis (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Economics (AREA)
- Entrepreneurship & Innovation (AREA)
- Human Resources & Organizations (AREA)
- Fuzzy Systems (AREA)
- Probability & Statistics with Applications (AREA)
- Operations Research (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- General Business, Economics & Management (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明公开了一种基于深度学习的隐含关系发现方法,属于信息技术领域,具体包括从学者发表网络G中生成论文合著网络G’;计算论文发表情况矩阵C,D,S以及论文的合著矩阵XS,XD,XT;提出了RGRU模型;在RGRU的基础上设计并构建tARMM模型来预测“导师‑学生”关系。本发明提出的tARMM模型在数据集上的预测准确度高于其他方法,能达到95%左右,对于其他具有时间依赖性的社会关系挖掘具有一定的借鉴意义和参考价值。

The invention discloses an implicit relationship discovery method based on deep learning, which belongs to the field of information technology, and specifically includes generating a paper co-authoring network G' from a scholar publishing network G; Co-authored the matrices X S , X D , X T ; proposed the RGRU model; designed and constructed a tARMM model based on RGRU to predict the "mentor-student" relationship. The prediction accuracy of the tARMM model proposed by the invention is higher than other methods on the data set, which can reach about 95%, and has certain reference significance and reference value for other time-dependent social relationship mining.
Description
技术领域technical field
本发明属于信息技术领域,具体涉及一种基于深度学习的隐含关系发现方法。The invention belongs to the field of information technology, and in particular relates to a deep learning-based implicit relationship discovery method.
背景技术Background technique
随着Facebook、Twitter、微信等社交媒体的普及和推广,社交媒体已经成为人们之间交流交互的重要平台。不同类型的社会关系对人有着不同的影响,人们的生活、学习和工作在这些关系的潜移默化之下发生着改变,比如在社交网络中,人们的喜好会受到朋友的影响,学生的研究方向会受到导师的影响。同时,在这些关系中还隐含着大量的额外信息,比如通过研究“导师-学生”关系,可以挖掘学术团体,建立科研社区网络,进一步了解相关研究课题的发展历程,找到下一步的发展方向。With the popularization and promotion of social media such as Facebook, Twitter and WeChat, social media has become an important platform for people to communicate and interact. Different types of social relationships have different effects on people, and people’s life, study and work are changing under the influence of these relationships. For example, in social networks, people’s preferences will be influenced by friends, and students’ research directions will be affected. Influenced by the teacher. At the same time, there is also a lot of additional information implied in these relationships. For example, by studying the "mentor-student" relationship, one can explore academic groups, establish a scientific research community network, further understand the development process of related research topics, and find the next development direction. .
网络中有很多的显式关系,如朋友关系、关注关系、评论关系、回复关系等,然而,也有很多关系是隐含在网络中的,如:“导师-学生”关系隐含在论文合著网络中。论文合著网络是科研人员在合作出版文献过程中逐渐形成的合作关系网络,比如DBLP。目前,有若干的项目以维护关系作为自己的目标,比如LinkedIn和AI家谱。前者要求用户对每一个特殊的对象进行标注,比如同事、导师、学生等,后者同样采用手工标注的方法对研究领域的导师信息进行标注。显然,这些方法大量依赖于人工的标注,不仅效率低,准确性也不高,这大大限制了其推广能力。对于这种现象一个理想的解决方案是设计一种方法,自动从网络中挖掘或预测出其中隐含的关系。There are many explicit relationships in the network, such as friend relationship, follow relationship, comment relationship, reply relationship, etc. However, there are also many relationships that are implicit in the network, such as: the "tutor-student" relationship is implicit in the co-authorship of the paper. in the network. The paper co-authorship network is a cooperative relationship network gradually formed by researchers in the process of co-publishing documents, such as DBLP. Currently, there are several projects whose goal is to maintain relationships, such as LinkedIn and AI genealogy. The former requires users to label each special object, such as colleagues, mentors, students, etc. The latter also uses manual labeling methods to label the mentor information in the research field. Obviously, these methods rely heavily on manual annotation, which is not only inefficient but also inaccurate, which greatly limits their generalization ability. An ideal solution to this phenomenon is to devise a method that automatically mines or predicts implicit relationships from the network.
在论文合著网络中,想要仅从出版名单中判断谁是导师是比较困难的。有时根据直觉的假设,采用启发式规则可以在某些社交网络中区分关系类型。但是,研究发现使用典型的启发式规则只能达到精度为70-80%,即使是使用基于多个不同特征训练的多个规则结合监督学习模型,精度平均仍然只有80%,而且,在实践训练中它往往是很难收集监督信息的。In a paper co-authorship network, it can be difficult to tell who is a supervisor just from the publication list. Using heuristic rules can sometimes distinguish relationship types in certain social networks, based on intuitive assumptions. However, the study found that using typical heuristic rules can only achieve an accuracy of 70-80%, even using multiple rules trained on multiple different features combined with a supervised learning model, the accuracy is still only 80% on average, and, in practice training It is often difficult to collect supervisory information.
论文合著网络中的“导师-学生”关系具有如下几个特性:The "mentor-student" relationship in the paper co-authorship network has the following characteristics:
1.隐含性。“导师-学生”关系是隐藏在论文合著网络中的,在论文合著网络中,只有论文的合作者、论文的题目、论文的发表时间、论文发表的刊物/会议等信息,无法显式地知道合作者之间的“导师-学生”关系。1. Implicit. The "mentor-student" relationship is hidden in the paper co-authoring network. In the paper co-authoring network, only the co-authors of the paper, the title of the paper, the publication time of the paper, the publication/conference where the paper was published, etc., cannot be explicitly published. Know the "mentor-student" relationship between collaborators.
2.时间依赖性。导师-学生关系具有高度的时间依赖性,对于任何一个作者来说,在其众多的合作者中,早期的合作者比后期的合作者更有可能是其导师。此外,一个人可以从学生的角色转化为导师角色,而这个角色转变可能没有任何明显的迹象。2. Time dependence. The mentor-student relationship is highly time-dependent. For any author, among its many collaborators, early collaborators are more likely to be their mentors than later ones. Furthermore, a person can transition from a student role to a mentor role without any visible signs of that role transition.
3.难推测性。由于论文合著网络仅具有合作出版论文的相关信息,与其他社交媒体相比是非常简单的,同时因为“导师-学生”关系隐藏在论文合著网络中,这就导致在论文合著网络中人工地去推断“导师-学生”关系是比较困难的。3. Hard to speculate. Since the paper co-authoring network only has relevant information about co-published papers, it is very simple compared to other social media, and because the "tutor-student" relationship is hidden in the paper co-authoring network, this leads to the It is difficult to infer the "tutor-student" relationship manually.
近年来,社交关系研究引起了学术界的广泛关注。当前对社交关系的研究工作可以分为三个方面:社交关系预测、社交关系类型识别和关系的交互预测。In recent years, the study of social relations has attracted extensive attention in the academic circles. The current research work on social relationships can be divided into three aspects: social relationship prediction, social relationship type identification and relationship interaction prediction.
社交关系预测,又称为链路预测,是指根据网络中节点的特征或已经存在的边,预测两个节点间存在边的可能性。Liben-Nowell等针对特定的社交网络,基于图的相似性度量方法计算节点之间的相似性,再利用该相似性预测节点之间的链接可能性。Lee等提出一种计算代价较小的基于社交向量时钟特征的模型来解决链接预测问题。Cunchao Tu等提出CANE模型,通过对用户相关的文本数据信息进行网络嵌入从而达到链路预测的目标。Backstrom等针对社交关系的强度问题提出了基于监督学习的随机游走算法。Zhao等提出一种基于“可靠路径”的预测方法,这是少数适用于加权网络的预测方法之一。Social relationship prediction, also known as link prediction, refers to predicting the possibility of an edge between two nodes based on the characteristics of nodes in the network or existing edges. For a specific social network, Liben-Nowell et al. calculated the similarity between nodes using a graph-based similarity measurement method, and then used the similarity to predict the link probability between nodes. Lee et al. proposed a computationally inexpensive model based on social vector clock features to solve the link prediction problem. Cuchao Tu et al. proposed the CANE model, which achieves the goal of link prediction by embedding the user-related text data information in the network. A random walk algorithm based on supervised learning was proposed by Backstrom et al. Zhao et al. proposed a prediction method based on "reliable paths", which is one of the few prediction methods suitable for weighted networks.
关系类型识别,是指针对一个或多个社交网络,自动地识别与挖掘出其中所蕴含的关系类型。Coppola等提出基于语义的自动关系挖掘框架。Leskovec等利用对数回归模型识别社交网络中的正关系或负关系,即朋友关系或非朋友关系。Diehl等使用学习排序函数识别“经理-下属”关系。Pentland等提出了几种obile数据挖掘模型,用于推测朋友关系。论文合著网络的“导师-学生”关系挖掘问题属于关系类型识别问题,在该问题上,唐杰等提出了TPFG模型用于从论文合著网络中挖掘“指导者-被指导者”关系,此外,他们面向异构网络(如邮件网络、科研合作网络等),提出一种基于因子图的统一框架,旨在解决社交关系类型的识别问题。李勇军等利用最大熵模型推测论文合著网络中的“导师-学生”关系。Relationship type identification refers to automatically identifying and mining the relationship types contained in one or more social networks. Coppola et al. proposed a semantic-based automatic relation mining framework. Leskovec et al. used a logarithmic regression model to identify positive or negative relationships in social networks, that is, friend relationships or non-friend relationships. Diehl et al. used a learned ranking function to identify "manager-subordinate" relationships. Pentland et al. proposed several obile data mining models for inferring friend relationships. The problem of "mentor-student" relationship mining in the paper co-authorship network belongs to the problem of relationship type identification. On this issue, Tang Jie et al. proposed a TPFG model to mine the "mentor-mentee" relationship from the paper co-authorship network. In addition, they propose a unified framework based on factor graphs for heterogeneous networks (such as email networks, scientific research collaboration networks, etc.), aiming to solve the identification problem of social relationship types. Li Yongjun et al. used the maximum entropy model to infer the "tutor-student" relationship in the paper co-authorship network.
关系交互预测,主要研究单向的社交关系怎样发展成双向的社交关系,以及其发生变化的原因。最常见的单向关系是明星和他们粉丝之间的关系,双向关系是朋友关系。Hopcroft等探索关系交互预测问题,Lou等研究社交关系是如何发展成为三元闭包的。他们共同提出一种将关系交互预测问题抽象为图的学习框架。Relationship interaction prediction mainly studies how a one-way social relationship develops into a two-way social relationship, and the reasons for its change. The most common one-way relationship is that between celebrities and their fans, and the two-way relationship is friendship. Hopcroft et al. explored the problem of relationship interaction prediction, and Lou et al. studied how social relationships developed into ternary closures. Together, they propose a learning framework that abstracts the relational interaction prediction problem as a graph.
发明内容SUMMARY OF THE INVENTION
针对现有技术中存在的上述技术问题,本发明提出了一种基于深度学习的隐含关系发现方法,设计合理,克服了现有技术的不足,具有良好的效果。In view of the above technical problems existing in the prior art, the present invention proposes a method for discovering implicit relationships based on deep learning, which has a reasonable design, overcomes the deficiencies of the prior art, and has good effects.
为了实现上述目的,本发明采用如下技术方案:In order to achieve the above object, the present invention adopts the following technical solutions:
一种基于深度学习的隐含关系发现方法,对隐含关系挖掘问题作出形式化的定义:An implicit relationship discovery method based on deep learning, which formally defines the implicit relationship mining problem:
定义1学者发表网络G
将时间依赖的学者发表网络形式化表示为一个二部图,令G=(A,P,E),其中


定义2论文合著网络G’Definition 2 Paper Co-authored Network G’
从G中生成




定义3论文合著矩阵CDefinition 3 Paper Co-authorship Matrix C
对于A中任意作者x,假设其与m位作者具有合著关系,合作者集合用Ax表示,Ax={b0,b1,b2,…,bm},其中b0=a0;若在某一年t中,x与bj合著的论文数为

其中,T为作者合作的总体时间域,本文以一年为一个时间跨度,若作者合著时间为[1970,2010],共40年,则在上述矩阵中T=39,合著矩阵C∈R(m+1)×40;Among them, T is the overall time domain of the author's cooperation. This article takes one year as a time span. If the author's co-authorship time is [1970, 2010], a total of 40 years, then in the above matrix T=39, the co-authorship matrix C∈ R (m+1)×40 ;
定义4导师学生关系RDefinition 4 Tutor-Student Relationship R
令R={yij|0<=i<=na,0<=j<=na},表示作者之间是否是“导师-学生”关系,其具体取值如下:Let R={y ij |0<=i<=n a , 0<=j<=n a }, indicating whether there is a "tutor-student" relationship between authors, and its specific values are as follows:

所述的基于深度学习的隐含关系发现方法,具体包括如下步骤:The described deep learning-based implicit relationship discovery method specifically includes the following steps:
Input:学者发表网络G;Input: Scholars publish network G;
Output:“导师-学生”关系的预测结果;Output: The predicted result of the "Tutor-Student" relationship;
步骤1:对学者发表网络G中的链接进行分析,从学者发表网络G中生成论文合著网络G’;Step 1: Analyze the links in the scholar's publication network G, and generate a paper co-authorship network G' from the scholar's publication network G;
步骤2:根据论文合著网络G’,计算论文发表情况矩阵C,D,S,进而计算论文的合著矩阵XS,XD,XT;Step 2: According to the paper co-authorship network G', calculate the paper publication matrix C, D, S, and then calculate the paper's co-author matrix X S , X D , X T ;
步骤3:建立tARMM(time-aware Advisor-advisee Relationship Mining Model,时间感知的导师学生关系挖掘模型)模型;Step 3: establish a tARMM (time-aware Advisor-advise Relationship Mining Model, time-aware advisor-student relationship mining model) model;
步骤4:通过tARMM模型对合著矩阵进行处理;Step 4: Process the co-authorship matrix through the tARMM model;
步骤4.1:使用RGRU计算概率PT;Step 4.1: Calculate probability P T using RGRU;
步骤4.2:使用DNN计算概率PF;Step 4.2: Calculate probability P F using DNN;
步骤4.3:计算最终的导师概率P;Step 4.3: Calculate the final mentor probability P;
步骤5:P中最大概率的候选导师即为x的预测导师,从而得到“导师-学生”关系的预测结果。Step 5: The candidate tutor with the highest probability in P is the predicted tutor of x, so as to obtain the prediction result of the "tutor-student" relationship.
优选地,在步骤2中,对于论文的合著情况,从如下两个方面进行分析:Preferably, in step 2, the co-authorship of the paper is analyzed from the following two aspects:
第一方面,从合著的详细情况进行分析,对于作者x,通过合著矩阵C表示x与其候选导师之间的合著论文发表情况;The first aspect is to analyze the details of the co-authorship. For the author x, the co-authorship matrix C is used to represent the publication of the co-authored papers between x and his candidate supervisor;
候选导师的论文发表情况用D表示:The publication status of candidate supervisors’ papers is denoted by D:


作者x的论文发表情况pnx用S表示:The publication situation of author x's paper pn x is represented by S:
S=(S0 … ST-1) (2.3);S = (S 0 ... S T-1 ) (2.3);

分别利用作者和候选导师的论文发表情况对合著矩阵C进行归一化处理:The co-authorship matrix C is normalized by the publications of the authors and candidate supervisors respectively:
XS=C·S (2.5);X S =C · S (2.5);
XD=D·S (2.6);X D = D · S (2.6);
其中,XS为基于学生的合著子矩阵,XSij∈XS,表示在第j年中作者x与其候选导师bi合著论文数占作者x第j年总论文数的比例;XD为基于导师的合著子矩阵,XDij∈XD,表示在第j年中作者x与其候选导师bi合著论文数占候选导师bi第j年总论文数的比例;Among them, X S is the co-authored sub-matrix based on students, X Sij ∈ X S , indicating the ratio of the number of papers co-authored by author x and his candidate supervisor bi to the total number of papers of author x in year j in the jth year; X D is the co-authored submatrix based on the supervisor, X Dij ∈ X D , which represents the proportion of the number of papers co-authored by the author x and his candidate supervisor bi in the jth year to the total number of papers in the jth year by the candidate supervisor bi;
第二方面,从合著的时间角度出发,根据合著矩阵C将合著情况的时间结构以矩阵的形式进行表示,具体定义如下:In the second aspect, from the perspective of co-authoring time, the time structure of co-authoring situations is represented in the form of a matrix according to the co-authoring matrix C, which is specifically defined as follows:


XT为基于时间结构的合著子矩阵,其含义是用矩阵的形式表示作者x与其候选导师bi之间合著论文的时间结构。X T is a co-authorship sub-matrix based on time structure, which means that the time structure of co-authored papers between author x and his candidate supervisor b i is represented in the form of a matrix.
优选地,在步骤4.1中,在tARMM模型中,对RNN(Recursive Neural Network,循环神经网络)进行改造,生成更新门循环单元RGRU(Refresh Gate Recurrent Unit,更新门循环单元),通过更新门循环单元RGRU,对XT进行处理,得到导师概率PT;Preferably, in step 4.1, in the tARMM model, the RNN (Recursive Neural Network, Recurrent Neural Network) is transformed to generate an update gate recurrent unit RGRU (Refresh Gate Recurrent Unit, update gate recurrent unit), by updating the gate recurrent unit RGRU, process X T to obtain the mentor probability P T ;
对于时刻t,有:For time t, there are:
rt=σ(wrht+1+whxt+br) (2.9);r t =σ(w r h t+1 +w h x t + br ) (2.9);
ht=(1-rt)ht+1+rtxt (2.10);h t =(1-r t )h t+1 +r t x t (2.10);
其中,σ指的是sigmoid激活函数,rt是更新门在时间t的状态,wrwr和wh均为更新门的权重矩阵,br是更新门的偏移量,ht+1是更新门单元在时刻t+1的状态,xt是时刻t的输入矩阵,ht是更新门单元在时间t的状态;Among them, σ refers to the sigmoid activation function, r t is the state of the update gate at time t, w r w r and w h are the weight matrices of the update gate, b r is the offset of the update gate, h t+1 is the state of the update gate unit at
基于RGRU的导师概率PT:RGRU-based mentor probability P T :
PT=hT (2.11);P T =h T (2.11);
其中,hT是更新门单元在时间T的状态;其公式与ht相同;Among them, h T is the state of the update gate unit at time T; its formula is the same as h t ;
具体步骤如下:Specific steps are as follows:
Input:论文合著矩阵XT;Input: paper co-author matrix X T ;
Output:基于RGRU的导师概率PT;Output: RGRU-based mentor probability P T ;
步骤4.1.1:初始化PT为零矩阵;Step 4.1.1: Initialize P T to zero matrix;
步骤4.1.2:通过公式(2.9)计算t年的更新门的状态rt;Step 4.1.2: Calculate the state r t of the update gate in year t by formula (2.9);
步骤4.1.3:通过公式(2.10)计算t年的更新门单元的状态ht;Step 4.1.3: Calculate the state h t of the update gate unit in year t by formula (2.10);
步骤4.1.4:通过公式(2.11)计算x的导师概率PT。Step 4.1.4: Calculate the mentor probability P T of x by formula (2.11).
优选地,在步骤4.2中,通过tARMM模型,采用深度神经网络,对XS、XD进行处理,得到基于类图矩阵的导师概率PF;Preferably, in step 4.2, through the tARMM model, a deep neural network is used to process X S and X D to obtain a mentor probability P F based on the class diagram matrix;
将XS和XD进行组合,构成一个双颜色通道的位图,称之为类图矩阵X;目标是发现类图矩阵X中的特定图形所在的行号;由于这是一个像素级的目标定位问题,所以构建一个DNN进行识别,根据感知器的计算公式,对于DNN中的每一个节点,其输出为:Combine X S and X D to form a two-color channel bitmap, which is called the class diagram matrix X; the goal is to find the row number of the specific graphic in the class diagram matrix X; since this is a pixel-level target Positioning problem, so build a DNN for identification, according to the calculation formula of the perceptron, for each node in the DNN, the output is:

其中,wi,b为模型的权重与偏移量参数,pi为每个节点预测出的概率值;Among them, w i , b are the weight and offset parameters of the model, and p i is the probability value predicted by each node;
则DNN最终产生的基于类图矩阵的导师概率PF为DNN最后一层的输出:Then the tutor probability P F based on the class graph matrix finally generated by DNN is the output of the last layer of DNN:
PF=Relu(f(XS,XD)) (2.13);P F =Relu(f(X S ,X D )) (2.13);
具体步骤如下:Specific steps are as follows:
Input:论文合著矩阵XS和XD;Input: paper co-author matrix X S and X D ;
Output:基于类图矩阵的导师概率PF;Output: tutor probability P F based on class diagram matrix;
步骤4.2.1:初始化PF为零矩阵;Step 4.2.1: Initialize PF to zero matrix;
步骤4.2.2:通过公式(2.12)计算DNN中每个节点的输出;Step 4.2.2: Calculate the output of each node in the DNN by formula (2.12);
步骤4.2.3:通过公式(2.13)计算概率PF。Step 4.2.3: Calculate probability PF by formula ( 2.13 ).
优选地,在步骤4.3中,将PT和PF通过全连接层生成最终的导师概率矩阵,从中选取最高的概率值P,其对应的候选导师即为x的预测导师;Preferably, in step 4.3, the final mentor probability matrix is generated by PT and PF through the fully connected layer, and the highest probability value P is selected from it, and the corresponding candidate mentor is the predicted mentor of x;
P=σ(PF·PT) (2.14)。P=σ(P F · P T ) (2.14).
本发明所带来的有益技术效果:Beneficial technical effects brought by the present invention:
本发明借鉴了长短时记忆模型(LSTM)和逻辑门循环单元(GRU)等变体循环神经网络(RNN)模型的理论,将RNN进行改造,提出更新门循环单元(RGRU),用于处理合著矩阵中的时间结构;由于RGRU仅具有一个门单元,在结构上比LSTM和GRU更简单,但在“导师-学生”关系的挖掘问题上具有更高的准确性;The invention draws on the theory of the variant cyclic neural network (RNN) model such as the long short-term memory model (LSTM) and the logic gate recurrent unit (GRU), transforms the RNN, and proposes an update gate recurrent unit (RGRU) for processing co-authored Temporal structure in the matrix; since RGRU has only one gate unit, it is structurally simpler than LSTM and GRU, but has higher accuracy on the problem of mining the "mentor-student" relationship;
本发明采用深度学习的思想处理论文合著网络中的“导师-学生”关系挖掘问题,提出时间依赖的“导师-学生”关系挖掘神经网络(tARMM),该模型在数据集上的预测准确度高于其他方法,能达到95%左右,对于其他具有时间依赖性的社会关系挖掘具有一定的借鉴意义和参考价值。The invention adopts the idea of deep learning to deal with the problem of "mentor-student" relationship mining in the paper co-authoring network, and proposes a time-dependent "mentor-student" relationship mining neural network (tARMM), which can predict the accuracy of the model on the data set. Compared with other methods, it can reach about 95%, which has certain reference significance and reference value for other time-dependent social relationship mining.
附图说明Description of drawings
图1为“导师-学生”关系挖掘示意图。Figure 1 is a schematic diagram of the "mentor-student" relationship mining.
图2为tARMM示意图。Figure 2 is a schematic diagram of tARMM.
图3为RGRU示意图。FIG. 3 is a schematic diagram of the RGRU.
图4(a)为XS的类图矩阵示意图。Figure 4(a) is a schematic diagram of the class diagram matrix of XS .
图4(b)为XD的类图矩阵示意图。Figure 4(b) is a schematic diagram of the class diagram matrix of XD .
图5为DNN示意图。Figure 5 is a schematic diagram of the DNN.
图6为全连接层示意图。Figure 6 is a schematic diagram of a fully connected layer.
具体实施方式Detailed ways
下面结合附图以及具体实施方式对本发明作进一步详细说明:The present invention is described in further detail below in conjunction with the accompanying drawings and specific embodiments:
1、问题的形式化定义1. Formal definition of the problem
在这部分,给出本文中的一些基础符号和定义。In this part, some basic symbols and definitions in this paper are given.
表1.1主要的符号及其含义Table 1.1 Main symbols and their meanings

定义1学者发表网络G
将时间依赖的学者发表网络形式化表示为一个二部图,令G=(A,P,E),其中


定义2论文合著网络G’Definition 2 Paper Co-authored Network G’
从G中生成




定义3论文合著矩阵CDefinition 3 Paper Co-authorship Matrix C
对于A中任意一作者x,假设其与m位作者具有合著关系,合作者集合用Ax表示,Ax={b0,b1,b2,…,bm},其中b0=a0。若在某一年t中,x与bj合著的论文数为

其中,T为作者合作的总体时间域,本文以一年为一个时间跨度,若作者合著时间为[1970,2010],共40年,则在上述矩阵中T=39,合著矩阵C∈R(m+1)×40。Among them, T is the overall time domain of the author's cooperation. This article takes one year as a time span. If the author's co-authorship time is [1970, 2010], a total of 40 years, then in the above matrix T=39, the co-authorship matrix C∈ R (m+1)×40 .
定义4导师学生关系RDefinition 4 Tutor-Student Relationship R
令R={yij|0<=i<=na,0<=j<=na},表示作者之间是否是“导师-学生”关系,其具体取值如下:Let R={y ij |0<=i<=n a , 0<=j<=n a }, indicating whether there is a "tutor-student" relationship between authors, and its specific values are as follows:

本文的研究目标就是从C中预测出x的导师yx,这需要解决谁是x的导师、以多大的概率为x的导师这两个问题。The research goal of this paper is to predict the mentor y x of x from C, which needs to solve the two problems of who is the mentor of x and what probability is the mentor of x.
2模型构建2 Model building
2.1合著矩阵的构建2.1 Construction of co-authorship matrix
为了挖掘“导师-学生”关系,首先从原始的学者发表网络G中生成论文合著网络G’,然后从中提取合著矩阵((如图1示))。In order to mine the "mentor-student" relationship, the paper co-authorship network G' is firstly generated from the original scholar publication network G, and then the co-authorship matrix (as shown in Figure 1) is extracted from it.
对于论文的合著情况,可以从如下两个方面进行分析:For the co-authorship of the paper, it can be analyzed from the following two aspects:
第一方面从合著的详细情况进行分析,对于作者x,有合著矩阵C表示x与其候选导师之间的合著论文发表情况。The first aspect analyzes the details of the co-authorship. For an author x, there is a co-authorship matrix C that represents the publication of co-authored papers between x and his candidate supervisors.
候选导师的论文发表情况用D表示:The publication status of candidate supervisors’ papers is denoted by D:


作者x的论文发表情况pnx用S表示:The publication situation of author x's paper pn x is represented by S:
S=(S0 … ST-1) (2.3);S = (S 0 ... S T-1 ) (2.3);

于是,分别利用作者和候选导师的论文发表情况对合著矩阵C进行归一化处理:Therefore, the co-authorship matrix C is normalized by using the papers published by the authors and candidate supervisors respectively:
XS=C·S (2.5);X S =C · S (2.5);
XD=D·S (2.6);X D = D · S (2.6);
XS和XD分别为基于学生的合著子矩阵和基于导师的合著子矩阵。对于XSij∈XS,表示在第j年中作者x与其候选导师bi合著论文数占作者x第j年总论文数的比例。XDij∈XD表示在第j年中作者x与其候选导师bi合著论文数占候选导师bi第j年总论文数的比例。X S and X D are the student-based co-authorship sub-matrix and the tutor-based co-author sub-matrix, respectively. For X Sij ∈ X S , it represents the ratio of the number of papers co-authored by author x and his candidate supervisor bi in the jth year to the total number of papers of the author x in the jth year. X Dij ∈ X D represents the ratio of the number of papers co-authored by author x and his candidate supervisor bi in the jth year to the total number of papers in the jth year by the candidate supervisor bi.
第二方面,从合著的时间角度出发,根据合著矩阵C将合著情况的时间结构以矩阵的形式进行表示,具体定义如下:In the second aspect, from the perspective of co-authoring time, the time structure of co-authoring situations is represented in the form of a matrix according to the co-authoring matrix C, which is specifically defined as follows:


XT成为基于时间结构的合著子矩阵,其含义是用矩阵的形式表示作者x与其候选导师之间合著论文的时间结构。X T becomes a co-authorship sub-matrix based on time structure, which means that the time structure of co-authored papers between author x and his candidate supervisor is represented in the form of a matrix.
2.2时间依赖的关系挖掘模型构建2.2 Time-dependent relationship mining model construction
本节我们提出一种时间依赖的关系挖掘神经网络模型tARMM(如图2所示),该模型通过分别对XT和XS、XD进行处理,得到基于时间结构和基于类图矩阵的导师概率矩阵,然后通过全连接层生成最终的导师概率矩阵。在对XT进行处理时,设计逆时间的更新门循环单元,对于XS和XD进行处理时,采用深度神经网络。In this section, we propose a time-dependent relation mining neural network model tARMM (as shown in Figure 2), which processes X T and X S and X D respectively to obtain a mentor based on time structure and class diagram matrix. probability matrix, and then generate the final tutor probability matrix through the fully connected layer. When processing X T , a reverse-time update gate cyclic unit is designed, and when processing X S and X D , a deep neural network is used.
2.2.1基于RGRU的概率计算方法2.2.1 Probability calculation method based on RGRU
本文在标准RNN基础上增设一更新门单元,形成只有一个更新门的循环神经网络,称之为更新门循环单元RGRU(如图3所示)。对于基于发表时间的合著矩阵XT,通过公式(2.7)可知在矩阵中,非0元素所在列越靠前,则所在行表征的候选导师具备更高的导师概率。所以将矩阵XT以列为单位反向经RGRU处理,得到基于RGRU的导师概率矩阵。In this paper, an update gate unit is added on the basis of the standard RNN to form a recurrent neural network with only one update gate, which is called the update gate recurrent unit RGRU (as shown in Figure 3). For the co-authorship matrix X T based on publication time, formula (2.7) shows that in the matrix, the higher the column where the non-zero element is located, the higher the probability of the candidate mentor represented by the row. Therefore, the matrix X T is reversely processed by RGRU in units of columns, and the RGRU-based tutor probability matrix is obtained.
对于时刻t,有:For time t, there are:
rt=σ(wrht+1+whxt+br) (2.9);r t =σ(w r h t+1 +w h x t + br ) (2.9);
ht=(1-rt)ht+1+rtxt (2.10);h t =(1-r t )h t+1 +r t x t (2.10);
其中,rt是更新门在时间t的状态,wrwh均为更新门的权重矩阵,br是更新门的偏移量,ht+1是更新门单元在时刻t+1的状态,xt是时刻t的输入矩阵,ht是更新门单元在时间t的状态;Among them, r t is the state of the update gate at time t, w r w h is the weight matrix of the update gate, b r is the offset of the update gate, and h t+1 is the state of the update gate unit at
基于RGRU的导师概率PT:RGRU-based mentor probability P T :
PT=hT (2.11);P T =h T (2.11);
其中,hT是更新门单元在时间T的状态;hT公式与ht相同。Among them, h T is the state of the update gate unit at time T; the formula of h T is the same as that of h t .
综上所述,基于改进的更新门循环单元(RGRU)的导师概率计算如算法1所示。To sum up, the mentor probability calculation based on the modified update gate recurrent unit (RGRU) is shown in


2.2.2基于类图矩阵的概率计算方法2.2.2 Probability calculation method based on class diagram matrix
XS和XD分别从学生和候选导师两方面表征合著情况。以XS为例,将基于学生的合著矩阵看作是66×40的灰度图,采取位图方式进行显示,可以发现当其中某一行所表征的候选导师为实际导师时,在该行中会存在连续的一段像素值构成类似于“一”的特殊图像,但是在不同的位图中具有不同的特征,所以本文通过深度神经网络对位图进行处理,提取其特征矩阵,挖掘特殊图像所在的位置。图4(a)为XS类图矩阵;图4(b)为XD类图矩阵。X S and X D characterize the co-authorship situation from the perspective of students and candidate supervisors, respectively. Taking XS as an example, the student-based co-authorship matrix is regarded as a 66×40 grayscale image and displayed in bitmap mode. It can be found that when the candidate tutor represented by a row is the actual tutor, the There will be a continuous segment of pixel values that constitute a special image similar to "one", but have different characteristics in different bitmaps, so this paper processes the bitmap through a deep neural network, extracts its feature matrix, and mines special images. the location. Figure 4(a) is the XS class diagram matrix; Figure 4(b) is the XD class diagram matrix.
将XS和XD进行组合,构成一个双颜色通道的位图,称之为类图矩阵X。所以下一步的目标是发现类图矩阵X中的特定图形所在的行号。由于这是一个像素级的目标定位问题,所以构建一个DNN(如图5所示)进行识别。根据感知器的计算公式,对于DNN中的每一个节点,其输出为:Combine X S and X D to form a two-color channel bitmap, which is called the class map matrix X. So the goal of the next step is to discover the row number of a particular figure in the class diagram matrix X. Since this is a pixel-level object localization problem, a DNN (as shown in Figure 5) is constructed for recognition. According to the calculation formula of the perceptron, for each node in the DNN, its output is:

令y′为DNN中最后一层的输出。则DNN最终产生的基于类图矩阵的导师概率PF为:Let y' be the output of the last layer in the DNN. Then the tutor probability P F based on the class diagram matrix finally generated by DNN is:
PF=Relu(f(XS,XD))=y′ (2.13);P F =Relu(f(X S ,X D ))=y'(2.13);
综上所述,DNN的实现过程可以使用如下算法描述。In summary, the implementation process of DNN can be described by the following algorithm.


最后,将PT和PF通过全连接层(如图6所示)生成最终的导师概率矩阵,从中选取最高的概率值,其对应的候选导师即为预测的导师。Finally, the final mentor probability matrix is generated by PT and PF through the fully connected layer (as shown in Figure 6), and the highest probability value is selected from it, and the corresponding candidate mentor is the predicted mentor.
P=σ(PF·PT) (2.14);P=σ(P F ·P T ) (2.14);
2.3模型的学习算法2.3 Learning algorithm of the model
本部分将介绍模型的学习算法,包括损失函数和参数的更新方法。本文所提的模型采用交叉熵作为损失函数,具体如下:This section will introduce the learning algorithm of the model, including the loss function and parameter update method. The model proposed in this paper uses cross entropy as the loss function, as follows:

在参数的更新方面,本文是在所有的参数均被初始化之后,采用Adam方法去优化参数。Adam方法是一种自适应学习率的学习方法,可以为每个参数计算自己的学习率。其公式如下:In terms of parameter update, this paper adopts Adam method to optimize parameters after all parameters are initialized. The Adam method is an adaptive learning rate learning method that calculates its own learning rate for each parameter. Its formula is as follows:
mt=β1mt-1+(1-β1)gt (2.16);m t =β 1 m t-1 +(1-β 1 )g t (2.16);




其中,mt是对梯度的一阶矩估计,可以看作是对期望E|gt|的估计,vt是对矩阵的二阶矩估计,可以看作是对期望

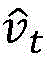

2.4算法描述2.4 Algorithm Description
本文提出的tARMM模型的完整算法描述如下:The complete algorithm of the tARMM model proposed in this paper is described as follows:


3实验设计与分析3 Experimental design and analysis
3.1实验设置3.1 Experimental setup
数据集。使用Michael Ley开发的DBLP计算机科学文献数据库作为实验的数据集去推测其中的“导师-学生”关系。选取其中从1970到2010年的部分,它包含有654628位作者和1076946篇出版物。作为标签数据,使用MAN,MathGP,AIGP三个数据集的并集作为验证数据集,其中MAN是通过在导师的个人主页上面爬取获得的,MathGP是从MathematicsGenealogy项目中爬取获得,AIGP是从AI Genealogy项目中爬取获得。data set. The DBLP computer science literature database developed by Michael Ley was used as the experimental data set to infer the "mentor-student" relationship. Taking the section from 1970 to 2010, it contains 654,628 authors and 1,076,946 publications. As label data, the union of MAN, MathGP, and AIGP datasets is used as the validation dataset, where MAN is obtained by crawling on the tutor's personal homepage, MathGP is obtained by crawling from the MathematicsGenealogy project, and AIGP is obtained from Crawled from the AI Genealogy project.
做了一系列的实验去探索模型在“导师-学生”关系挖掘问题上的正确性和有效性。随机从数据集中选择部分数据对模型进行训练,然后再从数据集中随机抽取数据集进行测试。A series of experiments are done to explore the correctness and effectiveness of the model on the problem of "mentor-student" relationship mining. Randomly select some data from the dataset to train the model, and then randomly select a dataset from the dataset for testing.
为了直观地比较推测结果,本文使用分类算法最常用的评价指标:准确率ACC,其计算公式如下:In order to compare the predicted results intuitively, this paper uses the most commonly used evaluation index for classification algorithms: the accuracy rate ACC, whose calculation formula is as follows:

其中,TP为真正例个数,FP为假正例个数。Among them, TP is the number of true examples, and FP is the number of false positive examples.
实验环境为:Intel Core i5-2520M双核(2.5GHz),windows10 64位,8G内存,NVIDA GeForce GT635M显卡。编程语言为:Matlab和Python,使用TensorFlow框架。The experimental environment is: Intel Core i5-2520M dual-core (2.5GHz), windows10 64-bit, 8G memory, NVIDIA GeForce GT635M graphics card. The programming languages are: Matlab and Python, using the TensorFlow framework.
3.2编程技术3.2 Programming techniques
数据预处理阶段采用Matlab编写代码,tARMM模型实现部分采用python进行编写,该部分使用了TensorFlow机器学习框架。结果的展示部分采用JavaWeb实现,网页端主要采用了百度开源的ECharts组件。The data preprocessing stage uses Matlab to write the code, and the tARMM model implementation part is written in python, which uses the TensorFlow machine learning framework. The display part of the results is implemented by JavaWeb, and the open source ECharts component of Baidu is mainly used on the web page.
(1)TensorFlow(1) TensorFlow
TensorFlow是Google开源的第二代用于数字计算的软件库,它是一个非常灵活的机器学习框架,能够运行在服务器或个人电脑甚至移动设备的单个或多个CPU和GPU上。TensorFlow is Google's open-source second-generation software library for numerical computing. It is a very flexible machine learning framework that can run on single or multiple CPUs and GPUs on servers or personal computers and even mobile devices.
TensorFlow是基于数据流图的处理框架,数据流图中的节点表示数学运算,边表示运算节点之间的数据交互。TensorFlow中Tensor表示节点之间传输的数据,Flow表示数据流,就是Tensor按照流的形式进入数据运算图的各个节点。TensorFlow is a processing framework based on data flow graphs. The nodes in the data flow graph represent mathematical operations, and the edges represent the data interaction between operation nodes. In TensorFlow, Tensor represents the data transmitted between nodes, and Flow represents the data flow, that is, Tensor enters each node of the data operation graph in the form of a flow.
在编程时需要使用图(graph)表示计算任务,然后在称为会话(Session)的上下文(Context)中执行图,同时,使用tensor表示数据,通过变量(Variable)维护状态,使用feed或者fetch为任意操作赋值或者从中获取数据。When programming, you need to use a graph to represent computing tasks, and then execute the graph in a context called a session. At the same time, use tensor to represent data, maintain state through variables, and use feed or fetch as Arbitrary operations assign values or get data from them.
(2)Echarts(2)Echarts
Echarts是一个纯javascript的图标库,将其嵌入到html网页当中,可以在计算机和移动设备上流畅运行,兼容当前绝大多数的浏览器,底层实现依赖于轻量级的Canvas类库Zrender,提供生动、直观、可交互、可高度个性化的数据可视化图标。文本使用Echarts用于实验结果的展示。Echarts is a pure javascript icon library, which can be embedded in html web pages and can run smoothly on computers and mobile devices. It is compatible with most current browsers. The underlying implementation relies on the lightweight Canvas class library Zrender, which provides Vivid, intuitive, interactive, and highly personalizable data visualization icons. The text uses Echarts for the presentation of experimental results.
3.3实验结果3.3 Experimental results
对于深度学习来说,不同的优化方法将会对训练的效率和有效性有不同的影响。一般来说,普遍使用梯度下降法作为模型的训练方法。梯度下降又有多种分类,其中批量梯度下降法BGD是梯度下降法中最原始的形式,具体思路是使用所有的样本来更新每一个参数。由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的增加而变得越来越缓慢。随机梯度下降法SGD正是为了解决批量梯度下降法这一弊端而提出的,本文即采用了随机梯度下降法来训练模型。For deep learning, different optimization methods will have different effects on the efficiency and effectiveness of training. In general, gradient descent is commonly used as a training method for models. Gradient descent has a variety of classifications. Among them, batch gradient descent method BGD is the most primitive form of gradient descent method. The specific idea is to use all samples to update each parameter. Since batch gradient descent requires all training samples to update each parameter, the training process becomes slower and slower as the number of samples increases. The stochastic gradient descent method SGD is proposed to solve the drawback of the batch gradient descent method. This paper adopts the stochastic gradient descent method to train the model.
3.3.1 RGRU的有效性3.3.1 Effectiveness of RGRU
为了证明RGRU的有效性,单独使用RNN、LSTM和更新门循环单元RGRU进行试验,得到的结果如下:To demonstrate the effectiveness of RGRU, experiments were conducted with RNN, LSTM and update gate recurrent unit RGRU alone, and the results were as follows:
表3.2不同神经网络的表现Table 3.2 Performance of Different Neural Networks

通过实验可以看出RGRU比单纯的循环神经网络和长短时记忆模型在“导师-学生”关系的挖掘问题上具有更高的准确性。证明对循环神经网络的改进是正确有效的。Through experiments, it can be seen that RGRU has higher accuracy than the simple recurrent neural network and long-short-term memory model in the problem of "mentor-student" relationship mining. Prove that the improvements to the recurrent neural network are correct and effective.
3.3.2 tARMM与其他算法的比较3.3.2 Comparison of tARMM with other algorithms
在该部分,选取针对“导师-学生”关系问题提出的TPFG模型和用于分类的SVM模型与本文提出的tARMM模型作对比。进行多次试验,取平均值,结果如下:In this part, the TPFG model and the SVM model for classification proposed for the "mentor-student" relationship are selected for comparison with the tARMM model proposed in this paper. Carry out multiple tests and take the average value. The results are as follows:
表3.3不同算法的结果比较Table 3.3 Comparison of Results of Different Algorithms

通过实验可以看出,tARMM模型的准确率是高于SVM和TPFG的,进一步证明tARMM模型的正确性。It can be seen through experiments that the accuracy of the tARMM model is higher than that of SVM and TPFG, which further proves the correctness of the tARMM model.
4总结与展望4 Summary and Outlook
本文研究了论文合著网络中“导师-学生”关系的识别问题。针对该问题,首先通过对数据的预处理生成合著矩阵,然后建立tARMM模型处理合著矩阵挖掘“导师-学生”关系。在tARMM模型中对RNN进行改造生成RGRU,该单元可挖掘具有时间依赖性的关系。利用DBLP中的数据进行实验,证明了tARMM模型的正确性和有效性。This paper investigates the problem of identifying “mentor-student” relationships in paper co-authorship networks. To solve this problem, firstly, the co-authorship matrix is generated by preprocessing the data, and then a tARMM model is established to process the co-authorship matrix to mine the "mentor-student" relationship. The RNN is transformed in the tARMM model to generate RGRU, a unit that mines time-dependent relationships. Experiments using the data in DBLP demonstrate the correctness and effectiveness of the tARMM model.
在该研究中,由于带标签的数据集无法涵盖整个DBLP数据库,所以存在一定的误差。对此,后期将通过扩大带标签的数据集对模型进行改进,提高模型的准确性。同时,本模型对具有时间依赖性的社会关系具有一定的拓展性,后期将针对不同的社交媒体对模型做进一步的改进,提高模型的通用性。In this study, there is a certain error because the labeled dataset cannot cover the entire DBLP database. In this regard, the model will be improved by expanding the labeled dataset in the later stage to improve the accuracy of the model. At the same time, this model has certain expansibility for time-dependent social relations, and the model will be further improved for different social media in the later stage to improve the generality of the model.
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。Of course, the above description is not intended to limit the present invention, and the present invention is not limited to the above examples. Changes, modifications, additions or substitutions made by those skilled in the art within the essential scope of the present invention should also belong to the present invention. The scope of protection of the invention.
Claims (1)
















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711469074.XA CN108228782B (en) | 2017-12-29 | 2017-12-29 | A Deep Learning-Based Approach for Implicit Relationship Discovery |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711469074.XA CN108228782B (en) | 2017-12-29 | 2017-12-29 | A Deep Learning-Based Approach for Implicit Relationship Discovery |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108228782A CN108228782A (en) | 2018-06-29 |
| CN108228782B true CN108228782B (en) | 2020-04-21 |
Family
ID=62646745
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201711469074.XA Active CN108228782B (en) | 2017-12-29 | 2017-12-29 | A Deep Learning-Based Approach for Implicit Relationship Discovery |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108228782B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110008279B (en) * | 2019-03-27 | 2021-03-23 | 北京工商大学 | A Visual Analysis Method and Application Based on "Relation-Weight" Ordered Matrix |
| CN111126758B (en) * | 2019-11-15 | 2023-09-29 | 中南大学 | An academic team influence spread prediction method, equipment and storage medium |
| CN112148776B (en) * | 2020-09-29 | 2024-05-03 | 清华大学 | Academic relationship prediction method and device based on neural network introducing semantic information |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106170800A (en) * | 2014-09-12 | 2016-11-30 | 微软技术许可有限责任公司 | Student DNN is learnt via output distribution |
| CN106557809A (en) * | 2015-09-30 | 2017-04-05 | 富士通株式会社 | Nerve network system and the method is trained by the nerve network system |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10783900B2 (en) * | 2014-10-03 | 2020-09-22 | Google Llc | Convolutional, long short-term memory, fully connected deep neural networks |
-
2017
- 2017-12-29 CN CN201711469074.XA patent/CN108228782B/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106170800A (en) * | 2014-09-12 | 2016-11-30 | 微软技术许可有限责任公司 | Student DNN is learnt via output distribution |
| CN106557809A (en) * | 2015-09-30 | 2017-04-05 | 富士通株式会社 | Nerve network system and the method is trained by the nerve network system |
Non-Patent Citations (1)
| Title |
|---|
| Identifying advisor-advisee relationships from co-author networks via a novel deep model;Zhongying Zhao 等;《Information Sciences》;20180727;第466卷;258–269页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108228782A (en) | 2018-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zhu et al. | Understanding place characteristics in geographic contexts through graph convolutional neural networks | |
| Cao et al. | Big data: A parallel particle swarm optimization-back-propagation neural network algorithm based on MapReduce | |
| US10303771B1 (en) | Utilizing machine learning models to identify insights in a document | |
| Hopcroft et al. | Who will follow you back? reciprocal relationship prediction | |
| Gou et al. | Learning sequential features for cascade outbreak prediction | |
| Feng et al. | A hierarchical multi-label classification method based on neural networks for gene function prediction | |
| Abbas et al. | Predicting the future popularity of academic publications using deep learning by considering it as temporal citation networks | |
| Masrur et al. | Interpretable machine learning for analysing heterogeneous drivers of geographic events in space-time | |
| Li et al. | The attribute-trend-similarity method to improve learning performance for small datasets | |
| Patel et al. | An improved fuzzy k-nearest neighbor algorithm for imbalanced data using adaptive approach | |
| Lerner et al. | Investigation of the K2 algorithm in learning Bayesian network classifiers | |
| Dang et al. | Link-sign prediction in dynamic signed directed networks | |
| Hu et al. | A community partitioning algorithm based on network enhancement | |
| CN108228782B (en) | A Deep Learning-Based Approach for Implicit Relationship Discovery | |
| Kakkar et al. | Enhancing energy efficiency and classification modeling through a combined approach of LightGBM and stratified kfold cross-validation | |
| Son et al. | Applying network link prediction in drug discovery: an overview of the literature | |
| Ye | Entropy measures of simplified neutrosophic sets and their decision-making approach with positive and negative arguments | |
| Deng et al. | GCN-based weakly-supervised community detection with updated structure centres selection | |
| Nural et al. | Automated predictive big data analytics using ontology based semantics | |
| Lekkas et al. | Using passive sensor data to probe associations of social structure with changes in personality: A synthesis of network analysis and machine learning | |
| Linares-Mustaros et al. | Processing extreme values in sales forecasting | |
| Li et al. | CRNN: Integrating classification rules into neural network | |
| Chu et al. | Relationships between geo-spatial features and COVID-19 hospitalisations revealed by machine learning models and SHAP values | |
| Liu et al. | A data classification method based on particle swarm optimisation and kernel function extreme learning machine | |
| Dalal | Understanding hidden neuron activations using structured background knowledge and deductive reasoning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |