CN107085616B - Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 - Google Patents
Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 Download PDFInfo
- Publication number
- CN107085616B CN107085616B CN201710397805.8A CN201710397805A CN107085616B CN 107085616 B CN107085616 B CN 107085616B CN 201710397805 A CN201710397805 A CN 201710397805A CN 107085616 B CN107085616 B CN 107085616B
- Authority
- CN
- China
- Prior art keywords
- node
- lbsn
- places
- abnormal
- competition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/29—Graphical models, e.g. Bayesian networks
- G06F18/295—Markov models or related models, e.g. semi-Markov models; Markov random fields; Networks embedding Markov models
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明公开了LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其步骤为:首先对存在虚假评论活动的可疑地点进行标注;其次基于LBSN的地点评分、时空属性和地点评论的文本内容,针对地点的整体评论异常与地点间恶意竞争的关系,进行异常特征的提取;采用逻辑斯蒂回归机器学习方法进行训练学习,获得每个地点的异常程度与两个地点之间的竞争程度;然后基于地点与地点间竞争关系构建马尔科夫随机场检测模型,将地点和地点间竞争关系的异常特征与LBSN网络拓扑相融合;基于检测模型,计算任意地点为可疑地点的概率;最终标注地点是否为存在虚假评论活动的可疑地点。该检测方法大幅提高了检测虚假评论活动的可疑地点的准确率。
Description
技术领域
本发明涉及到LBSN中一种基于多维属性挖掘的虚假评论可疑地点的检测方法。
背景技术
近年来,随着移动终端定位技术和移动互联网技术的快速发展,基于位置的社交网络即LBSN(全称为Location-Based Social Networks)平台取得了巨大的成功。LBSN通过位置特征将虚拟社交空间和现实行为空间连接起来,融合了线上关系与线下行为,用户可以依赖线上网络针对空间地点发布评论,线下依靠这些评论来探索发现新的地点,并对这些地点进行选择性访问、消费或者服务。然而,LBSN平台上海量的信息中存在各种虚假评论,其多为组织性的虚假评论活动,这类活动通过发布多条虚假评论以改变地点的口碑,从而影响用户的访问决策,为地点商家攫取不法利益,同时破坏网络环境,严重影响用户体验与网络信誉。因此,识别与检测这部分存在虚假评论活动的可疑地点具有重要的现实意义。
当前关于虚假评论活动的商家的检测技术主要是针对传统的电子商务网站,对于LBSN中存在虚假评论活动的可疑地点的检测研究较少,并且没有研究考虑地点商家之间的竞争性导致的虚假评论活动。在现实LBSN中,地点不仅能够通过本身整体的评论在时间、空间、评分、文本等维度表现出的异常检测是否存在虚假评论活动,而且通过地点之间的竞争关系能够更深入的发掘恶意竞争导致虚假评论活动的可疑地点,从而提高存在虚假评论活动的可疑地点的检测准确率。
发明内容
本发明所要解决的技术问题是:提供一种可以识别与检测存在虚假评论活动的可疑地点的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法。
为解决上述技术问题,本发明采用的技术方案为:LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,利用LBSN中地点的异常特征信息与地点间的竞争关系进行可疑地点的检测过程,包括如下步骤:
1)根据LBSN中已被过滤的评论信息,人工识别虚假评论活动,标注存在虚假评论活动的可疑地点以及无虚假评论行为的可信地点,并划分地点的训练集与测试集;同时标注存在恶意竞争活动的竞争关系地点对,与无竞争关系地点对,并划分竞争关系地点对的训练集与测试集。
2)针对存在虚假评论活动的地点进行分析,基于LBSN的地点评分、时空属性和地点评论的文本内容提取地点整体评论的异常特征,构造地点的异常特征集。
3)针对地点间的竞争性进行分析,基于LBSN的多种维度提取两地点间的恶意竞争关系的异常特征,构造地点间竞争关系的异常特征集。
4)基于逻辑斯蒂回归机器学习方法构建异常程度函数,根据步骤1)中标注的正负例对函数中特征权值参数进行学习,获得数据集中每个地点的异常程度εl与地点间竞争关系的异常程度εc。
5)基于LBSN构建马尔科夫随机场检测模型,包含节点与边,其中节点表示地点,边表示地点间竞争关系;所述节点包含两种类别:可疑地点与可信地点,设置在不同类别下节点属于各类别的先验概率,通过步骤4)中地点的异常程度获得;设置地点与地点间在不同类别下的关联程度值矩阵,,关联程度通过步骤4)中两地点间竞争异常程度获得。
6)根据步骤5)得到的马尔科夫随机场检测模型,对于节点vi到节点vj设置信息值 并基于该模型将信息值迭代传播,最终对每个节点vi生成置信度
并基于该模型将信息值迭代传播,最终对每个节点vi生成置信度 表示节点vi属于类别σi的可信度,作为节点vi属于类别σi的边缘概率。
表示节点vi属于类别σi的可信度,作为节点vi属于类别σi的边缘概率。
7)根据步骤6)获得的节点置信度,最终对地点是否为存在虚假评论活动的可疑地点进行标注。
所述步骤1)的数据集中虚假评论活动地点标注的具体方法为:根据LBSN网络中自动过滤的评论信息,选取被过滤评论比例高的部分地点,人工标注其中的虚假评论,将虚假评论比例高于一定阈值的地点标注为存在虚假评论活动的可疑地点,随机选取部分不存在被过滤评论的地点标注为可信地点。
所述步骤2)中从不同维度提取数据集中任意地点l的整体评论异常特征具体方法包括:从评分差异维度提取地点的总体评分差异性OSD(l),从时间维度提取地点的评论爆发性MRD(l),从时空维度提取地点的签到周期分布差异性D(r||c)从评论文本维度提取地点的内容相似性MCS(l)。
所述步骤3)中从不同维度提取数据集中存在竞争的两地点lm,ln间的恶意竞争的异常特征具体方法包括:从评分差异维度提取两竞争地点共同用户的评论差异性URD(lnm,ln),从时间维度提取两竞争地点共同用户的评论时间协同性ATI(lnm,ln),从评论文本维度提取两竞争地点共同用户的内容相似性ACS(lnm,ln)。
所述步骤4)中基于逻辑斯蒂回归机器学习方法进行训练学习获得每个地点的异常程度与地点间竞争关系的异常程度的具体方法分为以下3个步骤:
a)根据地点的异常特征集构造特征向量 基于步骤1)中标注的地点的训练集,通过采用梯度下降法训练学习获得地点的异常特征向量对应的权值向量
基于步骤1)中标注的地点的训练集,通过采用梯度下降法训练学习获得地点的异常特征向量对应的权值向量
b)根据地点间的竞争关系的异常特征集构造特征向量 基于步骤1)中标注的竞争关系地点对的训练集,通过采用最大似然估计和梯度下降法训练学习获得地点间竞争关系的异常特征向量对应的权值向量
基于步骤1)中标注的竞争关系地点对的训练集,通过采用最大似然估计和梯度下降法训练学习获得地点间竞争关系的异常特征向量对应的权值向量
c)根据地点的异常特征与权重计算所有地点的异常程度εl,根据地点间竞争关系的异常特征与权重计算所有地点间竞争关系的异常程度εc,计算异常程度εl与εc的具体方法为:


其中, 为根据特征集构造的特征向量,
为根据特征集构造的特征向量, 为特征向量对应的特征权向量。
为特征向量对应的特征权向量。
所述步骤6)中基于检测模型将信息值 迭代传播的具体方法为:
迭代传播的具体方法为:

其中,M为节点的类别集合, 为节点vi与节点vj在各自类别σi,σj下的关联程度值,
为节点vi与节点vj在各自类别σi,σj下的关联程度值, 为节点自身在类别σi下的先验概率值,
为节点自身在类别σi下的先验概率值, 为节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点vi的所有邻居节点集合,N(vi)\vj是节点vi除节点vj外的所有邻居节点集合,Z1是标准化常量,目的是确保
为节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点vi的所有邻居节点集合,N(vi)\vj是节点vi除节点vj外的所有邻居节点集合,Z1是标准化常量,目的是确保 即所有类别下信息值
即所有类别下信息值 之和为1。。
之和为1。。
所述步骤6)中需要计算每个节点vi在类别σi下的置信度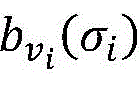 作为节点vi属于类别σi的概率,节点vi属于类别σi的置信度计算的具体方法为:
作为节点vi属于类别σi的概率,节点vi属于类别σi的置信度计算的具体方法为:

其中,Z2是标准化常量,目的是确保 即节点vi在所有类别下下的置信度之和为1。
即节点vi在所有类别下下的置信度之和为1。
本发明的有益效果为:本发明根据LBSN中地点的评论在评分、时间、空间和文本维度表现出的异常特征,提取地点的异常特征,基于逻辑斯蒂回归机器学习方法对地点进行分类,有效检测存在虚假评论活动的可疑地点;引入地点间的竞争关系改进检测效果,提取地点间竞争的异常特征;融合地点自身的异常特征与地点间竞争的异常特征,共同作用于存在虚假评论活动的可疑地点的检测,提升检测性能。具体地讲,本发明具有如下优点:
1、利用LBSN中地点的评论在评分、时间、空间、文本维度表现出的异常特征,提取地点的异常特征,基于逻辑斯蒂回归机器学习方法对地点进行分类,有效检测存在虚假评论活动的可疑地点;
2、引入地点间的竞争关系改进检测效果,提取地点间竞争的异常特征,深入挖掘可能存在虚假评论活动的地点;
3、融合地点自身的异常特征与地点间竞争的异常特征,共同作用于虚假评论活动地点的检测,提升检测的准确度。
附图说明
图1为本发明的异常特征提取流程图。
图2为本发明的虚假评论活动地点检测流程图。
图3为本发明的整体系统框架图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等同变换均落于本申请所附权利要求所限定的范围。
参见图1、图2和图3所示,本发明所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,包括如下步骤:
步骤1:根据LBSN网络中自动过滤的评论信息,选取被过滤评论比例高的部分地点,人工标注其中的虚假评论,将虚假评论比例高于一定阈值的地点标注为存在虚假评论活动的可疑地点,随机选取部分不存在被过滤评论的地点标注为可信地点。然后采用随机抽取的方法按照4∶1的比例将数据划分为两部分:S、T,其中S作为训练集,T作为测试集;
基于标注出的可疑地点,选取有共同的访问评论用户,间隔距离小于一定阈值并且地点的标签类别相似度大于一定阈值的地点对作为可能存在竞争关系的地点对候选集,基于人工标注的方式标注出候选集中存在恶意竞争导致虚假评论活动的地点对作为竞争地点对,随机选取候选集中无恶意竞争活动的地点对作为无竞争地点对。然后采取随机抽取的方法同样按照4∶1的比例将数据划分为两部分:S、T,其中S作为训练集,T作为测试集;
步骤2:针对存在虚假评论活动的地点进行分析,基于LBSN的评分、时间、空间、文本等多种维度提取数据集中任意地点l的异常特征进行量化。
1)从评分差异维度提取地点l的总体评分差异性OSD(l):

其中,t表示地点的某一条评论i∈Rl的发布日期时刻,Rl表示地点l的评论集合,ri(t)表示在t时刻评论i的评分,avgt’<tri(t’)表示t时刻之前地点l的平均评分,di表示评论ri(t)的评分与评论时刻前地点l的平均评分avgt’<tri(t’)之间的差异, 表示地点所有评论的平均评分差异。
表示地点所有评论的平均评分差异。
2)从时间维度提取地点l的评论爆发性MRD(l):

其中,n为一天内地点l收到的评论数,avg(n)为地点l在具有评论的天数内的平均每日评论次数,max(n)为地点l最大评论次数, 表示地点的每日最大评论数的绝对偏差。
表示地点的每日最大评论数的绝对偏差。
3)从时空维度提取地点l的签到周期分布差异性D(r||c):

其中,k∈{1,2,…,7}表示一周周期内的一天,r表示地点l在一周周期内评论分布向量,c表示地点l在一周周期内签到分布向量, 为KL散度描述地点签到时间分布和评论时间分布的差异性。
为KL散度描述地点签到时间分布和评论时间分布的差异性。
4)从评论文本维度提取地点l的内容相似性MCS(l):

其中,将地点的所有评论文本作为语料空间,cosine(ri,rj)为对于地点l的任意两条评论ri,rj基于TF-IDF的文本余弦相似性。
5)通过提取的数据集中所有地点的特征值构造地点的异常特征集 其中,
其中, 为总体评分差异性OSD(l),
为总体评分差异性OSD(l), 为评论爆发性MRD(l),
为评论爆发性MRD(l), 为签到周期分布差异性D(r||c),
为签到周期分布差异性D(r||c), 为内容相似性MCS(l)。
为内容相似性MCS(l)。
步骤3:针对地点间的竞争性进行分析,基于LBSN的多种维度提取数据集中任意可能存在竞争的地点对lm,ln竞争的异常特征进行量化。
1)从评分差异维度提取两竞争地点lm,ln共同用户的评论差异性URD(lm,ln):
URD(lm,ln)=avgi∈U|di|,di=ri(lm)-ri(ln) (5)
其中,地点lm与ln的共同评论用户集合为U,ri(l)表示用户i针对地点l的评分,di表示用户i对于两个竞争地点lm、ln的评分差异。
2)从时间维度提取两竞争地点lm,ln共同用户的评论时间协同性ATI(lnm,ln):
ATI(lm,ln)=avgi∈U|Ti(lnm)-Ti(ln)| (6)
其中,Ti(l)表示用户i针对地点l的评论时间,|Ti(lm)-Ti(ln)|表示用户i对于两个竞争地点lm、ln的评论时间间隔。
3)从评论文本维度提取两竞争地点lm,ln共同用户的内容相似性ACS(lnm,ln):

其中,RU表示共同用户集合U的针对于竞争地点的评论集合,将其作为语料空间,cosine(ri,rj)为共同用户针对竞争地点发布的评论文本ri,rj之间的基于TF-IDF的余弦相似性。
4)通过提取的数据集中所有可能存在竞争的地点对的特征值构造地点间竞争的异常特征集 其中,
其中, 为评论差异性URD(lnm,ln),
为评论差异性URD(lnm,ln), 为时间协同性ATI(lm,ln),
为时间协同性ATI(lm,ln), 为内容相似性ACS(lnm,ln)。
为内容相似性ACS(lnm,ln)。
步骤4:将步骤2与步骤3得到的特征向量采用逻辑斯蒂回归机器学习方法进行训练学习,获得每个地点的异常程度εl与两个地点之间的竞争程度εc。异常程度与竞争程度的计算方法相同,以下以异常程度εl的计算为例,主要包含以下步骤:
1)对于地点的异常特征集ΨL,构造该类的特征向量 其中,
其中, 表示特征集ΨL中的第i个特征值。
表示特征集ΨL中的第i个特征值。
2)为每一维特征设置权重ω,对于特征向量 构造对应特征权向量
构造对应特征权向量 其中,权值ωi表示特征权向量
其中,权值ωi表示特征权向量 中的第i个特征对于地点的异常程度εl的重要程度。
中的第i个特征对于地点的异常程度εl的重要程度。
3)基于二项逻辑斯蒂回归模型构造表示地点的异常程度的程度函数:

其中,εl∈[0,1],εl越接近于1表示地点l的异常程度越高。
4)基于构造的地点的训练集采用最大似然估计和梯度下降法对函数参数进行学习,学习得特征权向量
5)根据数据集中任意地点l的异常特征向量 与特征权向量
与特征权向量 计算数据集中所有地点l的异常程度εl。
计算数据集中所有地点l的异常程度εl。
步骤5:基于LBSN构建马尔科夫随机场检测模型的具体步骤分为以下3步:
1)基于LBSN与马尔科夫随机场构建网络G(V,E),其中,V是节点集合,E是地点-地点边的集合,为步骤1中选取的可能存在竞争关系的地点对候选集合,表示地点间的竞争关系。
2)对于节点vm,设置 为节点vm在不同类别σm下的先验概率分布,表示地点为不同类别地点的可能性。设置步骤4中获得的地点的异常程度εl表示节点在可疑地点类别下的先验值,1-εl表示节点在可信地点类别下的先验值。
为节点vm在不同类别σm下的先验概率分布,表示地点为不同类别地点的可能性。设置步骤4中获得的地点的异常程度εl表示节点在可疑地点类别下的先验值,1-εl表示节点在可信地点类别下的先验值。
3)对于地点-地点边E,设置 为节点vm与节点vn在各类别下的关联程度分布矩阵,表示地点的类别受到与其存在竞争的地点的类别的相关程度。若节点vm的类别为可疑地点,设置地点间竞争的异常程度εc表示地点间存在恶意竞争的可能性,1-εc表示地点间无恶意竞争的可能性。而当节点vm的类别为可信地点,不考虑地点间存在的恶意竞争特征,设置节点vm与节点vn为可疑地点和可信地点的相关程度相同,均为1/2。
为节点vm与节点vn在各类别下的关联程度分布矩阵,表示地点的类别受到与其存在竞争的地点的类别的相关程度。若节点vm的类别为可疑地点,设置地点间竞争的异常程度εc表示地点间存在恶意竞争的可能性,1-εc表示地点间无恶意竞争的可能性。而当节点vm的类别为可信地点,不考虑地点间存在的恶意竞争特征,设置节点vm与节点vn为可疑地点和可信地点的相关程度相同,均为1/2。
步骤6:根据步骤5得到的检测模型,计算每个地点为存在虚假评论活动的可疑地点的概率,具体包含以下步骤:
1)根据步骤5得到的检测模型,设置模型中任意节点vi到节点vj信息值 信息值传递方法为:
信息值传递方法为:

其中, 为步骤5中获得的节点在类别σi下的先验概率值,
为步骤5中获得的节点在类别σi下的先验概率值, 为节点vi与节点vj在各自类别σi,σj下的关联程度值,
为节点vi与节点vj在各自类别σi,σj下的关联程度值, 为节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点i的所有邻居节点集合,Z1是标准化常量,
为节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点i的所有邻居节点集合,Z1是标准化常量,
2)初始化所有信息值为1。
3)选取部分节点开始信息值迭代传播,在此过程中将信息值不断更新。
4)当所有的信息值连续两次更新的变化小于一定阈值时,表示所有节点的类别分布情况达到稳定状态,停止信息值传递。
5)计算每个节点vi在类别σi下的置信度 作为节点vi属于类别σi的概率,节点vi的置信度计算方式为:
作为节点vi属于类别σi的概率,节点vi的置信度计算方式为:

其中,Z2是标准化常量,目的是确保
步骤7:根据步骤6获得的任意节点vi在可疑地点类别σ下的置信度 基于测试集的检测结果选择合适的划分阈值δ,选取
基于测试集的检测结果选择合适的划分阈值δ,选取 的地点标注为存在虚假评论活动的可疑地点。
的地点标注为存在虚假评论活动的可疑地点。
Claims (7)
1.LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,利用LBSN中地点的异常特征与地点间的竞争关系进行虚假评论可疑地点检测过程,包括如下步骤:
1)根据LBSN中已被过滤的评论信息,人工识别虚假评论活动,标注存在虚假评论活动的可疑地点以及无虚假评论行为的可信地点,并划分训练集与测试集;
2)针对存在虚假评论活动的地点进行分析,基于LBSN的地点评分、时空属性和地点评论的文本内容提取地点整体评论的异常特征,构造地点的异常特征集;
3)针对地点间的竞争性进行分析,基于LBSN的多种维度提取两地点间的恶意竞争关系的异常特征,构造地点间竞争关系的异常特征集;
4)分别将步骤2)、步骤3)得到的特征集中的特征拼接为特征向量,采用基于逻辑斯蒂回归机器学习方法构建异常程度函数,根据步骤1)中标注的正负例对函数中特征权值参数进行学习,获得数据集中每个地点的异常程度εl与地点间竞争关系的异常程度εc;
5)基于LBSN构建马尔科夫随机场检测模型,包含节点与边,其中节点表示地点,边表示地点间竞争关系;所述节点包含两种类别:可疑地点与可信地点,设置不同类别下节点属于各类别的先验概率,通过步骤4)中得出的地点的异常程度获得;设置地点与地点间在不同类别下的关联程度值矩阵,关联程度通过步骤4)中两地点间竞争异常程度获得;
6)根据步骤5)得到的马尔科夫随机场检测模型,对于节点vi到节点vj设置信息值 并基于该模型将信息值迭代传播,最终对每个节点vi生成置信度
并基于该模型将信息值迭代传播,最终对每个节点vi生成置信度 表示节点vi属于类别σi的可信度,作为节点vi属于类别σi的边缘概率;
表示节点vi属于类别σi的可信度,作为节点vi属于类别σi的边缘概率;
7)根据步骤6)获得的节点置信度,最终对地点是否为存在虚假评论活动的可疑地点进行标注。
2.根据权利要求1所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤1)的数据集中存在虚假评论活动的可疑地点标注的具体方法为:根据LBSN网络中自动过滤的评论信息,人工标注其中的虚假评论,依据虚假评论对存在虚假评论活动的可疑地点与可信地点进行标注。
3.根据权利要求1所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤2)中分别从评分差异维度、时间维度、空间维度、评论文本维度对数据集中任意地点的整体评论进行异常特征的提取。
4.根据权利要求1所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤3)中分别从评分差异维度、时间维度、评论文本维度对数据集中两地点间竞争关系进行异常特征的提取。
5.根据权利要求3或4所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤4)中获得数据集中每个地点的异常程度εl与地点间竞争关系的异常程度εc的具体方法分为以下3个步骤:
a)根据地点的异常特征集拼接构造特征向量 基于步骤1)中标注的地点的训练集,通过采用梯度下降法训练学习获得地点的异常特征向量对应的权值向量
基于步骤1)中标注的地点的训练集,通过采用梯度下降法训练学习获得地点的异常特征向量对应的权值向量
b)根据地点间的竞争关系的异常特征集拼接构造特征向量 基于步骤1)中标注的竞争关系地点对的训练集,通过采用最大似然估计和梯度下降法训练学习获得地点间竞争关系的异常特征向量对应的权值向量
基于步骤1)中标注的竞争关系地点对的训练集,通过采用最大似然估计和梯度下降法训练学习获得地点间竞争关系的异常特征向量对应的权值向量
c)根据地点的异常特征与权重计算所有地点的异常程度εl,根据地点间竞争关系的异常特征与权重计算所有地点间竞争关系的异常程度εc,计算异常程度εl与εc的具体方法为:


6.根据权利要求5所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤6)中基于马尔科夫随机场检测模型将信息值 迭代传播的具体方法为:
迭代传播的具体方法为:

其中,M为节点的类别集合, 为节点vi与节点vj在各自类别σi,σj下的关联程度值,
为节点vi与节点vj在各自类别σi,σj下的关联程度值, 为节点vi在类别σi下的先验概率值,
为节点vi在类别σi下的先验概率值, 为类别σi下节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点vi的所有邻居节点集合,N(vi)\vj是节点vi除节点vj外的所有邻居节点集合,Z1是标准化常量,
为类别σi下节点vi的其他邻居节点vk传递给该节点的信息值,N(vi)是节点vi的所有邻居节点集合,N(vi)\vj是节点vi除节点vj外的所有邻居节点集合,Z1是标准化常量, 的目的是确保
的目的是确保 即所有类别下信息值
即所有类别下信息值 之和为1。
之和为1。
7.根据权利要求6所述的LBSN中一种基于多维属性挖掘的虚假评论可疑地点检测方法,其特征在于,所述步骤6)中需要计算每个节点vi在类别σi下的置信度 作为节点vi属于类别σi的概率,节点vi属于类别σi的置信度计算的具体方法为:
作为节点vi属于类别σi的概率,节点vi属于类别σi的置信度计算的具体方法为:

其中,Z2是标准化常量, 的目的是确保
的目的是确保 即节点vi在所有类别下下的置信度之和为1。
即节点vi在所有类别下下的置信度之和为1。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710397805.8A CN107085616B (zh) | 2017-05-31 | 2017-05-31 | Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710397805.8A CN107085616B (zh) | 2017-05-31 | 2017-05-31 | Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107085616A CN107085616A (zh) | 2017-08-22 |
| CN107085616B true CN107085616B (zh) | 2021-03-16 |
Family
ID=59608640
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710397805.8A Active CN107085616B (zh) | 2017-05-31 | 2017-05-31 | Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN107085616B (zh) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107784124B (zh) * | 2017-11-23 | 2021-08-24 | 重庆邮电大学 | 一种基于时空关系的lbsn超网络链接预测方法 |
| CN109639633B (zh) * | 2018-11-02 | 2021-11-12 | 平安科技(深圳)有限公司 | 异常流量数据识别方法、装置、介质及电子设备 |
| CN109670542A (zh) * | 2018-12-11 | 2019-04-23 | 田刚 | 一种基于评论外部信息的虚假评论检测方法 |
| CN109829733B (zh) * | 2019-01-31 | 2023-02-03 | 重庆大学 | 一种基于购物行为序列数据的虚假评论检测系统和方法 |
| CN113434628B (zh) * | 2021-05-14 | 2023-07-25 | 南京信息工程大学 | 一种基于特征级与传播关系网络的评论文本置信检测方法 |
| CN113468553B (zh) * | 2021-06-02 | 2022-07-19 | 湖北工业大学 | 一种面向工业大数据的隐私保护分析系统及方法 |
| CN113724035B (zh) * | 2021-07-29 | 2023-10-17 | 河海大学 | 一种基于特征学习和图推理的恶意用户检测方法 |
| CN116305271B (zh) * | 2023-03-15 | 2026-03-06 | 北京工业大学 | 一种面向数据挖掘的隐私保护方法及系统 |
| CN117828021A (zh) * | 2023-12-29 | 2024-04-05 | 西安理工大学 | 基于深度学习的社交网络虚假评论检测方法及系统 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010067070A1 (en) * | 2008-12-11 | 2010-06-17 | Scansafe Limited | Malware detection |
| CN103235933A (zh) * | 2013-04-15 | 2013-08-07 | 东南大学 | 一种基于隐马尔科夫模型的车辆异常行为检测方法 |
-
2017
- 2017-05-31 CN CN201710397805.8A patent/CN107085616B/zh active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010067070A1 (en) * | 2008-12-11 | 2010-06-17 | Scansafe Limited | Malware detection |
| CN103235933A (zh) * | 2013-04-15 | 2013-08-07 | 东南大学 | 一种基于隐马尔科夫模型的车辆异常行为检测方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN107085616A (zh) | 2017-08-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107085616B (zh) | Lbsn中一种基于多维属性挖掘的虚假评论可疑地点检测方法 | |
| CN110516067B (zh) | 基于话题检测的舆情监控方法、系统及存储介质 | |
| US10599774B1 (en) | Evaluating content items based upon semantic similarity of text | |
| CN104281882B (zh) | 基于用户特征的预测社交网络信息流行度的方法及系统 | |
| Fang et al. | Entity linking on microblogs with spatial and temporal signals | |
| CN109831460B (zh) | 一种基于协同训练的Web攻击检测方法 | |
| CN110175851B (zh) | 一种作弊行为检测方法及装置 | |
| CN103838835B (zh) | 一种网络敏感视频检测方法 | |
| CN112231570B (zh) | 推荐系统托攻击检测方法、装置、设备及存储介质 | |
| WO2018050022A1 (zh) | 应用程序的推荐方法及服务器 | |
| CN111522915A (zh) | 中文事件的抽取方法、装置、设备及存储介质 | |
| Gao et al. | Filtering of brand-related microblogs using social-smooth multiview embedding | |
| CN105005594A (zh) | 异常微博用户识别方法 | |
| Seneviratne et al. | Early detection of spam mobile apps | |
| CN107341183A (zh) | 一种基于暗网网站综合特征的网站分类方法 | |
| CN116776889A (zh) | 一种基于图卷积网络和外部知识嵌入的粤语谣言检测方法 | |
| CN102946331A (zh) | 一种社交网络僵尸用户检测方法及装置 | |
| CN114138968B (zh) | 一种网络热点的挖掘方法、装置、设备及存储介质 | |
| CN107809370B (zh) | 用户推荐方法及装置 | |
| CN104915399A (zh) | 基于新闻标题的推荐数据处理方法及系统 | |
| CN112084333A (zh) | 一种基于情感倾向分析的社交用户生成方法 | |
| CN115080756A (zh) | 一种面向威胁情报图谱的攻防行为和时空信息抽取方法 | |
| CN116015703A (zh) | 模型训练方法、攻击检测方法及相关装置 | |
| Mowar et al. | Fishing out the phishing websites | |
| Zhang et al. | A local expansion propagation algorithm for social link identification |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |