CN103124347A - Method for guiding multi-view video coding quantization process by visual perception characteristics - Google Patents
Method for guiding multi-view video coding quantization process by visual perception characteristics Download PDFInfo
- Publication number
- CN103124347A CN103124347A CN2012104020039A CN201210402003A CN103124347A CN 103124347 A CN103124347 A CN 103124347A CN 2012104020039 A CN2012104020039 A CN 2012104020039A CN 201210402003 A CN201210402003 A CN 201210402003A CN 103124347 A CN103124347 A CN 103124347A
- Authority
- CN
- China
- Prior art keywords
- frame
- coding
- current
- viewpoint
- follows
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images













Landscapes
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
本发明涉及一种利用视觉感知特性指导编码量化过程的方法。本方法的操作步骤如下:(1)读取输入视频序列每一帧的亮度值大小,建立频域的恰可辨失真阈值模型,(2)输入视频序列每一帧经过视点内和视点间的预测,(3)对残差数据进行离散余弦变换,(4)动态调节当前帧中每个宏块的量化步长,(5)动态调节率失真优化过程中的拉格朗日参数,(6)对量化的数据进行熵编码,形成码流通过网络传输。本发明在保证主观质量基本保持不变的情况下,提高了视频压缩效率,更加适合在网络中传输。
The present invention relates to a method for guiding the coding and quantization process by using visual perception characteristics. The operation steps of this method are as follows: (1) read the luminance value of each frame of the input video sequence, and set up a just discernible distortion threshold model in the frequency domain, (2) each frame of the input video sequence passes through the intra-viewpoint and the inter-viewpoint Prediction, (3) perform discrete cosine transform on the residual data, (4) dynamically adjust the quantization step size of each macroblock in the current frame, (5) dynamically adjust the Lagrangian parameters in the rate-distortion optimization process, (6 ) performs entropy encoding on the quantized data to form a code stream and transmit it through the network. The present invention improves the video compression efficiency under the condition that the subjective quality remains basically unchanged, and is more suitable for transmission in the network.
Description
技术领域 technical field
本发明涉及多视点视频编解码技术领域,特别是利用视觉感知特性指导多视点视频编码量化过程的方法,适用于高清3D视频信号的编解码。 The invention relates to the technical field of multi-viewpoint video coding and decoding, in particular to a method for guiding the multi-viewpoint video coding and quantization process by using visual perception characteristics, which is suitable for high-definition 3D video signal coding and decoding.
背景技术 Background technique
随着时代发展,人们对视听感受的要求越来越高,不满足于现有的单视二维视频。人们对于立体感体验要求越来越高,从固定角度的立体感到任意角度都可以感受到立体感,从而催生出多视点编码技术的发展。然而,多视点要求的数据大大提高,如何有效的提高视频压缩效率成为研究热点。目前,视频压缩技术主要集中在去除空间冗余、时间冗余和统计冗余三个方面。尽管视频专家推出新一代视频压缩编码技术(HEVC),期待视频压缩效率在H.264基础上再提高一倍。然而,由于人类视觉系统(HVS)自身的特性,存在着感知冗余还是没有被去除。随着对人眼视觉特性研究的渐渐深入,有视频工作者提出了去除人眼冗余的恰可辨失真模型(Just Noticeable Distortion,JND)。即根据得到的JND阈值度量感知冗余的大小,当变化值低于这个阈值就不被人眼感知。 With the development of the times, people have higher and higher requirements for audio-visual experience, and are not satisfied with the existing single-view two-dimensional video. People have higher and higher requirements for stereoscopic experience, and stereoscopic perception from a fixed angle can be experienced from any angle, thus giving birth to the development of multi-viewpoint coding technology. However, the data required by multi-viewpoints is greatly increased, and how to effectively improve the video compression efficiency has become a research hotspot. At present, video compression technology mainly focuses on three aspects of removing spatial redundancy, temporal redundancy and statistical redundancy. Although video experts have launched a new generation of video compression coding technology (HEVC), it is expected that the video compression efficiency will be doubled on the basis of H.264. However, due to the characteristics of the human visual system (HVS), there is perceptual redundancy that has not been removed. With the gradual deepening of the research on the visual characteristics of the human eye, some video workers have proposed a Just Noticeable Distortion (JND) model that removes the redundancy of the human eye. That is, measure the size of perceptual redundancy according to the obtained JND threshold, and when the change value is lower than this threshold, it will not be perceived by human eyes.
目前对于JND的研究主要分为两大类:像素域JND和频域JND模型。其中,文献[1]中提出的JND模型是经典的像素域模型,分别研究了亮度掩盖特性、纹理掩盖特性和时域掩盖特性。文献[2]中提出的频域JND模型在研究了前三种特性外,还研究了人眼对不同频率段的敏感性,这样使得频域JND模型更加符合人眼的视觉特性。 At present, the research on JND is mainly divided into two categories: pixel-domain JND and frequency-domain JND models. Among them, the JND model proposed in the literature [1] is a classic pixel domain model, which studies the characteristics of brightness masking, texture masking and time domain masking respectively. The frequency-domain JND model proposed in [2] not only studies the first three characteristics, but also studies the sensitivity of the human eye to different frequency bands, which makes the frequency-domain JND model more in line with the visual characteristics of the human eye.
针对文献[2]中提出的JND模型,是目前比较完备的DCT域JND模型。它除了包含像素的亮度掩盖特性和纹理掩盖特性,还增加了空间灵敏度函数效应。空间灵敏度函数反映了人眼的带通特性,通过去除人眼不能感知的频率成分达到去除人眼感知频率冗余目的。在时域掩盖效应中,包含了平滑眼球移动效应,不仅包含了运动幅度的大小,还包含了运动的方向信息。有研究者将其与多视点视频相结合作用于残差DCT变换(离散余弦变换)后,极大提高了压缩效率。但是,没有将其用于其他的编码过程如量化过程,故其去除视觉冗余性不够彻底。 Aiming at the JND model proposed in the literature [2], it is a relatively complete DCT domain JND model at present. In addition to including the brightness masking feature and texture masking feature of the pixel, it also adds the effect of the spatial sensitivity function. The spatial sensitivity function reflects the bandpass characteristics of the human eye, and removes the frequency components that the human eye cannot perceive to achieve the purpose of removing the frequency redundancy of the human eye. In the time-domain masking effect, the smooth eyeball movement effect is included, which includes not only the magnitude of the motion amplitude, but also the direction information of the motion. Some researchers combined it with multi-view video and applied it to the residual DCT transform (discrete cosine transform), which greatly improved the compression efficiency. However, it is not used in other coding processes such as quantization, so it is not thorough enough to remove visual redundancy.
文献[3]中建立的JND模型,虽然提出了利用JND模型指导量化过程。然而其建立的JND模型是像素域的,缺少了去除人眼频率冗余的过程,导致指导量化过程不够精确。其次,针对JND模型保证了主观质量,只需要对人眼不敏感的地方进行调节量化值,而其它区域量化值保持不变。最后在调整量化参数同时,对应的调整拉格朗日参数。 The JND model established in the literature [3], although proposed to use the JND model to guide the quantization process. However, the JND model established by it is in the pixel domain, and lacks the process of removing the frequency redundancy of the human eye, resulting in inaccurate guidance and quantization. Secondly, the subjective quality is guaranteed for the JND model, and the quantization value only needs to be adjusted in places where the human eye is not sensitive, while the quantization value of other areas remains unchanged. Finally, while adjusting the quantization parameters, the Lagrangian parameters are correspondingly adjusted.
本发明专利申请首次提出将DCT域JND模型应用到多视点视频编码中量化过程,在保证主观质量不变的情况下,进一步提高视频压缩效率。 The patent application of the present invention proposes for the first time that the DCT domain JND model is applied to the quantization process of multi-viewpoint video coding, so as to further improve the video compression efficiency while keeping the subjective quality unchanged.
文献[1]: X. Yang, W. Lin, and Z. Lu, “Motion-compensated residue preprocessing in video coding based on just-noticeable-distortion profile,” IEEE Trans. Circuits Syst. Video Technol., vol. 15, no. 6, pp. 742–752,2005. Literature [1]: X. Yang, W. Lin, and Z. Lu, “Motion-compensated residue preprocessing in video coding based on just-noticeable-distortion profile,” IEEE Trans. Circuits Syst. Video Technol., vol. 15 , no. 6, pp. 742–752, 2005.
文献[2]: Zhenyu Wei and King N. Ngan., "Spatio-Temporal Just Noticeable Distortion Profile for Grey Scale Image/Video in DCT Domain." IEEE transactions on circuits and systems for video technology.VOL. 19, NO. 3, March 2009. Literature [2]: Zhenyu Wei and King N. Ngan., "Spatio-Temporal Just Noticeable Distortion Profile for Gray Scale Image/Video in DCT Domain." IEEE transactions on circuits and systems for video technology. VOL. 19, NO. 3 , March 2009.
文献[3]: Z. Chen and C. Guillemot, “Perceptually friendly H.26 /AVC video coding based on foveated just noticeable distortion model,” IEEE Trans. Circuits Syst. Video Technol., vol. 20, no. 6, pp. 806–819, Jun.2010. Literature [3]: Z. Chen and C. Guillemot, "Perceptually friendly H.26 /AVC video coding based on foveated just noticeable distortion model," IEEE Trans. Circuits Syst. Video Technol., vol. 20, no. 6, pp. 806–819, Jun. 2010.
发明内容 Contents of the invention
本发明的目的是针对已有技术存在的缺陷,提供一种利用视觉感知特性指导多视点视频编码量化过程的方法,该方法在保证视频主观质量不变的情况下,运用频域JND模型指导多视点量化过程,对人眼不敏感的区域提高量化步长,提高了视频压缩效率。在调整步长的同时,动态调整率失真优化函数的拉格朗日参数,使得编码效率进一步提高。 The purpose of the present invention is to provide a method for guiding the quantization process of multi-viewpoint video coding by using visual perception characteristics to solve the defects in the prior art. The method uses the frequency domain JND model to guide multi-viewpoint video coding while ensuring that the subjective quality of the video remains unchanged. During the viewpoint quantization process, the quantization step size is increased in areas that are not sensitive to human eyes, and the video compression efficiency is improved. While adjusting the step size, the Lagrangian parameter of the rate-distortion optimization function is dynamically adjusted, so that the coding efficiency is further improved.
为达到上述目的,本发明采用如下的技术方案: To achieve the above object, the present invention adopts the following technical solutions:
一种利用视觉感知特性指导多视点视频编码量化过程的方法,其特征在于操作步骤如下: A method of using visual perception characteristics to guide the quantization process of multi-viewpoint video coding, characterized in that the operation steps are as follows:
(1) 读取输入视频序列每一帧的亮度值大小,建立频域的恰可辨失真阈值模型, (1) Read the brightness value of each frame of the input video sequence, and establish a just discernable distortion threshold model in the frequency domain,
(2) 输入视频序列每一帧经过视点内和视点间的预测, (2) Each frame of the input video sequence undergoes intra-viewpoint and inter-viewpoint prediction,
(3) 对残差数据进行离散余弦变换(DCT变换), (3) Discrete cosine transform (DCT transform) is performed on the residual data,
(4) 动态调节当前帧中每个宏块的量化步长, (4) Dynamically adjust the quantization step size of each macroblock in the current frame,
(5) 动态调节率失真优化过程中的拉格朗日参数, (5) Lagrangian parameters in the dynamic adjustment rate-distortion optimization process,
(6) 对量化的数据进行熵编码,形成码流通过网络传输。 (6) Entropy encoding is performed on the quantized data to form a code stream for transmission through the network.
本发明的利用视觉感知特性指导多视点视频编码量化过程的方法与已有技术相比较,具有如下显而易见的突出实质性特点和显著技术进步: Compared with the prior art, the method of using visual perception characteristics to guide the quantization process of multi-viewpoint video encoding in the present invention has the following obvious outstanding substantive features and significant technological progress:
1)、本多视点视频编码方法在保证重建视频质量不变的同时,使得编码过程在通过量化这个子程序就能降低编码码率,试验中最大码率可以降到12.35%; 1) The multi-view video coding method can reduce the coding bit rate through the subroutine quantization in the coding process while ensuring the quality of the reconstructed video. In the experiment, the maximum bit rate can be reduced to 12.35%;
2)、本多视点视频编码方法在保证重建视频质量不变的同时,采用平均主观分数差值,当主观分数差值接近0时,说明两种方法的主观质量越接近,本方法的平均主观分数差值为0.03,因此说本发明的主观质量与多视点视频编解码JMVC代码的主观质量相当; 2) This multi-viewpoint video coding method uses the average subjective score difference while ensuring the quality of the reconstructed video. When the subjective score difference is close to 0, it means that the subjective quality of the two methods is closer, and the average subjective score of this method is closer to 0. The score difference is 0.03, so the subjective quality of the present invention is equivalent to the subjective quality of multi-viewpoint video codec JMVC code;
3)、本多视点视频编码方法没有增加特别复杂的编码过程,以较小的复杂度提高视频编码压缩效率。 3) The multi-viewpoint video encoding method does not add a particularly complicated encoding process, and improves video encoding and compression efficiency with less complexity.
附图说明 Description of drawings
图1是本发明中的利用视觉感知特性指导多视点视频编码量化过程的方法的原理框图。 FIG. 1 is a functional block diagram of the method for guiding the quantization process of multi-viewpoint video coding by using visual perception characteristics in the present invention.
图2是频域的恰可辨失真模型的框图。 Figure 2 is a block diagram of a just discernible distortion model in the frequency domain.
图3是视点内/间预测的框图。 3 is a block diagram of intra/inter-view prediction.
图4是DCT变换框图。 Fig. 4 is a block diagram of DCT transformation.
图5是动态调节量化步长的框图。 Fig. 5 is a block diagram of dynamically adjusting the quantization step size.
图6是动态调节率失真代价函数中的拉格朗日参数的框图。 6 is a block diagram of dynamically adjusting Lagrange parameters in a rate-distortion cost function.
图7是熵编码输出的框图。 Figure 7 is a block diagram of an entropy encoded output.
图8a是视频序列ballroom第0个视点第15帧图像使用JMVC原始编码方法的重建图像。 Fig. 8a is the reconstructed image of the 15th frame image of the 0th viewpoint of the video sequence ballroom using the JMVC original coding method.
图8b是视频序列ballroom第0个视点第15帧图像使用本发明方法的重建图像。 Fig. 8b is the reconstructed image of the 15th frame image of the 0th viewpoint of the video sequence ballroom using the method of the present invention.
图9是视频序列ballroom使用JMVC原始编码方法和本发明方法在不同QP和不同视点情况下,码率、PSNR值、重建视频主观质量评价分数差(DM0S)的对比结果 Figure 9 is the comparison result of the video sequence ballroom using the JMVC original encoding method and the method of the present invention under different QP and different viewpoints, the bit rate, PSNR value, and the difference in subjective quality evaluation score (DMOS) of the reconstructed video
图10a是视频序列race1第1个视点第35帧图像使用JMVC原始编码方法的重建图像。 Fig. 10a is the reconstructed image of the 35th frame image of the first viewpoint of the video sequence race1 using the JMVC original coding method.
图10b是视频序列race1第1个视点第35帧图像使用本发明方法的重建图像 Figure 10b is the reconstructed image of the 35th frame image of the first viewpoint of the video sequence race1 using the method of the present invention
图11是视频序列race1使用JMVC原始编码方法和本发明方法在不同QP和不同视点情况下,码率、PSNR值、重建视频主观质量评价分数差(DM0S)的对比结果 Fig. 11 is the comparison result of video sequence race1 using JMVC original coding method and the method of the present invention under different QP and different viewpoints, bit rate, PSNR value, reconstructed video subjective quality evaluation score difference (DMOS)
图12a是视频序列Crowd第2个视点第45帧图像使用JMVC原始编码方法的重建图像。 Fig. 12a is the reconstructed image of the 45th frame image of the second viewpoint of the video sequence Crowd using the JMVC original encoding method.
图12b是视频序列Crowd第2个视点第45帧图像使用本发明方法的重建图像。 Fig. 12b is the reconstructed image of the 45th frame image of the second viewpoint of the video sequence Crowd using the method of the present invention.
图13是视频序列Crowd使用JMVC原始编码方法和本发明方法在不同QP和不同视点情况下,码率、PSNR值、重建视频平均主观评分差值(DM0S)的对比结果。 Figure 13 shows the comparison results of video sequence Crowd using the JMVC original coding method and the method of the present invention under different QP and different viewpoints, bit rate, PSNR value, and reconstructed video average subjective score difference (DMOS).
具体实施方式 Detailed ways
以下结合附图对本发明的优选实施例作进一步的详细说明: Below in conjunction with accompanying drawing, preferred embodiment of the present invention is described in further detail:
实施例一: Embodiment one:
本实施例利用视觉感知特性指导多视点视频编码量化过程的方法,参见图1,包括以下步骤: In this embodiment, the method of using visual perception characteristics to guide the quantization process of multi-viewpoint video coding, as shown in FIG. 1, includes the following steps:
(1) 读取输入视频序列每一帧的亮度值大小,建立频域的恰可辨失真阈值模型, (1) Read the brightness value of each frame of the input video sequence, and establish a just discernable distortion threshold model in the frequency domain,
(2) 输入视频序列每一帧经过视点内和视点间的预测, (2) Each frame of the input video sequence undergoes intra-viewpoint and inter-viewpoint prediction,
(3) 对残差数据进行离散余弦变换, (3) Discrete cosine transform is performed on the residual data,
(4) 动态调节当前帧中每个宏块的量化步长, (4) Dynamically adjust the quantization step size of each macroblock in the current frame,
(5) 动态调节率失真优化过程中的拉格朗日参数, (5) Lagrangian parameters in the dynamic adjustment rate-distortion optimization process,
(6) 对量化的数据进行熵编码,形成码流通过网络传输。 (6) Entropy encoding is performed on the quantized data to form a code stream for transmission through the network.
实施例二:本实施例与实施例一基本相同,特别之处如下: Embodiment 2: This embodiment is basically the same as Embodiment 1, and the special features are as follows:
上述步骤(1)中建立频域JND模型包括四个模型,参见图2: The establishment of the frequency domain JND model in the above step (1) includes four models, see Figure 2:
(1-1)空间对比灵敏度函数模型是根据人眼的带通特性曲线,对于特定空间频率 

空间频率

其中,![]()



![]()

由于人眼视觉敏感度具有方向性,对水平和垂直方向比较敏感,对其他方向的敏感度相对小些。由此加上方向的调制因子可得: Since the visual sensitivity of the human eye is directional, it is more sensitive to horizontal and vertical directions, and less sensitive to other directions. Add the modulation factor of the direction to get:


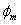
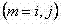

最后加上控制参数

在多视点编码过程中,由于存在8×8和4×4大小的DCT变换,故参数有所区别。在实验中,对于8×8块尺寸的DCT编码格式,


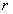



(1-2)亮度掩盖效应模型是根据实验,人眼视觉感知敏感度在中间灰度值区域比在较黑和较亮的背景区域更加敏感,最后拟合出亮度掩盖效应曲线,其表达式为: (1-2) The brightness masking effect model is based on experiments. The human visual perception sensitivity is more sensitive in the middle gray value area than in the darker and brighter background areas. Finally, the brightness masking effect curve is fitted, and its expression for:

其中
(1-3)纹理掩盖效应模型是根据图像纹理性的不同,可将图像分为三个区域:边界区,平滑区和纹理区。人眼依次对其敏感度降低。通常利用canny算子分出图像的各个区域。 (1-3) The texture masking effect model divides the image into three areas according to the texture of the image: boundary area, smooth area and texture area. The human eye becomes less sensitive to it in turn. The canny operator is usually used to separate the various regions of the image.
利用canny算子求出的边缘像素密度如下: The edge pixel density obtained by using the canny operator is as follows:

其中,
利用边缘像素密度将图像块划分为平坦区,纹理区和边缘区,图像块分类的依据公式如下: Use edge pixel density The image block is divided into flat area, texture area and edge area, and the basis formula for image block classification is as follows:

对于纹理区域,眼睛对低频部分失真不敏感,但高频部分适当进行保留。故得到对比掩盖的估计因子为: For textured areas, the eye is not sensitive to distortion in the low frequency part, but the high frequency part is properly preserved. Therefore, the estimated factor for contrast masking is:

其中(
由于空间对比灵敏度函数效应和亮度效应的重叠效应,得到最终掩盖效应因子为: Due to the overlapping effect of the spatial contrast sensitivity function effect and the brightness effect, the final masking effect factor is obtained as:
其中,




(1-4)时间对比灵敏度函数模型是根据实验测得时域掩盖效应的调制因子为: (1-4) The time-contrast sensitivity function model is based on the experimentally measured modulation factor of the time-domain masking effect:

其中,表示时间频率,






其中,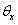


![]()

![]()
视网膜上图像的速度
其中,





(1-5)四种因子的加权乘积即构成当前编码帧的恰可辨失真阈值,其表达式为: (1-5) The weighted product of the four factors constitutes the just discernible distortion threshold of the current coded frame, and its expression is:

其中,



上述步骤(2)是对输入视频序列进行视点间/内预测,参见图3,其具体步骤如下: Above-mentioned step (2) is to carry out inter/intra-viewpoint prediction to input video sequence, referring to Fig. 3, its specific steps are as follows:
(2-1)视点内帧间/内预测是通过视点内的帧间预测去除当前帧的时间冗余,通过视点内的帧内预测去除当前帧的空间冗余。在帧内预测和帧间预测中选择率失真优化函数最小的那种预测方式。其中率失真优化函数表达式为: (2-1) Intra-view inter/intra prediction is to remove the temporal redundancy of the current frame through intra-view inter prediction, and remove the spatial redundancy of the current frame through intra-view intra prediction. The prediction method with the smallest rate-distortion optimization function is selected in intra-frame prediction and inter-frame prediction. The expression of the rate-distortion optimization function is:

其中

(2-2)进行视点间的预测是由于本方法是编码多个视点,通过视点间的对应帧进行预测当前帧,可以去除视点间的冗余信息。 (2-2) Inter-viewpoint prediction is performed because this method encodes multiple viewpoints, and predicts the current frame through corresponding frames between viewpoints, which can remove redundant information between viewpoints.
(2-3)比较视点间和视点内的编码代价,在视点内预测中选择最佳的预测方式再和视点间的预测方式比较,选择率失真优化代价函数最小的预测方式为最佳预测方式。充分考虑视点间和视点内的冗余特性,选择合适的预测方式进一步提高视频压缩效率。 (2-3) Compare the encoding cost between views and within views, select the best prediction method in intra-view prediction and compare it with the prediction method between views, and choose the prediction method with the smallest rate-distortion optimization cost function as the best prediction method . Fully consider the redundant characteristics between views and within views, and select the appropriate prediction method to further improve the video compression efficiency.
上述步骤(3)对残差数据进行离散余弦变换,参见图4,其具体步骤如下: Above-mentioned step (3) carries out discrete cosine transform to residual data, referring to Fig. 4, its concrete steps are as follows:
(3-1)编码块大小的判决,在多视点编码方法中编码块大小有

(3-2)对应的DCT变换,对于变换块采用


上述步骤(4)动态调节当前帧中每个宏块的量化步长,参见图5,其具体步骤如下: Above-mentioned step (4) dynamically adjusts the quantization step size of each macroblock in the current frame, referring to Fig. 5, its specific steps are as follows:
(4-1)通过已建立的JND模型,求出当前帧的平均JND值,平均JND阈值为: (4-1) Calculate the average JND value of the current frame through the established JND model, and the average JND threshold is:

其中,



(4-2)当前宏块的JND均值,第M个宏块的平均JND阈值表达为: (4-2) The JND mean value of the current macroblock, the average JND threshold value of the Mth macroblock is expressed as:

(4-3)动态调节当前宏块的量化步长,恰可辨失真阈值反映了人眼对一幅图像各个部分的敏感度的不同,因此可以根据恰可辨失真阈值的不同来动态调节各宏块的量化步长。对于人眼不敏感的地方,将量化步长适当的调大,否则,量化值不变。提出的量化参数调节为: (4-3) Dynamically adjust the quantization step size of the current macroblock. The just discernible distortion threshold reflects the sensitivity of the human eye to each part of an image, so each part can be dynamically adjusted according to the difference of the just discernible distortion threshold. The quantization step size of the macroblock. For places where the human eye is not sensitive, the quantization step size should be increased appropriately, otherwise, the quantization value will remain unchanged. The proposed quantization parameter tuning is:

其中,


其中,
上述步骤(5)动态调节率失真优化过程中的拉格朗日参数,参见图6,其具体操作步骤如下: The above step (5) dynamically adjusts the Lagrangian parameters in the rate-distortion optimization process, see Figure 6, and its specific operation steps are as follows:
(5-1)计算并比较当前帧的JND均值和当前编码宏块的JND均值,为下一步对拉格朗日参数的加权提供依据。 (5-1) Calculate and compare the average JND value of the current frame and the average JND value of the current coded macroblock to provide a basis for the weighting of the Lagrangian parameters in the next step.
(5-2)调整朗格朗日参数,前面调节了量化参数,拉格朗日率失真优化中的失真值和码率发生变化,此时再用原有的拉格朗日参数值,就不能保证是最优解。同时对应加权拉格朗日参数,能使代价函数重新达到最优,调整后的
其中,

(5-3)将调整后的拉格朗日参数代入到率失真优化代价函数中,其表达式如下: (5-3) Substituting the adjusted Lagrangian parameters into the rate-distortion optimization cost function, the expression is as follows:

其中


上述步骤(6)对量化的数据进行熵编码,形成码流通过网络传输,参见图7,其具体步骤如下: The above step (6) entropy-encodes the quantized data to form a code stream for transmission through the network, see Figure 7, the specific steps are as follows:
(6-1)对量化的数据进行熵编码,这样使得量化的数据能被二进制码流最有效的表示,去除了量化数据的统计冗余。 (6-1) Entropy encoding is performed on the quantized data, so that the quantized data can be most effectively represented by the binary code stream, and the statistical redundancy of the quantized data is removed.
(6-2)将熵编码形成的码流通过网络传输,实现视频的传输。在经过视觉感知特性处理的编码方法由于其占用带宽小,能够更好的适应网络传输。 (6-2) Transmit the code stream formed by entropy coding through the network to realize video transmission. The encoding method processed by visual perception characteristics can better adapt to network transmission because of its small bandwidth occupation.
下面进行大量仿真实验来评估本文所提出的利用视觉特性的多视点视频编码方法的性能。在配置为Intel Pentium 4 CPU 3.00GHz, 512M Internal Memory, Intel 8254G Express Chipset Family, Windows XP Operation System的PC机上编解码多视点视频序列ballroom、race1、crowd的前48帧,其中,BASIC QP设为20,24,28,32,实验平台选用多视点视频编解码参考软件JMVC,编解码预测结构选用HHI-IBBBP,视点间预测方式采用双向预测方式。
A large number of simulation experiments are carried out below to evaluate the performance of the multi-view video coding method proposed in this paper using visual characteristics. On a PC configured with
视频序列ballroom的实验结果如图8a~8b、图9所示。图8a是视频序列ballroom在量化参数QP=24的情况下,第0个视点第15帧图像使用JMVC原始编码方法的重建图像,重建视频图像的PSNR=40.31dB。图8b是视频序列ballroom在量化参数QP=24的情况下,第0个视点第15帧图像使用本发明方法的重建视频图像,重建视频图像的PSNR=40.10dB。图9是视频序列ballroom使用JMVC原始编码和本发明两种方法,在不同QP和不同视点的情况下,码率、PSNR值、码率节省百分比、重建视频主观质量评价分数差(DM0S)、平均码率节省百分比的统计结果。可以看出,视频序列ballroom在不同QP下,使用本发明方法的编码码率比使用JMVC原始编码方法的编码码率节省了7.47%~9.16%,JMVC原始编码方法和本发明方法的视频主观质量评价分数差为0.03~0.07,可以认为主观质量保持不变。 The experimental results of the video sequence ballroom are shown in Figures 8a-8b and Figure 9. Figure 8a is the reconstructed image of the video sequence ballroom in the case of the quantization parameter QP=24, the 15th frame image of the 0th viewpoint using the JMVC original coding method, and the PSNR of the reconstructed video image is 40.31dB. Fig. 8b is the reconstructed video image of the 15th frame image of the 0th viewpoint using the method of the present invention in the case of the quantization parameter QP=24 of the video sequence ballroom, and the PSNR of the reconstructed video image is 40.10dB. Figure 9 shows the video sequence ballroom using JMVC original encoding and the two methods of the present invention, in the case of different QP and different viewpoints, bit rate, PSNR value, bit rate saving percentage, reconstructed video subjective quality evaluation score difference (DMOS), average Statistical result of bit rate saving percentage. It can be seen that, under different QPs for the video sequence ballroom, the encoding rate using the method of the present invention is 7.47% to 9.16% lower than that using the original encoding method of JMVC, and the subjective video quality of the original encoding method of JMVC and the method of the present invention are The evaluation score difference is 0.03-0.07, and it can be considered that the subjective quality remains unchanged.
视频序列race1的实验结果如图10a~10b、图11所示。图10a是视频序列race1在量化参数QP=24的情况下,第1个视点第25帧图像使用JMVC原始编码方法的重建视频图像,重建视频图像的PSNR=41.15dB。图10b是视频序列race1在量化参数QP=24的情况下,第1个视点第36帧图像使用JMVC原始编码方法的重建视频图像,重建视频图像的PSNR=40.51dB。图11是视频序列race1使用JMVC原始编码和本发明两种方法,在不同QP和不同视点的情况下,码率、PSNR值、码率节省百分比、重建视频主观质量评价分数差(DM0S)、平均码率节省百分比的统计结果。可以看出,视频序列race1在不同QP下,使用本发明方法的编码码率比使用JMVC原始编码方法的编码码率节省了10.77%~12.35%,JMVC原始编码方法和本发明方法的视频主观质量评价分数差为0.06~0.09,可以认为主观质量保持不变。 The experimental results of the video sequence race1 are shown in Figures 10a-10b and Figure 11. Figure 10a is the reconstructed video image of the 25th frame image of the first viewpoint using the JMVC original coding method in the case of the video sequence race1 with the quantization parameter QP=24, and the PSNR of the reconstructed video image is 41.15dB. Figure 10b shows the reconstructed video image of the 36th frame image of the first viewpoint using the JMVC original coding method in the case of the video sequence race1 with the quantization parameter QP=24, and the PSNR of the reconstructed video image is 40.51dB. Figure 11 shows the video sequence race1 using JMVC original encoding and the two methods of the present invention, in the case of different QP and different viewpoints, the bit rate, PSNR value, bit rate saving percentage, reconstructed video subjective quality evaluation score difference (DMOS), average Statistical result of bit rate saving percentage. It can be seen that, under different QPs for the video sequence race1, the coding rate using the method of the present invention is 10.77% to 12.35% lower than the coding rate using the JMVC original coding method, and the subjective video quality of the JMVC original coding method and the inventive method The evaluation score difference is 0.06-0.09, and it can be considered that the subjective quality remains unchanged.
视频序列crowd的实验结果如图12a~12b、图13所示。图12a是视频序列crowd在量化参数QP=35的情况下,第2个视点第45帧图像使用JMVC原始编码方法的重建视频图像,重建视频图像的PSNR=33.77dB。图12b是视频序列crowd在量化参数QP=35的情况下,第2个视点第45帧图像使用JMVC原始编码方法的重建视频图像,重建视频图像的PSNR=33.12dB。图13是视频序列crowd使用JMVC原始编码和本发明两种方法,在不同QP和不同视点的情况下,码率、PSNR值、码率节省百分比、重建视频主观质量评价分数差(DM0S)、平均码率节省百分比的统计结果。可以看出,视频序列crowd在不同QP下,使用本发明方法的编码码率比使用JMVC原始编码方法的编码码率节省了8.95%~9.83%,JMVC原始编码方法和本发明方法的视频主观质量评价分数差为0.03~0.08,可以认为主观质量保持不变。 The experimental results of video sequence crowd are shown in Figures 12a-12b and Figure 13. Fig. 12a is the reconstructed video image of the 45th frame image of the second viewpoint using the JMVC original coding method in the case of the video sequence crowd with the quantization parameter QP=35, and the PSNR of the reconstructed video image is 33.77dB. Figure 12b shows the reconstructed video image of the 45th frame image of the second viewpoint using the JMVC original coding method when the quantization parameter QP=35 of the video sequence crowd, and the PSNR of the reconstructed video image is 33.12dB. Figure 13 shows the video sequence crowd using JMVC original encoding and the two methods of the present invention, in the case of different QP and different viewpoints, bit rate, PSNR value, bit rate saving percentage, reconstructed video subjective quality evaluation score difference (DMOS), average Statistical result of bit rate saving percentage. It can be seen that the video sequence crowd is under different QPs, and the encoding rate using the method of the present invention is 8.95% to 9.83% lower than that using the JMVC original encoding method. The subjective video quality of the JMVC original encoding method and the inventive method The evaluation score difference is 0.03 to 0.08, and it can be considered that the subjective quality remains unchanged.
结合以上各图表可以看出,本发明通过建立DCT域的JND模型,并将其运用到多视点视频编码框架量化过程和率失真优化过程,在保证主观质量不变的情况下,大幅度降低多视点视频编码码率,提高了多视点视频编码的压缩效率。 Combining the above charts, it can be seen that the present invention establishes a JND model in the DCT domain and applies it to the quantization process and rate-distortion optimization process of the multi-viewpoint video coding framework. Viewpoint video coding bit rate, which improves the compression efficiency of multi-viewpoint video coding.
Claims (7)






























Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210402003.9A CN103124347B (en) | 2012-10-22 | 2012-10-22 | Vision perception characteristic is utilized to instruct the method for multiple view video coding quantizing process |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210402003.9A CN103124347B (en) | 2012-10-22 | 2012-10-22 | Vision perception characteristic is utilized to instruct the method for multiple view video coding quantizing process |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN103124347A true CN103124347A (en) | 2013-05-29 |
| CN103124347B CN103124347B (en) | 2016-04-27 |
Family
ID=48455183
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201210402003.9A Expired - Fee Related CN103124347B (en) | 2012-10-22 | 2012-10-22 | Vision perception characteristic is utilized to instruct the method for multiple view video coding quantizing process |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN103124347B (en) |
Cited By (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103475875A (en) * | 2013-06-27 | 2013-12-25 | 上海大学 | Image adaptive measuring method based on compressed sensing |
| CN103716623A (en) * | 2013-12-17 | 2014-04-09 | 北京大学深圳研究生院 | Video compression encoding-and-decoding method and encoder-decoder on the basis of weighting quantification |
| CN104219526A (en) * | 2014-09-01 | 2014-12-17 | 国家广播电影电视总局广播科学研究院 | HEVC rate distortion optimization algorithm based on just-noticeable perception quality judging criterion |
| CN104349167A (en) * | 2014-11-17 | 2015-02-11 | 电子科技大学 | Adjustment method of video code rate distortion optimization |
| CN104469386A (en) * | 2014-12-15 | 2015-03-25 | 西安电子科技大学 | Stereoscopic video perception and coding method for just-noticeable error model based on DOF |
| CN104488266A (en) * | 2013-06-27 | 2015-04-01 | 北京大学深圳研究生院 | AVS Video Compression Encoding Method and Encoder |
| CN105245890A (en) * | 2015-10-16 | 2016-01-13 | 北京工业大学 | Efficient video encoding method based on vision attention priority |
| CN105704497A (en) * | 2016-01-30 | 2016-06-22 | 上海大学 | Fast select algorithm for coding unit size facing 3D-HEVC |
| CN105850123A (en) * | 2013-12-19 | 2016-08-10 | 汤姆逊许可公司 | Method and device for encoding a high-dynamic range image |
| CN106454386A (en) * | 2016-10-26 | 2017-02-22 | 广东电网有限责任公司电力科学研究院 | JND (Just-noticeable difference) based video encoding method and device |
| CN107027031A (en) * | 2016-01-31 | 2017-08-08 | 西安电子科技大学 | A method and device for encoding video images |
| CN107094251A (en) * | 2017-03-31 | 2017-08-25 | 浙江大学 | A kind of video, image coding/decoding method and device adjusted based on locus adaptive quality |
| CN107197266A (en) * | 2017-06-26 | 2017-09-22 | 杭州当虹科技有限公司 | A kind of HDR method for video coding |
| CN108111852A (en) * | 2018-01-12 | 2018-06-01 | 东华大学 | Towards the double measurement parameter rate distortion control methods for quantifying splits' positions perceptual coding |
| CN108574841A (en) * | 2017-03-07 | 2018-09-25 | 北京金山云网络技术有限公司 | A coding method and device based on adaptive quantization parameters |
| CN110024382A (en) * | 2017-07-19 | 2019-07-16 | 联发科技股份有限公司 | The method and apparatus for reducing the pseudomorphism at the noncoherent boundary in encoded virtual reality image |
| CN110113606A (en) * | 2019-03-12 | 2019-08-09 | 佛山市顺德区中山大学研究院 | A kind of method, apparatus and equipment of removal human eye perception redundant video coding |
| CN113489983A (en) * | 2021-06-11 | 2021-10-08 | 浙江智慧视频安防创新中心有限公司 | Method and device for determining block coding parameters based on correlation comparison |
| CN113850879A (en) * | 2021-06-01 | 2021-12-28 | 天翼智慧家庭科技有限公司 | Method for improving compression ratio of static background video based on background modeling technology |
| CN114747214A (en) * | 2019-10-21 | 2022-07-12 | 弗劳恩霍夫应用研究促进协会 | Weighted PSNR quality metric for video encoded data |
| CN115174898A (en) * | 2022-06-27 | 2022-10-11 | 福州大学 | Rate distortion optimization method based on visual perception |
| CN115967806A (en) * | 2023-03-13 | 2023-04-14 | 阿里巴巴(中国)有限公司 | Data frame coding control method and system and electronic equipment |
| WO2023155445A1 (en) * | 2022-02-21 | 2023-08-24 | 翱捷科技股份有限公司 | Rate distortion optimization method and apparatus based on motion detection |
| CN119413128A (en) * | 2025-01-06 | 2025-02-11 | 交通运输部天津水运工程科学研究所 | Intelligent monitoring method for rail deformation of terminal equipment |
| CN119815012A (en) * | 2023-10-09 | 2025-04-11 | 浙江大学 | A method and device for processing image blocks in immersive media coding |
| CN120751139A (en) * | 2025-08-15 | 2025-10-03 | 华侨大学 | Screen content video coding perception code rate control method and device based on DCT domain JND |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1968419A (en) * | 2005-11-16 | 2007-05-23 | 三星电子株式会社 | Image encoding method and apparatus and image decoding method and apparatus using characteristics of the human visual system |
| CN101710995A (en) * | 2009-12-10 | 2010-05-19 | 武汉大学 | Video coding system based on vision characteristic |
| CN101854555A (en) * | 2010-06-18 | 2010-10-06 | 上海交通大学 | Video Coding System Based on Adaptive Adjustment of Prediction Residual |
| CN102420988A (en) * | 2011-12-02 | 2012-04-18 | 上海大学 | Multi-view video coding system utilizing visual characteristics |
| CN102724525A (en) * | 2012-06-01 | 2012-10-10 | 宁波大学 | Depth video coding method on basis of foveal JND (just noticeable distortion) model |
-
2012
- 2012-10-22 CN CN201210402003.9A patent/CN103124347B/en not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1968419A (en) * | 2005-11-16 | 2007-05-23 | 三星电子株式会社 | Image encoding method and apparatus and image decoding method and apparatus using characteristics of the human visual system |
| CN101710995A (en) * | 2009-12-10 | 2010-05-19 | 武汉大学 | Video coding system based on vision characteristic |
| CN101854555A (en) * | 2010-06-18 | 2010-10-06 | 上海交通大学 | Video Coding System Based on Adaptive Adjustment of Prediction Residual |
| CN102420988A (en) * | 2011-12-02 | 2012-04-18 | 上海大学 | Multi-view video coding system utilizing visual characteristics |
| CN102724525A (en) * | 2012-06-01 | 2012-10-10 | 宁波大学 | Depth video coding method on basis of foveal JND (just noticeable distortion) model |
Cited By (44)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104488266A (en) * | 2013-06-27 | 2015-04-01 | 北京大学深圳研究生院 | AVS Video Compression Encoding Method and Encoder |
| CN104488266B (en) * | 2013-06-27 | 2018-07-06 | 北京大学深圳研究生院 | AVS Video Compression Encoding Method and Encoder |
| CN103475875A (en) * | 2013-06-27 | 2013-12-25 | 上海大学 | Image adaptive measuring method based on compressed sensing |
| CN103475875B (en) * | 2013-06-27 | 2017-02-08 | 上海大学 | Image adaptive measuring method based on compressed sensing |
| CN103716623B (en) * | 2013-12-17 | 2017-02-15 | 北京大学深圳研究生院 | Video compression encoding-and-decoding method and encoder-decoder on the basis of weighting quantification |
| CN103716623A (en) * | 2013-12-17 | 2014-04-09 | 北京大学深圳研究生院 | Video compression encoding-and-decoding method and encoder-decoder on the basis of weighting quantification |
| US10574987B2 (en) | 2013-12-19 | 2020-02-25 | Interdigital Vc Holdings, Inc. | Method and device for encoding a high-dynamic range image |
| CN105850123B (en) * | 2013-12-19 | 2019-06-18 | 汤姆逊许可公司 | Method and apparatus for encoding high dynamic range images |
| CN105850123A (en) * | 2013-12-19 | 2016-08-10 | 汤姆逊许可公司 | Method and device for encoding a high-dynamic range image |
| CN104219526A (en) * | 2014-09-01 | 2014-12-17 | 国家广播电影电视总局广播科学研究院 | HEVC rate distortion optimization algorithm based on just-noticeable perception quality judging criterion |
| CN104219526B (en) * | 2014-09-01 | 2017-05-24 | 国家广播电影电视总局广播科学研究院 | HEVC rate distortion optimization algorithm based on just-noticeable perception quality judging criterion |
| CN104349167A (en) * | 2014-11-17 | 2015-02-11 | 电子科技大学 | Adjustment method of video code rate distortion optimization |
| CN104349167B (en) * | 2014-11-17 | 2018-01-19 | 电子科技大学 | A kind of method of adjustment of Video coding rate-distortion optimization |
| CN104469386B (en) * | 2014-12-15 | 2017-07-04 | 西安电子科技大学 | A kind of perception method for encoding stereo video of the proper appreciable error model based on DOF |
| CN104469386A (en) * | 2014-12-15 | 2015-03-25 | 西安电子科技大学 | Stereoscopic video perception and coding method for just-noticeable error model based on DOF |
| CN105245890B (en) * | 2015-10-16 | 2018-01-19 | 北京工业大学 | A kind of efficient video coding method of view-based access control model attention rate priority |
| CN105245890A (en) * | 2015-10-16 | 2016-01-13 | 北京工业大学 | Efficient video encoding method based on vision attention priority |
| CN105704497A (en) * | 2016-01-30 | 2016-06-22 | 上海大学 | Fast select algorithm for coding unit size facing 3D-HEVC |
| CN105704497B (en) * | 2016-01-30 | 2018-08-17 | 上海大学 | Coding unit size fast selection algorithm towards 3D-HEVC |
| CN107027031A (en) * | 2016-01-31 | 2017-08-08 | 西安电子科技大学 | A method and device for encoding video images |
| CN106454386B (en) * | 2016-10-26 | 2019-07-05 | 广东电网有限责任公司电力科学研究院 | A kind of method and apparatus of the Video coding based on JND |
| CN106454386A (en) * | 2016-10-26 | 2017-02-22 | 广东电网有限责任公司电力科学研究院 | JND (Just-noticeable difference) based video encoding method and device |
| CN108574841A (en) * | 2017-03-07 | 2018-09-25 | 北京金山云网络技术有限公司 | A coding method and device based on adaptive quantization parameters |
| CN107094251A (en) * | 2017-03-31 | 2017-08-25 | 浙江大学 | A kind of video, image coding/decoding method and device adjusted based on locus adaptive quality |
| CN107197266A (en) * | 2017-06-26 | 2017-09-22 | 杭州当虹科技有限公司 | A kind of HDR method for video coding |
| CN110024382B (en) * | 2017-07-19 | 2022-04-12 | 联发科技股份有限公司 | Method and device for processing 360-degree virtual reality image |
| CN110024382A (en) * | 2017-07-19 | 2019-07-16 | 联发科技股份有限公司 | The method and apparatus for reducing the pseudomorphism at the noncoherent boundary in encoded virtual reality image |
| US11049314B2 (en) | 2017-07-19 | 2021-06-29 | Mediatek Inc | Method and apparatus for reduction of artifacts at discontinuous boundaries in coded virtual-reality images |
| CN108111852B (en) * | 2018-01-12 | 2020-05-29 | 东华大学 | Two-measure parameter rate-distortion control method for quantized block compressed sensing coding |
| CN108111852A (en) * | 2018-01-12 | 2018-06-01 | 东华大学 | Towards the double measurement parameter rate distortion control methods for quantifying splits' positions perceptual coding |
| CN110113606A (en) * | 2019-03-12 | 2019-08-09 | 佛山市顺德区中山大学研究院 | A kind of method, apparatus and equipment of removal human eye perception redundant video coding |
| CN114747214A (en) * | 2019-10-21 | 2022-07-12 | 弗劳恩霍夫应用研究促进协会 | Weighted PSNR quality metric for video encoded data |
| US12126812B2 (en) | 2019-10-21 | 2024-10-22 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for improved video quality assessment |
| CN113850879A (en) * | 2021-06-01 | 2021-12-28 | 天翼智慧家庭科技有限公司 | Method for improving compression ratio of static background video based on background modeling technology |
| CN113489983A (en) * | 2021-06-11 | 2021-10-08 | 浙江智慧视频安防创新中心有限公司 | Method and device for determining block coding parameters based on correlation comparison |
| WO2023155445A1 (en) * | 2022-02-21 | 2023-08-24 | 翱捷科技股份有限公司 | Rate distortion optimization method and apparatus based on motion detection |
| CN115174898A (en) * | 2022-06-27 | 2022-10-11 | 福州大学 | Rate distortion optimization method based on visual perception |
| CN115967806A (en) * | 2023-03-13 | 2023-04-14 | 阿里巴巴(中国)有限公司 | Data frame coding control method and system and electronic equipment |
| CN119815012A (en) * | 2023-10-09 | 2025-04-11 | 浙江大学 | A method and device for processing image blocks in immersive media coding |
| CN119815012B (en) * | 2023-10-09 | 2025-12-09 | 浙江大学 | Method and device for processing image block in immersive media coding |
| CN119413128A (en) * | 2025-01-06 | 2025-02-11 | 交通运输部天津水运工程科学研究所 | Intelligent monitoring method for rail deformation of terminal equipment |
| CN119413128B (en) * | 2025-01-06 | 2025-03-07 | 交通运输部天津水运工程科学研究所 | Intelligent monitoring method for deformation of dock equipment track |
| CN120751139A (en) * | 2025-08-15 | 2025-10-03 | 华侨大学 | Screen content video coding perception code rate control method and device based on DCT domain JND |
| CN120751139B (en) * | 2025-08-15 | 2025-11-11 | 华侨大学 | A screen content video coding-aware bitrate control method and device based on DCT domain JND |
Also Published As
| Publication number | Publication date |
|---|---|
| CN103124347B (en) | 2016-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103124347B (en) | Vision perception characteristic is utilized to instruct the method for multiple view video coding quantizing process | |
| CN112825557B (en) | An adaptive perceptual spatiotemporal quantization method for video coding | |
| CN101827267B (en) | Code rate control method based on video image segmentation technology | |
| CN102186070B (en) | Method for realizing rapid video coding by adopting hierarchical structure anticipation | |
| CN104219525B (en) | Perception method for video coding based on conspicuousness and minimum discernable distortion | |
| CN106534862B (en) | Video coding method | |
| US9554139B2 (en) | Encoding/decoding apparatus and method using flexible deblocking filtering | |
| CN105049850B (en) | HEVC bit rate control methods based on area-of-interest | |
| CN102420988B (en) | Multi-view video coding system utilizing visual characteristics | |
| CN101729891B (en) | Method for encoding multi-view depth video | |
| WO2010078759A1 (en) | Method for image temporal and spatial resolution processing based on code rate control | |
| CN104853191B (en) | A kind of HEVC fast encoding method | |
| CN103096079B (en) | A kind of multi-view video rate control based on proper discernable distortion | |
| CN104378636B (en) | A kind of video encoding method and device | |
| CN106303521B (en) | A kind of HEVC Rate-distortion optimization method based on sensitivity of awareness | |
| CN106412572A (en) | Video stream encoding quality evaluation method based on motion characteristics | |
| CN104602028A (en) | Entire frame loss error concealment method for B frame of stereoscopic video | |
| CN108521572B (en) | A Residual Filtering Method Based on Pixel Domain JND Model | |
| CN109451310A (en) | A kind of Rate-distortion optimization method and device based on significance weighted | |
| CN101841723B (en) | Perceptual Video Compression Method Based on JND and AR Model | |
| CN102420990B (en) | Multi-view video-oriented fast coding method | |
| CN103634600A (en) | Video coding mode selection method and system based on SSIM evaluation | |
| CN101729883A (en) | Method for adaptively adjusting video decoding complexity | |
| JP2009135902A (en) | Encoding apparatus, encoding apparatus control method, and computer program | |
| CN101489141B (en) | An Adaptive Intra Macroblock Refresh Method Based on Subjective Quality-Distortion Prediction |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20160427 Termination date: 20211022 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |