CN114817425B - Method, device and equipment for classifying cold and hot data and readable storage medium - Google Patents
Method, device and equipment for classifying cold and hot data and readable storage medium Download PDFInfo
- Publication number
- CN114817425B CN114817425B CN202210740213.2A CN202210740213A CN114817425B CN 114817425 B CN114817425 B CN 114817425B CN 202210740213 A CN202210740213 A CN 202210740213A CN 114817425 B CN114817425 B CN 114817425B
- Authority
- CN
- China
- Prior art keywords
- data
- sub
- database
- parameter
- value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
- G06F16/285—Clustering or classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明提供了一种冷热数据分类的方法、装置、设备及可读存储介质,涉及数据存储技术领域。本申请中通过统计入库数据的访问特性以及入库数据本身所具有的价值大小,基于数据价值的改进的牛顿冷却定律的冷热数据分类模型计算入库数据在当前时刻下的温度,从而可以在任意时刻根据入库数据温度值的大小进行划分,将入库数据实时的划分为热数据、温数据、冷数据,基于冷热特性为数据的分层存储提供坚实的基础,有助于将数据价值高、访问频率高的数据放在高速存储设备中,将数据价值低、访问频率低的数据放在低速存储设备中,通过这种方式能够有效降低数据管理终端中海量数据的存储成本。

The present invention provides a method, device, device and readable storage medium for classifying cold and hot data, and relates to the technical field of data storage. In this application, by counting the access characteristics of the inbound data and the value of the inbound data itself, the temperature of the inbound data at the current moment is calculated based on the improved Newton's law of cooling data classification model of data value, so that the temperature of the inbound data can be calculated. At any time, it is divided according to the size of the temperature value of the storage data, and the storage data is divided into hot data, warm data, and cold data in real time. Data with high data value and high access frequency is placed in high-speed storage devices, and data with low data value and low access frequency is placed in low-speed storage devices. In this way, the storage cost of massive data in data management terminals can be effectively reduced.
Description
技术领域technical field
本发明涉及数据存储技术领域,具体而言,涉及一种冷热数据分类的方法、装置、设备及可读存储介质。The present invention relates to the technical field of data storage, and in particular, to a method, apparatus, device and readable storage medium for classifying cold and hot data.
背景技术Background technique
随着交通构筑物监测场景下长期的数据积累,传统的解决方案是不断扩容机器的存储容量或者增加更高性能的存储设备,然而这种方式伴随着严重的存储资源浪费、能耗上升。针对目前的现状,众多专家学者按照访问频度划分监测数据冷热特性,并基于数据冷热特性分类存储。但目前众多的冷热数据判定模F型更多考虑的是数据的访问特性,依据数据的访问特性来计算数据的温度,没有考虑数据本身的价值大小。With the long-term data accumulation in the traffic structure monitoring scenario, the traditional solution is to continuously expand the storage capacity of the machine or add higher-performance storage devices. However, this method is accompanied by serious waste of storage resources and increased energy consumption. In view of the current situation, many experts and scholars divide the monitoring data cold and hot characteristics according to the frequency of access, and classify and store them based on the cold and hot characteristics of the data. However, at present, many hot and cold data judgment models F-type more consider the access characteristics of data, and calculate the temperature of data according to the access characteristics of data, without considering the value of the data itself.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于提供一种冷热数据分类的方法、装置、设备及可读存储介质,以改善上述问题。为了实现上述目的,本发明采取的技术方案如下:The purpose of the present invention is to provide a method, apparatus, device and readable storage medium for classifying cold and hot data, so as to improve the above problems. In order to achieve the above object, the technical scheme adopted by the present invention is as follows:
第一方面,本申请提供了一种冷热数据分类的方法,包括:In a first aspect, the present application provides a method for classifying hot and cold data, including:
获取至少两个数据流信息,每个所述数据流信息包括入库数据以及所述入库数据对应的温度参数和第一时刻。At least two pieces of data flow information are acquired, and each of the data flow information includes storage data and a temperature parameter and a first time corresponding to the storage data.
判断所述入库数据是否被访问,若所述入库数据被访问,则获取第二时刻以及所述入库数据在所述第一时刻下对应的所述温度参数、数据价值增量、数据温度增量和数据价值权重;并根据所述温度参数、所述数据价值增量、所述数据温度增量和所述数据价值权重更新所述入库数据在所述第二时刻下对应的所述温度参数;所述第二时刻为所述入库数据被访问时的时间参数。Determine whether the inbound data is accessed, and if the inbound data is accessed, obtain the temperature parameter, data value increment, data corresponding to the second time and the inbound data at the first time temperature increment and data value weight; and according to the temperature parameter, the data value increment, the data temperature increment and the data value weight, update the corresponding data of the inbound data at the second moment. the temperature parameter; the second time is the time parameter when the inbound data is accessed.
基于所述入库数据对应的更新后的所述温度参数,对所述数据流信息进行冷热数据的分类。Based on the updated temperature parameters corresponding to the inbound data, the data flow information is classified into cold and hot data.
第二方面,本申请还提供了一种冷热数据分类的装置,包括获取模块、判断模块和分类模块,其中:In a second aspect, the present application also provides an apparatus for classifying cold and hot data, including an acquisition module, a judgment module and a classification module, wherein:
获取模块:用于获取至少两个数据流信息,每个所述数据流信息包括入库数据以及所述入库数据对应的温度参数和第一时刻。Acquisition module: used to acquire at least two pieces of data flow information, each of the data flow information includes storage data, and a temperature parameter and a first time corresponding to the storage data.
判断模块:用于判断所述入库数据是否被访问,若所述入库数据被访问,则获取第二时刻以及所述入库数据在所述第一时刻下对应的所述温度参数、数据价值增量、数据温度增量和数据价值权重;并根据所述温度参数、所述数据价值增量、所述数据温度增量和所述数据价值权重更新所述入库数据在所述第二时刻下对应的所述温度参数;所述第二时刻为所述入库数据被访问时的时间参数。Judgment module: for judging whether the inbound data is accessed, if the inbound data is accessed, obtain the second moment and the temperature parameters and data corresponding to the inbound data at the first moment value increment, data temperature increment and data value weight; and update the inbound data in the second according to the temperature parameter, the data value increment, the data temperature increment and the data value weight The temperature parameter corresponding to the time; the second time is the time parameter when the inbound data is accessed.
分类模块:用于基于所述入库数据对应的更新后的所述温度参数,对所述数据流信息进行冷热数据的分类。Classification module: used for classifying cold and hot data on the data flow information based on the updated temperature parameter corresponding to the storage data.
第三方面,本申请还提供了一种冷热数据分类的设备,包括:In a third aspect, the present application also provides a device for classifying cold and hot data, including:
存储器,用于存储计算机程序;memory for storing computer programs;
处理器,用于执行所述计算机程序时实现所述冷热数据分类的方法的步骤。The processor is configured to implement the steps of the method for classifying hot and cold data when executing the computer program.
第四方面,本申请还提供了一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述基于冷热数据分类的方法的步骤。In a fourth aspect, the present application further provides a readable storage medium, where a computer program is stored on the readable storage medium, and when the computer program is executed by a processor, the steps of the above-mentioned method for classifying cold and hot data are implemented.
本发明的有益效果为:The beneficial effects of the present invention are:
本申请中,通过统计入库数据的访问特性(如访问时间、访问频率等)以及入库数据本身所具有的价值大小,基于数据价值的改进的牛顿冷却定律的冷热数据分类模型计算出入库数据在当前时刻下的温度,从而可以在任意时刻根据入库数据温度值(即活跃程度)的大小进行划分,将入库数据实时的划分为热数据、温数据、冷数据,基于冷热特性为数据的分层存储提供坚实的基础,有助于将数据价值高、访问频率高的数据放在高速存储设备中,将数据价值低、访问频率低的数据放在低速存储设备中,通过这种方式能够有效降低数据管理终端中海量数据的存储成本。In this application, by counting the access characteristics of the inbound data (such as access time, access frequency, etc.) and the value of the inbound data itself, the cold and hot data classification model based on the improved Newton's law of cooling based on the value of the data calculates the inbound and outbound data. The temperature of the data at the current moment, so that it can be divided at any time according to the temperature value (that is, the activity level) of the inbound data, and the inbound data can be divided into hot data, warm data, and cold data in real time, based on the characteristics of cold and heat It provides a solid foundation for the hierarchical storage of data, which helps to put data with high data value and high access frequency in high-speed storage devices, and data with low data value and low access frequency in low-speed storage devices. This method can effectively reduce the storage cost of massive data in the data management terminal.
本发明的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明实施例了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。Other features and advantages of the present invention will be set forth in the description which follows, and, in part, will be apparent from the description, or may be learned by practice of embodiments of the invention. The objectives and other advantages of the invention may be realized and attained by the structure particularly pointed out in the written description, claims, and drawings.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the embodiments. It should be understood that the following drawings only show some embodiments of the present invention, and therefore do not It should be regarded as a limitation of the scope, and for those of ordinary skill in the art, other related drawings can also be obtained according to these drawings without any creative effort.
图1为本发明实施例中所述的冷热数据分类的方法流程示意图;1 is a schematic flowchart of a method for classifying cold and hot data according to an embodiment of the present invention;
图2为本发明实施例中所述的冷热数据分类的装置结构示意图;2 is a schematic structural diagram of an apparatus for classifying cold and hot data according to an embodiment of the present invention;
图3为本发明实施例中所述的冷热数据分类的设备结构示意图。FIG. 3 is a schematic structural diagram of a device for classifying cold and hot data according to an embodiment of the present invention.
图中:700-冷热数据分类的装置;710、获取模块;711、第一处理单元;712、第二处理单元;7121、第一子单元;7122、第二子单元;7123、第三子单元;7124、第四子单元;720、判断模块;721、获取子单元;722、第一计算单元;723、第二计算单元;724、第三计算单元;730、分类模块;800、冷热数据分类的设备;801、处理器;802、存储器;803、多媒体组件;804、I/O接口;805、通信组件。In the figure: 700 - apparatus for classifying hot and cold data; 710, acquisition module; 711, first processing unit; 712, second processing unit; 7121, first subunit; 7122, second subunit; 7123, third subunit unit; 7124, fourth subunit; 720, judgment module; 721, acquisition subunit; 722, first calculation unit; 723, second calculation unit; 724, third calculation unit; 730, classification module; 800, cold and
具体实施方式Detailed ways
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments These are some embodiments of the present invention, but not all embodiments. The components of the embodiments of the invention generally described and illustrated in the drawings herein may be arranged and designed in a variety of different configurations. Thus, the following detailed description of the embodiments of the invention provided in the accompanying drawings is not intended to limit the scope of the invention as claimed, but is merely representative of selected embodiments of the invention. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。It should be noted that like numerals and letters refer to like items in the following figures, so once an item is defined in one figure, it does not require further definition and explanation in subsequent figures. Meanwhile, in the description of the present invention, the terms "first", "second", etc. are only used to distinguish the description, and cannot be understood as indicating or implying relative importance.
首先,对本申请可适用的应用场景以及该应用场景下的系统架构进行介绍。本申请可以应用于数据管理终端基于数据的冷热属性进行存储的场景下,本申请中以交通构筑物的监测数据为例进行详细的说明。First, the applicable application scenarios of this application and the system architecture under the application scenarios are introduced. The present application can be applied to a scenario where the data management terminal stores data based on the cold and hot attributes of the data. In the present application, monitoring data of a traffic structure is taken as an example for detailed description.
实施例1:Example 1:
参见图1,图1所示为本实施例中所述冷热数据分类的方法流程示意图。本申请提供了一种冷热数据分类的方法包括步骤S1、步骤S2和步骤S3,其中:Referring to FIG. 1 , FIG. 1 shows a schematic flowchart of the method for classifying cold and hot data in this embodiment. The present application provides a method for classifying hot and cold data, including step S1, step S2 and step S3, wherein:
步骤S1、获取至少两个数据流信息,每个所述数据流信息包括入库数据以及所述入库数据对应的温度参数和第一时刻。Step S1: Acquire at least two data flow information, each of which includes storage data, a temperature parameter and a first time corresponding to the storage data.
可以理解的是,在本步骤中,数据管理终端通过传感器、监测设备等工具实时采集入库数据,以及入库数据对应的温度参数和第一时刻构成数据流信息,第一时刻的初始值为数据管理终端检验到入库数据的时间,入库数据即为传感器或监测设备检测到的实验数据,入库数据刚传入数据管理终端时的温度参数为客户端输入的自定义温度。It can be understood that in this step, the data management terminal collects the storage data in real time through sensors, monitoring equipment and other tools, and the temperature parameters corresponding to the storage data and the first moment constitute data flow information, and the initial value of the first moment is The time from the data management terminal inspection to the storage data, the storage data is the experimental data detected by the sensor or monitoring equipment, and the temperature parameter when the storage data is just transmitted to the data management terminal is the user-defined temperature input by the client.
在另一示例性实施例中,步骤S1中还包括步骤S101和步骤S102,其中:In another exemplary embodiment, step S1 further includes step S101 and step S102, wherein:
步骤S101、分别判断每个所述数据流信息是否在预设的归类条件内,若所述数据流信息在所述预设的归类条件内,则得到至少一个子数据库,所述子数据库为所述数据流信息进行聚类处理划分后的具有同一属性的数据集合;所述归类条件为划分同一属性数据的信息。Step S101, respectively determine whether each of the data flow information is within the preset classification conditions, if the data flow information is within the preset classification conditions, then obtain at least one sub-database, the sub-database The data set having the same attribute after clustering processing is performed for the data flow information; the classification condition is the information of dividing the data of the same attribute.
可以理解的是,在本步骤中,根据归类条件和数据流信息中所包含的入库数据对数据流信息进行分类。本实施例中的归类条件为入库数据的类型信息,假设归类条件为交通构筑物场景下的索力、风向这两种类型的信息,并根据上述归类条件中的两种分类情况,将数据流信息分成两个子数据库。It can be understood that, in this step, the data flow information is classified according to the classification conditions and the storage data included in the data flow information. The classification condition in this embodiment is the type information of the storage data. It is assumed that the classification condition is the two types of information of cable force and wind direction in the traffic structure scene, and according to the two classification conditions in the above classification conditions, Divide the data flow information into two sub-databases.
步骤S102、基于所述第一时刻,判断每个所述子数据库中是否存在缺失数据,若不存在缺失数据,则分别对每个所述子数据库进行剔除,并更新每个所述子数据库为剔除后的子数据库;若存在缺失数据,则对每个所述子数据库进行补全,并更新所述子数据库为补全后的子数据库。Step S102, based on the first moment, determine whether there is missing data in each of the sub-databases, if there is no missing data, remove each of the sub-databases respectively, and update each of the sub-databases as: The deleted subdatabase; if there is missing data, complete each of the subdatabases, and update the subdatabase to be the completed subdatabase.
可以理解的是,在本步骤中,基于时间序列根据第一时刻的分别判断索力、风向这两种类型的数据是否存在某一时段或时刻的缺失,若果存在缺失的话就对子数据库进行补全并更新子数据库;数据补全的方法可以利用零、平均值、缺失点邻近值等数字进行填充,还可以采用线性插值、拉格朗日插值等算法进行填充。若不存在缺失的话就对子数据库中的异常值进行剔除并更新子数据库,异常值的剔除可以通过设置剔除阈值的上、下限等方式来对子数据库中进行剔除。It can be understood that, in this step, based on the time series, it is determined whether the two types of data of cable force and wind direction are missing in a certain period or time based on the first moment. Completion and update of sub-databases; data completion methods can be filled with numbers such as zero, average, and adjacent values of missing points, and can also be filled with algorithms such as linear interpolation and Lagrangian interpolation. If there is no missing, the outliers in the sub-database will be eliminated and the sub-database will be updated. For the elimination of outliers, the sub-database can be eliminated by setting the upper and lower limits of the elimination threshold.
为了防止这些非正常监测数据对后续时序数据预测的干扰,根据实时测试的数据集的具体情况选择正确的异常数据处理方法十分重要。由此,上述步骤S102包括步骤S1021、步骤S1022、步骤S1023和步骤S1024,其中:In order to prevent these abnormal monitoring data from interfering with subsequent time series data prediction, it is very important to select the correct abnormal data processing method according to the specific conditions of the real-time test data set. Therefore, the above step S102 includes step S1021, step S1022, step S1023 and step S1024, wherein:
步骤S1021、获取子集合,所述子集合为基于所述第一时刻,从所述子数据库中截取的至少十个连续的所述数据流信息的集合。Step S1021: Acquire a sub-set, where the sub-set is a set of at least ten consecutive pieces of the data flow information intercepted from the sub-database based on the first moment.
可以理解的是,在本步骤中,基于时间序列从风向子数据库中选取连续的至少十个数据流信息构成子集合。索力子数据库按照上述方式截取子集合。It can be understood that, in this step, continuous at least ten pieces of data flow information are selected from the wind direction sub-database based on the time series to form a subset. The Soli sub-database intercepts sub-collections in the above-mentioned manner.
步骤S1022、计算剔除条件:基于所述子集合,分别计算所述子集合中所述入库数据的算数平均值和标准差值;根据所述算数平均数和所述标准差值计算,得到第一条件。Step S1022, calculating the exclusion conditions: based on the subset, calculate the arithmetic mean and standard deviation of the storage data in the subset respectively; calculate according to the arithmetic mean and the standard deviation to obtain the first a condition.
可以理解的是,在本步骤中,分别根据子集合中所有的入库数据的算数平均值和标准差值,并根据算数平均数和所述标准差值计算,得到第一条件。假设本实施例中,基于拉依达法则通过计算均值和标准差来剔除异常数据,那么计算得到第一条件如公式(1)所示:It can be understood that, in this step, the first condition is obtained by calculating according to the arithmetic mean and standard deviation of all the inbound data in the subset, and calculating according to the arithmetic mean and the standard deviation. Assuming that in this embodiment, the abnormal data is eliminated by calculating the mean and standard deviation based on Laida's rule, then the first condition obtained by calculation is shown in formula (1):

其中:


步骤S1023、根据所述第一条件,对所述子数据库进行剔除,得到剔除后的所述子数据库。Step S1023 , according to the first condition, remove the sub-database to obtain the removed sub-database.
可以理解的是,在本步骤中,超过上述第一条件的范围的入库数据则为异常数据,对其进行标记然后剔除,得到剔除后的所述子数据库。It can be understood that, in this step, the incoming data that exceeds the range of the above-mentioned first condition is abnormal data, which is marked and then eliminated to obtain the eliminated sub-database.
步骤S1024、判断剔除后的所述子数据库是否服从正态分布,若判断剔除后的所述子数据库不服从正态分布,则根据剔除后的所述子数据库重新开始计算剔除条件,直至剔除后的所述子数据库服从正态分布。Step S1024, judging whether the deleted sub-database obeys the normal distribution, and if it is judged that the deleted sub-database does not obey the normal distribution, restart the calculation of the elimination condition according to the deleted sub-database until after the elimination. The sub-database of is normally distributed.
可以理解的是,在本步骤中,根据剔除后的所述子数据库判断留下的数据基于时间序列是否服从正态分布,若不服从则根据保留的入库数据重新计算剔除条件,并根据更新后的剔除条件进行剔除,直至剔除后的所述子数据库服从正态分布。It can be understood that, in this step, according to the deleted sub-database, it is judged whether the remaining data obeys the normal distribution based on the time series, and if it does not obey, the exclusion condition is recalculated according to the retained storage data, and according to the updated data. Elimination is carried out according to the subsequent elimination conditions until the sub-database after elimination obeys the normal distribution.
由于众多不确定性因素导致如监测设备掉线、传感器失灵、网络传输中断、更换监测设备等原因,导致监测时间序列数据存在着不同程度的缺失数据情况,进而影响到监测数据的完整性以及监测对象评估的准确性。由此,步骤S102还包括步骤S1025、步骤S1026、步骤S1027和步骤S1028,其中:Due to many uncertain factors, such as monitoring equipment disconnection, sensor failure, network transmission interruption, replacement of monitoring equipment, etc., there are different degrees of missing data in monitoring time series data, which in turn affects the integrity of monitoring data and monitoring. Accuracy of subject assessment. Therefore, step S102 further includes step S1025, step S1026, step S1027 and step S1028, wherein:
步骤S1025、基于所述第一时刻,获取所述子数据库中的缺失段信息。Step S1025: Obtain missing segment information in the sub-database based on the first moment.
可以理解的是,在本步骤中,基于时间序列获得那些地方存在数据缺失。It can be understood that in this step, there are data missing in those places obtained based on the time series.
步骤S1026、根据所述缺失段信息,获取所述缺失段信息首尾两端的数据参数,所述数据参数包括所述入库数据和所述第一时刻。Step S1026: Acquire data parameters at both ends of the missing segment information according to the missing segment information, where the data parameters include the storage data and the first time.
可以理解的是,在本步骤中,根据缺失段信息,分别获取缺失段信息首尾两端的入库数据以及入库数据对应的第一时刻。It can be understood that, in this step, according to the missing segment information, the inbound data at the beginning and the end of the missing segment information and the first moment corresponding to the inbound data are obtained respectively.
步骤S1027、根据所述缺失段信息首尾两端的所述数据参数计算得到插值系数。Step S1027: Calculate and obtain an interpolation coefficient according to the data parameters at the first and last ends of the missing segment information.
可以理解的是,在本步骤中,设缺失段信息首尾两端的数据参数分别为(a1、b1)和(a2、b2),根据上述两个数据参数按照公式(2)计算插值系数,公式(2)如下:It can be understood that, in this step, the data parameters at the beginning and end of the missing segment information are set to be (a 1 , b 1 ) and (a 2 , b 2 ) respectively, and the interpolation is calculated according to formula (2) according to the above two data parameters. coefficient, formula (2) is as follows:

其中:
步骤S1028、根据所述数据参数和所述插值系数,对所述缺失段信息进行填充。Step S1028: Fill in the missing segment information according to the data parameter and the interpolation coefficient.
可以理解的是,在本步骤中,所述数据参数和所述插值系数按照公式(3)对缺失段信息进行填充,公式(3)如下:It can be understood that, in this step, the data parameters and the interpolation coefficients fill in the missing segment information according to formula (3), and formula (3) is as follows:

其中:y为缺失段信息中间任意第一时刻对应的入库数据,
步骤S2、判断所述入库数据是否被访问,若所述入库数据被访问,则获取第二时刻以及所述入库数据在所述第一时刻下对应的所述温度参数、数据价值增量、数据温度增量和数据价值权重;并根据所述温度参数、所述数据价值增量、所述数据温度增量和所述数据价值权重更新所述入库数据在所述第二时刻下对应的所述温度参数;所述第二时刻为所述入库数据被访问时的时间参数。Step S2, judging whether the inbound data is accessed, if the inbound data is accessed, obtain the second time and the corresponding temperature parameter and data value increase of the inbound data at the first time. data temperature increment and data value weight; and according to the temperature parameter, the data value increment, the data temperature increment and the data value weight, update the inbound data at the second moment The corresponding temperature parameter; the second time is the time parameter when the inbound data is accessed.
可以理解的是,在本步骤中,在向数据管理终端传输数据的同时,客户端自定义输入温度参数、数据价值增量、数据温度增量和数据价值权重,当入库数据被访问时,则找到入库数据所对应的上述自定义参数,根据上述自定义参数计算得到更新后的温度参数,且更新后的温度参数与入库数据在被访问时刻时的第二时刻相对应。对入库数据的访问包括修改、查询等操作。It can be understood that in this step, while transmitting data to the data management terminal, the client customizes the input temperature parameters, data value increment, data temperature increment and data value weight. Then, the above-mentioned custom parameters corresponding to the storage data are found, and the updated temperature parameters are calculated according to the above-mentioned custom parameters, and the updated temperature parameters correspond to the second moment when the storage data is accessed. Access to database data includes operations such as modification and query.
本实施例中,步骤S2还包括步骤S201、步骤S202和步骤S203,其中:In this embodiment, step S2 further includes step S201, step S202 and step S203, wherein:
步骤S201、根据所述数据价值增量、所述数据温度增量和所述数据价值权重计算,得到数据温度变化值。Step S201: Calculate according to the data value increment, the data temperature increment and the data value weight to obtain a data temperature change value.
可以理解的是,在本步骤中,根据公式(4)计算数据温度变化值,公式(4)如下:It can be understood that in this step, the data temperature change value is calculated according to formula (4), and formula (4) is as follows:

其中:TZ为数据温度变化值;

步骤S202、根据所述温度参数、所述数据温度变化值和牛顿衰减系数计算,得到更新后的所述温度参数。Step S202: Calculate according to the temperature parameter, the data temperature change value and the Newton attenuation coefficient to obtain the updated temperature parameter.
可以理解的是,在本步骤中,根据公式(5)更新入库数据的温度参数,公式(5)如下:It can be understood that in this step, the temperature parameter of the storage data is updated according to the formula (5), and the formula (5) is as follows:

其中,
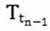
步骤S203、基于所述第二时刻,建立所述入库数据、更新后的所述温度参数与所述第二时刻的映射关系。Step S203: Based on the second time, establish a mapping relationship between the storage data, the updated temperature parameter and the second time.
可以理解的是,在本步骤中,根据入库数据被访问的时刻和更新后的温度参数,建立第二时刻、入库数据和更新后的所述温度参数的映射关系,便于后期入库数据再次被访问时,对其对应的温度参数进行迭代更新。It can be understood that, in this step, according to the time when the storage data is accessed and the updated temperature parameter, a mapping relationship between the second moment, the storage data and the updated temperature parameter is established, which is convenient for the storage data in the later stage. When accessed again, iteratively update its corresponding temperature parameters.
上述步骤中价值权重的确定方法还包括步骤S2011、步骤S2012、步骤S2013和步骤S2014,其中:The method for determining the value weight in the above steps further includes step S2011, step S2012, step S2013 and step S2014, wherein:
步骤S2011、获取第一参数、第二参数和研究集合信息,所述第一参数为访问所述子数据库的用户数量;所述第二参数为对所述子数据库对应的数据应用价值的评估值;所述研究集合信息为不同属性的所述子数据库构成的数据集合。Step S2011: Obtain a first parameter, a second parameter and research collection information, where the first parameter is the number of users accessing the sub-database; the second parameter is an evaluation value of the data application value corresponding to the sub-database ; The research collection information is a data collection composed of the sub-databases with different attributes.
可以理解的是,在本步骤中,若一条数据被访问的用户数量越多,数据的价值就越高;同时如果一个数据被多个用户访问,那么它的改变和它的访问性能就会影响更多的用户,因此需要从数据管理终端的访问记录中获得第一参数。从数据管理终端中获取客户端输入的子数据库的第二参数,该参数由用户对该价值的使用情况进行人为评估确定。根据不同的研究问题,从数据管理终端中调取与研究问题相关联的子数据库构成研究集合信息。It is understandable that, in this step, if a piece of data is accessed by more users, the value of the data will be higher; at the same time, if a piece of data is accessed by multiple users, its changes and its access performance will affect the data. More users, therefore, need to obtain the first parameter from the access record of the data management terminal. The second parameter of the sub-database input by the client is obtained from the data management terminal, and the parameter is determined by the user's manual evaluation of the usage of the value. According to different research questions, the sub-databases associated with the research questions are retrieved from the data management terminal to constitute research collection information.
步骤S2012、根据所述第一参数和所述第二参数计算,得到第一数据价值,所述第一数据价值为所述子数据库对应的所述第一参数和第二参数之和。Step S2012: Calculate according to the first parameter and the second parameter to obtain a first data value, where the first data value is the sum of the first parameter and the second parameter corresponding to the sub-database.
步骤S2013、根据所述第一数据价值和所述研究集合信息计算,得到第二数据价值,所述第二数据价值为所述研究集合信息中所有所述子数据库的所述第一数据价值之和。Step S2013: Calculate according to the first data value and the research set information to obtain a second data value, where the second data value is the sum of the first data values of all the sub-databases in the research set information. and.
步骤S2014、根据所述第一数据价值和所述第二数据价值计算,得到所述子数据库对应的数据价值权重。Step S2014: Calculate according to the first data value and the second data value to obtain the data value weight corresponding to the sub-database.
可以理解的是,在本步骤中,根据公式(6)确定子数据库对应的数据价值权重,公式(6)如下:It can be understood that in this step, the data value weight corresponding to the sub-database is determined according to formula (6), and formula (6) is as follows:

其中:

步骤S3、基于所述入库数据对应的更新后的所述温度参数,对所述数据流信息进行冷热数据的分类。Step S3 , classifying the data flow information based on the updated temperature parameter corresponding to the storage data, classifying the cold and hot data.
可以理解的是,在本步骤中,基于所述入库数据对应的更新后的所述温度参数,对所述数据流信息进行冷热数据的分类,分类完毕后再将第二时刻更新为第一时刻,并将更新后的第一时刻、入库数据和更新后的温度参数构成更新后的数据流信息存入数据管理终端中。It can be understood that, in this step, based on the updated temperature parameters corresponding to the storage data, the data stream information is classified as cold and hot data, and after the classification is completed, the second time is updated to the first time. At one time, the updated first time, the storage data and the updated temperature parameters constitute the updated data flow information and are stored in the data management terminal.
实施例2:Example 2:
请参照图2,图2所示为本实施例的冷热数据分类的装置700结构示意图,该冷热数据分类的装置700包括获取模块710、判断模块720和分类模块730,其中:Please refer to FIG. 2. FIG. 2 shows a schematic structural diagram of an
获取模块710:用于获取至少两个数据流信息,每个所述数据流信息包括入库数据以及所述入库数据对应的温度参数和第一时刻。Obtaining module 710: configured to obtain at least two data flow information, each of the data flow information includes storage data, temperature parameters and first time corresponding to the storage data.
优选地,上述获取模块710还包括第一处理单元711和第二处理单元712,其中:Preferably, the above obtaining
第一处理单元711:用于分别判断每个所述数据流信息是否在预设的归类条件内,若所述数据流信息在所述预设的归类条件内,则得到至少一个子数据库,所述子数据库为所述数据流信息进行聚类处理划分后的具有同一属性的数据集合;所述归类条件为划分同一属性数据的信息。The
第二处理单元712:用于基于所述第一时刻,判断每个所述子数据库中是否存在缺失数据,若不存在缺失数据,则分别对每个所述子数据库进行剔除,并更新每个所述子数据库为剔除后的子数据库;若存在缺失数据,则对每个所述子数据库进行补全,并更新所述子数据库为补全后的子数据库。The
优选地,上述第二处理单元712包括第一子单元7121、第二子单元7122、第三子单元7123和第四子单元7124,其中:Preferably, the above-mentioned
第一子单元7121:用于基于所述第一时刻,获取所述子数据库中的缺失段信息。The
第二子单元7122:用于根据所述缺失段信息,获取所述缺失段信息首尾两端的数据参数,所述数据参数包括所述入库数据和所述第一时刻。The
第三子单元7123:用于根据所述缺失段信息首尾两端的所述数据参数计算得到插值系数。The
第四子单元7124:用于根据所述数据参数和所述插值系数,对所述缺失段信息进行填充。Fourth subunit 7124: used to fill in the missing segment information according to the data parameter and the interpolation coefficient.
判断模块720:用于判断所述入库数据是否被访问,若所述入库数据被访问,则获取第二时刻以及所述入库数据在所述第一时刻下对应的所述温度参数、数据价值增量、数据温度增量和数据价值权重;并根据所述温度参数、所述数据价值增量、所述数据温度增量和所述数据价值权重更新所述入库数据在所述第二时刻下对应的所述温度参数;所述第二时刻为所述入库数据被访问时的时间参数。Judging module 720: for judging whether the inbound data is accessed, and if the inbound data is accessed, obtain the second moment and the temperature parameter corresponding to the inbound data at the first moment, Data value increment, data temperature increment and data value weight; and according to the temperature parameter, the data value increment, the data temperature increment and the data value weight, update the inbound data in the The temperature parameter corresponding to the second time; the second time is the time parameter when the inbound data is accessed.
优选地,上述判断模块720还包括获取子单元721、第一计算单元722、第二计算单元723和第三计算单元724,其中:Preferably, the
获取子单元721:用于获取第一参数、第二参数和研究集合信息,所述第一参数为访问所述子数据库的用户数量;所述第二参数为对所述子数据库对应的数据应用价值的评估值;所述研究集合信息为不同属性的所述子数据库构成的数据集合;Obtaining subunit 721: used to obtain a first parameter, a second parameter and study set information, where the first parameter is the number of users accessing the sub-database; the second parameter is the data application corresponding to the sub-database The evaluation value of the value; the research collection information is a data collection composed of the sub-databases with different attributes;
第一计算单元722:用于根据所述第一参数和所述第二参数计算,得到第一数据价值,所述第一数据价值为所述子数据库对应的所述第一参数和第二参数之和;The
第二计算单元723:用于根据所述第一数据价值和所述研究集合信息计算,得到第二数据价值,所述第二数据价值为所述研究集合信息中所有所述子数据库的所述第一数据价值之和;Second calculation unit 723: configured to calculate according to the first data value and the research set information to obtain a second data value, where the second data value is the data of all the sub-databases in the research set information The sum of the first data value;
第三计算单元724:用于根据所述第一数据价值和所述第二数据价值计算,得到所述子数据库对应的数据价值权重。The
分类模块730:用于基于所述入库数据对应的更新后的所述温度参数,对所述数据流信息进行冷热数据的分类。Classification module 730: configured to classify the cold and hot data on the data flow information based on the updated temperature parameter corresponding to the storage data.
需要说明的是,关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。It should be noted that, with regard to the apparatus in the foregoing embodiment, the specific manner in which each module performs operations has been described in detail in the embodiment of the method, and will not be described in detail here.
实施例3:Example 3:
相应于上面的方法实施例,本实施例中还提供了一种冷热数据分类的设备800,下文描述的一种冷热数据分类的设备800与上文描述的一种冷热数据分类的方法可相互对应参照。Corresponding to the above method embodiments, a
图3是根据示例性实施例示出的一种冷热数据分类的设备800的框图。如图3所示,该冷热数据分类的设备800可以包括:处理器801,存储器802。该冷热数据分类的设备800还可以包括多媒体组件803,I/O接口804,以及通信组件805中的一者或多者。FIG. 3 is a block diagram of a
其中,处理器801用于控制该冷热数据分类的设备800的整体操作,以完成上述的冷热数据分类的方法中的全部或部分步骤。存储器802用于存储各种类型的数据以支持在该冷热数据分类的设备800的操作,这些数据例如可以包括用于在该冷热数据分类的设备800上操作的任何应用程序或方法的指令,以及应用程序相关的数据,例如联系人数据、收发的消息、图片、音频、视频等等。该存储器802可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(Static Random Access Memory,简称SRAM),电可擦除可编程只读存储器(Electrically Erasable Programmable Read-OnlyMemory,简称EEPROM),可擦除可编程只读存储器(Erasable Programmable Read-OnlyMemory,简称EPROM),可编程只读存储器(Programmable Read-Only Memory,简称PROM),只读存储器(Read-Only Memory,简称ROM),磁存储器,快闪存储器,磁盘或光盘。多媒体组件803可以包括屏幕和音频组件。其中屏幕例如可以是触摸屏,音频组件用于输出和/或输入音频信号。例如,音频组件可以包括一个麦克风,麦克风用于接收外部音频信号。所接收的音频信号可以被进一步存储在存储器802或通过通信组件805发送。音频组件还包括至少一个扬声器,用于输出音频信号。I/O接口804为处理器801和其他接口模块之间提供接口,上述其他接口模块可以是键盘,鼠标,按钮等。这些按钮可以是虚拟按钮或者实体按钮。通信组件805用于该冷热数据分类的设备800与其他设备之间进行有线或无线通信。无线通信,例如Wi-Fi,蓝牙,近场通信(Near Field Communication,简称NFC),2G、3G或4G,或它们中的一种或几种的组合,因此相应的该通信组件805可以包括:Wi-Fi模块,蓝牙模块,NFC模块。Wherein, the
在一示例性实施例中,冷热数据分类的设备800可以被一个或多个应用专用集成电路(Application Specific Integrated Circuit,简称ASIC)、数字信号处理器(DigitalSignal Processor,简称DSP)、数字信号处理设备(Digital Signal ProcessingDevice,简称DSPD)、可编程逻辑器件(Programmable Logic Device,简称PLD)、现场可编程门阵列(Field Programmable Gate Array,简称FPGA)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述的冷热数据分类的方法。In an exemplary embodiment, the
在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该程序指令被处理器执行时实现上述的冷热数据分类的方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器802,上述程序指令可由冷热数据分类的设备800的处理器801执行以完成上述的冷热数据分类的方法。In another exemplary embodiment, a computer-readable storage medium including program instructions is also provided, and when the program instructions are executed by a processor, the steps of the above-mentioned method for classifying hot and cold data are implemented. For example, the computer-readable storage medium can be the above-mentioned
实施例4:Example 4:
相应于上面的方法实施例,本实施例中还提供了一种可读存储介质,下文描述的一种可读存储介质与上文描述的一种冷热数据分类的方法可相互对应参照。Corresponding to the above method embodiments, a readable storage medium is also provided in this embodiment, and a readable storage medium described below and a method for classifying cold and hot data described above can be referred to each other correspondingly.
一种可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述方法实施例的冷热数据分类的方法的步骤。A readable storage medium on which a computer program is stored, and when the computer program is executed by a processor, implements the steps of the method for classifying hot and cold data according to the above method embodiment.
该可读存储介质具体可以为U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可存储程序代码的可读存储介质。The readable storage medium may specifically be a USB flash drive, a mobile hard disk, a read-only memory (Read-Only Memory, ROM), a random access memory (Random Access Memory, RAM), a magnetic disk, or an optical disk, etc. that can store program codes. Readable storage medium.
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. For those skilled in the art, the present invention may have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included within the protection scope of the present invention.
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。The above are only specific embodiments of the present invention, but the protection scope of the present invention is not limited thereto. Any person skilled in the art can easily think of changes or substitutions within the technical scope disclosed by the present invention. should be included within the protection scope of the present invention. Therefore, the protection scope of the present invention should be subject to the protection scope of the claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210740213.2A CN114817425B (en) | 2022-06-28 | 2022-06-28 | Method, device and equipment for classifying cold and hot data and readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210740213.2A CN114817425B (en) | 2022-06-28 | 2022-06-28 | Method, device and equipment for classifying cold and hot data and readable storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114817425A CN114817425A (en) | 2022-07-29 |
| CN114817425B true CN114817425B (en) | 2022-09-02 |
Family
ID=82522454
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210740213.2A Active CN114817425B (en) | 2022-06-28 | 2022-06-28 | Method, device and equipment for classifying cold and hot data and readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114817425B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115827653B (en) * | 2022-11-25 | 2023-09-05 | 深圳计算科学研究院 | Pure column type updating method and device for HTAP and mass data |
| CN116424169A (en) * | 2023-04-10 | 2023-07-14 | 重庆赛力斯新能源汽车设计院有限公司 | An intelligent control method and device for a car seat |
| CN116204138B (en) * | 2023-05-05 | 2023-07-07 | 成都三合力通科技有限公司 | A high-efficiency storage system and method based on hierarchical storage |
| CN117076523B (en) * | 2023-10-13 | 2024-02-09 | 华能资本服务有限公司 | Local data time sequence storage method |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104731794A (en) * | 2013-12-19 | 2015-06-24 | 北京华易互动科技有限公司 | Cold-hot data fragmenting, mining and storing method |
| US9274941B1 (en) * | 2009-06-30 | 2016-03-01 | Emc Corporation | Facilitating data migration between tiers |
| CN107273409A (en) * | 2017-05-03 | 2017-10-20 | 广州赫炎大数据科技有限公司 | A kind of network data acquisition, storage and processing method and system |
| CN107315540A (en) * | 2017-06-13 | 2017-11-03 | 深圳神州数码云科数据技术有限公司 | A kind of AUTOMATIC ZONING storage method and system |
| CN112699142A (en) * | 2020-12-29 | 2021-04-23 | 平安普惠企业管理有限公司 | Cold and hot data processing method and device, electronic equipment and storage medium |
| DE102020117890A1 (en) * | 2019-10-28 | 2021-04-29 | Samsung Electronics Co., Ltd. | Storage device, method for operating the storage device, and computer system with storage device |
| CN112819775A (en) * | 2021-01-28 | 2021-05-18 | 中国空气动力研究与发展中心超高速空气动力研究所 | Segmentation and reinforcement method for damage detection image of aerospace composite material |
| CN112948398A (en) * | 2021-04-29 | 2021-06-11 | 电子科技大学 | Hierarchical storage system and method for cold and hot data |
| CN112988884A (en) * | 2019-12-17 | 2021-06-18 | 中国移动通信集团陕西有限公司 | Big data platform data storage method and device |
| CN113021818A (en) * | 2021-03-25 | 2021-06-25 | 弘丰塑胶制品(深圳)有限公司 | Control system of injection mold with automatic stripping function |
| CN113190585A (en) * | 2021-04-12 | 2021-07-30 | 郑州轻工业大学 | Big data acquisition and analysis system for clothing design |
| CN113515497A (en) * | 2020-04-09 | 2021-10-19 | 奇安信安全技术(珠海)有限公司 | Database data processing method, device and system |
| CN113886587A (en) * | 2021-10-09 | 2022-01-04 | 杭州凡闻科技有限公司 | A data classification method based on deep learning and a method for building a map |
| CN114186002A (en) * | 2021-12-14 | 2022-03-15 | 智博天宫(苏州)人工智能产业研究院有限公司 | Scientific and technological achievement data processing and analyzing method and system |
| CN114266492A (en) * | 2021-12-27 | 2022-04-01 | 天元大数据信用管理有限公司 | A Data Mining-Based Enterprise Financing Fund Matching Method |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101741509B1 (en) * | 2015-07-01 | 2017-06-15 | 지속가능발전소 주식회사 | Device and method for analyzing corporate reputation by data mining of news, recording medium for performing the method |
-
2022
- 2022-06-28 CN CN202210740213.2A patent/CN114817425B/en active Active
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9274941B1 (en) * | 2009-06-30 | 2016-03-01 | Emc Corporation | Facilitating data migration between tiers |
| CN104731794A (en) * | 2013-12-19 | 2015-06-24 | 北京华易互动科技有限公司 | Cold-hot data fragmenting, mining and storing method |
| CN107273409A (en) * | 2017-05-03 | 2017-10-20 | 广州赫炎大数据科技有限公司 | A kind of network data acquisition, storage and processing method and system |
| CN107315540A (en) * | 2017-06-13 | 2017-11-03 | 深圳神州数码云科数据技术有限公司 | A kind of AUTOMATIC ZONING storage method and system |
| DE102020117890A1 (en) * | 2019-10-28 | 2021-04-29 | Samsung Electronics Co., Ltd. | Storage device, method for operating the storage device, and computer system with storage device |
| CN112988884A (en) * | 2019-12-17 | 2021-06-18 | 中国移动通信集团陕西有限公司 | Big data platform data storage method and device |
| CN113515497A (en) * | 2020-04-09 | 2021-10-19 | 奇安信安全技术(珠海)有限公司 | Database data processing method, device and system |
| CN112699142A (en) * | 2020-12-29 | 2021-04-23 | 平安普惠企业管理有限公司 | Cold and hot data processing method and device, electronic equipment and storage medium |
| CN112819775A (en) * | 2021-01-28 | 2021-05-18 | 中国空气动力研究与发展中心超高速空气动力研究所 | Segmentation and reinforcement method for damage detection image of aerospace composite material |
| CN113021818A (en) * | 2021-03-25 | 2021-06-25 | 弘丰塑胶制品(深圳)有限公司 | Control system of injection mold with automatic stripping function |
| CN113190585A (en) * | 2021-04-12 | 2021-07-30 | 郑州轻工业大学 | Big data acquisition and analysis system for clothing design |
| CN112948398A (en) * | 2021-04-29 | 2021-06-11 | 电子科技大学 | Hierarchical storage system and method for cold and hot data |
| CN113886587A (en) * | 2021-10-09 | 2022-01-04 | 杭州凡闻科技有限公司 | A data classification method based on deep learning and a method for building a map |
| CN114186002A (en) * | 2021-12-14 | 2022-03-15 | 智博天宫(苏州)人工智能产业研究院有限公司 | Scientific and technological achievement data processing and analyzing method and system |
| CN114266492A (en) * | 2021-12-27 | 2022-04-01 | 天元大数据信用管理有限公司 | A Data Mining-Based Enterprise Financing Fund Matching Method |
Non-Patent Citations (4)
| Title |
|---|
| 基于价值评估的数据迁移策略研究;江菲等;《电子设计工程》;20110405(第07期);第11-13页 * |
| 基于内容分析法的电子商务模式分类研究;柳俊等;《管理工程学报》;20110715(第03期);第204-209页 * |
| 基于数据温度的冷热数据识别机制研究;解玉琳;《中国优秀博硕士学位论文全文数据库(硕士)信息科技辑》;20190815(第2019年第08期);第I138-461页 * |
| 数据库信息资源内容质量用户满意度模型及实证研究;莫祖英等;《中国图书馆学报》;20130315(第02期);第87-99页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114817425A (en) | 2022-07-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114817425B (en) | Method, device and equipment for classifying cold and hot data and readable storage medium | |
| WO2020155752A1 (en) | Outlier detection model verification method and apparatus, and computer device and storage medium | |
| TWI761642B (en) | Method, device and electronic device for determining decision-making strategy corresponding to business | |
| CN110442790A (en) | Recommend method, apparatus, server and the storage medium of multi-medium data | |
| CN106022505A (en) | Method and device of predicting user off-grid | |
| CN111435482A (en) | Outbound model construction method, outbound method, device and storage medium | |
| CN106126391A (en) | System monitoring method and apparatus | |
| WO2018130201A1 (en) | Method for determining associated account, server and storage medium | |
| WO2020073528A1 (en) | Session-based information push method and apparatus, computer device, and storage medium | |
| CN111680167A (en) | A service request response method and server | |
| CN120744791B (en) | Operation and maintenance management method and device, electronic equipment and storage medium | |
| CN116866218A (en) | A network performance detection method and system | |
| CN108647727A (en) | Unbalanced data classification lack sampling method, apparatus, equipment and medium | |
| CN115114534A (en) | Music recommendation method, server and storage medium | |
| WO2025016349A1 (en) | Abnormal data detection method and apparatus, and storage medium | |
| CN111010387B (en) | A method, device, device and medium for detecting illegal replacement of Internet of Things equipment | |
| CN108228896A (en) | A kind of missing data complementing method and device based on density | |
| CN121333878A (en) | An alarm processing method, related apparatus and system | |
| CN111475540A (en) | A method and device for generating a user relationship network | |
| CN110796164A (en) | Method and system for determining cluster number of data cluster, electronic device and storage medium | |
| CN118467643B (en) | Block chain-based data sharing method | |
| CN118863293B (en) | Power distribution network fault prediction method based on digital twin | |
| CN114239719A (en) | Network satisfaction prediction model construction method and device, prediction method and device | |
| CN109446432A (en) | Method and device for recommending information | |
| CN115203556B (en) | A method, apparatus, electronic device, and storage medium for training a scoring prediction model. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |